GPT系列发展史:从GPT-1到GPT-5,看AI语言模型的飞跃式进化!
本文回顾了GPT系列模型的发展历程,从GPT-1开创预训练+微调范式,到GPT-2验证零样本学习,再到GPT-3以1750亿参数规模引领大模型时代,GPT-4引入多模态处理,GPT-5在编码、写作及长上下文理解上表现卓越。文章重点阐述了各代模型的技术突破和性能提升,以及幻觉问题与改进措施,展现了AI语言模型在深度与广度上的飞跃。
GPT(Generative Pre-trained Transformer)

GPT-1:开创预训练+微调的范式
在2018年OpenAI推出了GPT1模型,GPT-1是基于生成式预训练的transformer架构,采用了decoder only,也就是解码器only的模型,专注于预测下一个单词,GPT-1包含1.17亿个参数,采用了无监督预训练和有监督微调的方法,以增强模型的通用问题求解能力。
GPT-1的模型主要包含两个阶段:预训练和微调
预训练:在大量无标签的数据上训练模型,以学习通用的表示和知识。
微调:在特定任务的有标签数据上对预训练模型进行调整,以适应该任务的需求。
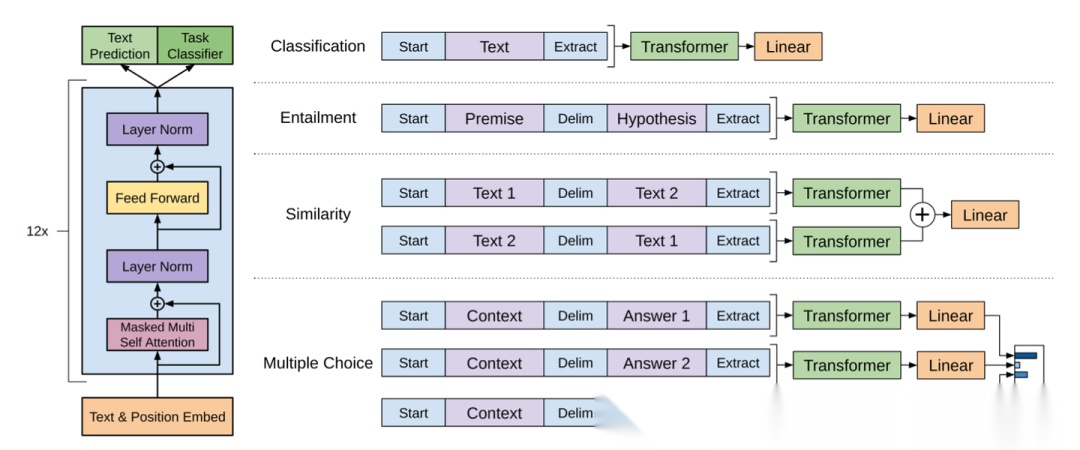
论文里分别展示了模型的架构和后续微调时不同任务的处理方式:
GPT-2:证明零样本学习,Zero-shot打破传统任务的微调限制
GPT-2继承了GPT-1的架构,并将参数规模扩大到了15亿,使用大规模的网页数据集进行预训练,与GPT-1相比,GPT-2的创新之处在于尝试通过增加模型的参数规模来提升性能,同时去除了对于特性任务的微调环节(使用零样本学习Zero-shot Learning),探索使用无监督预训练模型来解决多种下游任务,无需显示的进行标注和微调。
GPT-2继续沿用在GPT-1中使用的单向Transformer模型,区别在于GPT-2使用了更多的网络参数和更大的数据集,以此来训练一个泛化能力更强的词向量模型,GPT-2相比于GPT-1有如下几点区别:
主推zero-shot,而GPT-1为预训练+微调
模型更大,参数量达到了15亿,而GPT-1只有1亿
数据集更大,WebText数据集包含了40GB的文本数据,而GPT-1只有5GB
训练参数变化,batch_size从64增加到512,上下文窗口大小从512增加到1024
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其他类别任务中而不需要额外的训练。
GPT-3:首个规模达到175B的大模型
OpenAI在2020年推出了具有里程碑意义的GPT-3模型,其参数规模达到了1750亿,标志着对模型扩展规模的极限尝试,GPT-3.5作为GPT-3的升级版,在语言处理的复杂度和细粒度上有了显著的提升,它在文本生成语义理解的能力,使其在学术研究和内容创作方面大放异彩。
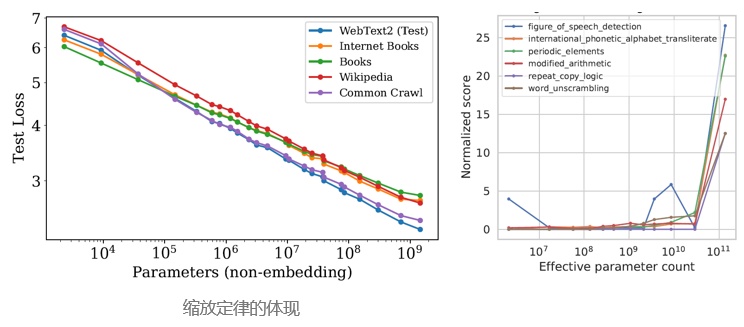
few-shot prompting的涌现能力主要体现为模型在没有达到一定规模前,得到的表现较为随机,在突破规模的临界点后,表现大幅度提升。在GPT-3的规模突破2*10²²Training FLOPs(13B参数),模型的表现开始快速上升。
GPT-4:多模态大模型
在2023年OpenAI发布了GPT-4,首次引入了多模态的模型,GPT-4在解决复杂任务的能力显著强于GPT-3.5,在面向人类的考试中取得了优异的成绩。

GPT-4的关键能力:
1、模型能力可预测:为了避免模型粒度的繁琐微调,规避巨额的试错开销,OpenAI构建了稳定的、可扩展的训练框架和优化方法(Predictable Scaling),通过千分之一的计算开销实现了扩展预测。
2、多模态的处理能力:通过多模态Transformer多模态大语言模型和多模型的组合方式,实现多模态的处理。
3、更强的上下文理解长度:GPT-4(32k)支持最大上下文长度为32K,是ChatGPT上下文长度的8倍。
GPT-4的局限性:幻觉
大型语言模型会产生幻觉,幻觉是指生成的文本中的语义或句法上看似合理但实际上不正确或无意义的错误。
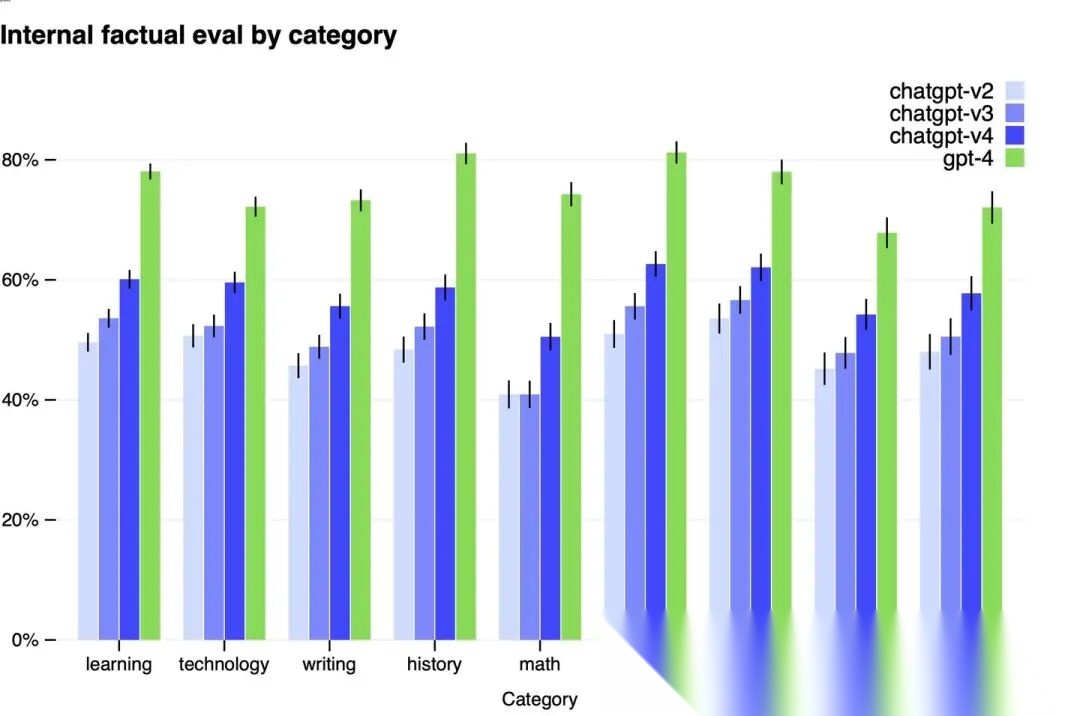
在内部对抗性事实评估测试中,GPT-4 相比于上一代 GPT-3.5 提高了 19% 的准确率(相对 40% 的提升),显著减少了幻觉(不真实的或自相矛盾的生成内容,“自信地胡说八道”),但幻觉依旧存在,所以在一些高风险领域(如医疗、金融)中,需要进行额外的人工审查或者完全避免使用。
GPT-5:大语言处理能力与深度推理功能
该模型支持编码、写作、多模态输入及长上下文理解,提供自动切换响应模式与个性化交互选项,适用于编程、数学推导和健康咨询等领域。
编码能力:在从GitHub获取现实世界编码任务的基准测试SWE-bench Verified中,GPT-5思考后首次尝试的准确率达74.9%,高于OpenAI推理模型o3的69.1%和GPT-4o的30.8%,略高于Anthropic的Claude Opus 4.1。早期测试者注意到其在间距、排版和留白等设计选择方面的改进。
幻觉降低:GPT-5相比此前的模型更可靠和实用,它能更准确地回答现实世界的疑问,出现幻觉的可能性显著降低。GPT-5在HealthBench Hard Hallucinations测试中错误信息率仅为1.6%,远低于GPT-4o的15.8%,GPT-5响应中包含事实错误的可能性比GPT-4o低约45%;深度思考模式下,事实错误率则比o3降低80%,GPT-5响应的错误信息率仅为4.8%,GPT-4o为20.6%,o3为22%,GPT-5变得更加准确和可靠;在开放性事实准确性基准LongFact和FActScore测试中,GPT-5的幻觉率比o3减少大约六倍,长篇内容生成的准确性显著提升。
超长能力:GPT-5具有达到400K的超长上下文能力,这对长文档检索与跨文件代码修改更友好,虽然相比Gemini 1M(谷歌旗下产品)的上下文量还有距离,但于其他对手而言,已算是领先一步。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献126条内容
已为社区贡献126条内容

所有评论(0)