YOLO 5目标检测原理
1.几种数据增强的方法

1.1旋转缩放

一句话总结:让模型学会"不管目标怎么转、怎么变大小,我都能认出来"
1. 缩放(Scale)的作用:应对目标远近/大小变化
原图:人占画面 80%(近距离)
增强后:人占画面 30%(模拟远距离)→ 模型学会识别小人2. 旋转(Rotation)的作用:应对目标方向变化
原图:车是正着的 🚗
增强后:车旋转45° ↗️ → 模型学会"斜着的车也是车"
YOLOv5 默认只开缩放不开旋转,是因为大多数日常物体(人、车、猫狗)有固定方向,强行旋转反而会让模型学到奇怪的特征。只有在航拍、遥感、工业零件等方向任意的场景,才需要手动开启旋转增强。
1.2 错切/非垂直投影

错切变换:垂直错切和水平错切,变换之后平行线依然保持平行,角度改变
实际场景:摄像头不是正对道路,而是斜着拍
↓
问题:车、路牌在图像中是倾斜的,不是正面
↓
错切增强:训练时随机倾斜图像
↓
效果:模型学会识别"斜着的车",即使摄像头角度不正也能检测
透明变换:模拟人眼看到的"近大远小"效果
铁轨实际上平行,但在照片里看起来越远越窄,最终汇聚到一点
这就是透视效果——三维世界在二维图像上的投影
由于旋转/错切/透视后,标注框会变大且不准确,YOLOv5 内部有过滤机制(面积阈值 10%),过度增强会导致有效训练样本减少。建议通过可视化检查增强后的图像,确保 bbox 没有严重变形。
1.3 翻转

翻转(Flip) 和旋转/缩放/错切/透视的目的本质上是一样的——都是为了让模型学会"不管目标怎么变,我都能认出来"。
左右翻转:
原图:狗朝左看 🐕 ←
增强后:狗朝右看 → 🐕模型学到的:"狗不管是朝左还是朝右,都是狗"
上下翻转:
原图:狗正常站立 🐕
增强后:狗倒过来 🙃为什么默认关闭?
- 现实中狗很少倒着走(除非特殊场景如无人机倒立拍摄)
- 强行翻转会引入"不真实的样本",反而干扰模型
翻转是最简单、最高效的方向增强,旋转/错切/透视是更复杂的视角增强,缩放是距离增强。它们组合起来,让模型具备真正的鲁棒性。
1.4 四图拼接

把4张不同的图拼成1张大图,让模型一次"看"到更多场景、更多目标
左上:斑马在草地 右上:长颈鹿在室内
左下:人在涂鸦墙 右下:便当盒↓ Mosaic 拼接 ↓
┌─────────────────────────────┐
│ 🦓斑马 │ 🦒长颈鹿 │
│ 草地 │ 室内 │
├─────────────────────────────┤
│ 👤人 │ 🍱便当 │
│ 涂鸦墙 │ 食物 │
└─────────────────────────────┘↓ 随机裁剪 + 缩放 ↓
最终训练图像(640×640):
包含4个场景的部分内容 + 所有目标的标注框
为啥需要Mosaic?解决啥问题?
| 问题 | 说明 | 后果 |
| ------------- | ------------------- | -------------- |
| **小目标太少** | 一张图里远处的人只有几个像素 | 模型学不会检测小人 |
| **背景单一** | 每张图只有一个场景(草地/室内/街道) | 模型过拟合特定背景 |
| **Batch 效率低** | 小目标需要大分辨率,GPU内存不够 | 只能用小 batch,训练慢 |
| **上下文缺失** | 模型看不到"多场景对比" | 泛化能力差 |
优势?
| 优势 | 原理 | 效果 |
| ------------- | ---------------- | ------------------------ |
| **小目标变多** | 4张图拼接,远距离目标被放大显示 | 小目标检测能力提升 **+3.2% mAP** |
| **背景多样化** | 一次看到草地+室内+街道+食物 | 模型学会"背景无关的特征" |
| **变相大 Batch** | 4张图合成1张,内存占用相同 | 等效 batch size ×4,训练更快 |
| **丰富上下文** | 不同场景的目标相邻出现 | 提升泛化能力 |
Mosaic 是 YOLOv5 相比 YOLOv4 最重要的改进之一,也是它被广泛采用的关键原因——简单、有效、几乎免费提升性能。Mosaic = 用"拼图游戏"的方式,让模型一次性接受"高难度综合训练",从而学会在真实世界的复杂场景中"眼观六路、明察秋毫"

注意:中心点的选取有可能导致目标边框被裁剪,需要额外的对哪些被裁剪掉的目标边框重新计算一下。
1.5 图像相互融合

将两张图像按透明度叠加融合,标签直接拼接保留,训练模型同时检测两个目标
与 Mosaic 的本质区别:
| | **Mosaic** | **MixUp** |
| ------ | ----------- | ------------- |
| **方式** | 4张图空间拼接 | 2张图像素融合 |
| **视觉** | 边界清晰,各自独立 | 半透明叠加,互相渗透 |
| **标签** | 框位置重新计算 | 直接拼接两组框 |
| **目的** | 看更多场景、更多小目标 | 学更鲁棒的特征、防止过拟合 |
| **适用** | 通用检测(默认全开) | 大模型/少样本/类别不平衡 |
核心作用(3点):
| 作用 | 说明 |
| ------------- | -------------------------- |
| **1. 特征鲁棒性** | 颜色/背景混合,迫使模型关注形状本质,而非过拟合背景 |
| **2. 虚拟样本扩充** | 两张图组合创造新训练样本,缓解数据不足 |
| **3. 正则化效果** | 类似"加噪训练",减少过拟合,提升泛化能力 |
Mosaic 是"空间拼图"让模型见多识广;MixUp 是"像素融合"让模型去伪存真——不被颜色背景迷惑,学到目标的本质特征。关键记忆点:MixUp 的标签是拼接不是融合 → 模型要同时检出两个目标,而不是输出概率分布。
1.6 copy-paste (复制粘贴)数据增强

将图像中的目标实例(带有精确分割掩码)复制并粘贴到另一张图像的随机位置,实现"实例级"的数据增强主要作用确实是 增加小目标样本数量,提升小目标检测能力
和Mosaic的本质区别:
| | **Mosaic** | **Copy-Paste** |
| -------- | ------------ | ---------------- |
| **操作对象** | 4张完整图像 | 单个目标实例 |
| **标注要求** | 边界框(bbox)即可 | 需要分割掩码(segments) |
| **拼接方式** | 空间拼接,边界清晰 | 像素级粘贴,可产生遮挡 |
| **背景处理** | 保留原图背景 | 目标融入新背景 |
| **核心目的** | 增加小目标数量、丰富场景 | 增加特定类别样本、模拟遮挡 |
作用:
| 作用 | 详细说明 | 典型场景 |
| ------------- | ----------------------- | --------------- |
| **1. 小目标过采样** | 复制小目标实例,粘贴到不同背景,增加小目标数量 | 遥感、航拍、小物体检测 |
| **2. 类别平衡** | 对稀有类别进行过采样,复制粘贴到多张图中 | 工业缺陷、稀有动物、医学病灶 |
| **3. 遮挡模拟** | 允许30% IoA 重叠,模拟真实遮挡场景 | 拥挤人群、重叠物体检测 |
更准确的说法:"作用是通过复制粘贴小目标到不同位置,增加小目标样本数量和空间分布多样性,从而提升模型对小目标的检测能力。它并不强调模拟真实场景,而是通过人工增加样本丰富度来解决小目标稀缺问题。"

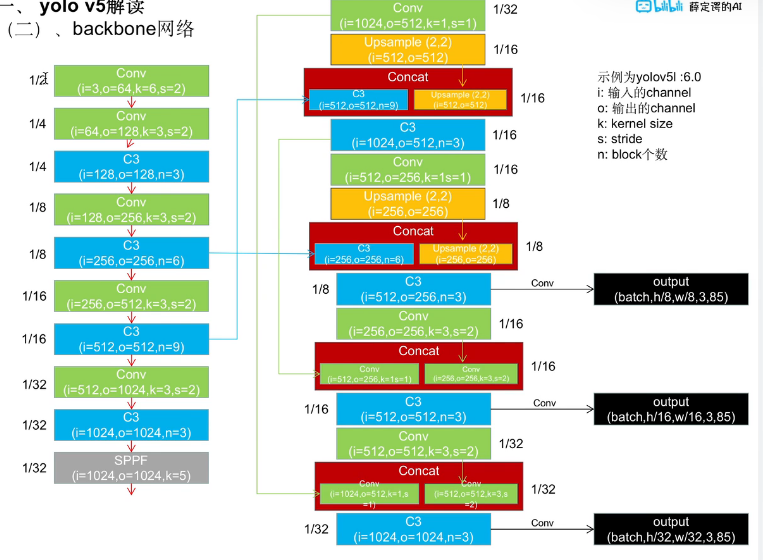
2 backbone 网络细节
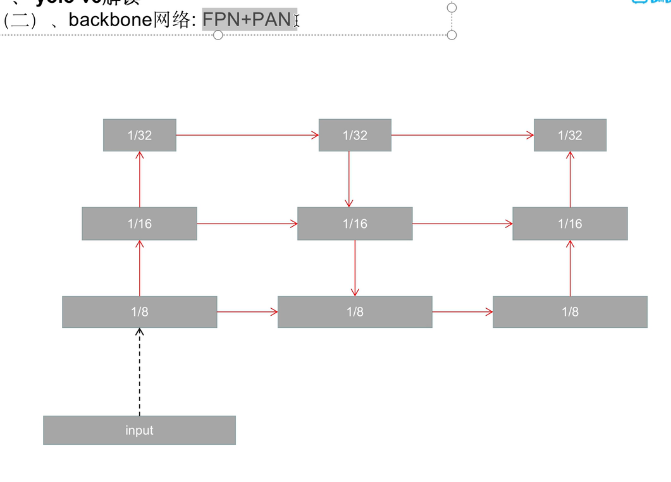
2.1 backbone 网络:FPN+PAN
YOLOv5 一般分为:
1)Backbone
负责从输入图片中提取不同层次的特征。
比如:
- 浅层特征:细节多,适合小目标
- 深层特征:语义强,适合大目标
2)Neck
就是你问的 FPN + PAN,负责把不同层的特征进行融合。
3)Head
负责最终输出检测结果:
- 类别
- 目标框位置
- 置信度
因为目标检测里会遇到不同大小的目标:
- 小目标:需要高分辨率、细节丰富的浅层特征
- 大目标:需要语义信息更强的深层特征
但问题是:
- 浅层特征虽然细节多,但“看不懂”高级语义
- 深层特征虽然语义强,但分辨率低,小目标容易丢失
所以就需要一个结构把它们融合起来。
这就是 FPN + PAN 的作用!!!!!!
2.2.1 FPN
feature pytamid network 特征金字塔网络,把高层的语义信息传递给底层特征。
FPN怎么做?
假设 backbone 输出了三层特征:
- 大特征图:分辨率高,适合小目标
- 中特征图
- 小特征图:分辨率低,语义强,适合大目标
FPN 的流程一般是:
自上而下(top-down)
- 从最深层特征开始
- 上采样(upsample)
- 和上一层较浅的特征进行融合(concat 或 add)
- 再继续上采样融合
深层给浅层“补语义”
2.2.2 PAN?
浅层给深层“补细节和位置信息”
因为浅层特征对:边缘 轮廓 位置信息 更敏感,这些信息传回深层后,深层特征的定位能力会更强。
2.2.3 YOLOv5 中 FPN + PAN 的作用
<让不同层特征双向融合,提高多尺度目标检测能力>
YOLOv5 里把两者结合起来,形成一个双向特征融合结构:
- FPN:上采样 + 融合
- PAN:下采样 + 再融合
这样做的结果就是:
优点 1:多尺度特征融合更充分
不同层特征都能互相交流。
优点 2:小目标检测更好
浅层有细节,高层有语义,融合后更适合检测小目标。
优点 3:定位更准
PAN 把底层位置信息往上传,提升边框回归效果。
优点 4:对大中小目标都更友好
YOLOv5 通常会在多个尺度上进行预测。
2.3.6 理解的几个点
- 浅层特征指的是啥?
- “浅层特征”一般指的是 网络前面几层输出的特征图,不一定只是“第一层卷积”,而是靠近输入端的那些层。
- 优点:分辨率高 保留更多的局部细节(边缘 纹理 角点 颜色变化 小目标的局部结构)
- 缺点:语义信息弱 “知道有边,有纹理,但不知道这是人?车?狗?”
- 深层特征指的是啥?
- “深层特征”就是网络后面几层提取出来的特征,靠近输出端。
- 优点:多次卷积,下采样后,分辨率更低,感受野更大,语义更强;比深层特征更容易表达:“这是一个人的整体结构”“这是车的结构”
- 缺点:空间细节变少,小目标,边界,精确位置可能不如浅层清楚
- 上采样
- 通过增加数据点或样本的数量来提高数据的分辨率
- 在深度学习中,尤其是像 YOLOv5 这样的目标检测模型中,上采样通常是在网络的较深层进行的,目的是将特征图的空间分辨率提高,以恢复到接近输入图像的大小。这有助于保留更多的空间信息,使得网络能够更好地识别和定位目标。
- 下采样
- 减少数据点或样本的数量来降低数据的分辨率。yolo v5中用于降低特征图的空间维度,有助于蹭墙语义特征
- 在 CNN 中,逐层进行下采样(例如使用池化操作)会逐渐减少特征图的尺寸,同时增加特征图的深度。这样,网络能够提取更高级别的语义信息,因为每层的下采样都能够压缩并阐明重要特征,减少噪音。
- 靠近输入端
- 靠近输入端的特征: 在网络的输入层,特征图保持较高的空间分辨率,能够保留大量的细节和局部信息。这些特征通常包含丰富的空间信息,比如纹理、边缘等。
- 靠近输出端
- 靠近输出端的特征: 随着信息通过网络的传播,特征图经历了多个下采样层。通过下采样,图像的空间分辨率逐渐降低,虽然网络能够提取更高层次的语义特征(如物体的形状和结构),但高频的空间信息和细节会在这一过程中丢失。
2.2 backbone 网络 Conv层 分组卷积

“groups=g”分组卷积
分组卷积 = 把输入通道分成若干组,每组各自做卷积,最后再把结果拼起来。
核心作用:减少参数量,减少计算量,控制不同通道之间的信息交互方式。
2.2.1 普通卷积和分组卷积的区别
普通卷积:
输入特征图:H × W × C_in 比如:80 × 80 × 16
如果做一个普通卷积,输出通道设为 32,那么意思是:
- 会有 32个卷积核
- 每个卷积核都会看全部16个输入通道
也就是说,每个输出通道都和所有输入通道相连。
你可以把它理解成:
每个输出通道都在“综合分析全部输入通道的信息”。
这就是普通卷积最大的特点:
通道之间完全混合。
分组卷积:
如果设置:g=2
那么 16 个输入通道就会被分成 2 组:
- 第1组:8个通道
- 第2组:8个通道
输出通道 32 也会对应分成 2 组来算,比如每组出 16 个通道。
计算时:
- 第1组输入只和第1组卷积核运算
- 第2组输入只和第2组卷积核运算
- 两组彼此之间不直接卷积混合
- 最后把两组输出拼接起来
核心区别:
普通卷积:
每个输出通道看所有输入通道
分组卷积:
每个输出通道只看自己那一组输入通道
老师把全班分成几个组:
- 1组只能看1组资料
- 2组只能看2组资料
这样每组处理更快,成本更低,
但缺点是:
组和组之间交流变少了。
所以分组卷积的本质就是:
用“限制通道交互”来换取“更低的计算成本”。
2.2.2 为啥能减少计算量?
因为普通卷积里,每个输出通道都要连接全部输入通道。
但分组后,每个输出通道只连接一部分输入通道,所以参数和计算都下降。
2.2.3 分组卷积的优点和缺点
- 优点:更省计算,更适合轻量化部署,可以控制结构设计(有时认为限制通道混合,反而能得到更好的结构效率)
- 缺点:通道之间的信息融合变弱,表达能力可能下降,需要额外模块弥补通道混合(比如配合 1*1 conv 做信息融合)
YOLOv5 在精度和速度之间做了一个平衡,没有极端地全换成分组卷积,普通卷积虽然贵一些,优势:通道混合更充分;语义表达更强;对检测精度更友好
2.3 backbone 网络 Conv层 激活函数 SiLU
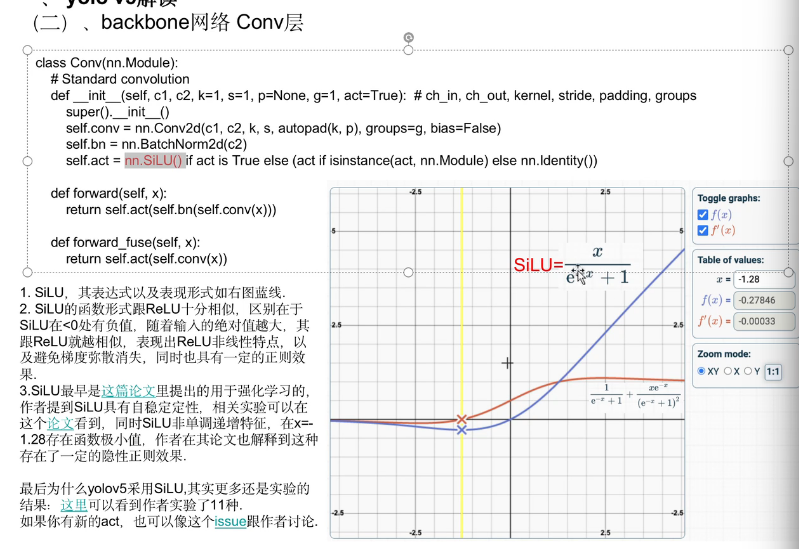
SiLU 像一个“软开关”,负数也有小幅输出,正数被增强,平滑且稳定。
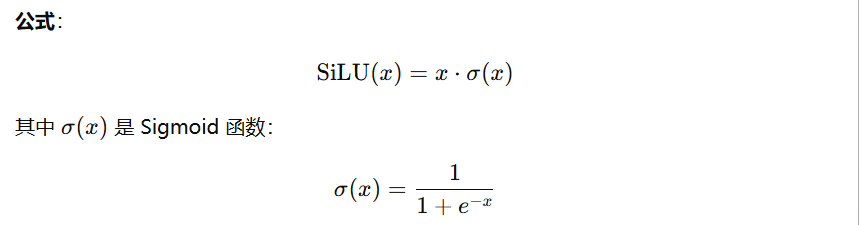
特点:
-
输出值连续光滑,比 ReLU 更平滑,没有硬切断(ReLU 在 0 以下输出 0)。
-
对大正数近似线性,对负数有一定“抑制”,避免负数直接消失(比 ReLU 更温和)。
-
实验表明,在深度网络中,使用 SiLU 能提升收敛速度和准确率。
2.4 backbone网络 C3层

2.4.1 DenseNet的基本思想
DenseNet 的特点是 层间全连接:
-
每一层都会把前面所有层的输出通过 concat 连接起来作为下一层的输入
-
优点:增强特征复用,提高梯度流通性,缓解梯度消失。
-
缺点:随着层数增加,
concat产生的特征维度越来越大,计算量和显存消耗很高。 -
图上:每一层
Dense Layer的输出通过concat与前面所有层的输出连接,再传入下一层。
2.4.2 CSPNet的改进思路:
CSPNet(Cross Stage Partial)是在 DenseNet 的基础上做了 计算优化和速度提升:
- 分割通道:CSP 将输入特征图分成两部分:
-
一部分参与卷积计算(深层特征提取)
-
另一部分直接跳过卷积,保留原始特征
-
-
再合并:最后通过
concat将两部分特征拼接在一起,作为输出。 -
图上:“Partial Dense Block” 表示只对一部分通道做 Dense-like 卷积和
这样可以 减少计算量,同时保持 DenseNet 的梯度优势和特征表达能力。concat;“copy + concat” 表示另一部分通道直接跳过卷积,然后与卷积部分拼接;这样可以 减少计算量,同时保持 DenseNet 的梯度优势和特征表达能力。
速度+精度
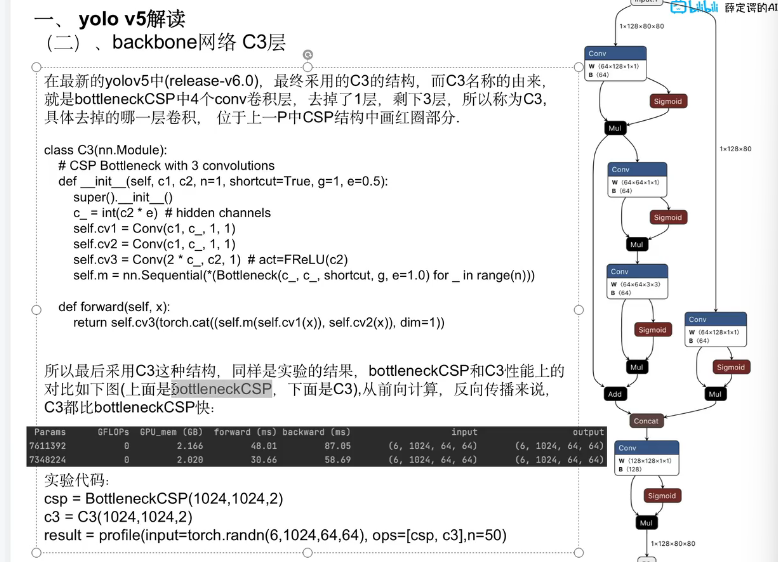
2.4.3 YOLO v5中的c3
不采用通道分离,输入特征全部进入两个分支处理,最后拼接融合
YOLO v5的C3层是全部参与卷积的设计,不是"一半参与、一半不参与"的通道分离方式。这种修改简化了结构,同时保持了跨阶段部分连接(CSP)的思想来提升特征融合效率。
原始CSP: 输入 ─┬─→ [卷积处理] ─┐
├─→ [直接跳跃] ─┤→ 拼接
│ │
└── 通道分离 ───┘YOLOv5 C3: 输入 ─┬─→ [卷积→Bottleneck×n→卷积] ─┐
├─→ [卷积] ───────────────────┤→ 拼接→BN→激活→输出
│ │
└── 全部参与卷积 ──────────────┘
2.5 backbone 网络 SPPF层
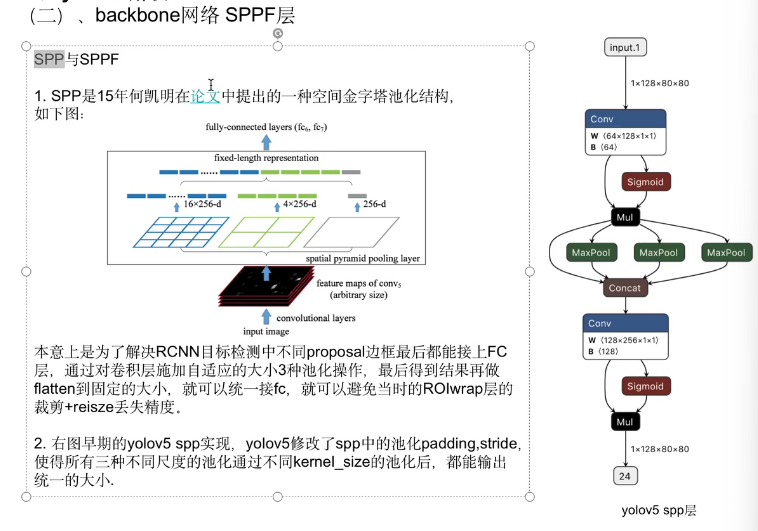
2.5.1 SPP空间金字塔池化
核心问题:传统的CNN都要要求固定尺寸输入,因为全连接层需要固定维度输入。
解决方法:通过 空间金字塔池化(SPP),把不同大小的特征图“压缩”成固定长度的向量,无论输入图是 224×224 还是 512×512,输出维度一样。
SPP解决方案:
输入特征图 (任意尺寸 H×W×C)
│
├──→ 池化核: 1×1 (精细特征) ──┐
├──→ 池化核: 2×2 (中等特征) ─┼→ 拼接 → 固定维度输出
└──→ 池化核: 4×4 (粗粒度特征)─┘
(每个尺度池化后展平,拼接成固定长度向量)补充:啥是池化?
池化就是"压缩"特征图,把局部区域的信息聚合成一个值,降低分辨率但保留关键特征。
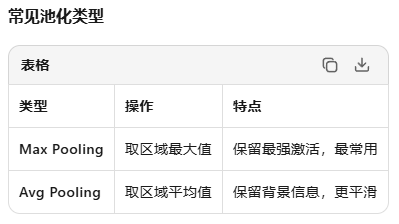
spp是如何做到:固定维度输出的?
层面1:空间维度固定(H×W不变)
通过设置padding,让不同大小的池化核输出相同的空间尺寸。
公式: padding = (kernel_size - 1) / 2
1×1 池化: padding = 0 → 输出尺寸 = 输入尺寸
5×5 池化: padding = 2 → 输出尺寸 = 输入尺寸
9×9 池化: padding = 4 → 输出尺寸 = 输入尺寸
13×13池化: padding = 6 → 输出尺寸 = 输入尺寸
无论输入图像是224×224还是800×600,经过SPP后空间尺寸都一样!
层面2:通道维度固定(总维度固定)
输入特征图尺寸: H×W×C (H,W任意,C固定,如256)
经过4个并行池化:
- 每个分支输出: H×W×C
- 拼接后输出: H×W×(4×C) = H×W×1024→ 最终维度只与C有关,与H,W无关!
为啥要多个池化核同时进行呢?
"多尺度提取防遗漏,Padding固定保维度" —— SPPF让网络既看得全,又接得上。
2.5.2 YOLO中的SPP/SPPF有什么不同?

2.5..2.1 yolo v5中SPPF的位置
YOLO v5 Backbone结构:
输入图像 (640×640×3)
↓
Conv + C3 × 3 (下采样到 80×80)
↓
Conv + C3 × 6 (下采样到 40×40)
↓
Conv + C3 × 9 (下采样到 20×20)
↓
Conv ──→ 【SPPF】 ←── 放在最深层,特征图最小(20×20),通道最多(1024)
↓
输出到Neck (PANet)为什么放这里?
深层特征图小(20×20),计算量可控
通道数多(1024),信息丰富,需要多尺度融合
即将进入Neck做特征金字塔,需要强语义特征
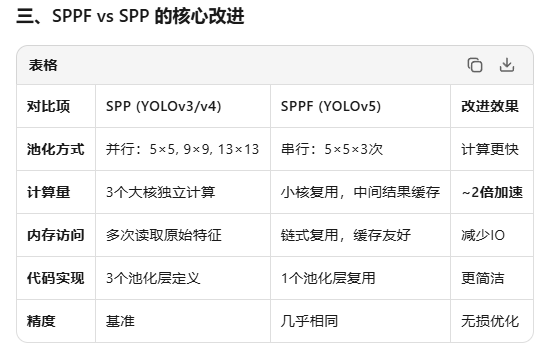
为啥sppf串行甚至更节省时间:?
计算量暴减 + 硬件友好
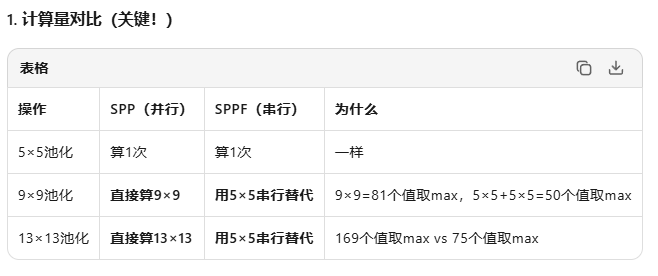
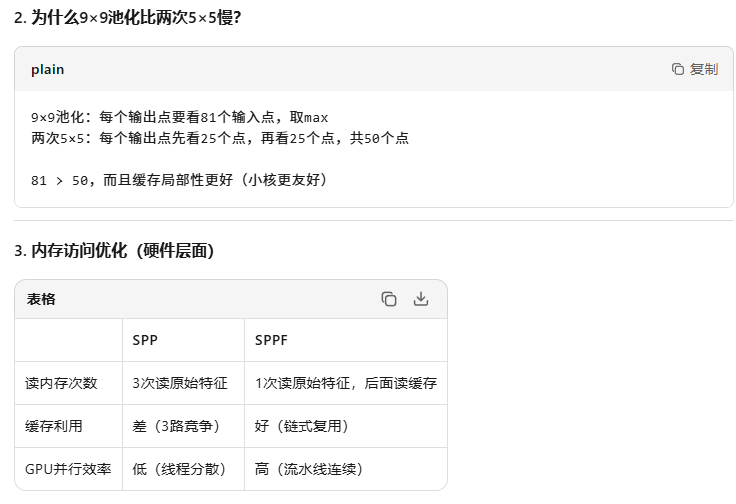
SPPF快不是因为"串行比并行快",而是因为"小核串行比大核并行计算量更少、缓存更友好" —— 用3个小铲子(5×5)替代3把大铲子(5/9/13),挖一样深的坑,但挥铲次数少多了!
3 YOLO V5边框预测细节

3.1 准备阶段(训练前)
1.1 anchor聚类计算
数据集所有GT框的宽高 → K-means聚类 → 9个Anchor
↓
┌──────────┼──────────┐
P3(小) P4(中) P5(大)
80×80 40×40 20×20
【创新点①】:AutoAnchor自动优化
- 不是固定值,根据数据集自适应调整
- 训练前检查,必要时重新聚类
3.2 训练阶段(forword+loss)
2.1 特征提取与检测
输入图像 (640×640×3)
↓
Backbone(CSPDarknet) + Neck(PANet)
↓
三个尺度特征图:
├──→ P3: 80×80×128 ──→ Conv ──→ 80×80×3×85 (255通道)
├──→ P4: 40×40×256 ──→ Conv ──→ 40×40×3×85
└──→ P5: 20×20×512 ──→ Conv ──→ 20×20×3×85
85 = 5(x,y,w,h,obj) + 80(COCO类别)
3 = 每个cell的anchor数量
2.2 预测值解码(训练时也要算 为了算loss)
网络输出:tx, ty, tw, th, to, cls...
【创新点②】:中心点跨cell预测(范围扩展到-0.5~1.5)
bx = 2 × σ(tx) - 0.5 + cx # 相对于grid cell的偏移
by = 2 × σ(ty) - 0.5 + cy【创新点③】:宽高缩放因子(0~4倍)
bw = pw × (2 × σ(tw))² # 相对于anchor的缩放
bh = ph × (2 × σ(th))²最终得到预测框 (bx, by, bw, bh)
2.3 正负样本匹配(关键)
每个GT框 → 找最佳匹配anchor:
Step1: 计算GT与9个anchor的宽高比
Step2: 满足 ratio < 4 且 IoU > 0.2 的anchor为正样本
【创新点④】:跨anchor正样本扩充
- 一个GT可以同时匹配多个anchor(同尺度或跨尺度)
- 甚至一个GT可以匹配到相邻的grid cell(因为中心点范围-0.5~1.5)
- 正样本数量大幅增加,训练更充分传统YOLO:1个GT → 1个anchor
YOLO v5: 1个GT → 最多3个anchor × 多个cell = 更多正样本
2.4 损失计算
总 Loss = L_box + L_obj + L_cls
【创新点⑤】:CIoU Loss替代IoU/GIoU/DIoU
L_box = 1 - CIoU(pred, GT)CIoU = IoU - ρ²(b,bᵍᵗ)/c² - αv
│ │ │ │
│ │ │ └── 长宽比一致性
│ │ └────── 中心点距离惩罚
│ └───────────────────── 重叠区域
└────────────────────────── 基础交并比优势:同时优化重叠度、中心点距离、长宽比
L_obj:置信度损失(BCE)
L_cls:分类损失(BCE)
2.5 反向传播更新权重
Loss.backward() → 优化器(SGD/Adam) → 更新网络参数
3.3 推理阶段(预测)
3.1 前向传播得到预测
输入图像 → Backbone+Neck+Head → 三个尺度预测图
↓
每个位置:tx, ty, tw, th, to, cls...
3.2 解码所有候选框
对每个grid cell的每个anchor:
# 用同样公式解码(和训练时一致)
bx = 2 × σ(tx) - 0.5 + cx
by = 2 × σ(ty) - 0.5 + cy
bw = pw × (2 × σ(tw))²
bh = ph × (2 × σ(th))²
# 置信度得分
conf = σ(to)
cls_prob = softmax(cls)
score = conf × max(cls_prob)
# 过滤低分框
if score > 0.25: 保留
else: 丢弃
3.3 后处理:NMS
输入:大量候选框(如10000个)
↓
按score排序
↓
取最高框,删除IoU>0.45的重叠框
↓
重复直到无框可删
↓
输出:最终检测结果(类别、置信度、x,y,w,h)
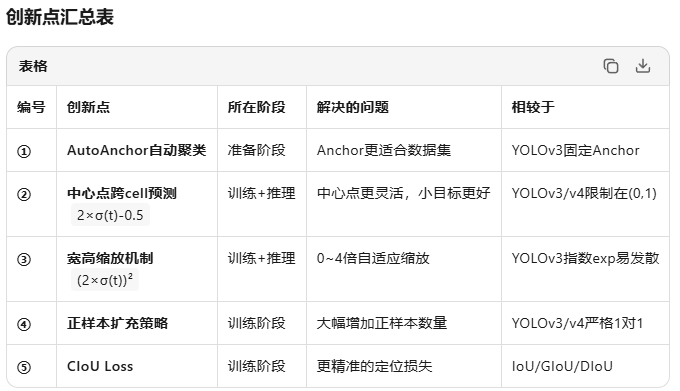
3.4 理解改动
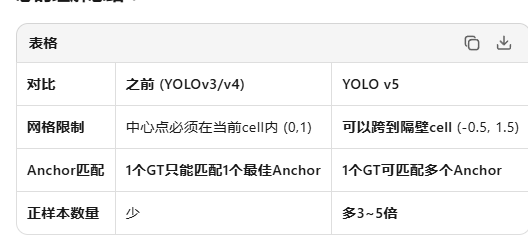
1. grid cell预测范围

什么是offset?
最终中心点坐标 = grid_cell坐标 + offset
比如:
- grid cell (3, 5) 的左上角是 (3, 5)
- 预测框中心 = (3 + offset_x, 5 + offset_y)
YOLOv3的问题:[0,1]限制太死
grid cell (3,5) 的范围:
┌─────────────────┐
│ │
│ (3,5) │
│ ●────────┐ │
│ │ │ │
│ │ 中心 │ │ ← offset只能在[0,1]内
│ │ 可在这 │ │ 即只能在这个小方格内
│ │ │ │
│ └────────┘ │
│ (4,6) │
└─────────────────┘问题:如果物体中心刚好在边界附近,比如(3.9, 5.1)?
它明明离cell(3,5)很近,但v3只能让cell(3,5)预测
或者勉强让cell(4,5)预测,但offset会接近0或1,很难学
四、YOLOv5的改进:[-0.5, 1.5]跨出去
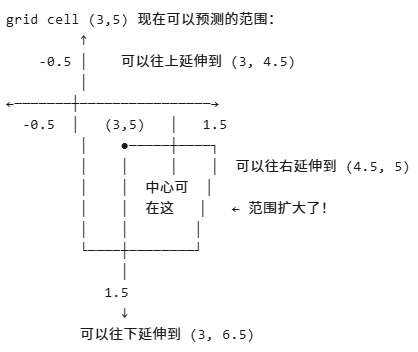
YOLOv3把预测框"锁死"在当前cell内([0,1]),YOLOv5把"锁链"松了([-0.5,1.5]),让预测框可以"探出头"到邻居cell,一个GT能被多个cell同时学习,大大增加了正样本数量!
2. 正采样
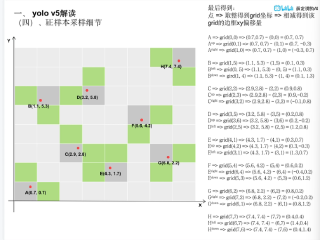
每个GT框(红点)→ 不仅匹配中心所在的grid cell
→ 还匹配上下左右相邻的grid cell(绿色区域)
条件:只要GT框中心到相邻cell中心的偏移量在[-0.5, 1.5]范围内
正样本采样规则总结:
对于每个GT框中心点(x, y):
1. 计算中心grid: (cx, cy) = (floor(x), floor(y))
2. 计算偏移: (dx, dy) = (x-cx, y-cy)
3. 检查4个相邻grid:
grid(cx, cy) ← 自身,一定匹配
grid(cx+1, cy) ← 右边,如果dx > 0.5(靠近右边界)
grid(cx, cy+1) ← 下边,如果dy > 0.5(靠近下边界)
grid(cx+1, cy+1) ← 右下,如果dx>0.5且dy>0.5(靠近右下角)或者更宽松:只要偏移在[-0.5, 1.5]内都匹配(YOLOv5实际做法)
和yolo 3的核心区别:
【YOLOv3】 【YOLOv5】
"一个萝卜一个坑" "一个萝卜多个坑"GT中心(3.2, 5.8) GT中心(3.2, 5.8)
↓ ↓
只属于grid(3,5) 属于grid(3,5) —┐
↓ 属于grid(3,6) ─┼→ 3个正样本
正样本:1个 属于grid(2,5) —┘
正样本:3个
正样本采样的完整流程:
输入:GT框 (x, y, w, h, class)
Step1: 确定尺度
根据GT框大小,匹配到P3(小)/P4(中)/P5(大)某个尺度Step2: 确定anchor(跨anchor匹配)
计算GT与当前尺度3个anchor的宽高比
如果 ratio < 4 且 IoU > 0.2,该anchor为正样本
→ 可能1个GT匹配多个anchor!Step3: 确定grid cell(跨cell匹配)← 重点!
根据中心点(x,y),找到中心grid(cx,cy)
计算到周围4个grid的偏移
偏移在[-0.5, 1.5]内的grid都作为正样本位置Step4: 组合
正样本 = 匹配的anchor × 匹配的grid cell
例如:
- 匹配anchor0和anchor1(2个)
- 匹配grid(3,5)、(3,6)、(25)(3个)
- 总正样本 = 2 × 3 = 6个!
YOLOv5正样本采样 = "跨anchor + 跨cell"双重扩充 —— 一个GT框不再孤单地匹配1个anchor+1个cell,而是可以"左拥右抱"多个anchor、"脚踏多只船"多个cell,正样本数量翻3-5倍,训练更充分,检测更精准!
正样本正采样细节:

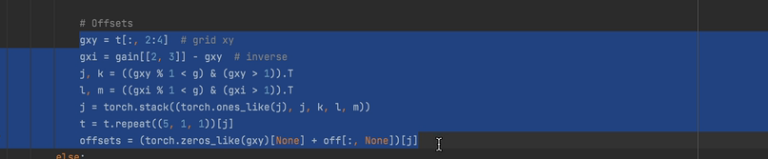
《提高正样本比例的操作》
对于每个GT框:
1. 找最佳尺度(P3/P4/P5)
2. 找匹配的anchor(宽高比<4的)
3. 找匹配的grid cell:
基础:中心grid (cx, cy) 一定匹配
扩展检查(x方向):
- 如果 x%1 < 0.5 且 x > 1 → 左边grid (cx-1, cy) 也匹配
扩展检查(y方向):
- 如果 y%1 < 0.5 且 y > 1 → 上边grid (cx, cy-1) 也匹配
对角:
- 如果x和y都满足 → 左上grid (cx-1, cy-1) 也匹配4. 最终正样本 = 匹配anchor × 匹配gri
用D点(3.2, 5.8)完整走一遍
坐标:x=3.2, y=5.8
尺度:假设匹配P4(中等目标)
Anchor:假设匹配anchor0和anchor1(2个)Grid匹配:
- 中心grid:floor(3.2)=3, floor(5.8)=5 → (3,5) ✓
- x方向:3.2%1=0.2 < 0.5, 3>1 → 左边(2,5) ✓
- y方向:5.8%1=0.8 ≥ 0.5,但5.8靠近6 → 实际代码会检查向下(3,6) ✓假设匹配grid:(3,5), (2,5), (3,6) 共3个
总正样本:2个anchor × 3个grid = 6个预测位置都要学这个GT!
纳入“隔壁邻居”,他要做啥呢?
GT框中心点 → 判断偏向哪个方向 → 隔壁网格的anchor也要学习这个GT
↓
"学习" = 隔壁网格的预测也要负责预测这个GT框
= 隔壁网格也算正样本,参与损失计算具体举例:
GT框中心在 (3.2, 5.8),偏向左边(x%1=0.2 < 0.5)
【原来】只学习 grid(3,5) 的anchor
【现在】还要学习 grid(2,5) 的anchor ← 左边邻居!即:
- grid(3,5) 的3个anchor → 都要预测这个GT
- grid(2,5) 的3个anchor → 也要预测这个GT!正样本从3个 → 6个(如果y方向也满足,可能9个)
究竟要学啥?
训练时:
- 这些被选中的anchor位置 → 算正样本
- 它们的预测框 → 要和GT框算CIoU Loss
- 分类和置信度 → 也要算Loss简单说:一个GT框,多个网格、多个anchor一起学!
4 YOLO v5损失计算的细节
4.1 损失函数演变史:
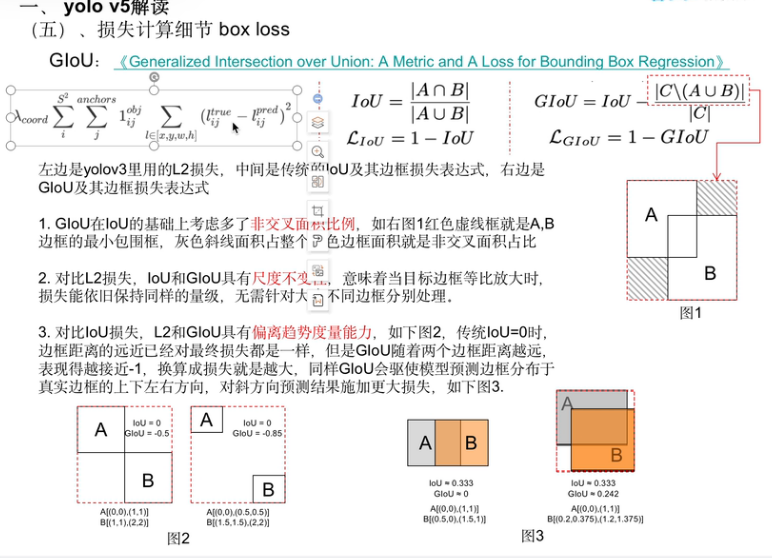
4.1.1 L2损失(YOLO v3早期)
L2 = (x_pred - x_true)² + (y_pred - y_true)² + (w_pred - w_true)² + ...
问题:
- 只算坐标差,不管框有没有重叠
- 大框和小框的"1像素误差"惩罚一样,不公平
4.1.2 ioU损失(考虑重叠)
IoU = 交集面积 / 并集面积 = |A∩B| / |A∪B|
L_IoU = 1 - IoU
优点:直接衡量重叠程度,有尺度不变性
缺点:不重叠时IoU=0,损失恒为1,不知道往哪优化
4.1.3 GioU损失(解决不重叠问题)
GIoU = IoU - |C - (A∪B)| / |C|
C = 包含A和B的最小包围框(图1红色虚线框)
|C - (A∪B)| = C中除了A和B之外的面积(灰色斜线部分)L_GIoU = 1 - GIoU

4.1.4 DioU/CioU(YOLOv5使用)
CIoU = IoU - ρ²(b,bᵍᵗ)/c² - αv
ρ = 中心点距离
c = 对角线距离
v = 长宽比差异惩罚
α = 平衡系数在GIoU基础上,进一步优化:
DIoU = 考虑中心点距离 CIoU = DIoU + 长宽比一致性(YOLOv5用这个!)
4.1.5 总览
场景:预测框A vs 真实框B
【L2损失】
A(0,0,10,10) B(100,100,10,10) → L2很大,但不知道为啥大【IoU损失】
A和B不重叠 → IoU=0 → 损失=1(恒定的,无法优化)【GIoU损失】
A和B不重叠 → 看最小包围框C
- A,B距离近 → C小 → GIoU大(如0.5)→ 损失小
- A,B距离远 → C大 → GIoU小(如-0.5)→ 损失大
✓ 能指导优化方向!【CIoU损失】(YOLOv5)
在GIoU基础上,还考虑:
- 中心点是否对齐
- 长宽比是否一致
✓ 更精细,收敛更快!
YOLOv5用CIoU损失 = "不仅要框重叠,还要中心对齐、形状相似" —— 从L2的"瞎比划",到IoU的"看重叠",再到GIoU的"看距离",最后到CIoU的"全都要",损失函数越来越懂"好框"的标准!
IoU的致命伤:不重叠就是"一刀切"(损失恒为1),距离信息完全丢失;GIoU/CIoU的改进:不重叠也能"量距离",越远惩罚越大,训练有方向!
【IoU的问题】
Epoch 1: 预测框在左上角,GT在右下角 → IoU=0,损失=1
Epoch 10: 预测框靠近了一些 → IoU=0,损失=1
Epoch 100: 还是很远 → IoU=0,损失=1网络:"我一直错得一样多,不知道往哪改!"
【GIoU/CIoU的优势】
Epoch 1: 距离1000 → GIoU=-0.9,损失=1.9
Epoch 10: 距离100 → GIoU=-0.5,损失=1.5 ← 损失变小了!有进步!
Epoch 100: 距离10 → GIoU=-0.1,损失=1.1 ← 越来越近!网络:"损失在下降,我在进步,继续往这个方向改!"

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)