OO-U1单元总结
一、基于度量的架构分析
先展示各类以及其规模:
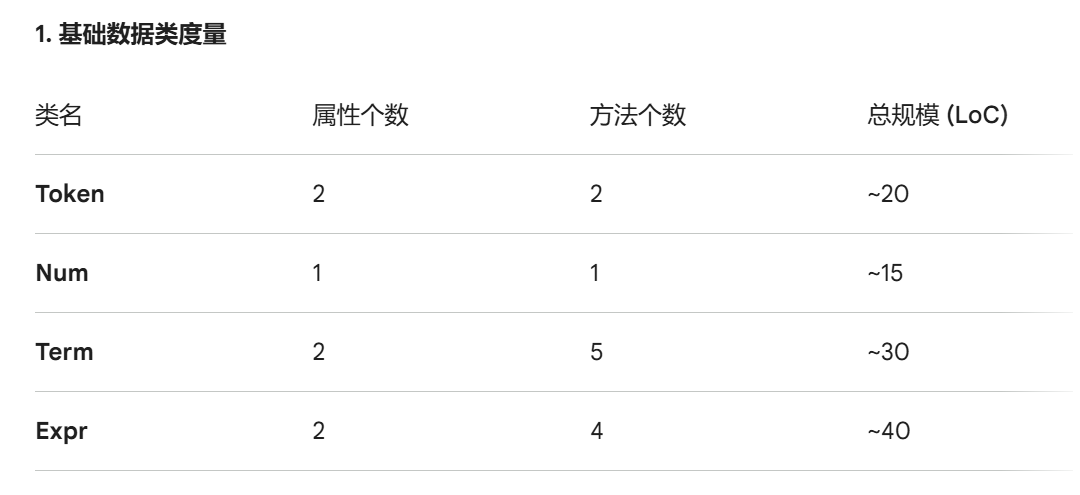

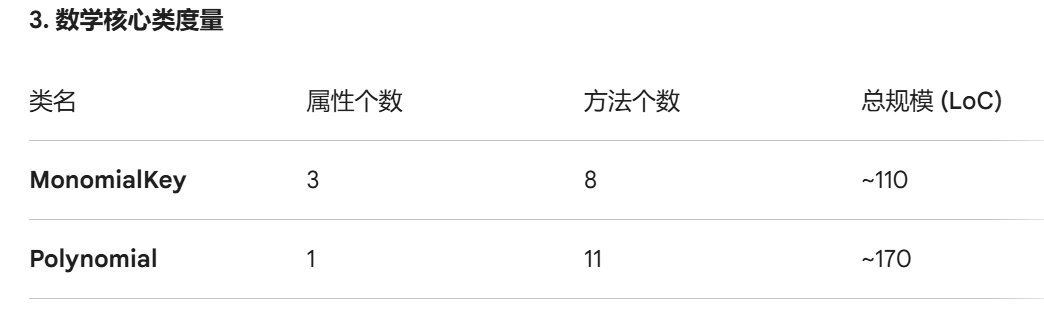
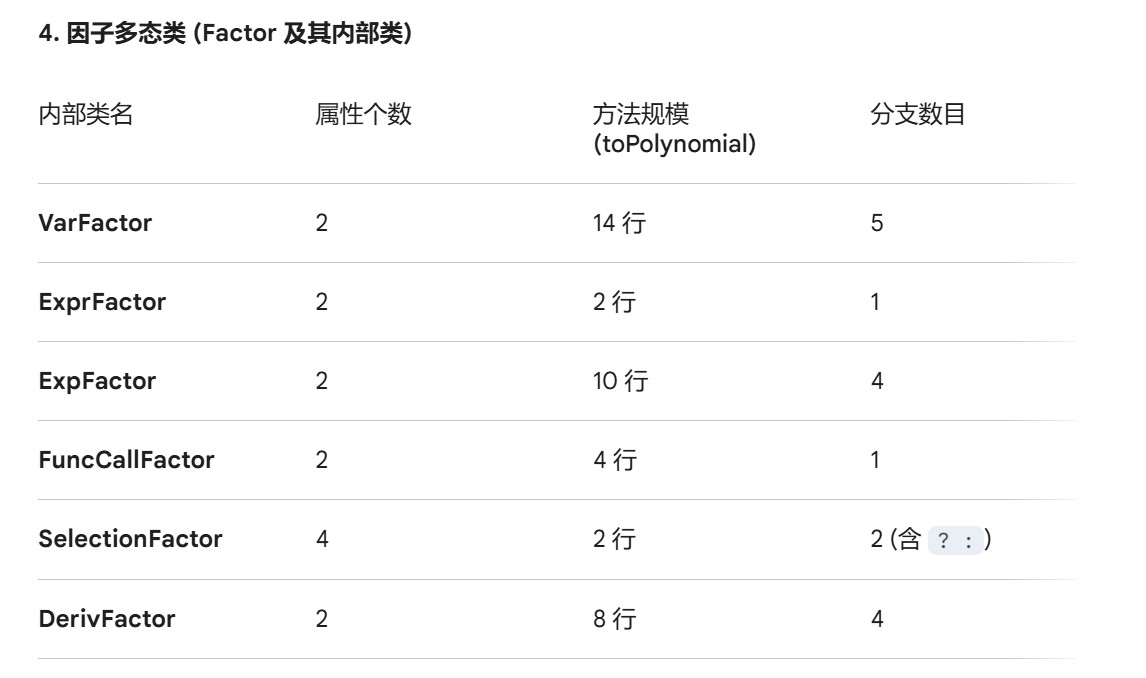
然后逐层逐类分析:(基于个人理解,有可能不对)
首先是明确计算的原子单元,以及单元的运算规则——
第一层,原子层
- MonomialKey(单项式key):核心抽象。针对 “x^n*y^n * exp (P)” 的结构,封装xxPower(x 的幂次)yyPower和expInner(exp 的内部多项式),并定义:
- 乘法规则:幂次相加、expInner 相加(利用 exp (A)*exp (B)=exp (A+B));
- 合并规则:exp (0)=1 时消除 exp 因子;
- 排序 / 相等规则:在比较完 x 的幂次后,加入对 y 幂次的比较判定;
- 字符串格式化规则:控制 “x^2*exp (x)” 这类输出的可读性。
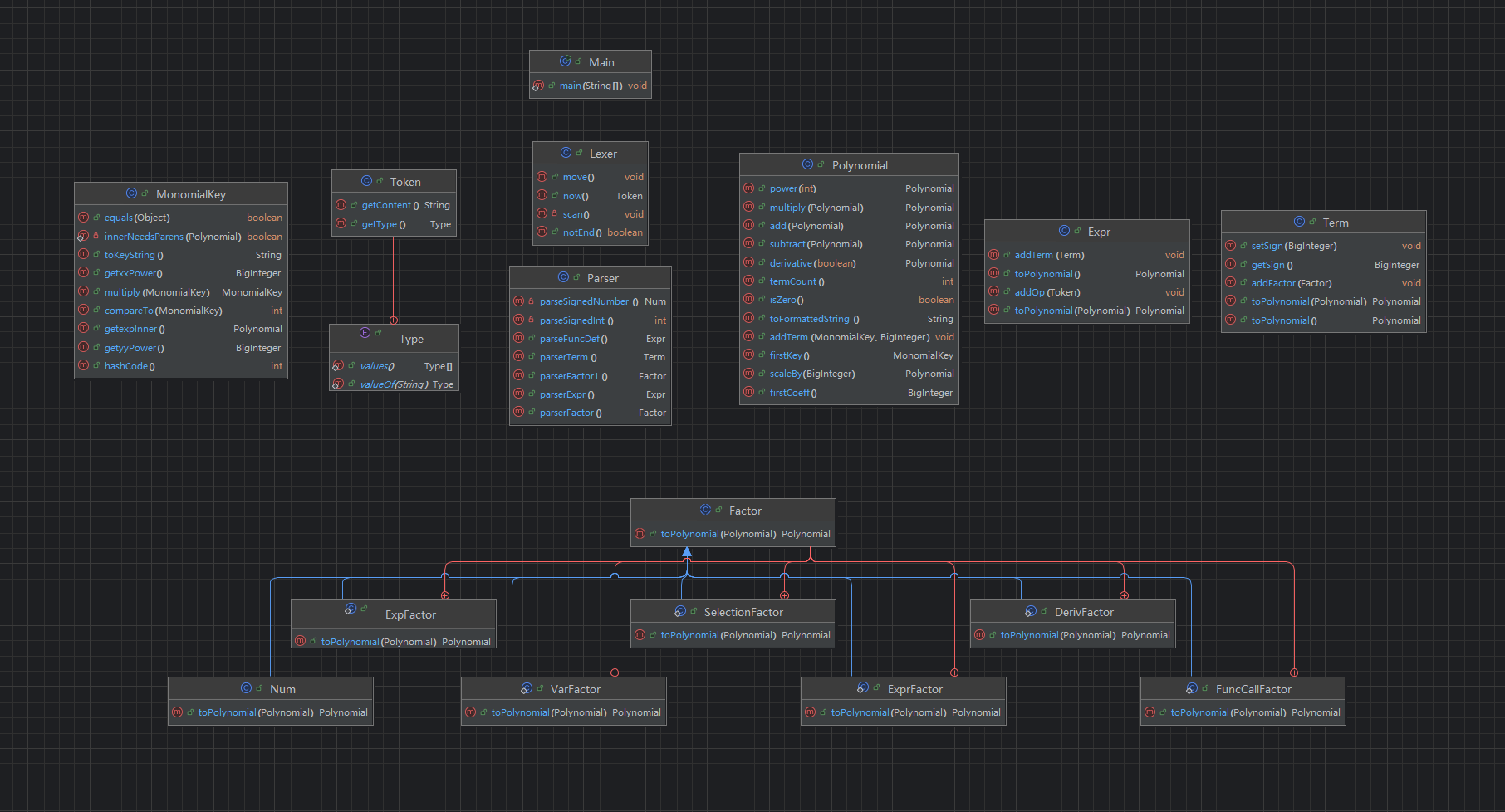
第二层,因子层,考虑原子单元的组合,解决不同类型因子统一计算的问题——基于底层原子抽象出 “因子” 这一概念,并分类实现。Factor 作为抽象基类,定义了所有因子类型的统一接口规范,声明抽象方法 toPolynomial(Polynomial xsub),要求所有静态内部子类实现 。其中参数 xsub 为变量 x 的替换多项式(null 表示不替换,保留原始变量 x),用于函数调用场景下的变量代入操作。静态内部子类的实现逻辑如下(为简化blog仅举两例,嗯):
- Factor.VarFactor:表征变量因子 xⁿ,构造时传入指数 exponent,实例化为 Factor.VarFactor 类型对象。其 toPolynomial 方法根据入参 xsub 是否为 null 分支处理:若为 null,直接生成 x^exponent 多项式;若不为 null,则将 x 替换为 xsub 后执行幂运算并返回结果多项式。
- Factor.ExprFactor:表征表达式幂次因子 (expr)ⁿ,构造时传入表达式 Expr 实例及指数 exponent。其 toPolynomial 方法逻辑与 VarFactor 一致,先将内部表达式转换为多项式(代入 xsub),再执行指定次数的幂运算。
第三层,项(Term),因子相乘的形式。以BigInteger实现多层符号的统一管理,展开所有因子实现toPolynomial功能,得到多项式。表达式(Expr),项的合并。
第四层,解析词法:
Token(词法单元):通过Token枚举所有语法元素(+、-、*、^等),是构建 “语法树” 的第一步,解决 “如何把输入字符串拆成可识别的最小语法片段”的问题。Token 类包含type和content两个核心属性,需预先枚举type的所有合法取值以支撑后续词法类型归类。对外提供getType()和getContent()两个公共访问方法。
Lexer 类作为词法分析器核心实现类,其scan()方法通过逐字符扫描输入文本完成词法单元(Token)的解析(注意跳过空白字符‘ ’以及‘/t’),并将解析后的 Token 实例逐一存入 tokens 列表;类内部维护tokenPos私有属性,用于标识当前 Token 的读取游标位置;notEnd()方法用于校验 tokens 列表是否仍有未读取的 Token,now()方法返回当前 Token 的读取游标位置,move()方法则将tokenPos游标向后移动一个单元。
Parser 类接收 Lexer 完成词法分析后的完整 Token 流上下文,通过调用 Lexer 暴露的公共访问接口,跳过语法无关的格式类 Token,并采用递归下降解析法逐层调用解析方法构建抽象语法树(AST)。下面举例一个方法:
- parserFactor()方法:返回对应类型的 Factor 实例,根据读取到的首个 Token 类型(+、-、数字、x、左括号、exp、f、左方括号等)判定因子类型,跳过冗余的语法格式 Token,依据规约文档定义的语法结构(固定位置的表达式 / 项 / 因子),递归调用对应的解析方法完成因子解析;
第五层, Polynomial 类(核心运算): 实现了项的化简addTerm,加法add,乘法multiply,幂次power,求导 derivative等...其中求导遵循微积分的乘法法则与链式法则;通过递归调用内层多项式的求导,将复杂的嵌套求导化简为简单的多项式加法和乘法。最后,将表达式化成最后的输出样式的方法为toFormattedString。
Main 层作为程序的入口类,负责处理输入输出,调用其他类方法实现功能。
综上所述,以上分层结构可保证每一层专注自己的功能,再进行拓展就只用修改相应部分,这符合作业中高内聚,低耦合的要求。
优点:可拓展性较好,后继添加因子和方法比较容易。
缺点:也许factor做接口会比做继承好些。有些设计过于冗长丑陋。
二、出现的bug:
第一次作业无显著bug;第二次作业bug出在指数幂误设为int类型。第三次作业bug出在exp内层是否应该添加括号上。
三、寻找别人的bug:
舍友采取了白箱测试,将他人代码放到自己构建的测评机寻找hack数据;我则是根据题意自行构造黑箱样例;
从结果上来看舍友的方法效果更好。我只在第二次,第三次作业找到别人的一处bug。被找到的bug都只是因为处理不了fx,exp迭代过多的情况。
四、架构设计体验:
其实一开始我参考课程组提供的lexer,parser建立基本的文法解析架构的时候没考虑过用mono类作为单项式加入key,而是直接用treemap存的xxpower,expinner。
后来我在思考如何避免多层嵌套,把问题丢给了ai,使它帮我想出来的,mono类存放项的幂指数,以及将exp(A)^B转化为exp(C)样式的式子后将C存入类。
后来又多了选择式因子;函数解析式解析,就分别设置一个专门的factor子类处理,再重写toPolynomial方法解决。后来的求导因子也是如此,不过还要在多项式类中再设置一个计算的方法。不过自定义递推函数则是利用DP方法,在main输入时就将前五项计算存下,之后就直接调用即可。
五、LLM使用体验
大模型非常好用,如果作业没思路问ai,甚至可以将作业完整写完发一版代码给你。不过基本上都会有些瑕疵,而且根据提示词不同,ai代码也是良莠不齐。
一些想新实现的方法也可以叫它写一遍,过目一边检查没有离谱错误基本就能添加进工程。
六、心得体会
一开始写的时候就觉得,真恶心,感觉啥都不会,寒假过去java全部还给老师了,更别说第一次作业就要求设计一个比较完整的文法解析的工程,要不是加油站的补充资料简直毫无头绪。
后来好不容易写完第一次作业了,当然,离不开大模型的倾情教学,教我怎么设置类,类里应该写什么,怎么继承,为什么要继承......结果后来第二次作业更恶心了。
我甚至以为要重构了,完全不知道怎么把exp加进来。后来也是AI教的,弄了一个单项式类存关键值后再treemap。最后也是勉强过了公测。
第三次作业不用怎么改原来的架构,只是添加了几个因子,计算方式,但是公测由于疏忽依旧有bug。
关于这坨东西是如何制造出来的呢......作业迭代我最喜欢写的就是token,lexer和parser了,其他类写的怎么写怎么错,后面实在没眼看就直接问ai了。我也不知道是否有好一点的架构,至少不用像这样自己读一遍才能讲出来一二。不过看了几个b房的同学,发现更看不懂,所以不了了之了。
几次作业我实现同类项合并后完全没有优化,三次都进的b房。其实感觉为了得分添加诸如,将正项提到开头这种功能挺没意思的。不过只是为了维持体面的分数这些也足够了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)