揭秘RAG系统底层逻辑,从“能用”到“工程化”的7层进化图谱!
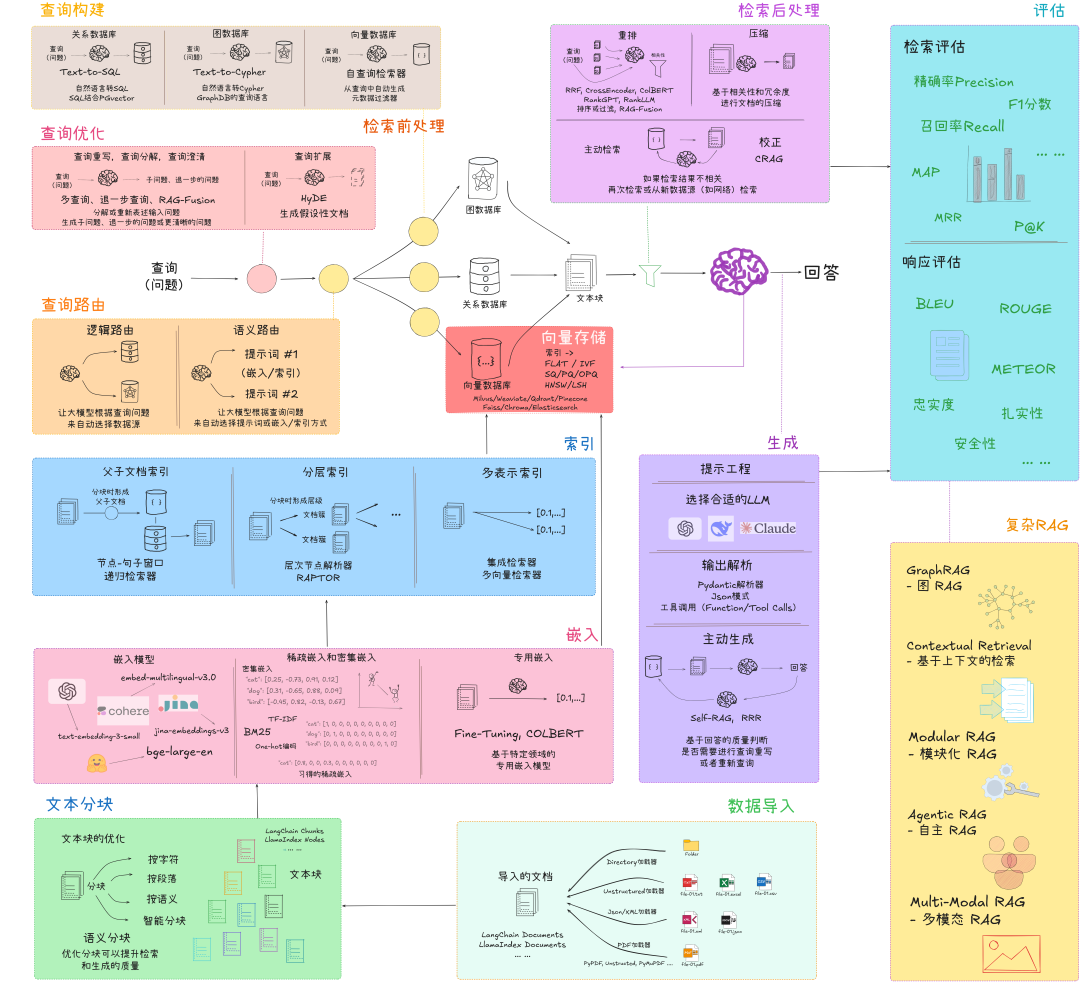
这张图,佳哥真是用心了
今天这一篇,我不讲案例、不讲代码、不讲某个框架的用法。
我只做一件事:
把这张图,从“看起来复杂”,讲到“你知道它为什么必须长这样”。
先说一句狠话
如果你觉得 RAG 是:
那你现在看到的大多数 RAG 系统,在规模一上来时,都会失效。
不是模型不行,是结构没搭完。
而这张图,讲的就是:
一个 RAG 系统,从“能用”,到“可扩展、可评估、可演化”,到底需要哪些结构层。
第一层:数据不是从“文本”开始的
很多人一上来就聊向量库,其实顺序是反的。
真正的起点在最底部:数据导入与文本分块。
你会看到这里不是一句“切 chunk”,而是:
- 按字符 / 句子 / 语义的分块策略
- 父子文档索引
- 分层索引(RAPTOR)
- 多表示索引
为什么?
因为检索失败,80% 不是检索算法的问题,是切块阶段就已经丢信息了。
如果你在这一层没有“结构意识”,
后面所有高级技巧,都是在补锅。
第二层:Embedding 从来不是一个模型的问题
中间这一大块,是很多人最容易误解的地方。
Embedding 不是只有一个向量。
你会看到:
- 稠密向量(OpenAI / bge / jina)
- 稀疏向量(TF-IDF / BM25)
- 专用嵌入(Fine-Tuning / ColBERT)
为什么要这么复杂?
因为现实世界的检索,本来就不是一个相似度空间。
关键词、语义、领域信号,本来就不在同一个空间里。
真正可用的系统,一定是混合表示。
第三层:索引与向量库只是“物理层”
很多人把 FAISS、Milvus、HNSW 当成核心。
但在这张图里,它们被刻意画得很“靠后”。
因为它们解决的只是一个问题:
怎么快。
而不是:
怎么对。
索引策略(父子、分层、多表示),
远比你选哪种向量库重要。
第四层:真正开始像「系统」的地方——查询侧
图左上角,是整个系统的灵魂。
你会看到四件事同时出现:
- 查询构建
- 查询优化
- 查询路由
- HyDE / 主动检索
这一步意味着什么?
意味着系统已经不再是:
“用户问一句,我搜一遍”。
而是:
系统开始“理解该怎么问世界”。
第五层:检索后处理,决定答案质量上限
中间偏右那一块,是很多 Demo 系统里完全没有的东西。
- 重排(Rerank / Cross-Encoder / ColBERT)
- 压缩(相关性 + 冗余控制)
- 校正(CRAG)
- 主动补查
这一层解决的是:
不是有没有搜到,而是“哪些值得被看见”。
如果没有这一层,
你永远会觉得:
“有点对,但总差点意思”。
第六层:生成不只是“丢给模型”
右下角的生成部分,我刻意没有画成一个大脑就结束。
你会看到:
- 提示工程
- 结构化输出(Pydantic / JSON Schema)
- 工具调用
- Self-RAG / RRR
- 主动再检索
这意味着一件事:
生成,本身也是一个可以被设计、被反思的过程。
第七层:评估,是系统是否“工程化”的分水岭
最右侧那一列,是很多人最不想做、但最重要的。
- Precision / Recall / F1
- MRR / MAP
- BLEU / ROUGE / METEOR
- 忠实度 / 安全性
有没有这一列,决定了:
你是在做 Demo,
还是在做系统。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献118条内容
已为社区贡献118条内容

所有评论(0)