RAG实战:从零开始打造高效AI课程规划系统,解锁MySQL+向量检索的硬核秘籍!
RAG(Retrieval Augmented Generation)
检索增强生成 (RAG) 是一种 AI 框架,它结合了传统的信息检索系统(如搜索引擎或数据库)与大型语言模型(LLMs)的生成能力。
RAG 的核心思想是:
- 检索 (Retrieval): 当用户提出问题时,首先从一个外部的、权威的知识库中检索出与问题最相关的几段信息(上下文)。
- 增强 (Augmented): 将检索到的这些信息作为额外的上下文,与用户原始的问题一起,“增强” LLM 的输入。
- 生成 (Generation): LLM 在这个增强的上下文中生成回答。
RAG优势
- 减少幻觉 (Hallucinations): LLM 倾向于“编造”不存在的事实。RAG 通过提供真实、可靠的外部信息,大大降低了 LLM 产生不准确或虚假信息的可能性。
- 知识时效性:LLM 的训练数据是静态的。RAG 允许你使用最新的数据(例如,你 MySQL 数据库中每天更新的课程信息),而无需重新训练或微调 LLM。
- 特定领域知识:LLM 可能对你的公司内部数据、特定行业的术语或小众知识了解甚少。RAG 使 LLM 能够回答这些特定领域的问题。
- 可追溯性/可解释性: 由于回答是基于检索到的文档生成的,你可以很容易地提供引用来源 (source_documents),让用户知道答案来自哪里,增加了透明度和信任度。
- 成本效益:与耗时且昂贵的 LLM 微调相比,RAG 通常是更经济高效的解决方案。你只需更新向量数据库即可。
RAG实战
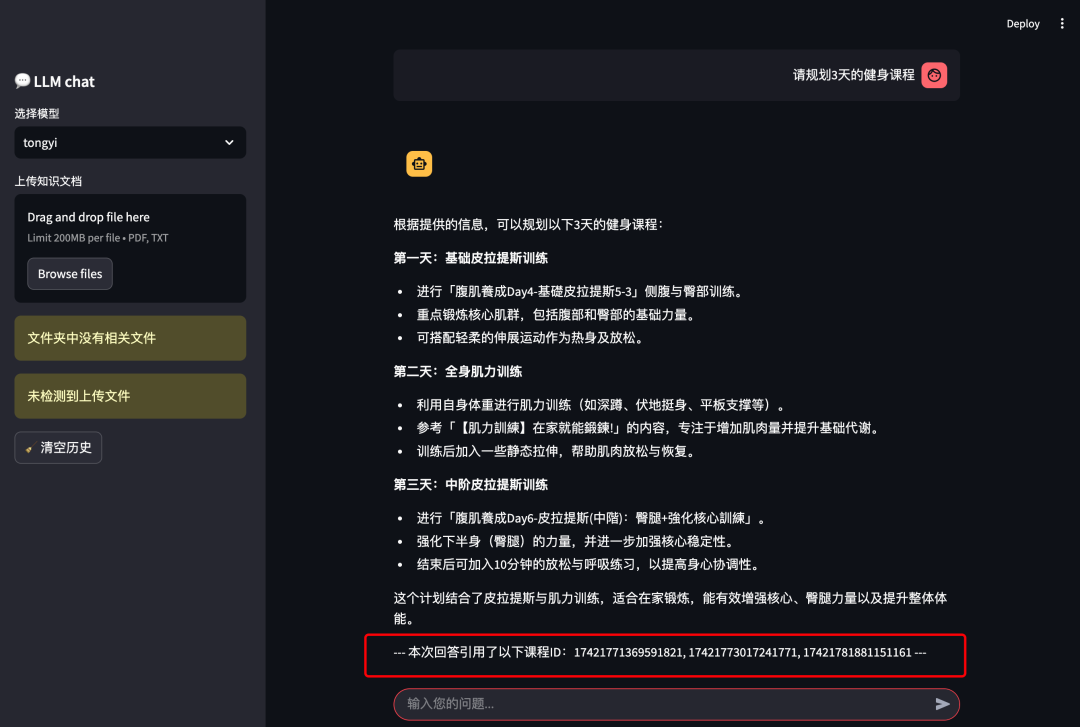
AI课程规划+课程ID
课程ID对应数据库中的, 这些数值AI是不能识别的, 需要增强之后输出。
环境准备
这里用到的包有很多, 主要有这些:
- streamlit
- langchain
- langchain-core
- pymysql
- faiss-cpu
我目前用到的库, 可以选择性复制:
aiohappyeyeballs==2.6.1aiohttp==3.11.13aiosignal==1.3.2altair==5.5.0annotated-types==0.7.0anyio==4.8.0attrs==25.1.0blinker==1.9.0cachetools==5.5.2certifi==2025.1.31charset-normalizer==3.4.1click==8.1.8dashscope==1.22.2dataclasses-json==0.6.7distro==1.9.0frozenlist==1.5.0gitdb==4.0.12GitPython==3.1.44greenlet==3.1.1h11==0.14.0httpcore==1.0.7httpx==0.28.1httpx-sse==0.4.0idna==3.10Jinja2==3.1.6jiter==0.9.0jsonpatch==1.33jsonpointer==3.0.0jsonschema==4.23.0jsonschema-specifications==2024.10.1langchain==0.3.20langchain-community==0.3.19langchain-core==0.3.45langchain-deepseek==0.1.2langchain-openai==0.3.8langchain-text-splitters==0.3.6langsmith==0.3.15MarkupSafe==3.0.2marshmallow==3.26.1multidict==6.1.0mypy-extensions==1.0.0narwhals==1.30.0numpy==2.2.3openai==1.66.3orjson==3.10.15packaging==24.2pandas==2.2.3pillow==11.1.0propcache==0.3.0protobuf==5.29.3pyarrow==19.0.1pydantic==2.10.6pydantic-settings==2.8.1pydantic_core==2.27.2pydeck==0.9.1python-dateutil==2.9.0.post0python-dotenv==1.0.1pytz==2025.1PyYAML==6.0.2referencing==0.36.2regex==2024.11.6requests==2.32.3requests-toolbelt==1.0.0rpds-py==0.23.1six==1.17.0smmap==5.0.2sniffio==1.3.1SQLAlchemy==2.0.39streamlit==1.43.1tenacity==9.0.0tiktoken==0.9.0toml==0.10.2tornado==6.4.2tqdm==4.67.1typing-inspect==0.9.0typing_extensions==4.12.2tzdata==2025.1urllib3==2.3.0watchdog==6.0.0websocket-client==1.8.0yarl==1.18.3zstandard==0.23.0PyMySQL==1.1.1faiss-cpu==1.11.0
当前这里也需要有api-key, 这个langchain框架大部分都支持的。
分步处理
- 外部知识库(mysql)
# src.api.useCourse.pyimport reimport pymysqlimport pandas as pdfrom langchain_core.documents import Documentdef fetch_and_preprocess_data(table_name, course_name, course_id): print("开始查询数据...") # 建立连接 conn = pymysql.connect( host='****', user='****', password='****', database='****' ) try: with conn.cursor() as cursor: # 查询数据 query = f"SELECT {course_name}, {course_id} FROM {table_name} LIMIT 20" cursor.execute(query) data = cursor.fetchall() print("查询结果:") print(data) df = pd.DataFrame(data, columns=['course_name', 'course_id']) # 文本预处理函数 def preprocess_text(text): ifnot isinstance(text, str): return"" text = re.sub(r'<.*?>', '', text) # 去除HTML标签 text = re.sub(r'\s+', ' ', text).strip() # 压缩空白符 return text df['cleaned_text'] = df[course_name].apply(preprocess_text) print("✅ 数据预处理完成。") # df.to_csv('data.csv', index=False) return df except Exception as e: print(f"❌ 查询或预处理MySQL数据失败: {e}") return pd.DataFrame() finally: if conn: conn.close()def getMysqlDocuments(): # 示例:从 'tb_course' 表中提取 'course_name' 字段 mysql_data_df = fetch_and_preprocess_data('tb_course', 'course_name', 'id') ifnot mysql_data_df.empty: documents = [] for index, row in mysql_data_df.iterrows(): # 确保文本和ID有效 if pd.notna(row['cleaned_text']) and row['cleaned_text'].strip() and pd.notna(row['course_id']): doc = Document( page_content=row['cleaned_text'], metadata={ "course_id": str(row['course_id']), # 建议将ID转换为字符串 "original_content": row['course_name'] # 存储原始内容,方便后续追溯 } ) documents.append(doc) if documents: print(f"✅ 成功构建 {len(documents)} 个 LangChain Document 对象。") print("\n第一个 Document 示例:") print(documents[0]) else: print("⚠️ 没有有效的 Document 对象可供处理。") return documents
- 检索组件(embedding)
- 加载mysql或者CSV文件
# load-file.pyfrom langchain_community.document_loaders import PyPDFLoader, Docx2txtLoaderfrom frontend.components.sidebar import check_csv_in_folderimport streamlit as stfrom src.api.useCourse import getMysqlDocumentsdef load_file(): all_docs = [] load_files = check_csv_in_folder() mysql_docs = getMysqlDocuments() print(load_files)if len(load_files) == 0 : st.warning("未检测到上传文件")else: for file in load_files: file_path = f"/data/raw/{file}" # 加载 PDF 文件 pdf_loader = PyPDFLoader(file_path) pdf_docs = pdf_loader.load() all_docs = all_docs + pdf_docs# 合并所有文档return all_docs + mysql_docs
- 数据清洗
# transform-file.pyfrom src.model_manage.load_file import load_filefrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_core.documents import Document# 过滤和清洗def clean_text(doc): # 示例:移除多余的空格和换行符 cleaned_content = doc.page_content.replace("\n", " ").strip() # 保留原始元数据(可选) return Document(page_content=cleaned_content, metadata=doc.metadata)# 文本转换def transform_data(): # 加载文件 docs = load_file() if docs isNone: returnNone # 分块处理 text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每块文本的最大长度 chunk_overlap=50, # 块之间的重叠长度 length_function=len ) split_docs = text_splitter.split_documents(docs) # 清洗文本 cleaned_docs = [clean_text(doc) for doc in split_docs] return cleaned_docs
- 向量化处理
# embedding.pyfrom langchain_community.embeddings import DashScopeEmbeddingsfrom langchain_community.vectorstores import FAISSfrom src.model_manage.transform_file import transform_data""" 向量化文本数据 @author: petter"""def embedding_data(): cleaned_docs = transform_data()if cleaned_docs isNone: returnNone# 向量化文本 embeddings = DashScopeEmbeddings( model="text-embedding-v2", )# 生成向量数据库 vector_db = FAISS.from_documents(cleaned_docs, embeddings)# 保存到本地(可选) vector_db.save_local("faiss_index")return vector_db
- 增强/上下文注入
import streamlit as stfrom langchain.chains import RetrievalQAfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandlerfrom langchain_core.runnables import RunnableLambdafrom operator import itemgetterfrom src.model_manage.embedding import embedding_datavector_db = embedding_data()# 模型初始化# --------------------------@st.cache_resourcedef get_model(): """初始化并缓存DeepSeek模型""" qa_chain = RetrievalQA.from_chain_type( llm = 大模型名称, chain_type="stuff", # 上下文检索 retriever=vector_db.as_retriever( search_type="similarity", search_kwargs={"k": 3} # 检索最相似的 3 个文档 ), return_source_documents=True, ) return qa_chain
- 生成组件
def generate_stream_response(prompt): """生成流式响应内容""" model = get_model() # 流式响应数据增强 final_chain = model | RunnableLambda(postprocess_ai_response) chain = final_chain.invoke({ "query": prompt }) try: for chunk in chain: yield chunk except Exception as e: yield f"⚠️ 请求失败:{str(e)}"
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)