GDPval-AA Elo:基于Elo评分的专家级任务评估
GDPval-AA Elo:基于Elo评分的专家级任务评估
GDPval-AA(General-Development-Provability Assessment-Agentic AI)是由OpenAI于2026年1月推出的Elo评分系统基准,专注于评估AI模型在经济上有价值的知识工作中的表现。与传统的静态基准测试不同,GDPval-AA使用盲比较对评估和动态Elo评分系统,提供更准确的模型能力相对排名。

核心定位与适用场景
GDPval-AA的核心定位是经济上有价值的AI代理工作评估。GDPval-AA代表了AI评测的哲学转变:从"能做什么"(静态知识回忆)转向"能做什么用"(经济上有价值的任务执行)。
适用场景包括:
- 真实世界知识工作:来自美国劳动统计局工作活动的任务,反映现实职场需求
- 多职业覆盖:44个职业,9大行业,贡献美国GDP
- 动态评估:实时更新,反映模型改进
- 盲比评估:防止偏差和过拟合,确保公平比较
评测方法论
Elo评分机制(两阶段流程)
阶段1:任务提交阶段
- 模型通过Stirrup框架接收任务
- 模型有Shell访问+网页浏览
- 每个任务最多100回合(助手消息+工具调用=1次)
- 必须调用
finish工具并附带文件路径提交
阶段2:成对评分阶段
- 平衡采样:每个模型对在多样化任务上测试一次
- 主动采样:基于Elo优先级化评分相似评级的模型
- 盲评估:提交被匿名为"提交A"和"提交B"
- 评分模型:Gemini 3 Pro Preview评估哪个提交更好响应任务
- 多模态评分:支持视频/音频内容,解析文档为文本+图像
Elo计算:
- 模型:Bradley-Terry最大似然估计
- 基线:锚定到GPT-5.1 (Non-Reasoning) = 1,000 Elo
- 置信区间:95%通过bootstrap重采样(1,000次重拟合)
- 冻结评分:Elo在评估时冻结,确保索引稳定性
- 智能指数归一化:
clamp((Elo - 500) / 2000
任务池设计
数据集规格:
- 220个任务(金公开数据集)
- 44个职业覆盖美国劳动力
- 9大行业贡献美国GDP
- 来源:美国劳动统计局工作活动
- 经验水平:基于平均14年经验的专业人士任务
行业细分:
- 金融和保险(25个任务)
- 政府(25个任务)
- 医疗保健和社会援助(25个任务)
- 信息(25个任务)
- 制造(25个任务)
- 专业、科学、技术服务(25个任务)
-
- 3个行业的其余任务
任务类型:
- 文档创建(Word、PDF)
- 演示文稿幻灯片(PowerPoint)
- 电子表格(Excel)
- 图表和图形
- 多媒体内容(音频/视频)
示例职业:
- 客户服务代表
- 金融/投资分析师
- 注册护士
- 会计师和审计师
- 新闻记者和通讯员
- 机械工程师
- 合规官
Stirrup框架详情
关键特性:
- 哲学:“与模型协作,而非对抗它”——让LLM驱动自己的工作流
- 预构建工具:
- Web Fetch(从网页提取markdown)
- Web Search(Brave Search API,前5个结果)
- View Image(PNG/JPG/JPEG用于视觉模型)
- Run Shell(bash执行带stdout/stderr)
- Finish(任务完成信号)
- 上下文管理:在70%上下文窗口限制时自动总结
- 执行环境:E2B沙箱,100+预安装Python包
- 限制:每任务100回合(轮次),24小时超时
预安装环境:
- Jupyter生态系统
- 数据科学(numpy, pandas, scipy, matplotlib, seaborn)
- ML(scikit-learn, xgboost, catboost, lightgbm)
- NLP(nltk, gensim, spacy)
- 文档处理(python-docx, python-pptx, openpyxl)
- 媒体处理(ffmpeg, moviepy, librosa)
- CAD/3D(cadquery)
- 化学(rdkit)
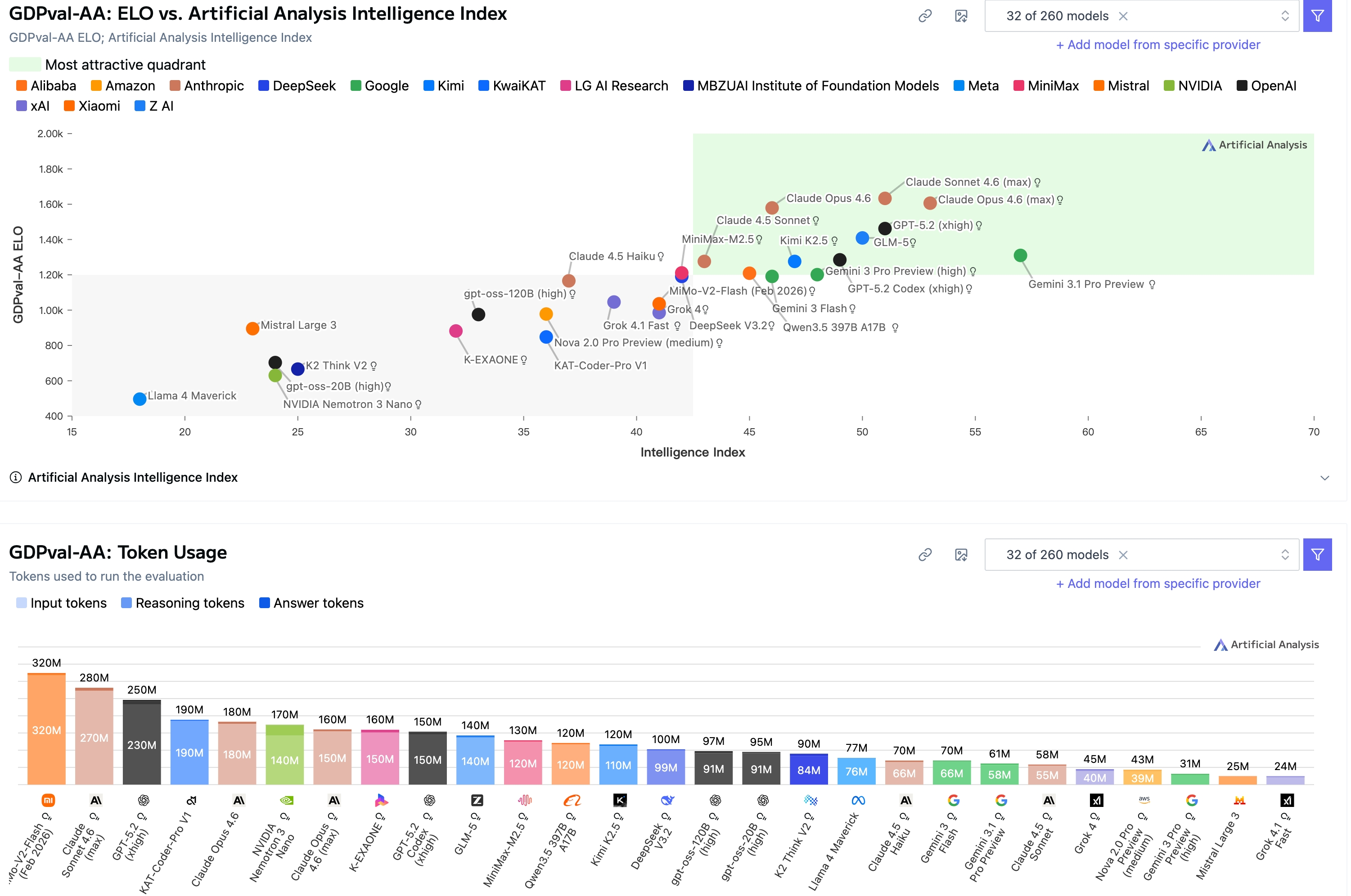
最新评测结果
截至2026年2月,GDPval-AA的最新评测结果显示:
| 排名 | 模型 | Elo评分 | 关键细节 |
|---|---|---|---|
| 1 | Claude Sonnet 4.6 | 1633 | 新领导者(2026年2月17日),在Sonnet 4.5上85%胜率 |
| 2 | Claude Opus 4.6 | ~1600+ | 在Sonnet 4.6的95% CI内 |
| 3 | GPT-5.2 (xhigh) | 1442 | 前领导者,扩展推理工作 |
| 4 | Claude Opus 4.5 | 1403 | 推理变体 |
| 5 | Claude Sonnet 4.5 | 1259 | 非推理变体 |
关键数据点:
- Sonnet 4.6使用280M令牌(vs Sonnet 4.5的58M)——4.8倍增长
- Opus 4.6使用160M令牌(等效设置)
- GPT-5.2成本**$620运行GDPval-AA(vs Opus 4.5的$608,GPT-5.1的$88)
性能分析
Sonnet 4.6的突破:
- 在1/5成本下达到接近Opus 4.6的性能
- 在ARC-AGI-2上4.3倍提升:13.6% → 58.3%
- 上下文压缩:有效实现无限对话
与其他基准的关系
Artificial Analysis Intelligence Index v4.0(2026年1月)
| 基准 | 权重 | 类别 | |
|-------------|-------|------|
| GDPval-AA | 16.7% | 代理(智能指数的25%) |
| Terminal-Bench Hard | 16.7% | 编码 |
| SciCode | 8.3% | 编码 |
| AA-LCR | 6.25% | 通用 |
| AA-Omniscience | 12.5% | 通用 |
| IFBench | 6.25% | 通用 |
| HLE | 12.5% | 科学推理 |
| GPQA Diamond | 6.25% | 科学推理 |
| CritPt | 6.25% | 科学推理 |
| τ²-Bench Telecom | 8.3% | 代理 |
从v4.0移除:
- MMLU-Pro(饱和在~95%+)
- AIME 2025(饱和)
- LiveCodeBench(饱和)
与传统基准对比
| 基准类型 | 示例 | GDPval-AA差异 |
|---|---|---|
| 静态知识 | MMLU、GPQA | GDPval测试真实世界应用 |
| 编码挑战 | LeetCode、SWE-Bench | GDPval生成文档,非代码 |
| 多选题 | ARC-AGI、MMMU | GDPval有开放端可交付成果 |
| 对话式 | LMSYS Arena | GDPval测量任务完成,非聊天质量 |
| 代理 | Terminal-Bench | GDPval专注于知识工作vs终端任务 |
与竞技游戏Elo系统对比
| 方面 | 国际象棋/竞技游戏 | GDPval-AA |
|---|---|---|
| 起源 | Arpad Elo(1960s国际象棋) | 适配自LMSYS聊天竞技场 |
| 基线评分 | 1200-1500(变化) | 1000(GPT-5.1基线) |
| 配对方法 | 循环赛/锦标赛 | 平衡 + Elo信息主动采样 |
| 比赛结果 | 胜/负/平局 | 更好/相同/更差(3路比较) |
| 评分 | 比赛结果由规则决定 | AI模型(Gemini 3 Pro)评估可交付成果质量 |
| 上下文 | 自包含游戏 | 带有参考材料的真实世界任务 |
| 动态更新 | 实时更新 | 评估时冻结 |
| 置信度 | 统计不确定性 | Bootstrap 95% CI(1,000次重采样) |
| 模型 | Bradley-Terry | Bradley-Terry(相同) |
关键差异:
- 评分复杂性:国际象棋有清晰的胜条件;GDPval要求定性评估可交付成果质量
- 任务持续时间:国际象棋:分钟;GDPval:数小时(多轮代理循环)
- 成本:国际象棋:最小;GDPval:$88-$620每次模型运行
- 资源要求:GDPval需要Shell访问、网页浏览、文件I/O
局限性与挑战
技术局限
- 上下文窗口:模型必须支持最少~100k令牌(用于参考文件+对话历史)
- 文档兼容性:Microsoft Office文件(.pptx、.docx)需要开源工具的往返转换
- 轮次限制:100回合可能约束非常长视野任务
- 总结压缩:70%限制时的上下文压缩可能丢失微妙细节
方法论局限
- 评分模型偏差:Gemini 3 Pro可能有不符合人类专家的偏好
- 任务代表性:220个任务可能无法捕捉真实世界工作的所有方面
- 冻结评分:索引稳定性要求冻结评分,这不反映随时间的模型改进
- 成本障碍:高评估成本($88-$620)限制模型测试频率
- 语言:仅文本,英语评估(智能指数中无多语言)
与LiveBench/HLE对比
- HLE:2,500个学术问题,Google-proof,测量前沿知识
- LiveBench:来自真实编程竞赛的动态编码问题
- GDPval-AA:测量经济上有价值的工作,非学术知识或纯编码
对开发者的启示
来自Artificial Analysis团队
- GDPval-AA代表了哲学转变:测量"经济上有价值的行动"vs"回忆"
- 该基准旨在解决基准饱和——传统测试正变得过时,因为模型改进
- 智能指数v4.0增加难度:顶级模型现在得分~50 vs 73(前版本)
- Elo系统选择因其相对排名能力——随着新模型出现动态跟踪进展
来自OpenAI(原始GDPval论文)
- 前沿模型线性随时间改进
- 当前最佳模型接近行业专家质量
- 推理工作、任务上下文和脚手架都提升性能
- 模型与人工监督配对可以更便宜、更快地完成任务,而非无辅助专家工作流
来自Anthropic(Sonnet 4.6公告)
- Sonnet 4.6达到接近Opus性能,成本为1/5
- 在GDPval-AA上领先,拥有最佳办公和金融任务
- 在ARC-AGI-2上4.3倍提升:13.6% → 58.3%
- 上下文压缩实现有效无限对话
总结与展望
GDPval-AA代表了AI能力评估的重要演进。通过其经济上有价值的任务、盲比较Elo评分和动态更新机制,它提供了比传统静态基准更准确、更相关的模型能力相对排名。
关键发现:
- Elo系统提供动态相对排名,优于静态绝对分数
- 盲评估防止偏差,确保公平比较
- 冻结评分确保稳定性,避免频繁重新评估
- Claude Sonnet 4.6的显著改进(1633 Elo)显示推理效率提升
- 经济价值焦点区分GDPval与学术基准
启示:
- 经济上有价值的任务是AI能力的真实测试
- 动态评估反映快速模型演进
- Elo系统为持续比较提供可靠框架
- **多维度评估(智能指数)**比单一基准更全面
参考来源
- GDPval-AA榜单:https://artificialanalysis.ai/evaluations/gdpval-aa
- OpenAI GDPval论文:arXiv 2510.04374(ICLR 2026)
- OpenAI GDPval博客:https://openai.com/index/gdpval/
- GDPval Explorer:https://gdpval.dev/
- 评估方法论:https://artificialanalysis.ai/methodology/intelligence-benchmarking
- Stirrup框架:https://github.com/ArtificialAnalysis/Stirrup
- Claude Sonnet 4.6文章:https://artificialanalysis.ai/articles/claude-sonnet-4-6-gdpval(2026年2月17日)
- VentureBeat:AI指数革新(2026年1月6日)
(本文基于公开信息整理,所有数据和观点均标注来源。来源包括OpenAI、Artificial Analysis、GitHub等多个官方来源。)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)