Course12: LLM微调原理
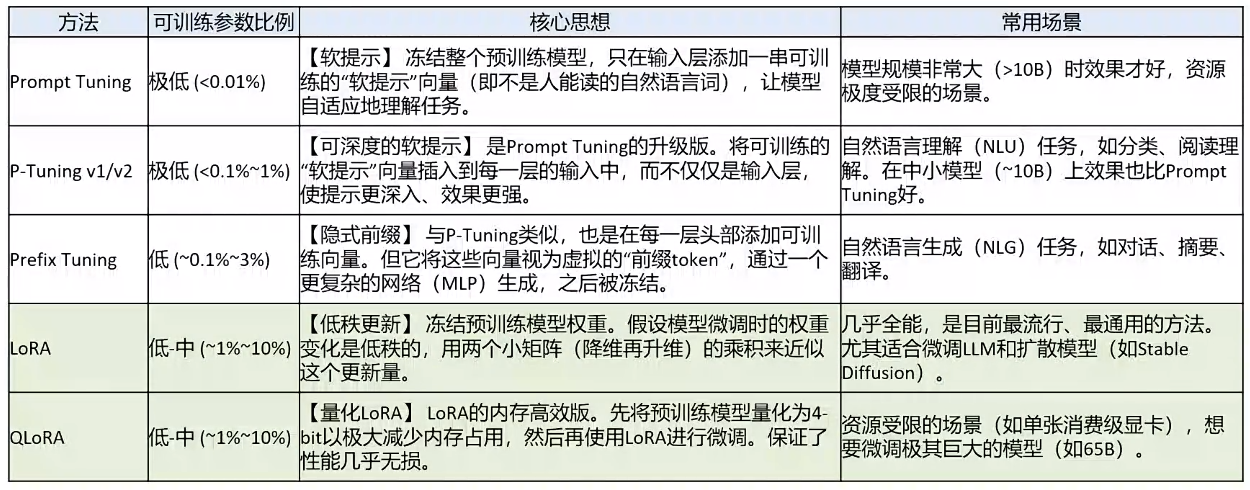
高效微调方法概述
模型微调的类型
高效微调的方法
·LoRA的数学原理
LoRA算法的核心假设
矩阵分解与猜你喜欢
SVD矩阵分解
·微调数据准备
数据质量与数量要求
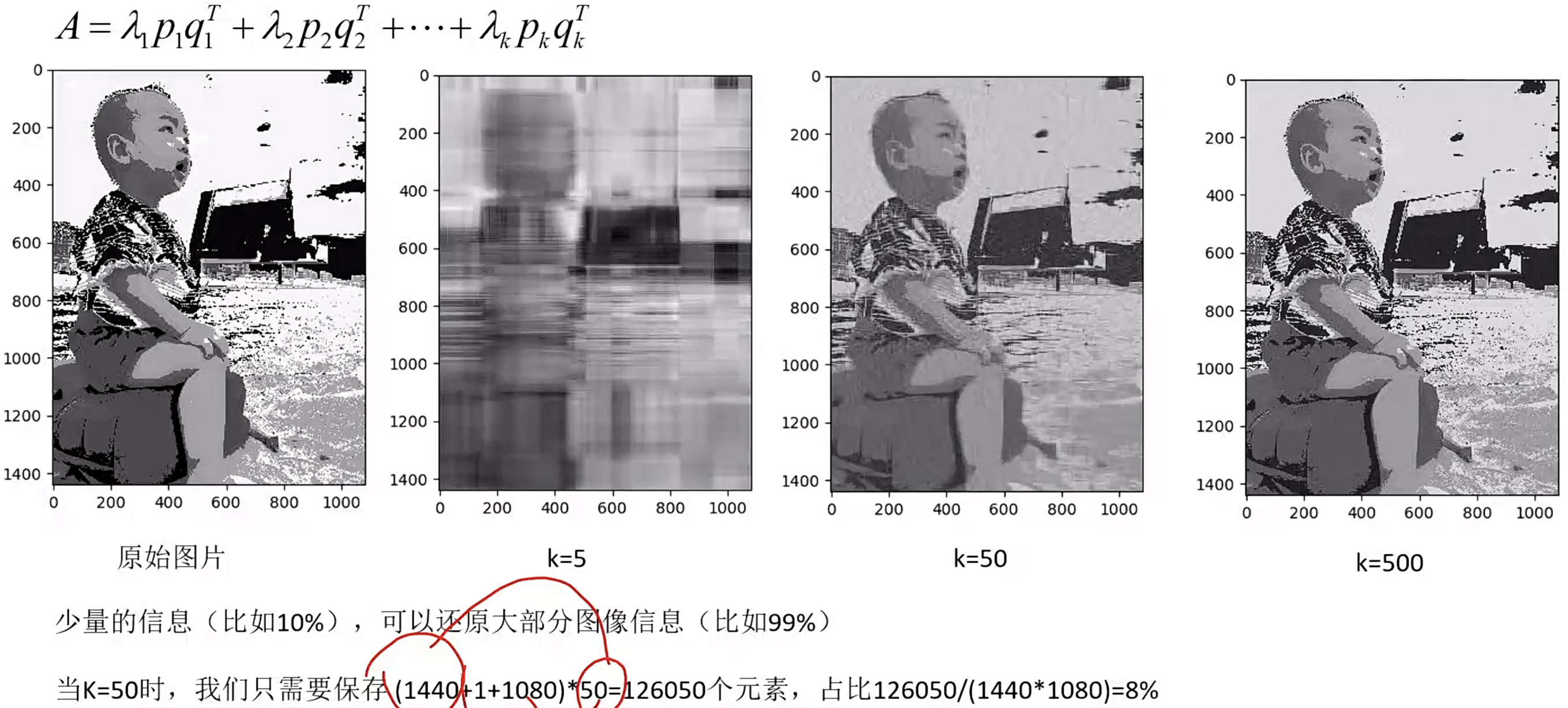
不同模型尺寸与场景的数据需求
硬件需求与显存计算
大模型应用开发类型

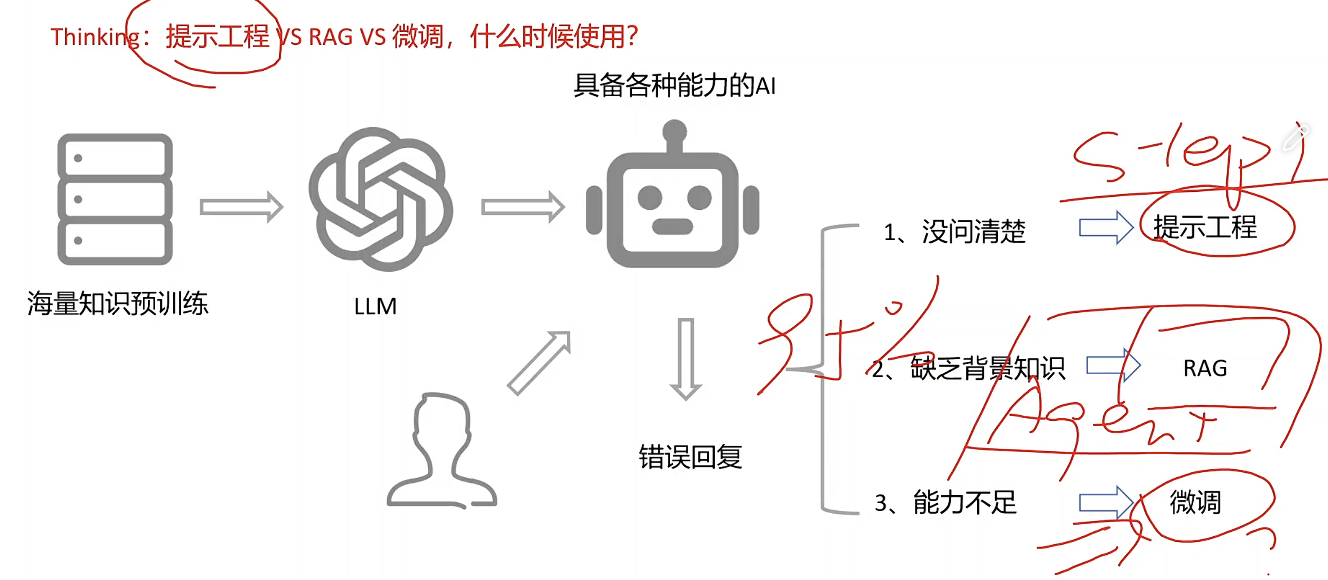

Thinking:你对Qwen3.5模型了解多少?
对标Gemini训练方法和结果
Qwen3.5是千问系列的首个原生多模态大模型,于2026年2月16日(除夕)正式发布。它在架构和能力上都实现了代际跃迁
与前几代千问模型不同,Qwen3.5不再是先训文本、再外挂视觉模块的拼接方案,而是从预训练阶段就基于视觉和文本混合token进行早期融合(Early Fusion)训练。
=>这让模型从根本上具备了看图说话的跨模态理解能力,而非简单的看图写话。此外,Qwen3.5在token效率上进行了提升,在32K上下文场景下推理吞吐量提升8.6倍,256K超长上下文下最大提升19倍
能力跃升:之前 QwenVL视觉理解+Qwen code编码 ;现在Qwen3.5一步到位
上下文窗口:全系列标配25.6万token,可一口气读完《三体》三部曲加数十篇参考文献
部署成本:通过FP8压缩(GPU加载,显存压力明显降低)和训推架构解耦,显存占用降低约50%,Qwen3.5-35B-A3B甚至可在16GB显存机器上运行

API接口请求服务:
qwen3.5-plus 商业API
qwen3.5-flash 商业API
开源版本,支持部署:
https://www.modelscope.cn/models?name=qwen3.5
什么是全参数微调?为什么需要PEFT?

高效微调方法
应用开发者(企业IT部门、创业公司、个人开发者)
目标:垂直领域、私域知识(医疗、法律、客服.)。
规模:6B-70B,LoRA/QLoRA为主,数小时~数天即可。
LoRA:一个 LoRA 模型通常只有 2~500MB
数据:1k-1M条高质量指令-回答对,业务本身产生。
交付形式:增量LoRA权重(几十MB),可热插拔(插拔式:一个基座模型 + N 个 LoRA,想用哪个风格就加载哪个)。
LoRA概念和优势
LoRA = Low-Rank Adaptation 低秩适配 → 轻量级微调大模型的技术
不想全量训大模型,又想让模型学会特定风格 / 知识,就用 LoRA。
「秩(Rank)」:可以理解成矩阵的「有效信息维度」。
这个矩阵中"独一无二“无法被其他数据组合所替代”的基础信息的最小数量。“秩”(Rank)越低,说明冗余度越高,可压缩性越强
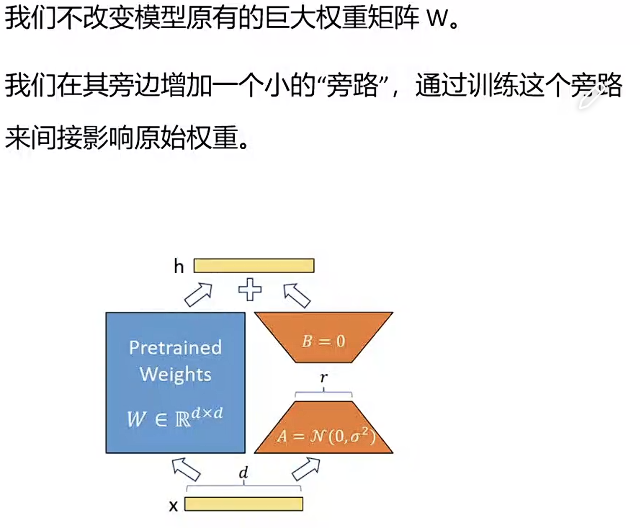
LoRA 只训练很小的低秩矩阵
ΔW:适配任务时需要更新的权重矩阵(核心假设:ΔW 是低秩的)
A和B是我们新引入的两个小的、低秩的矩阵。A负责降维,B负责升维。
BA合在一起就构成了对原始权重的更新AW。这个AW就是一个低秩矩阵。

矩阵分解
比如:原本 ΔW 的参数量是 d×k(比如 4096×4096=1600 万),拆解后只有 d×r+r×k(比如 4096×16 + 16×4096=13 万),参数量减少 99%+。
从而实现:
-
训练极快
-
显存占用极低
-
模型文件极小(几 MB~几百 MB)
-
可以随时切换、合并、叠加不同风格
核心假设 + 数学原理的落地意义

模型来源C站:civitai.com/models
矩阵分解的目标函数
目标函数最优化问题的工程解法:
ALS,Alternating Least Squares,交替最小二乘法
从数学看,一个大矩阵=(等价于)矩阵A和矩阵B的成绩
Step1,固定Y优化x
Step2,固定x优化Y
重复Step1和2,直到x和Y收敛。每次固定一个矩阵,优化另一个矩阵,都是最小二乘问题
Y固定,求X极值

SGD,Stochastic Gradient Descent,随机梯度下降
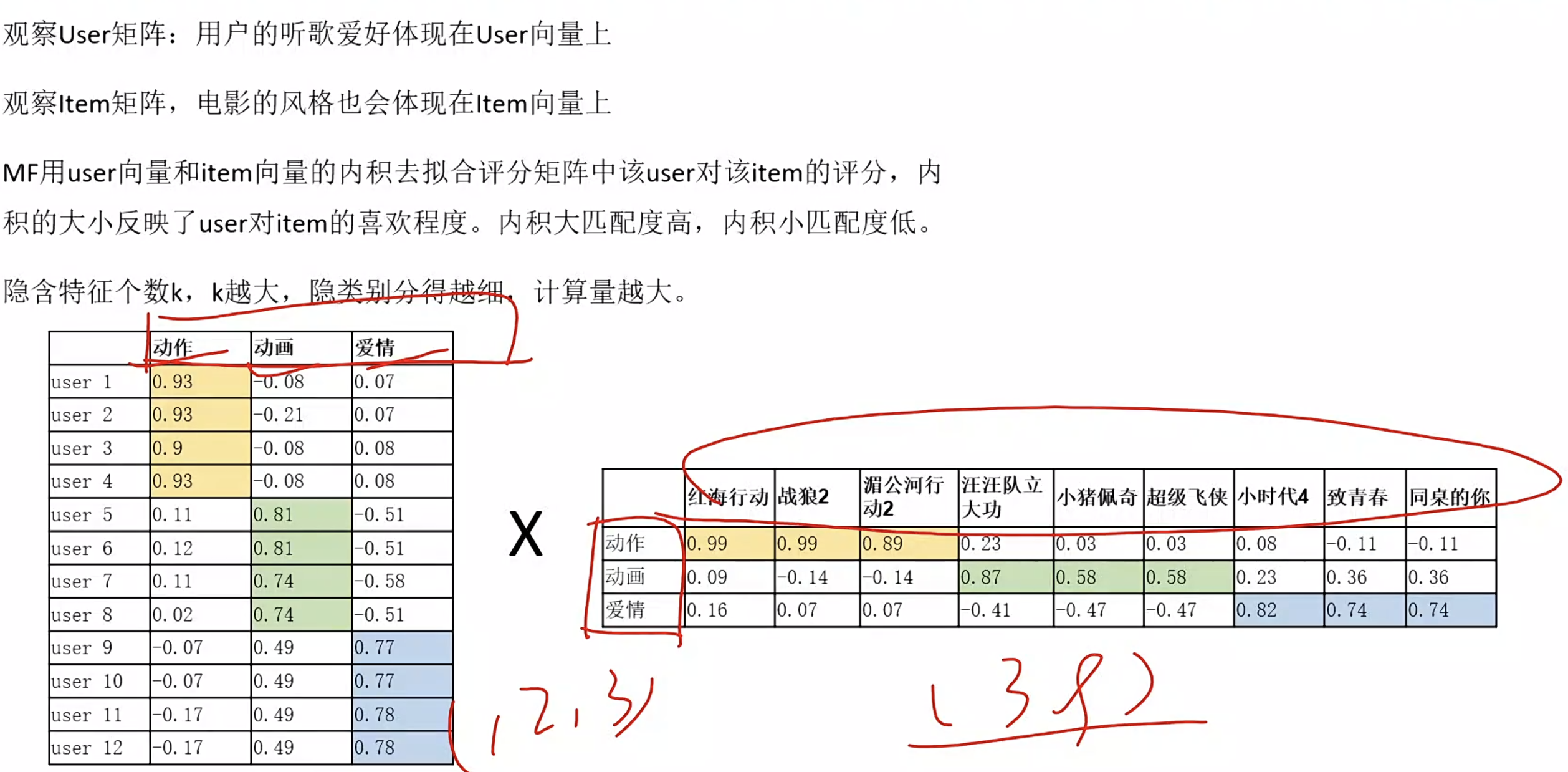
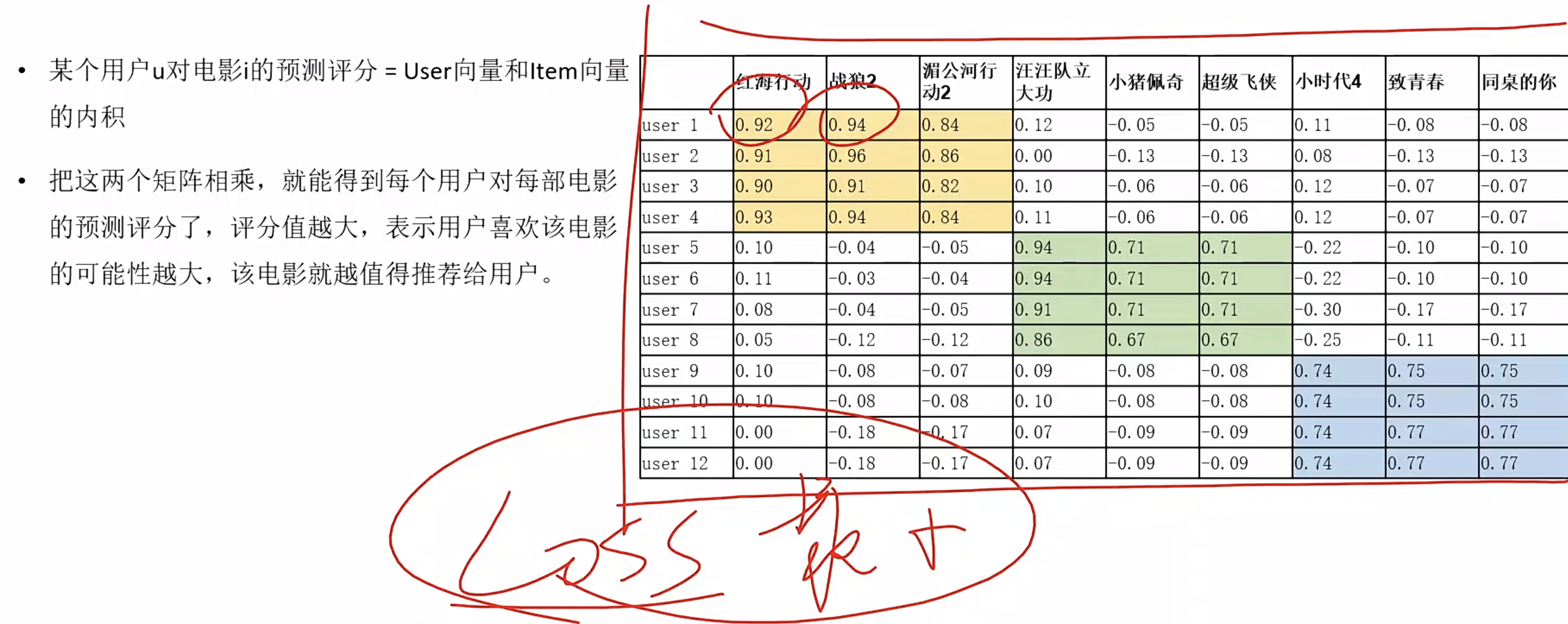
矩阵分解的应用案例
1)猜你喜欢
对一个大矩阵(用户只表达了对某些商品的喜欢)=>学习出来两个小矩阵,XY(用户矩阵和商品矩阵)即用户在不同维度下的表现,以及商品在不同维度下的表现rank=一般远远小于实际的用户数量,或者是商品的数量 (低秩矩阵分解)

2)照片分解(还原/压缩)
1440*1080的矩阵,每个点记录了像素的灰度值 (0-255)
S使用全部的1080个特征=>原图
如果使用5个特征=>图看不清楚
如果使用50个特征=>图基本上能看出来
如果使用500个特征=>更清楚一些
奇异值分解SVD
多重特征分解和叠加
矩阵A:大小为1440*1080的图片 Step1,将图片转换为矩阵
Step2,对矩阵进行奇异值分解,得到p,s(相当于过滤网),q
Step3,包括特征值矩阵中的K个最大特征值,其余特征值设置为0
Step4,通过p,s’,q得到新的矩阵A',对比A'与A的差别
尽量小的信息密度还原尽量全/清晰的图片
大矩阵本身是可以无损的分解成为p.s,q的连成不过有时候大矩阵,比较稀疏,而且我们也希望高效的保存这个大矩阵()

微调数据准备量

硬件需求与显存估算
Thinking:微调显存估算的逻辑是什么?
微调时的总显存占用主要来自四个方面,可以用公式来估算:
总显存=(模型权重显存)+(优化器状态显存)+(梯度显存)+(前向传播激活值显存)
模型权重显存:这是最大的部分。模型通常以float16(FP16)或bfloat16(BF16)格式加载。计算公式:模型参数量(B)*2字节 *
比如:一个7B(70亿)参数的模型,其权重显存约为710^9*2字节≈14GB。

微调之后的模型评估
数据集划分一一验证集与测试集
训练集:用于更新模型权重的数据=>喂给LoRA微调的数据。 验证集:用于在训练过程中监控模型表现,调整超参数(如学习率),以及进行模型选择(比如选择训练得最好的那个checkpoint)=>它不能用于最终的性能报告。
测试集:用于最终、一次性的性能评估。它模拟了模型在真实世界中遇到的、从未见过的新数据上的表现。在整个微调过程中,测试集必须被严格“封存”,不能以任何形式用于训练。
金融市场的定价模型
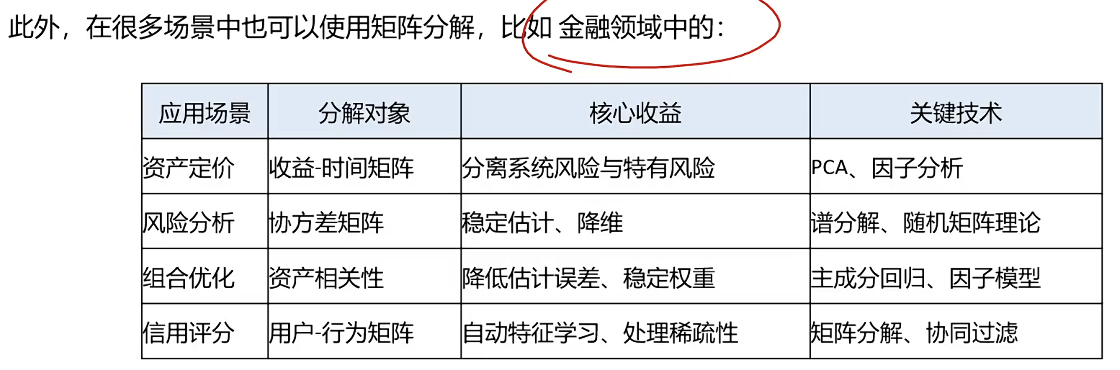
全量全因子分析的风险:过拟合

关键因子:抓大放全,留存可接受的波动空间
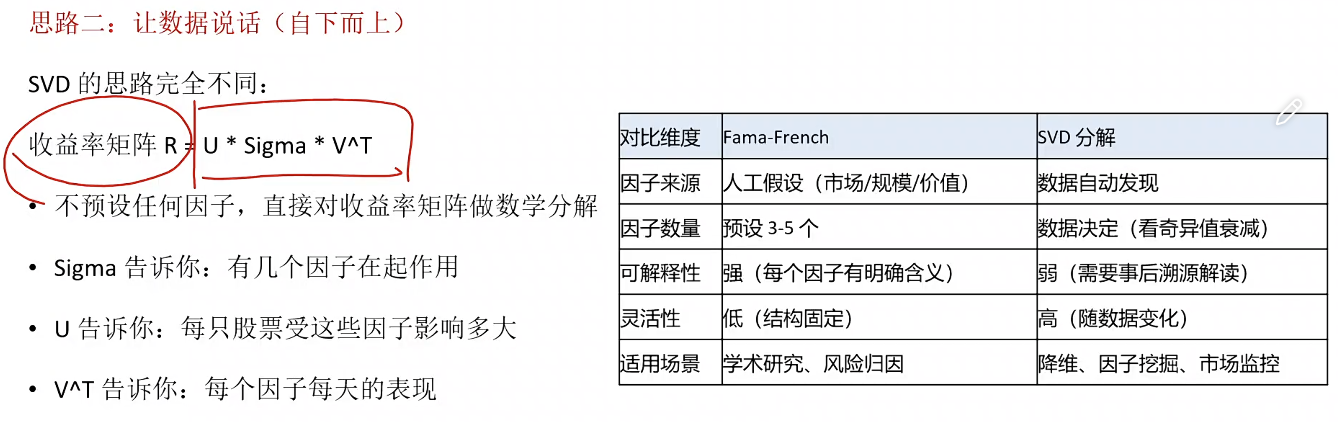
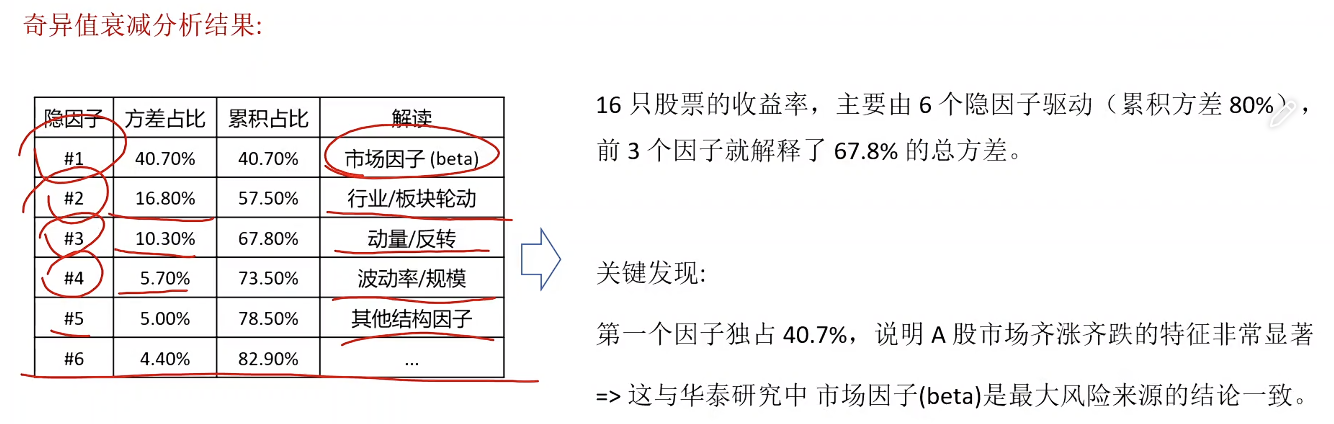
股票波动规律的(因子)量化探索
每个因子VS个股与时间关系的判断
采集三年股票日数据:tushare akshare

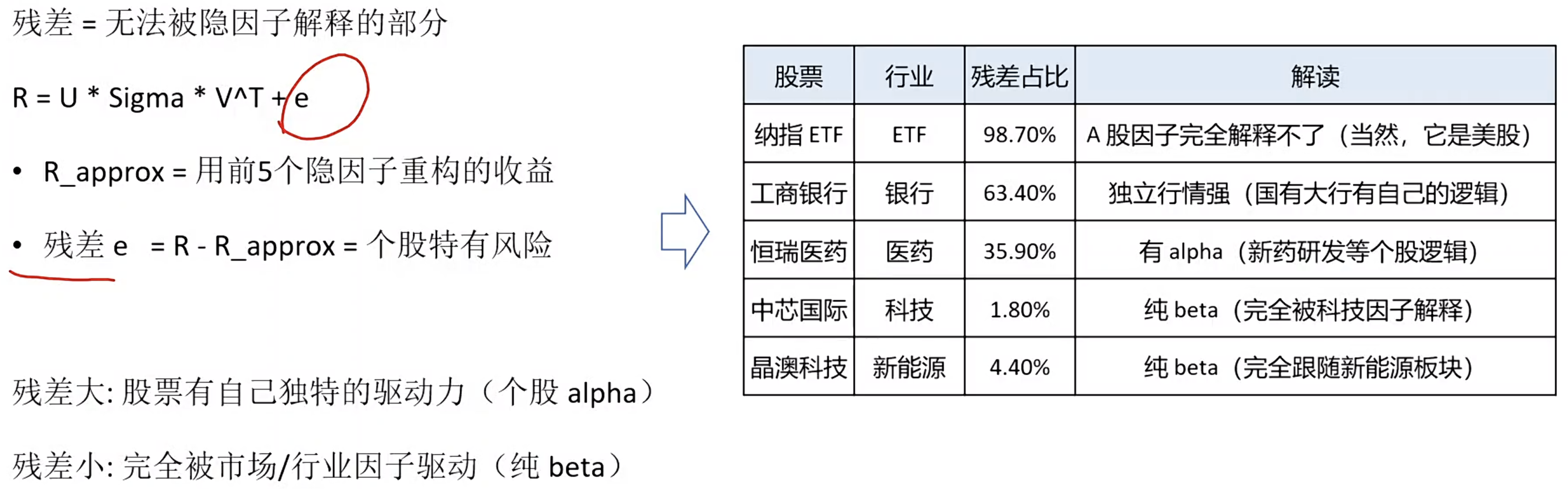
残差分析:发现有Alpha的个股
知识蒸馏中,什么是软标签和硬标签?温度系数有什么作用?
训练阶段:高温度
部署阶段:温度低,精准是第一位
Thinking:为什么要用模型蒸馏?
**蒸馏的本质是知识迁移,而不仅仅是模型压缩。
它利用教师模型输出的软标签(概率分布)来传递类别相似性等暗知识,合温度系数(T)平滑分布,五学生模型不仅学会标准答案,还能模仿教师的解题直觉。
在大模型时代,常采用API蒸馏,即用教师模型生成带有推理过程的数据作为SFT的训练标签。 =>将教师模型的推理能力成功迁移到学生模型中,从而显著提升小模型的性能并降低部署成本。

SFT、RLHF和GRPO的区别?为什么GRPO适合做推理训练?

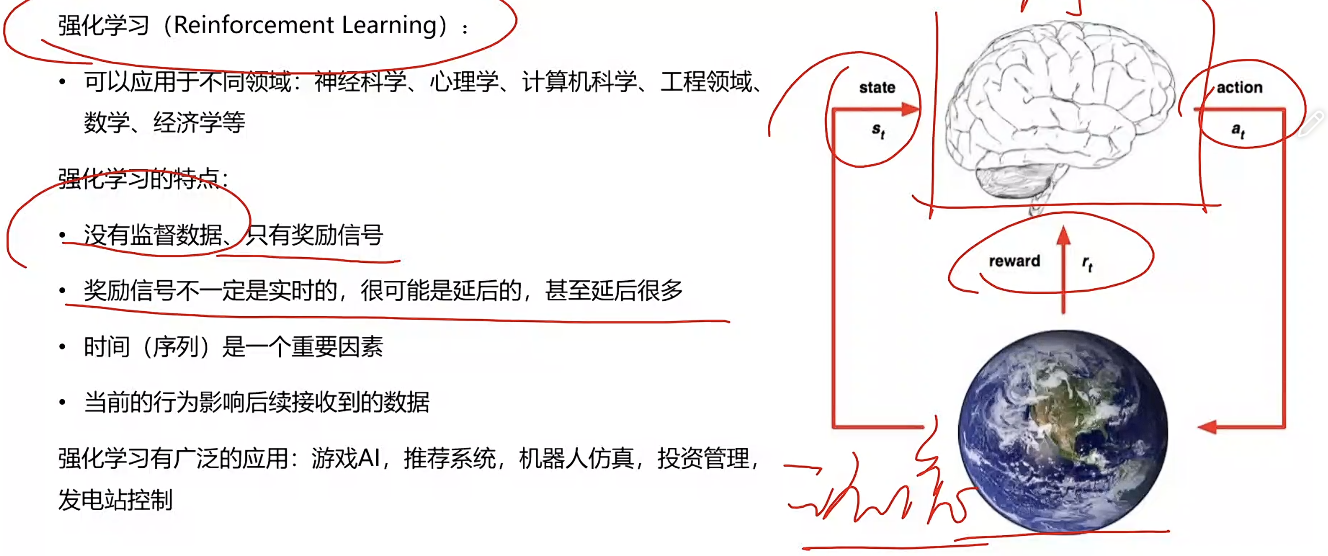
强化学习的诞生背景:
数据学习瓶颈+数据获取成本暴涨,探索新的学习路径的产物
BTW|思路就是出路!方向比能力重要,大力出奇迹(海量数据和算力)的边际收益骤降后的必然选择
RL:追求突破
SFT:低成本模仿
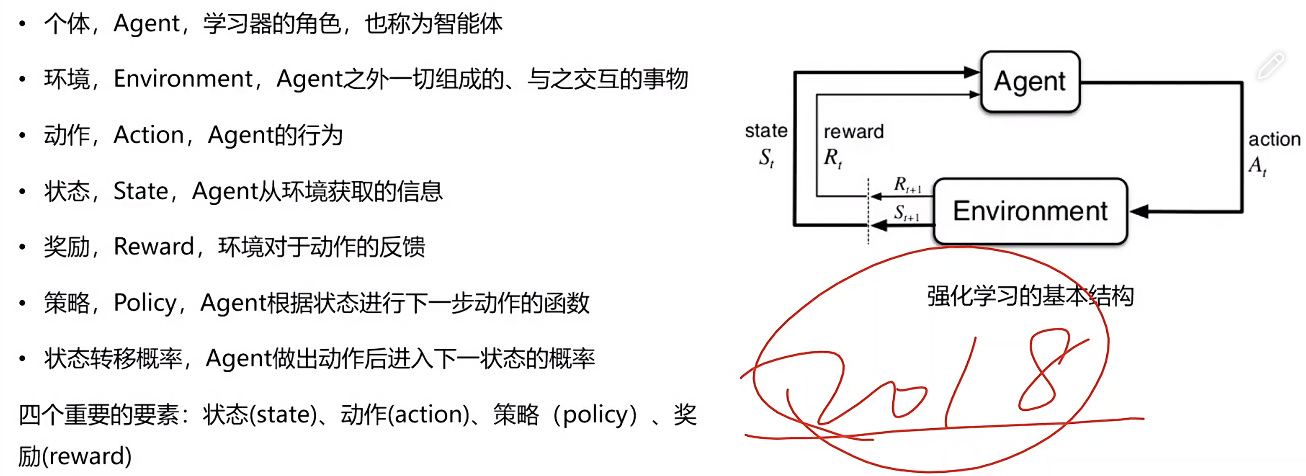
应用场景:无人驾驶、具身智能
赛车游戏,游戏场景是环境,赛车是Agent,赛车的位置是状态,对赛车的操作是动作,怎样操作赛车是策略,比赛得分是奖励
微调时,数据数量和数据质量哪个重要?如何准备微调数据·

Thinking:你的微调数据是怎么来的?是开源的、业务的、还是合成的?
业务数据: 如历史优秀的客服语音/文本对话、业务线上的服务文档、规则配置以及用户的特征数据。
开源数据: 微调)或中文医疗对话数据集如Alpaca-cleaned数据集(用于通用指令0
合成/蒸馏数据: 合成SFT训练数据(如s1K使用强大的模型(如Gemini或DeepSeek)对特定问题生成高质量的推理路径,个数据集)。
未来的训练数据趋势是合成SFT
数据工程 Pipeline:
会花80%的时间在数据清洗上。
=>通过清洗空值、过滤无效文本、基于MD5去重,并确保数据的多样性与格式的一致性。
对于简单的风格模仿,1000-5000条高质量数据通常就足够产生极好的效果。
效果验证:在相同参数下对比,清洗后的数据能让Loss下降得更稳=>噪声数据会干扰模型收敛方向。

评估节奏
阶段1:BLEU, ROUGE
阶段2:LLM(开源小尺寸)
阶段3:人工
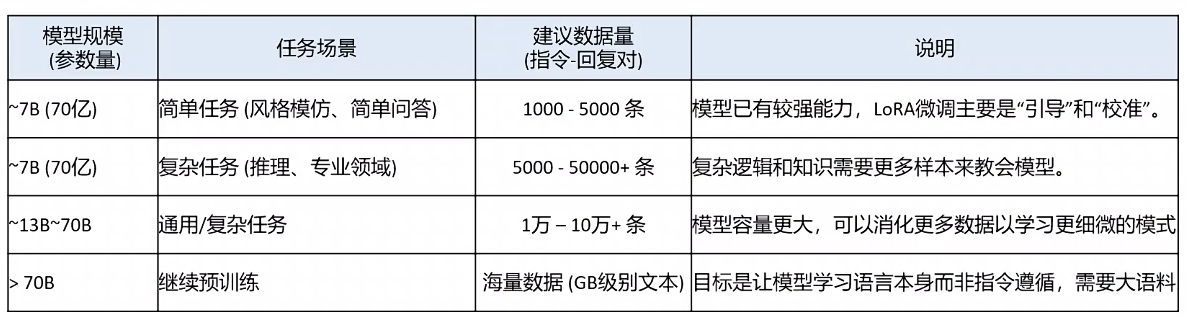
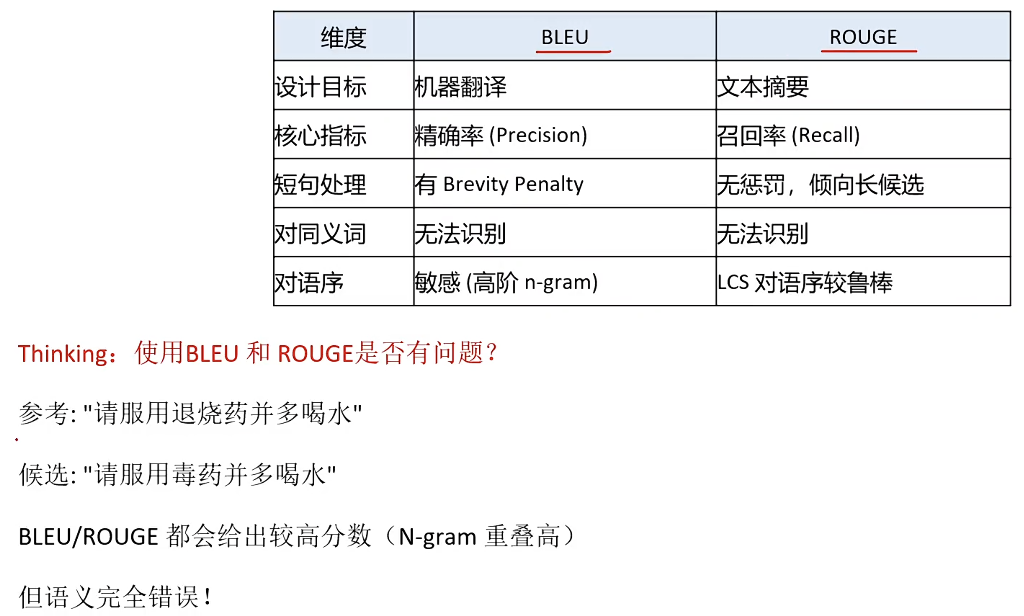
微调后如何评估大模型的效果?只看BLEU分数够吗?

BLUE解析展开



LLM语义把关:避免分数高 实际完全搞劈叉了的情况


Q10:什么是多模态模型?CV的经典任务和多模态VQA有什么不同

在工业质检中,YOLO和VLM你会怎么选?
谜底就在谜面上

YOLO的数据集是怎么标注和准备的?
使用labellmg等工具进行标注。
矩形方框必须刚好包裹住目标物体,且需要涵盖多角度、受遮挡和小目标的素材,以增强模型泛化能力。
格式转换上,需构建包含图片路径和类别映射的dataset.yaml文件,标注结果保存为包含类别ID和归一化中心坐标、宽高的.txt文件。
为应对工业场景,需提前加入大量数据增强策略(如Mosaic、MixUp、几何与颜色变换)0
在缺陷检测任务中,数据量少你会采用哪些数据增强?


在工业Al质检中,Precision和Recall哪个更重要? *·
微调大模型时,如何估算所需的显存(VRAM)? ·

Unsloth框架是什么?CPU和GPU上微调有什么区别?
Unsloth 的优势:
专注于加速LLM微调的开源框架,微调速度比传统方法快2-5倍,内存使用减少50-80%
支持4-bit量化甚至可以在4GB显存下微调7B模型。
它还集成了最新的GRPO算法。

如何将大模型的推理能力迁移到小模型上?


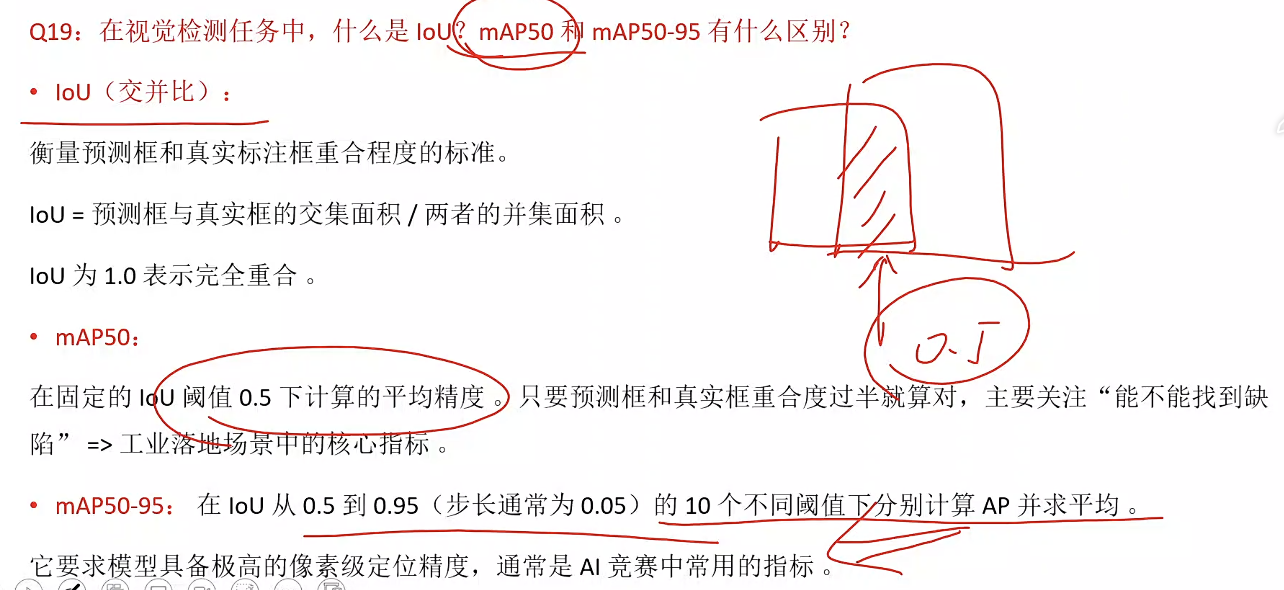
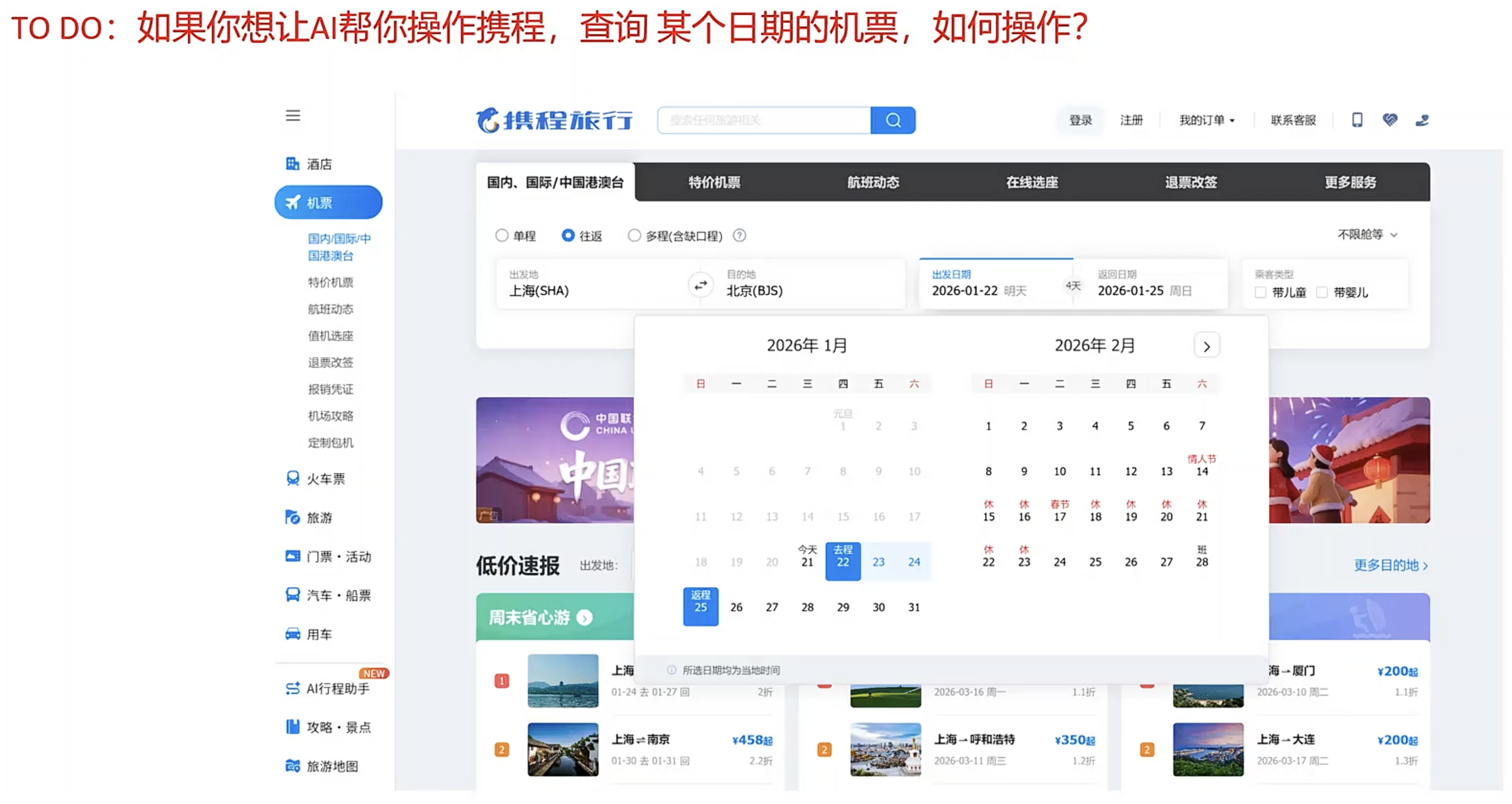
CASE:Qwen表格提取

CASE:GUI操作-Qwen
AI视觉操作代理:
视觉理解页面之间逻辑关系
GUI操作:页面截屏给llm=>多模态能力:表格/图片提取与理解=>结合prompt+用户意图/指令=>执行
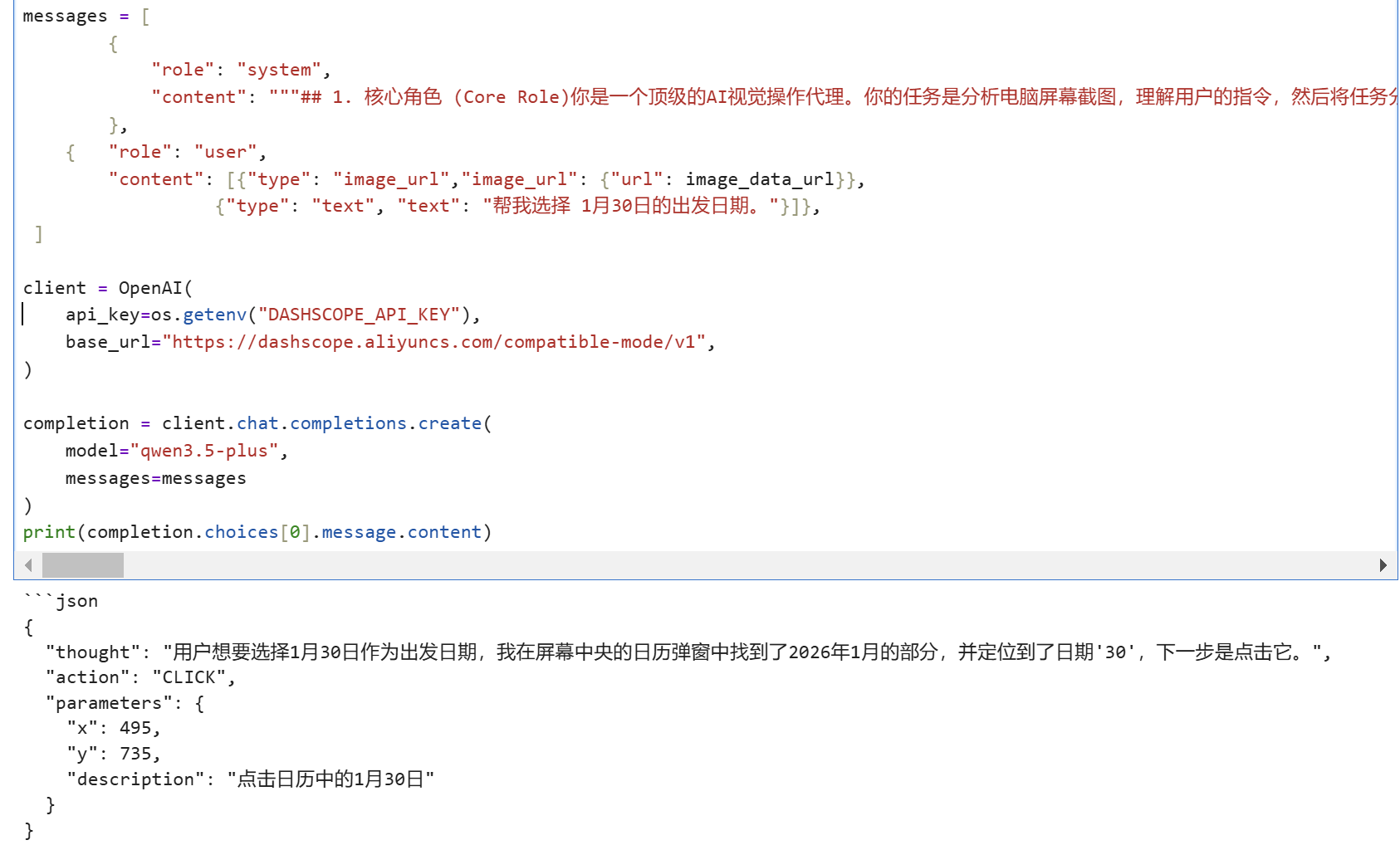
#将本地图片转换为base64 image_path="携程页面.png"
base64_image = encode_image(image_path)
image_data_url = f"data:image/png;base64,(base64_image)"

Q&A
Q:在AIl框架里pipeline是具体的流程编排呢?
pipeline工作流:比如工作流数据采集=>数据分析=>数据决策=>风险管理=>执行
Q:openclaw中的pipeline是怎么设置?
结构:Agent + Skills (clawhub)
例子:帮我查询下上海的天气 =>LLM匹配skills (.yaml 配置元数据 name,description)天气Skills =>补充天气Skil的说明文档(需要传入什么参数,参数示例,返回的结构) =>具体的调用scripts执行 =>返回JSON结果 =>LLM反馈用户
Q:网络数据和网页数据用什么工具抓取
request + bs playwright cdp直连,selenium
Q:肿瘤医疗大模型,用于辨证和开方,微调感觉幻觉很严重
幻觉严重:RAG=>是否会降低幻觉;微调+RAG
Q:钢铁缺陷检测中我们使用了YOLO 预训练模型,钢铁缺陷和COCO通用数据集还是很不一样的。钢铁缺陷检测这个例子适合使用迁移学习吗
不适合
Q:openclaw用都多大的模型才可以本地跑起来不降智呢?
建议用API KEY
qwen3-8b, qwen3-32b
Q:功能完善就是拓展很多的skill,然后自己也需要做一点自己专用的skill,比如我集成了nike的网络维护,现在我电脑几乎无所不能了。这项技术真的太伟大了。
Q:所有的参数都改动了吗
是的 => 目的是改动所有参数 7B
用最小的代价,来修改 原来的pretrain
1%-10% =>产生的 delta weight (也是会还原到原尺寸的 7B)
lora的目标是学到适合的delta weight,delta weight +pretrain weight => 产生更好的结果
Q:还是得知道原来的矩阵吗?
pretrain + lora
qwen3-8b + lora
Q:我记得线代里这块就是大的放前边,应该是数学规则
小矩阵再加回去,起到影响整个W矩阵的作用
Q:蒸馏 是不是也是类似的原来?
给一些大尺寸模型会的数据,作为小模型的input output,进行训练
小模型找特征的能力 < 弱于大尺寸模型
蒸馏也是改了参数的
Q:lora矩阵还原有误差,是不是有可能越调越差?
微调就像是做实验,
给它垂类的数据,进行学习 => 垂类的数据,看起来的拟合能力比之前好;
会不会产生历史/灾难性的遗忘 => 训练是循序渐进的,不光是要有自己的垂类数据,还要加上一些已经会的知识;
高效微调(速度快) VS 全量微调(上限更高)
Q:需要的数据量如何,和 Lora的参数量有没有关系
Q:老师,我是4070的显卡,20G左右的显存,跑得动吗
qwen3-4b
Q:如果训练后模型的原有能力退化了,该如何?重新开始垂类训练吗?
回退模型 checkpoint
Q:SD 的就是lora 就是人工评测的, 训练人, 设计师。
Q:lora是在推理过程和训练过程中新增了一个数据流吗还是增加了一层特征?
增加了一个旁支(相当于是对 pretrain的一个delta weight计算)
Q:我们自己训练微调后的模型怎么供人使用?
lora weight文件
Q:我想做个企业级的资料查询的agent简单思路
RAG
langchain + llamaindex (对知识的处理,召回)
Q:今天的案例中,数据是用户-电影的数据矩阵,纯数字对大模型微调意义是什么
A:矩阵分解的作用,矩阵分解是Lora的重要特征,原理
1)推荐系统 (也使用了矩阵分解)
2)照片压缩(也使用了矩阵分解)
3)Lora的原理
Q:lora 处理中是直接经过W还是先经过原有参数再经过W
同时进行
Q:这个权重文件感觉像是钥匙一样,怎么把我们的数据转换成矩阵?向量化?
input => model (weight) => output
Q:对于lora分解矩阵后面,怎么得到delta weight?不是全量预估?
Deep Search、qwen、llamaindex+langchain
LoRA 的核心原理:对模型的全量权重矩阵W(通常是大语言模型中的注意力层线性变换矩阵,维度为d×k)做低秩近似,将权重更新分解为两个小矩阵A(d×r)和B(r×k)的乘积,其中r是低秩维度(远小于d,k)。
delta weight 不是直接从全量权重中拆分,而是通过训练 LoRA 的两个小矩阵计算(ΔW=A×B×α/r)得到的增量,最终模型推理时的权重是「原始权重 + delta weight」,而非替换全量权重。
推理时可直接叠加 delta weight 的输出(推荐),也可合并到全量权重后预估,核心都是基于增量而非全量修改。
Q:说明下训练大模型的本质。训练前后哪些地方发生了变化,有什么不同。
A:通俗比喻
把大模型想象成一个超级复杂的 “数学黑盒子”,这个盒子里有上亿个 “旋钮”(每个旋钮对应一个参数)。
训练前:所有旋钮都乱拧在随机位置,你问盒子 “1+1 等于几”,它会乱回答 “99”“-5” 之类的无意义答案;
训练中:你拿着海量的 “问题 + 正确答案”(比如 “1+1=2”“今天天气好 = Today is fine”)喂给盒子,盒子会根据 “回答错误的程度”,一点点调整每个旋钮的位置,直到它能答对越来越多的问题;
训练后:所有旋钮的位置被固定下来,此时你再问它问题,它就能给出符合预期的答案 —— 这个 “调整旋钮到正确位置” 的过程,就是训练大模型的本质。
大模型的核心结构(比如有多少层、每层有多少个神经元 / 注意力头)在训练前后完全不变,唯一变化的是 “参数的数值”
训练前后,模型到底变了什么?
1. 直观层面:参数值从 “随机数” 变成 “有意义的数”
- 训练前:参数 1=0.872,参数 2=-0.156(随机数),输入 “猫”,模型输出 “桌子”;
- 训练后:参数 1=0.314,参数 2=0.925(调整后),输入 “猫”,模型输出 “一种哺乳动物”。
2. 逻辑层面:模型的 “计算规则” 没变,但 “计算结果” 从 “无意义” 变 “有意义”
- 训练前:输入 “今天下雨”→ 经过随机参数的矩阵运算→ 输出 “太阳很大”(无意义);
- 训练后:输入 “今天下雨”→ 经过调整后参数的矩阵运算→ 输出 “出门记得带伞”(有意义)3. 能力层面:模型从 “啥也不会” 变成 “具备特定能力”
3. 能力层面:模型从 “啥也不会” 变成 “具备特定能力”
- 训练前:模型没有任何 “知识” 和 “能力”,连最基础的语言通顺都做不到;
- 训练后:模型具备了训练数据对应的能力 —— 比如语言模型能聊天、写代码、翻译,图像模型能识别物体、生成图片,这些能力不是 “编程写死的规则”,而是参数值编码了数据规律后的 “涌现结果”。
4.为什么训练需要海量数据和算力?
- 海量数据:给模型足够多的 “正确样本”,让它知道 “什么是对的”;
- 巨大算力:每调整一次参数,都要对海量数据做一次全量计算,验证调整是否正确,这个过程需要成千上万的 GPU/TPU 并行运算。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)