千问 vs. DeepSeek:好模型的表征为何“殊途同归”?诠信全译从数学机理揭示大模型本质
当大模型的能力日益强大,一个根本性问题愈发凸显:我们究竟如何判断一个模型是“真的好”?传统的榜单评测可以被应试攻克,用户的主观体验又难以量化。在这一背景下,诠信全译基于其开创的“等效与或交互”理论,提出了一种从数学机理层面评估大模型表征质量的全新方法。
该方法不再依赖海量测试数据的间接评测,而是通过分析模型在单个样本上建模的交互逻辑复杂度分布,直接判断其泛化能力。运用这一技术对比当前两大主流模型——千问和DeepSeek,诠信全译发现了一个关键现象:优秀模型的表征会“殊途同归”,而潜在缺陷则隐藏在那些难以泛化的噪声交互之中。这一发现为理解大模型的本质提供了全新的数学视角。

1.背景
长期以来,人们对大模型存在一个认知误区,认为只能借助外部测试手段进行间接的黑盒评测,而难以从原理层面直接把握大模型的表征质量,以及其所建模知识与逻辑的正确性。
而我们所提出的这项新技术,成功打破了这一困境。
经研究证明,在大模型生成句子时,,其输出一个词素(Token)的置信度得分,能够以“与或交互”逻辑的形式进行解释。具体而言,给定一个输入句子,我们证明大模型仅仅能够建模少量的(比如100个左右)在输入单词之间的交互关系。其中,每个交互关系对应一个与或逻辑运算,并贡献出一定的数值得分。可以证明神经网络整体的输出置信度可以用这些交互的得分来精确拟合出来。给定一个输入句子,我们可以穷举对输入单元的全部可能的遮挡状态,无论如何遮挡输入单元,可以证明这个与或交互逻辑模型依然可以精确拟合出神经网络在指数级遮挡变化下的各种输出。
这一发现为理解大语言模型的决策机制提供了根本的理论保障——它确保了用简洁的符号化逻辑解释神经网络,不再停留在工程性拟合阶段,而是在理论上保障了解释数值的严谨性。
2.科学评估大模型的泛化能力
从这一全新视角出发,我们得以直接从大模型所建模的细节交互逻辑的层面来评估大模型的泛化能力。因为神经网络的输出置信度可以表示为输入单词间不同交互逻辑的数值效用之和,所以我们能够通过直接量化不同交互逻辑的泛化形,从而推断出大模型整体的泛化性。可泛化交互逻辑特指能够通过迁移到测试样本中激活,并辅助模型对该样本分类的交互逻辑。
更重要的是,通过观察神经网络中可泛化的交互逻辑和不可泛化的交互逻辑,我们发现并部分证明了可泛化的交互逻辑和不可泛化的交互逻辑往往在交互阶数方面服从不同的分布。交互的阶数指参与交互的输入单词的数量,即交互的复杂度。可以泛化的交互通常呈现"衰减型"分布特征:大部分可泛化交互都属于简单、低阶的交互逻辑,而复杂度稍高的交互逻辑的数值效用会随着复杂度增加呈指数级下降。相比之下,不可泛化的交互则表现出"纺锤形"分布特征,其中中等复杂度的交互占主导地位,但其数值效用会正负抵消。特别值得注意的是,神经网络通常很少建模极简单和极复杂的不可泛化交互。
上述技术彻底绕开了传统端到端黑盒测试的框架,因为它表明我们可以直接通过分析神经网络在单个样本上的交互复杂度的分布,来直接判断其泛化能力,而不再需要像传统方法那样必须用大量测试集来评估网络性能。这代表着一种重要进步——我们可以更高效地评估和理解神经网络的泛化特性。
3.对比两个主流大模型
这里,我们来对比两个主流大模型:DeepSeek和千问。deepseek-r1-distill-llama-8b是80亿参数的模型,千问qwen2.5-7b有70亿参数,参数量相差不大。
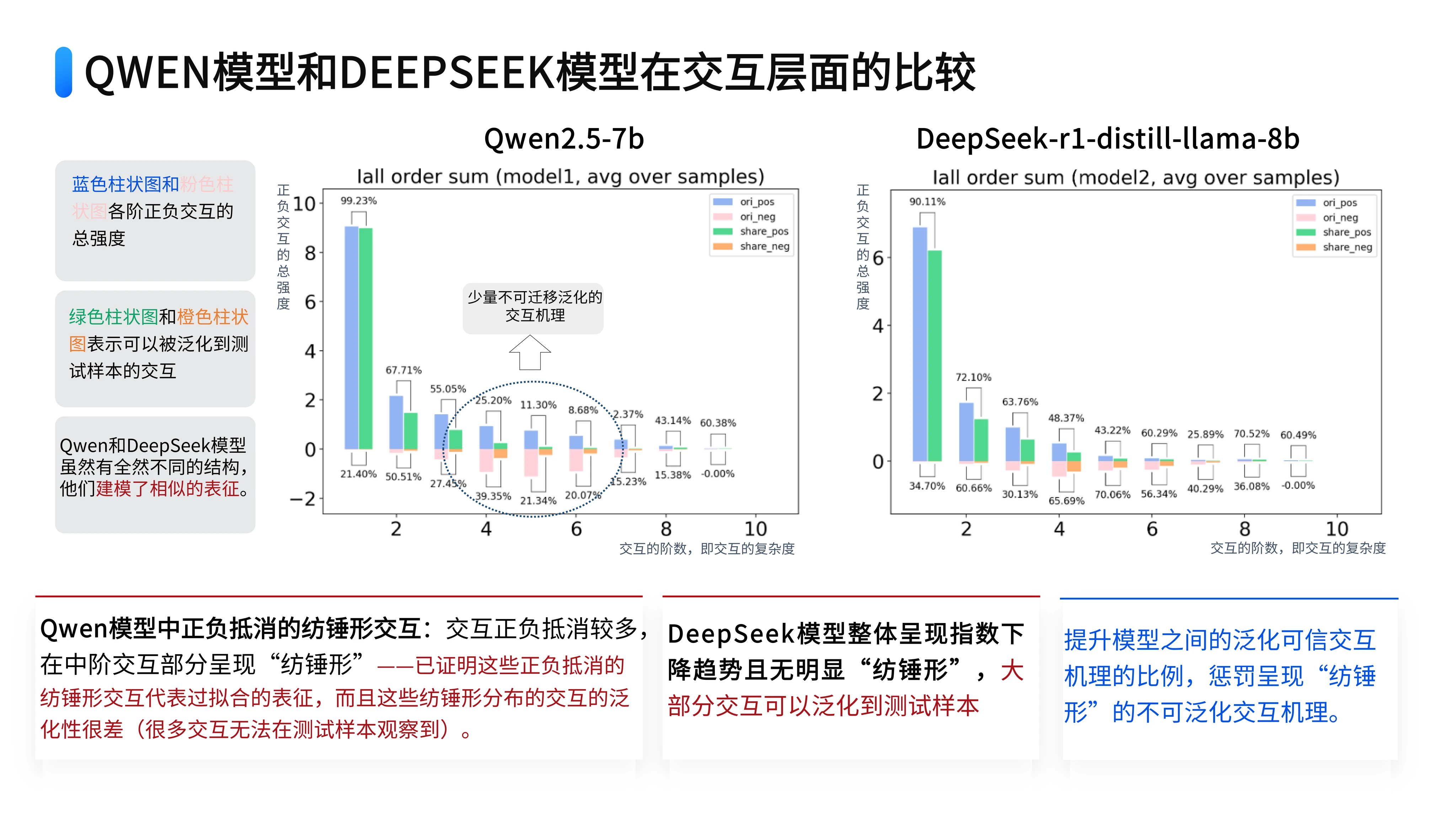
我们经过测试发现,当输入相同内容时,两个模型所建模的交互逻辑有很高的相似度。具体表现有两大特点:
⭐️ 第一、两个模型对相同输入产生的交互逻辑大部分是重合的。也就是说,DeepSeek所建模的大量显著交互逻辑,前文往往也建模了;反过来也成立。
⭐️ 第二、我们的算法从交互复杂度分布角度揭示了相比于DeepSeek 8b模型千问7b模型的潜在缺陷。
千问7b模型比DeepSeek 8b模型多建模了一些"纺锤形"难以泛化的交互逻辑,即一些数值上相互抵消的中等复杂度的交互效用,有理论证明这往往表示一些过拟合的噪声。相比之下,DeepSeek建模的大部分交互往往都是可以泛化的,不同交互间的正负抵消效用也小很多。
基于这个发现,我们找到了一种新方法来评估大模型的性能。以往需要用海量数据测试,现在只需通过少量样本分析其内在交互的复杂度分布,就能判断模型的泛化能力。这种评估维度能更科学地反映模型的真实水平。
造成这些难以泛化交互的原因有很多种,当然每一种原因都可以在数学上给出确切的分析和溯源,有些需要在特定数据集上延长训练时间,有些需要减少训练时长而增加样本第一性,有些需要数据清晰,都是可以从机理层面得到解析的,这里就不多赘述了。
🔥 【立即预约机理诊疗】
无论您是受困于高昂的训练成本,还是急需为高风险业务线引入可靠的AI能力,欢迎联系诠信全译:
📧 诠信全译商务合作:contact@symtrustai.com
🌐 诠信全译企业官网:https://www.symtrustai.com/
💻 诠信全译等效交互Demo在线体验:https://demo.symtrustai.com/demo
💻 诠信全译等效交互算法开源代码:
https://github.com/SymtrustAI/InteractionExplanationDemo


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)