AAAI | Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
Sparse4DGS 论文总结
01 论文信息
- 论文题目: Sparse4DGS: 4D Gaussian Splatting for Sparse-Frame Dynamic Scene Reconstruction
- 作者: Changyue Shi, Chuxiao Yang, Xinyuan Hu, Minghao Chen, Wenwen Pan, Yan Yang, Jiajun Ding, Zhou Yu, Jun Yu
- 作者单位: Hangzhou Dianzi University;Peking University;Harbin Institute of Technology
- 会议信息: AAAI 2026
- 项目页: ChangyueShi.github.io/Sparse4DGS
- 论文定位: 面向稀疏帧动态场景重建的 4D Gaussian Splatting 方法,是论文明确强调的首个 sparse-frame 4D scene reconstruction 方法。
02 论文主要贡献
这篇论文解决的是一个很具体、但现有动态 3DGS/4DGS 方法普遍没认真处理的问题:输入不是高帧率连续视频,而是低帧率、帧间跨度大的稀疏视频时,如何仍然重建出高质量动态场景。
作者观察到,现有动态高斯方法在 sparse-frame 设定下,容易同时在两处失效:
- canonical space 失稳:规范空间中的高斯难以学到稳定、细致的结构;
- deformed space 错位:deformation network 在大位移条件下容易学习到错误形变。
而且最明显的失败区域并不是“没纹理的地方”,而是高纹理、边缘清晰、细节丰富的区域。这些区域虽然包含更多信息,但在帧间跳变大时也更难保持对齐。
围绕这个现象,论文提出 Sparse4DGS,核心思想是:把优化重点显式放到 texture-rich regions 上。具体做法包括两部分:
- Texture-Aware Deformation Regularization, TADR:在形变空间中加入纹理感知的深度纹理对齐约束,约束高纹理区域的几何形变。
- Texture-Aware Canonical Optimization, TACO:在 canonical Gaussian field 的优化过程中加入基于纹理强度的噪声驱动,让高斯逐步向纹理丰富区域集中。
论文在 NeRF-Synthetic、NeRF-DS、HyperNeRF 和自建 iPhone-4D 数据集上进行了验证,结果表明 Sparse4DGS 在 sparse-frame 输入下优于现有动态重建或 sparse-view baseline。
03 论文创新点
3.1 首个面向 sparse-frame dynamic scene reconstruction 的 4DGS 方法
论文不是简单把已有动态 Gaussian Splatting 方法拿来降帧测试,而是把“稀疏帧动态重建”本身当作一个独立问题来研究。这一点很重要,因为 sparse-frame 的难点并不是普通动态重建性能轻微下降,而是监督本身会变得严重欠约束。
3.2 提出 Texture Intensity Gaussian Field
作者先从每个输入帧中提取 2D texture intensity map,再把这种纹理强度嵌入到 3D Gaussian 上,形成能表达“哪里是纹理丰富区域”的高斯属性场。这个设计为后续的 deformation regularization 和 canonical optimization 提供了统一的纹理依据。
3.3 提出 Texture-Aware Deformation Regularization
作者没有直接拿深度图做普通全图监督,而是对深度图本身再提取 texture intensity,并用深度纹理的一致性来约束 deformation network。这比直接对齐深度值更强调局部结构边界。
3.4 提出 Texture-Aware Canonical Optimization
作者把 canonical Gaussian 的梯度更新改写到 SGLD 风格框架中,并加入与纹理强度相关的噪声项。直观上说,这相当于在优化过程中持续“推”高斯去靠近纹理丰富区域,而不是只依赖常规梯度。
3.5 支持真实低帧率应用场景
论文不仅在公开数据集上测试,还构建了 iPhone-4D 数据集,并分别测试 30 FPS 与 5 FPS 输入。这个设置说明方法目标确实是现实视频采集,而不是只在理想实验条件下成立。
04 方法
4.1 问题出发点
已有动态 Gaussian Splatting 方法通常依赖密集视频序列。相邻帧之间位移较小,deformation network 比较容易学习时间连续变化。
但在 sparse-frame 设定下:
- 帧间运动跨度更大;
- 遮挡变化更强;
- 单纯 RGB photometric loss 更容易出现伪解;
- 高纹理区域最容易暴露错位与几何崩坏。
论文在引言中明确指出,现有方法在 sparse-frame 输入时会在 canonical 与 deformed 两个空间都出现退化,尤其是在texture-rich areas。这一点也正是 Sparse4DGS 设计的出发点。

Figure 1 展示了 “Sheet” 场景在 sparse 输入下的对比结果,包括 canonical frame 与 deformed frame 两行,对比了 Deformable3DGS、CoRGS、4DGaussians 与 Ours。它直接支撑本文的问题动机:现有方法在高纹理区域会模糊、错位,而 Sparse4DGS 能在 canonical 与 deformed 两个空间都恢复更清晰的细节。
4.2 整体框架总览
Sparse4DGS 的整体流程如 Figure 2 所示,可以概括为三步:
-
从稀疏输入帧提取辅助信号
- 用 Sobel operator 从 RGB 图像中提取 texture intensity map
- 用 Mono-Depth Estimator 预测深度图
-
把 texture intensity 嵌入到 Gaussian 表示中
- 每个 Gaussian 增加一个 TI 属性
- 通过纹理渲染图和真实 TI 图的一致性损失优化该属性
-
分别从 deformed space 与 canonical space 两侧做改进
- 在 deformed side 使用 TADR
- 在 canonical side 使用 TACO
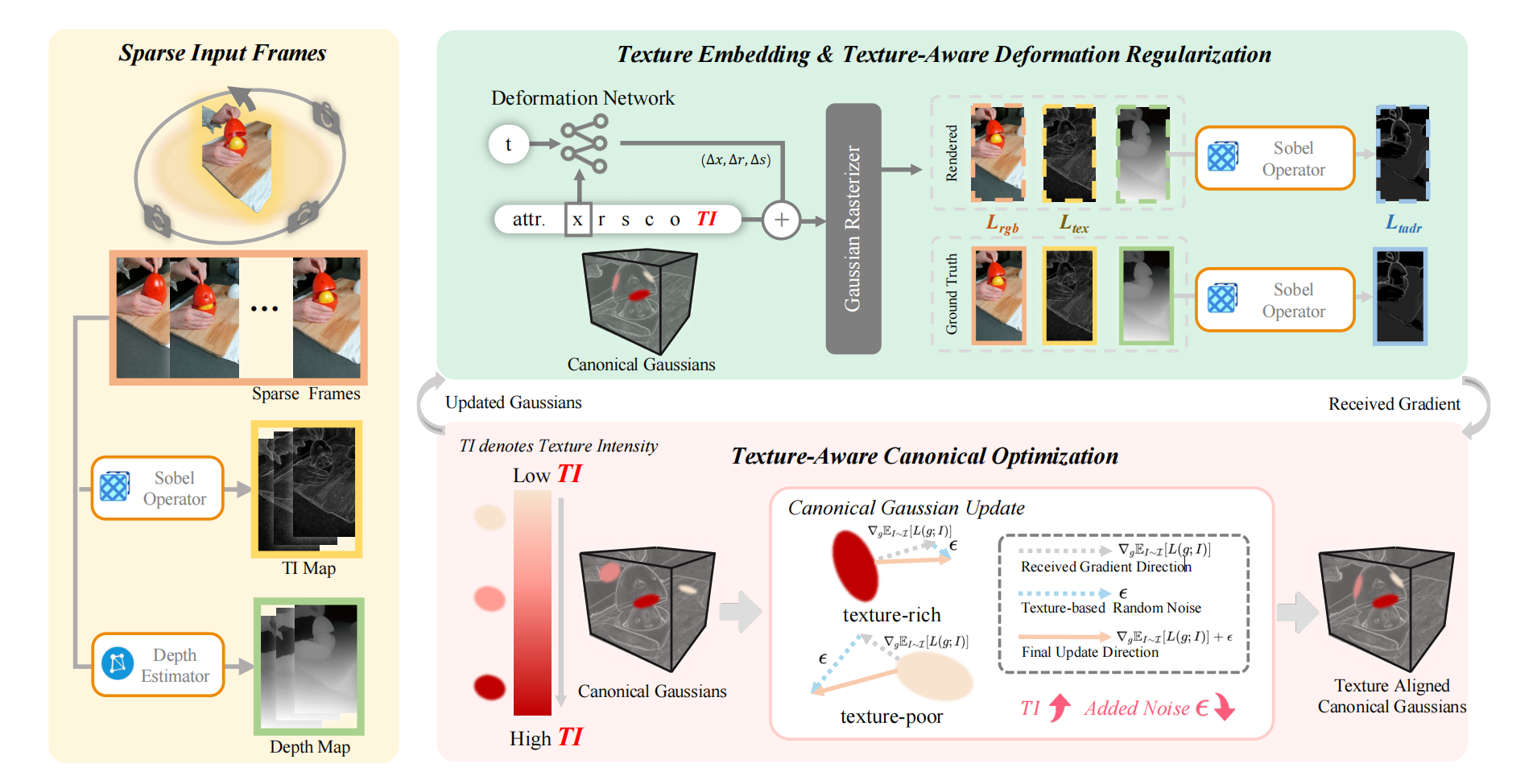
Figure 2 左侧给出 sparse frames、TI map、depth map 的产生过程,右上是 Texture Embedding & Texture-Aware Deformation Regularization,右下是 Texture-Aware Canonical Optimization。
4.3 Preliminary: Dynamic Gaussian Splatting 与 SGLD
4.3.1 Dynamic Gaussian Splatting
论文沿用了动态 Gaussian Splatting 的基本设定。静态场景由一组 anisotropic Gaussians 表示:
{μi, si, ri, oi, ci}\{\mu_i,\; s_i,\; r_i,\; o_i,\; c_i\}{μi,si,ri,oi,ci}
其中:
- μi∈R3\mu_i \in \mathbb{R}^3μi∈R3:高斯中心位置
- si∈R3s_i \in \mathbb{R}^3si∈R3:尺度
- ri∈R4r_i \in \mathbb{R}^4ri∈R4:旋转相关参数
- oi∈Ro_i \in \mathbb{R}oi∈R:opacity
- ci∈RKc_i \in \mathbb{R}^Kci∈RK:颜色或 SH 表示
其渲染遵循 alpha blending:
c=∑i=1nciαi∏j=1i−1(1−αj) c = \sum_{i=1}^{n} c_i \alpha_i \prod_{j=1}^{i-1}(1 - \alpha_j) c=i=1∑nciαij=1∏i−1(1−αj)
为了表示动态场景,时间 ttt 下的 Gaussian 由 deformation MLP 预测偏移:
(δx,δr,δs)=Fθ(γ(sg(x)),γ(t)) (\delta x, \delta r, \delta s) = F_{\theta}(\gamma(sg(x)), \gamma(t)) (δx,δr,δs)=Fθ(γ(sg(x)),γ(t))
其中:
- FθF_{\theta}Fθ 是 deformation MLP
- γ(⋅)\gamma(\cdot)γ(⋅) 是 positional encoding
- sg(⋅)sg(\cdot)sg(⋅) 表示 stop-gradient
- 取一个 canonical Gaussian 的位置 xxx
- 取当前时间 ttt
- 先分别做位置编码
- 喂给 deformation MLP
- 输出这个 Gaussian 在当前时刻应该有的位移、旋转、尺度改变量
也就是:
canonical Gaussian+time t→deformation network→(δx,δr,δs) \text{canonical Gaussian} + \text{time } t \rightarrow \text{deformation network} \rightarrow (\delta x,\delta r,\delta s) canonical Gaussian+time t→deformation network→(δx,δr,δs)
然后再把这些偏移加回 canonical Gaussian 上,就得到当前时刻的 deformed Gaussian。
渲染损失使用:
Lrgb=(1−λ)L1(I^,I)+λLSSIM(I^,I) L_{rgb} = (1-\lambda)L_1(\hat{I}, I) + \lambda L_{SSIM}(\hat{I}, I) Lrgb=(1−λ)L1(I^,I)+λLSSIM(I^,I)
4.3.2 Stochastic Gradient Langevin Dynamics
论文接着引入 SGLD 作为 TACO 的理论基础。
传统 SGD 更新写作:
g=g−α⋅∇gEI∼I[L(g;I)] g = g - \alpha \cdot \nabla_g \mathbb{E}_{I \sim \mathcal{I}}[L(g;I)] g=g−α⋅∇gEI∼I[L(g;I)]
SGLD 写作:
g=g+a⋅∇glogP(g)+b⋅ϵ g = g + a \cdot \nabla_g \log P(g) + b \cdot \epsilon g=g+a⋅∇glogP(g)+b⋅ϵ
在 Gaussian Splatting 相关工作中,可写成:
g=g−αg⋅∇gEI∼I[L(g;I)]+αnoise⋅ϵo g = g - \alpha_g \cdot \nabla_g \mathbb{E}_{I \sim \mathcal{I}}[L(g;I)] + \alpha_{noise} \cdot \epsilon_o g=g−αg⋅∇gEI∼I[L(g;I)]+αnoise⋅ϵo
其中噪声项:
ϵo=σ(−k(o−t))⋅Ση \epsilon_o = \sigma(-k(o-t)) \cdot \Sigma \eta ϵo=σ(−k(o−t))⋅Ση
Sparse4DGS 就是在这个基础上进一步引入纹理相关噪声。
4.4 Texture Intensity Gaussian Field
4.4.1 2D Texture Intensity Maps
为了显式表示纹理丰富程度,作者首先从输入 RGB 图像提取每像素梯度幅值。给定 RGB 图像 I∈RH×W×3I \in \mathbb{R}^{H\times W \times 3}I∈RH×W×3,先用 Sobel 核计算水平和垂直梯度:
TIx=I∗[−101−202−101],TIy=I∗[−1−2−1000121] TI_x = I * \begin{bmatrix} -1 & 0 & 1\\ -2 & 0 & 2\\ -1 & 0 & 1 \end{bmatrix}, \quad TI_y = I * \begin{bmatrix} -1 & -2 & -1\\ 0 & 0 & 0\\ 1 & 2 & 1 \end{bmatrix} TIx=I∗ −1−2−1000121 ,TIy=I∗ −101−202−101
然后计算梯度幅值:
TIgt(i,j)=TIx(i,j)2+TIy(i,j)2 TI_{gt}(i,j) = \sqrt{TI_x(i,j)^2 + TI_y(i,j)^2} TIgt(i,j)=TIx(i,j)2+TIy(i,j)2
这个量就是论文里的 texture intensity。它本质上是在量化局部边缘与高频纹理强弱。
4.4.2 3D 中的 TI 属性
论文接着给每个 Gaussian 加入新的属性 TI,并通过 differentiable rasterizer 把它渲染成 TIrenderTI_{render}TIrender。然后用 GT 的 TIgtTI_{gt}TIgt 去监督。
但作者没有直接用 L1,而是使用 Pearson Correlation Coefficient, PCC,因为不同视角提取的 TI 图存在空间不一致,PCC 更强调相对变化趋势而不是逐像素绝对值。
PCC 定义为:
PCC(X,Y)=Cov(X,Y)Var(X)Var(Y) PCC(X,Y) = \frac{Cov(X,Y)}{\sqrt{Var(X)}\sqrt{Var(Y)}} PCC(X,Y)=Var(X)Var(Y)Cov(X,Y)
因此纹理嵌入损失写作:
Ltex=1−PCC(TIgt,TIrender) L_{tex} = 1 - PCC(TI_{gt}, TI_{render}) Ltex=1−PCC(TIgt,TIrender)


4.5 Texture-Aware Deformation Regularization, TADR
这一节对应论文 4.2。核心思想是:不仅要让 RGB 图对,还要让深度纹理结构对。
作者认为 texture intensity 往往和 depth change 有相关性,因此可以利用深度纹理来约束 deformation 的几何质量。
首先,对渲染深度 DrenderD_{render}Drender 和单目深度估计得到的 DdptD_{dpt}Ddpt 分别提取纹理:
TIrenderdepth=TE(Drender),TIgtdepth=TE(Ddpt) TI^{depth}_{render} = TE(D_{render}), \quad TI^{depth}_{gt} = TE(D_{dpt}) TIrenderdepth=TE(Drender),TIgtdepth=TE(Ddpt)
然后定义 TADR 损失:
Ltadr=1−PCC(TIgtdepth,TIrenderdepth) L_{tadr} = 1 - PCC(TI^{depth}_{gt}, TI^{depth}_{render}) Ltadr=1−PCC(TIgtdepth,TIrenderdepth)
最终总损失:
L=Lrgb+λ1Ltex+λ2Ltadr L = L_{rgb} + \lambda_1 L_{tex} + \lambda_2 L_{tadr} L=Lrgb+λ1Ltex+λ2Ltadr
这里很关键的一点是,作者不是直接对齐深度值,而是对齐深度纹理。这样更强调局部结构边界和几何变化区域,也更适合 sparse-frame 条件下高纹理区域容易出错的场景。
4.6 Texture-Aware Canonical Optimization, TACO
这一节对应论文 4.3。作者认为,除了 deformation network,canonical Gaussian field 自身在 sparse-frame 条件下也会优化不稳。因此他们基于 SGLD 改写了 canonical Gaussian 的更新方式。
作者提出:
g=g−αg⋅∇gEI∼I[L(g;I)]+αnoise⋅(ϵtex+ϵo) g = g - \alpha_g \cdot \nabla_g \mathbb{E}_{I \sim \mathcal{I}}[L(g;I)] + \alpha_{noise}\cdot(\epsilon_{tex} + \epsilon_o) g=g−αg⋅∇gEI∼I[L(g;I)]+αnoise⋅(ϵtex+ϵo)
其中:
- ϵo\epsilon_oϵo 是原先用于抑制模糊/浮动高斯的 opacity noise
- ϵtex\epsilon_{tex}ϵtex 是新加入的 texture-aware noise
其定义为:
ϵtex=σ(−k(TI−t))⋅Ση \epsilon_{tex} = \sigma(-k(TI - t)) \cdot \Sigma \eta ϵtex=σ(−k(TI−t))⋅Ση
论文说明 TI 的数值范围与 opacity 一致,因此沿用了和 (\epsilon_o) 一样的超参数。
直观理解:
- 如果某个 Gaussian 当前的 TI 很低,说明它不在纹理丰富区域,那么它会收到更大的随机扰动;
- 如果它逐渐移动到高 TI 区域,那么 (\epsilon_{tex}) 逐渐变小,更新趋于稳定。
因此,TACO 的作用是持续推动 canonical Gaussians 往 texture-rich regions 集中。
05 实验分析
5.1 数据集与设置
论文在以下数据集上验证 Sparse4DGS:
- NeRF-Synthetic
- NeRF-DS
- HyperNeRF
- iPhone-4D
其中:
- NeRF-Synthetic 与 NeRF-DS 分别从原训练集均匀采样 20/30/40 帧;
- HyperNeRF 采样 10/20/30 帧;
- iPhone-4D 是作者构建的真实数据集,使用 iPhone 在 30 FPS 采集,并测试 30 FPS 与 5 FPS 输入。
baseline 包括:
- Deformable3DGS
- 4DGaussians
- CoRGS
评价指标为:
- PSNR ↑
- SSIM ↑
- LPIPS ↓
5.2 主结果
定量结果
Table 1 给出了多数据集定量比较。表中结果显示:
- 在 NeRF-Synthetic (20 frames) 上,Sparse4DGS 的 PSNR/SSIM/LPIPS 都是最优;
- 在 NeRF-DS (20 frames) 上也取得最优;
- 在 Hyper-NeRF (30 frames) 上仍然最优;
- 在 iPhone-4D (30 FPS) 与 iPhone-4D (5 FPS) 上同样取得最佳结果。
其中最能说明问题的是 iPhone-4D 5 FPS,因为这是最接近稀疏帧现实场景的测试。论文表中 Ours 的 PSNR/SSIM/LPIPS 明显优于三个 baseline,说明该方法在低帧率输入下优势尤其明显。

5.3 多帧率应用分析
论文专门在 iPhone-4D 上讨论了 30 FPS 与 5 FPS 两种输入条件。这个实验非常关键,因为它验证了 Sparse4DGS 不只是“普通动态重建方法稍微加强版”,而是真正对低帧率场景有效。
作者结论是:
- 在 30 FPS 输入下,Sparse4DGS 仍优于 baseline;
- 在 5 FPS 输入下,优势更明显;
- 说明随着输入变稀疏,texture-aware 机制的价值变得更大。
这一点与方法设计完全一致,因为 sparse-frame 越严重,普通 photometric supervision 越不可靠,而 TI + depth 的辅助约束就越重要。
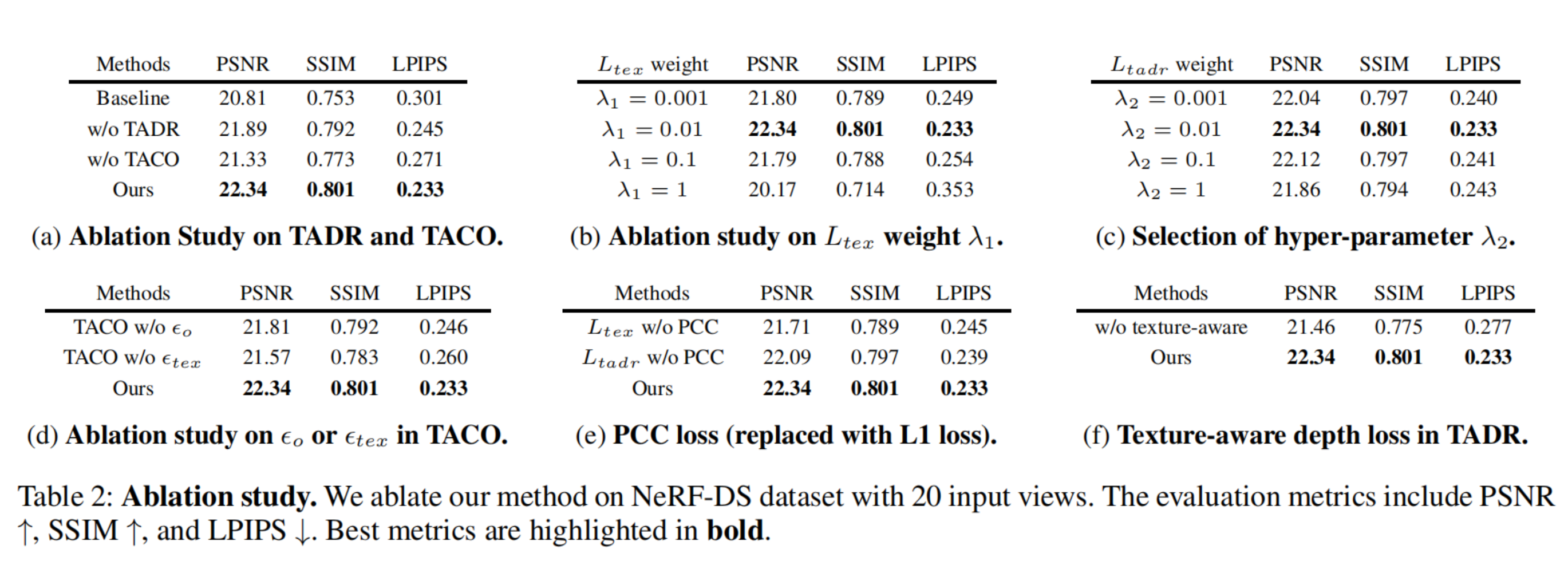
5.4 消融实验
Table 2 做了比较完整的 ablation study,全部在 NeRF-DS 20 input views 上进行。
5.4.1 模块消融
Table 2(a) 比较:
- Baseline
- w/o TADR
- w/o TACO
- Ours
结果表明去掉 TADR 或 TACO 都会掉点,而且去掉 TACO 的下降更明显,说明 canonical optimization 的改进非常关键。
5.4.2 超参数消融
- Table 2(b) 研究 LtexL_{tex}Ltex 的权重 λ1\lambda_1λ1
- Table 2© 研究 LtadrL_{tadr}Ltadr 的权重 λ2\lambda_2λ2
两者都表明设置为 0.01 时最好。
5.4.3 TACO 中噪声项的作用
Table 2(d) 比较:
- TACO w/o ϵo\epsilon_oϵo
- TACO w/o ϵtex\epsilon_{tex}ϵtex
- Ours
说明两个噪声项都有效,ϵtex\epsilon_{tex}ϵtex 对把高斯推向高纹理区域尤其重要。
5.4.4 PCC 的作用
Table 2(e) 用 L1 代替 PCC。结果性能下降,说明作者使用 PCC 而不是普通 L1 是有必要的。
5.4.5 Texture-aware depth loss 的作用
Table 2(f) 比较 texture-aware depth loss 与普通 depth loss,结果 Ours 更优。
5.5 方法优势与局限
优势
- 问题抓得准:不是泛泛提升动态重建,而是直击 sparse-frame 失败原因。
- 两侧同时修:同时改 canonical 与 deformation,而不是只修一个分支。
- 辅助信号设计合理:TI 负责指出关键区域,depth texture 负责提供几何边界约束。
- 实验完整:既有公开数据集,也有真实 iPhone 数据,并且专门测了低帧率。
可能局限
- 方法依赖单目深度估计质量,如果 DPT 结果偏差较大,可能影响监督。
- 纹理感知机制更偏向高纹理区域,对大面积低纹理区域的帮助可能有限。
- 新增 TADR 与 TACO 会增加训练复杂度与调参成本。
06 个人声明
本文为作者对原论文的学习笔记与整理,内容以论文正文为核心依据,并结合用户给定整理规则进行了修订。由于个人理解有限,若存在表述误差,请以论文原文为准。本文仅用于学术交流与学习,不代表任何机构立场。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)