Course16:AI服务核心:高并发原理与性能监控调优
KV Cache(Key-Value Cache,键值缓存)
KV Cache(Key-Value Cache,键值缓存) 是 Transformer 架构大模型在自回归推理(逐 token 生成)时的核心加速技术,通过缓存历史 token 的 Key/Value 向量,避免重复计算,将注意力计算复杂度从 O(n²) 降至 O(n),是大模型实时交互的关键工程优化。
核心原理
-
第 1 步(初始):计算所有输入 token 的 K、V,存入缓存。
-
第 2 步(生成):
-
仅计算新 token的 Q、K、V。
-
用新 Q 与缓存的全部 K 计算注意力权重。
-
用权重对缓存的全部 V 加权求和,得到输出。
-
将新 token 的 K、V 追加到缓存,序列长度 +1。
-
KV Cache 的代价与挑战
-
显存占用高:缓存需存储所有历史 K/V,长上下文(如 32k)显存开销巨大。
-
内存碎片化:动态追加易导致显存碎片,影响效率。
-
上下文长度限制:缓存大小决定模型能处理的最大序列长度。
主流优化方案(工程落地)
-
分组查询注意力(GQA/MQA):多头共享 K/V,大幅减少缓存体积。
-
PagedAttention(vLLM):用分页式内存管理 KV Cache,解决碎片化、支持高并发。
-
KV 量化(FP8/INT4):降低缓存位宽,节省显存。
-
滑动窗口 / 稀疏注意力:只缓存最近 N 个 token,控制缓存大小。
PagedAttention 存储映射

PagedAttention机制
1. 按需分配(on-demand allocation)
-
不像传统 KV Cache 一次性占满整个上下文长度(如 4k/32k)。
-
按块(block)分配,生成多少 token 就分配多少块。
-
显存利用率极高,不浪费、不预留、不空占。
一句话记: 用多少给多少,不提前占坑。
2. 写时复制(copy-on-write)
-
多个请求共享同一段前缀 KV Cache 时,先共用、不复制。
-
只有当某一路需要修改、追加、分叉时,才复制自己那一份。
-
大幅减少重复 KV 计算与显存拷贝。
一句话记: 能共享就共享,要改再复制。
3. 动态重排(dynamic reorder / defragmentation)
-
KV 块在物理上可以不连续,逻辑上连续。
-
系统能随时重组、移动块,解决显存碎片。
-
支持批量调度、动态换入换出(CPU/GPU 内存)。
一句话记: 物理乱没关系,逻辑连续就行,随时整理。
-
按需分配:省显存,不浪费。
-
写时复制:省拷贝,共享前缀。
-
动态重排:无碎片,支持高并发。
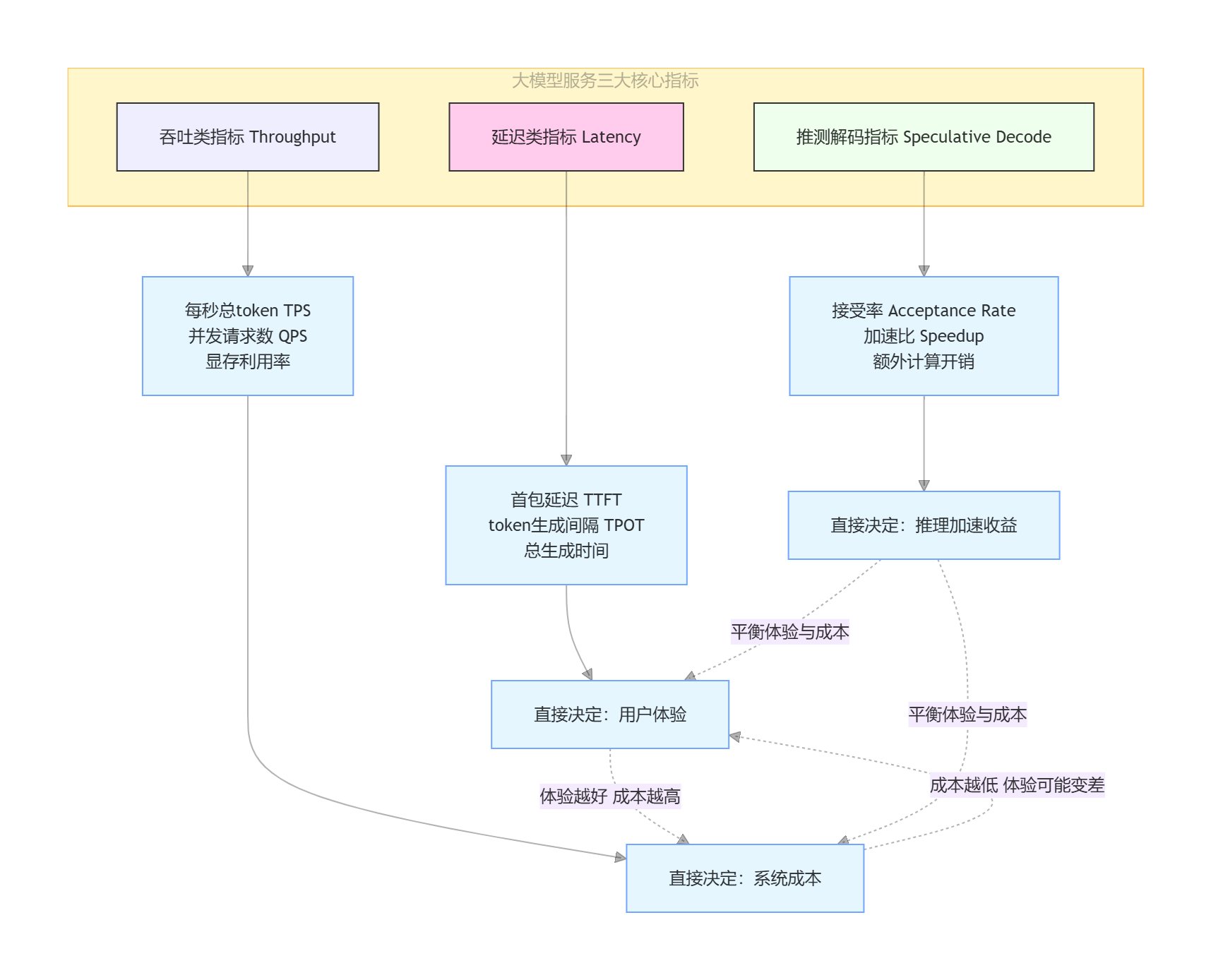
大模型三大核心指标
延迟类指标管用户体验,吞吐类指标管系统成本,推测解码指标管加速收益
vLLM系统架构
vLLM 是基于 PagedAttention 实现的高性能 LLM 推理引擎,采用三层进程架构 + 调度 - 执行分离 + 分布式 Worker 设计(把 LLM 推理从 “显存瓶颈” 变成 “算力瓶颈”),核心是用虚拟内存式 KV 缓存管理实现极致显存利用率与高并发。
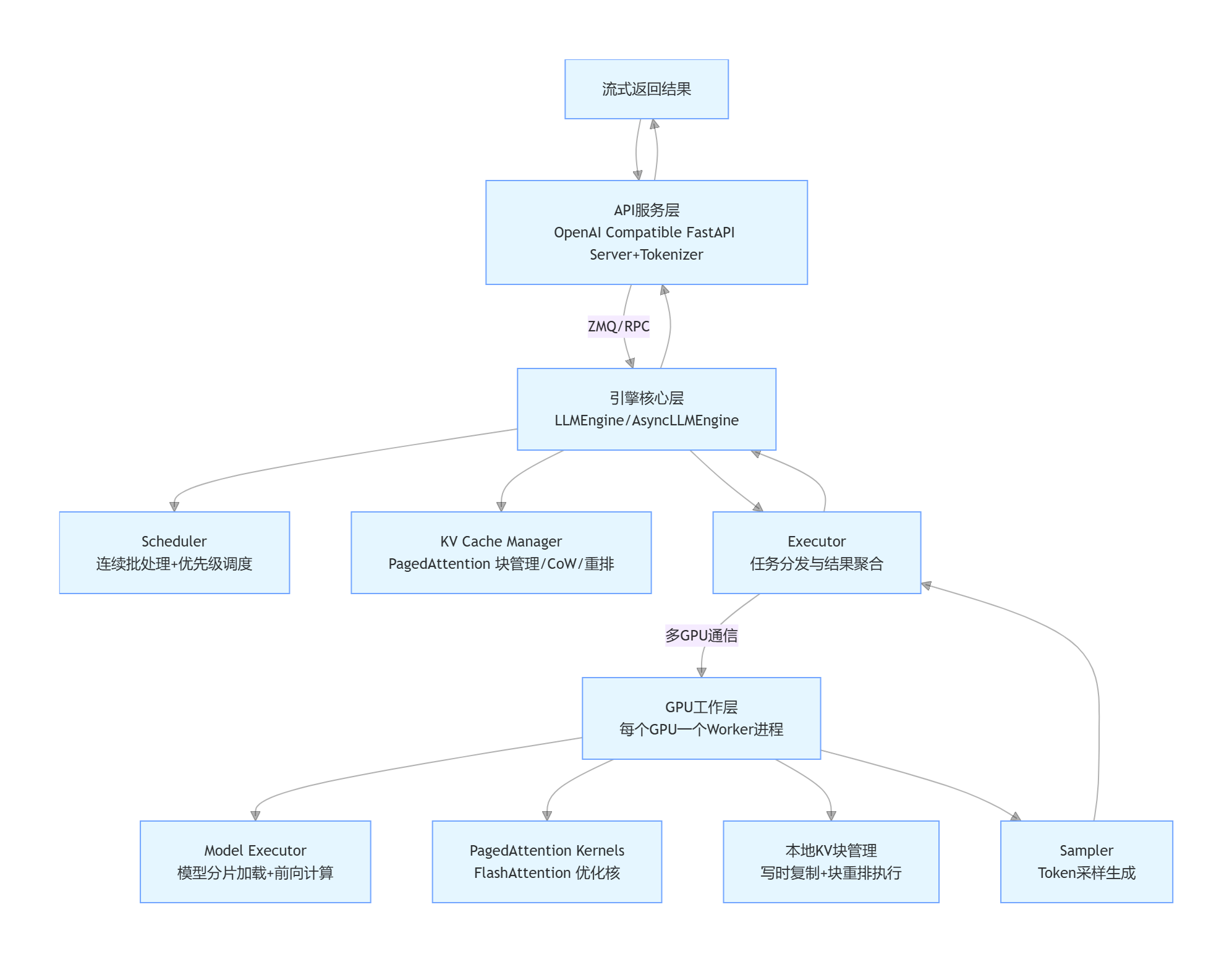
核心数据流(请求生命周期)
-
用户请求 → API 服务 → 分词 → 生成 Sequence 对象 → 入队。
-
Scheduler 选批 → 为序列分配 KV 块 → 生成任务下发给 Executor。
-
Executor 分发到对应 GPU Worker → 执行 PagedAttention + 模型前向。
-
生成新 Token → 更新 KV 缓存(追加块) → 返回 Token 到引擎。
-
引擎判断是否完成 → 流式返回给 API → 最终返回用户。
极致显存利用率:PagedAttention 减少碎片、支持高并发(数千请求)。
高吞吐低延迟:连续批处理 + 高效注意力核,比传统方法提升 5–20 倍。
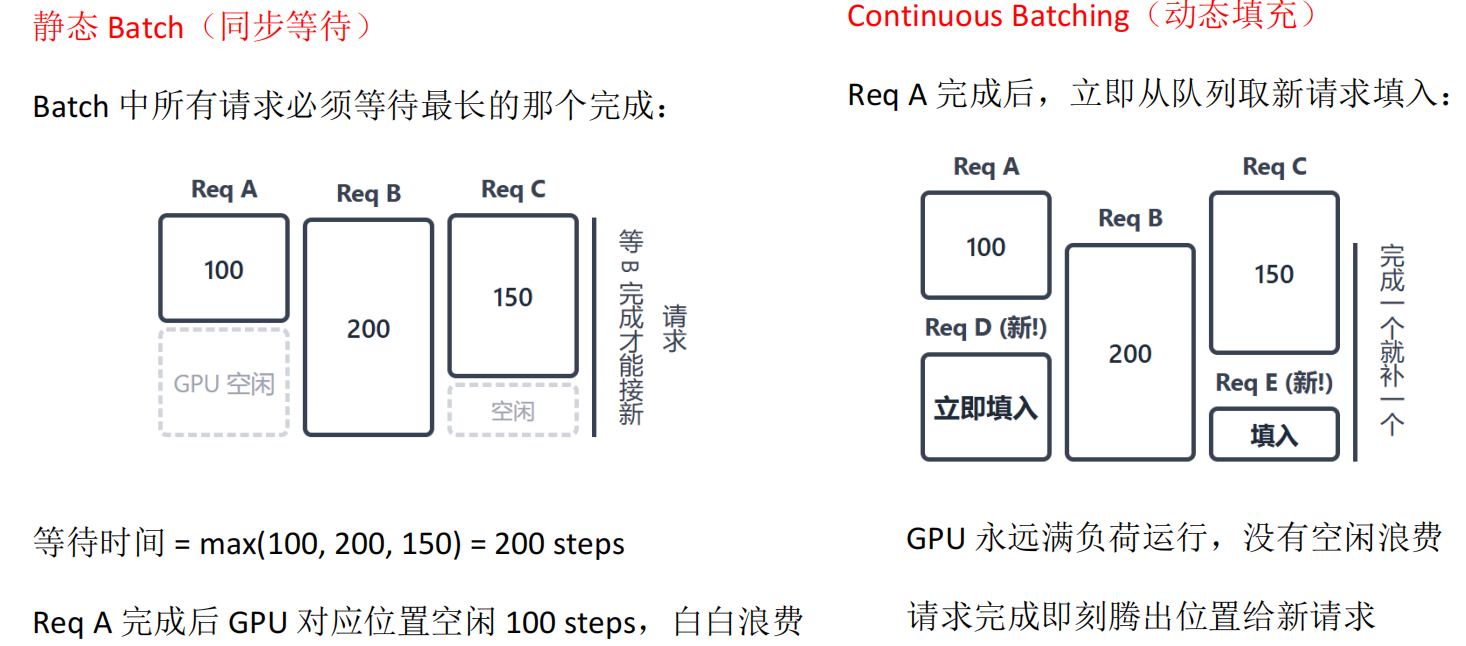
Batch
1. 核心规则(死记硬背)
-
真实有效 token:相同前缀 → 共享 KV Cache
-
Padding token(填充位):
不计算 KV、不缓存、不共享
模型直接跳过它,不存 KV,也不参与注意力计算
模型用 attention_mask 区分:
• 1 = 有效词 → 算 KV,缓存
• 0 = padding → 屏蔽,不算 KV,不缓存
所以 padding 从头到尾不参与 KV Cache 的任何共享和存储。
相同有效输入前缀 ✅ 共享 KV Cache
Padding 填充位 ❌ 不共享、不计算、不缓存
输出分支不同 ❌ 不共享,独立存储
vLLM 的 Iteration-level Scheduling(伪代码)

-
vLLM Iteration-level Scheduling 核心总结 ✨
-
核心机制
• 调度粒度:以 ** 单次迭代(生成一个 token)** 为单位进行调度,而非等待整个 batch 请求全部完成(Request-level)。
• 核心流程:
-
处理新请求:对新到达的请求计算所需显存块数并分配,加入当前 batch。
-
前向传播:对 batch 内所有请求执行一次前向传播,各生成一个 token。
-
清理完成请求:检查请求是否生成结束(EOS),若结束则立即释放其占用的显存块(PagedAttention),并从 batch 中移除。
-
-
| 维度 | Iteration-level (vLLM) | Request-level (传统) |
|---|---|---|
| 调度时机 | 每生成 1 个 token 后 | 整个 batch 所有请求完成后 |
| 资源释放 | 即时释放完成请求的显存块 | 等待 batch 结束后统一释放 |
| 新请求加入 | 本迭代即可加入 | 需等待当前 batch 完全结束 |
| 资源利用率 | 更高,低延迟 | 较低,易造成资源闲置 |
推测解码
推测解码(又称投机采样)来自论文《Fast Inference from Transformers via Speculative Decoding, 2023》。
角色分工: 草稿模型(Draft Model小模型,比如 7B):跑得快,先批量生成几个 “候选 token”,相当于先写个草稿。 目标模型(大模型,比如 70B):精度高,只需要对草稿里的候选 token 做一次验证,接受对的、拒绝错的,最终输出高质量结果。
相同输入前缀
I love you → ,不重复算
Padding
全部跳过,不缓存、不共享
分支(Beam Search)
分支一旦不同,KV Cache 立刻分开,不共享
投机采样
小模型猜、大模型验,大模型推理次数越少,速度越快
用同架构小模型做 Draft,是投机采样加速大模型的最优选择,
α 值直接决定了最终能实现多少倍的推理速度提升。

MEDUSA推理框架
medusa heads
妙解,大模型自带多预测头,一次猜一串 token,加速推理
论文:《Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads》(2024)
=>核心思想:去掉独立的 Draft Model
传统推测解码需要一个独立的小模型做 Draft,工程上不够优雅(要维护两个模型)
MEDUSA 提供 One Model 的方案:在原始模型上增加多个解码头 (Multiple Decoding Heads)
不做 Next-Token 预测,而是做 Next-Next-Token 预测 -- 多个 Head 并行预测未来若干 token
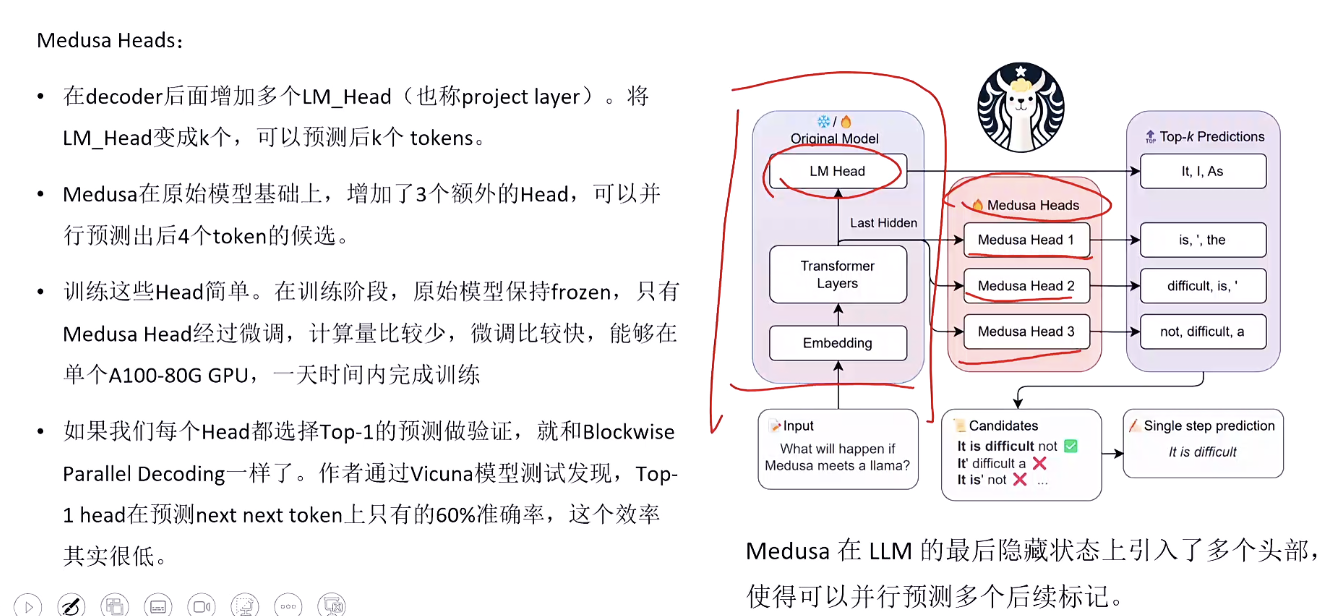
Tree Attention
树状并行,一次算出多条路径,看清好几个未来的token
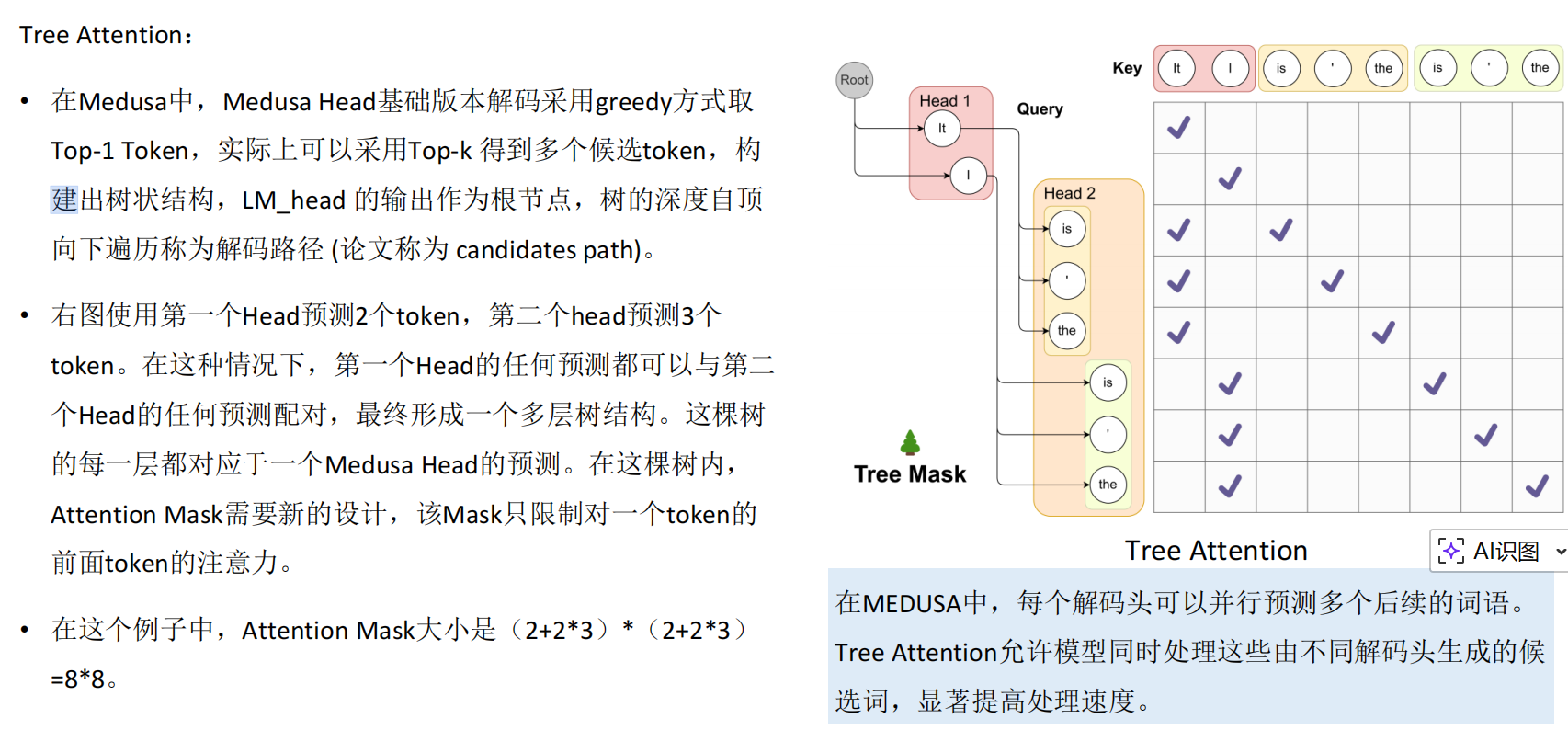
Medusa 里大模型的验证,就是把 “多往后猜的 2 个 token” 一起塞进一次前向传播,用 Tree Attention 算出它们的真实概率,然后从左到右挨个接受,直到遇到概率不够的就截断。
| 方式 | 验证时机 | 验证次数 | 核心逻辑 |
|---|---|---|---|
| Medusa | 同一次前向传播内 | 1 次(算完整棵树) | 大模型自己算每个候选的条件概率,一次性校验 |
| 投机采样 | 小模型猜完后 | 1 次(验整串候选) |
大模型对小模型的草稿做概率校验,接受对的、拒绝错的 |
EAGLE推理框架
https://github.com/SafeAILab/EAGLE
EAGLE的核心思想是在特征层面(即模型的倒数第二层)进行自 回归处理,而不是在token层面,并通过将下一个时间步的token序列纳入draft model来解决预测下一个特征时的不确定性问题。
传统推测解码的三大痛点
• 独立 Draft 模型:需要维护两个模型(如 LLaMA-7B 给 LLaMA-70B 做草稿),部署复杂
• Token 级预测:离散 token 的不确定性高(如 "I" 后面可能是 "am"、"always"、"like"),预测难度大
• 静态结构:不管输入是简单算术还是复杂推理,草稿树结构固定,资源浪费
EAGLE-3 解决了前辈的 “训练 - 推理不一致” 和 “特征约束瓶颈”,让多步预测的接受率更稳定,同时把计算调度得更贴合 GPU 并行特性,满载时也能高效榨干算力,不会因为负载变高就掉速。
EAGLE-3 BUFF叠满--- “更灵活的特征表达 + 训练推理对齐 + 高效 GPU 调度”,在高负载下依然能维持高接受率和高算力利用率,所以满载时加速比几乎不降。
推理框架三者对比
Speculative Decoding:外搭小模型猜 token,靠 “小模型跑腿、大模型验” 提速
MEDUSA:大模型自己多长头,一次前向并行猜多步 token
EAGLE:在特征层面先猜再转 token,精度与速度更平衡
EAGLE相比 MEDUSA,特征级预测更精准;相比投机采样,无需额外小模型;额外工作:基于feature和token计算新feature,再预测token

和其他方案的空间 / 时间对比
EAGLE 确实是用「额外特征缓存 + 自回归模块」的空间开销,换取「更高验证通过率 + 更少大模型推理步数」的时间收益,属于典型的 “空间换时间” 优化策略。
| 方案 | 空间开销 | 时间收益 | 本质 |
|---|---|---|---|
| Speculative Decoding | 高(需存两个独立模型) | 中(依赖小模型精度) | 模型级空间换时间 |
| MEDUSA | 中(新增多头参数) | 中高(多步并行预测) | 参数级空间换时间 |
| EAGLE | 中高(特征缓存 + 自回归模块) | 高(特征级预测通过率更高) | 特征级空间换时间 |
EAGLE与GRPO的相似性
| 维度 | EAGLE-1/2 | GRPO |
|---|---|---|
| 训练阶段 | 用目标模型的真实特征(标准答案)训练 Draft Model | 用模型自己生成的样本 + 奖励信号做 RLHF 训练 |
| 推理阶段 | 用 Draft Model 自己生成的特征(带误差)继续预测 | 用模型自己生成的序列继续生成,依赖之前的决策 |
| 核心问题 | 训练 - 推理分布不一致 → 误差累积 → 加速比饱和 | 训练时的 “最优样本” 和推理时的 “自生成样本” 分布偏移 → 奖励信号泛化差 → 效果天花板 |
| 本质 | 都是 “理想环境训练,真实环境推理”,导致模型在自回归场景下的鲁棒性不足 |
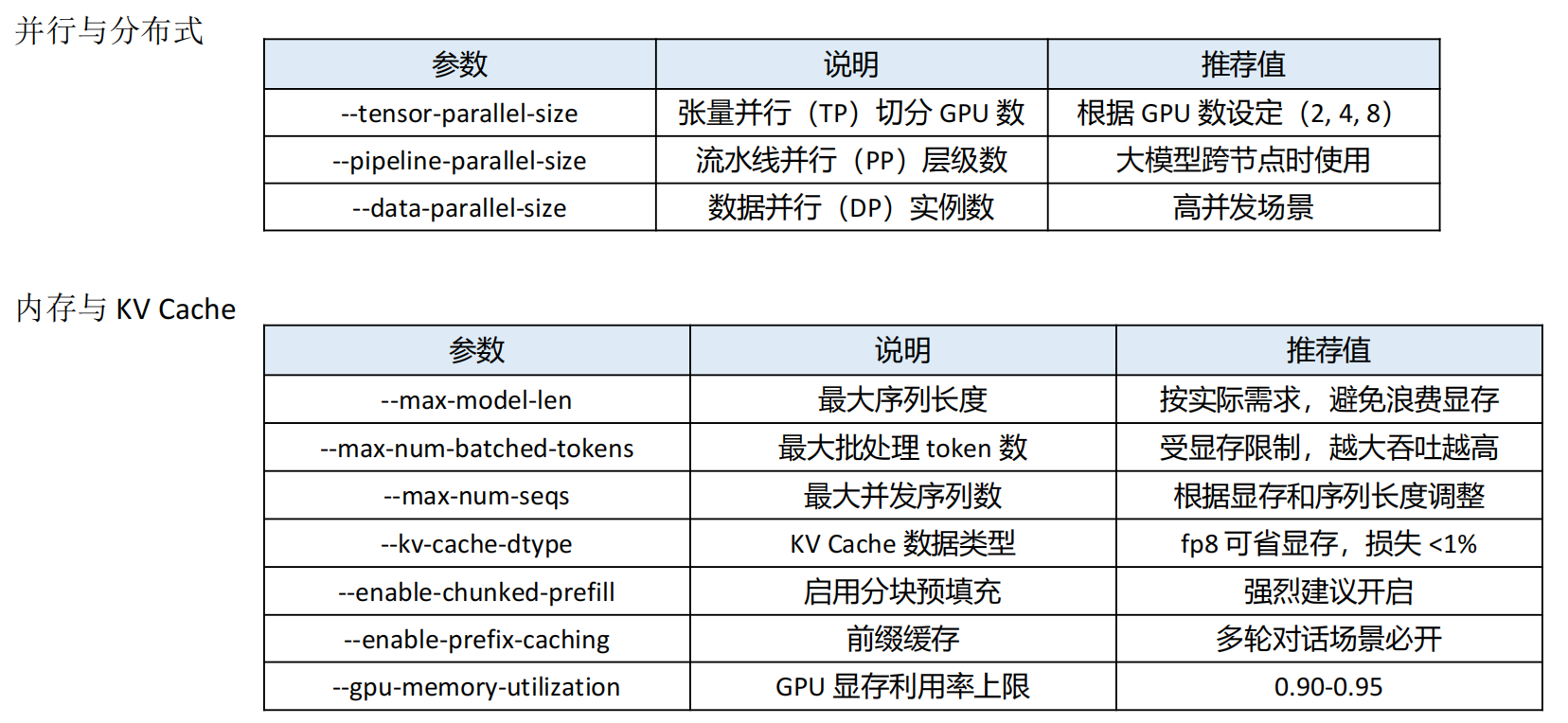
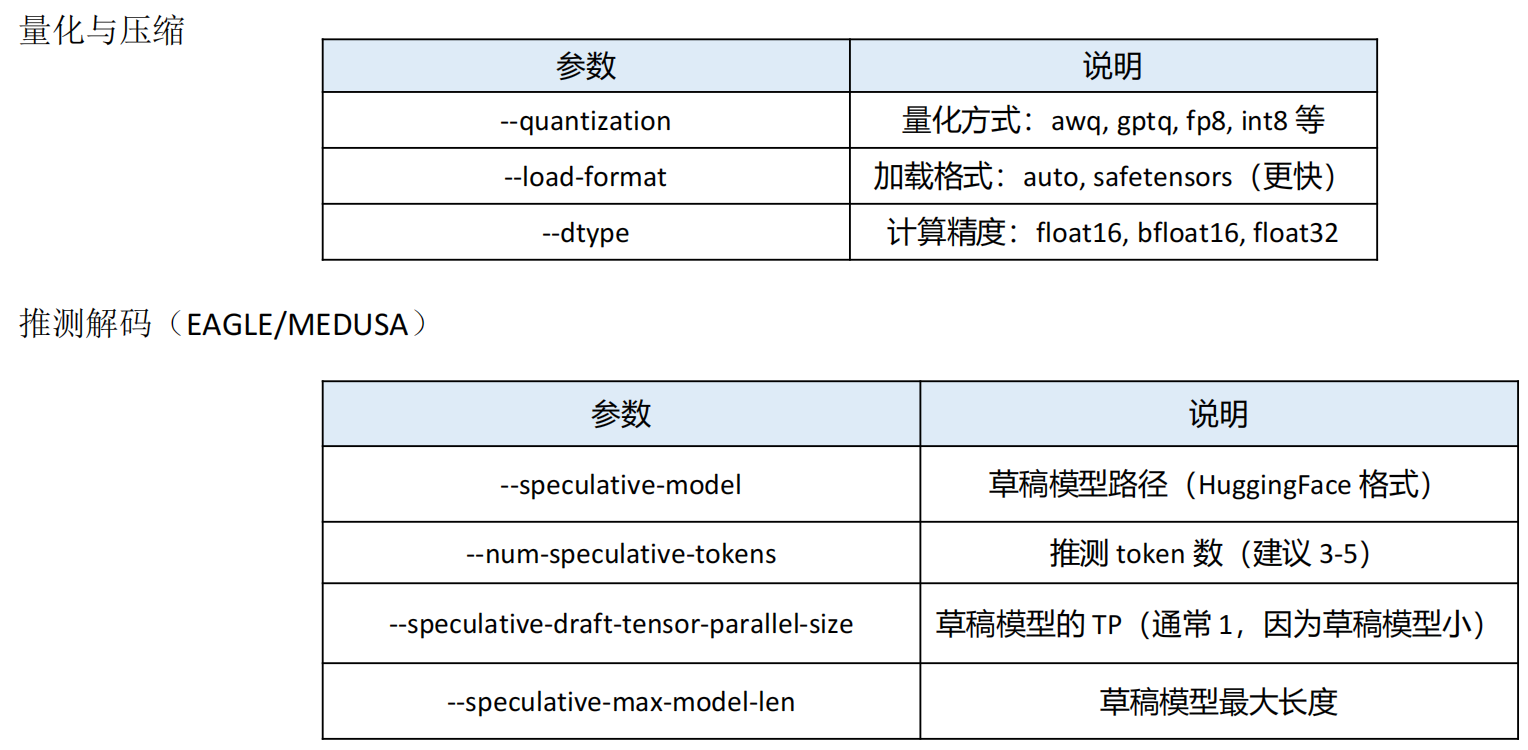
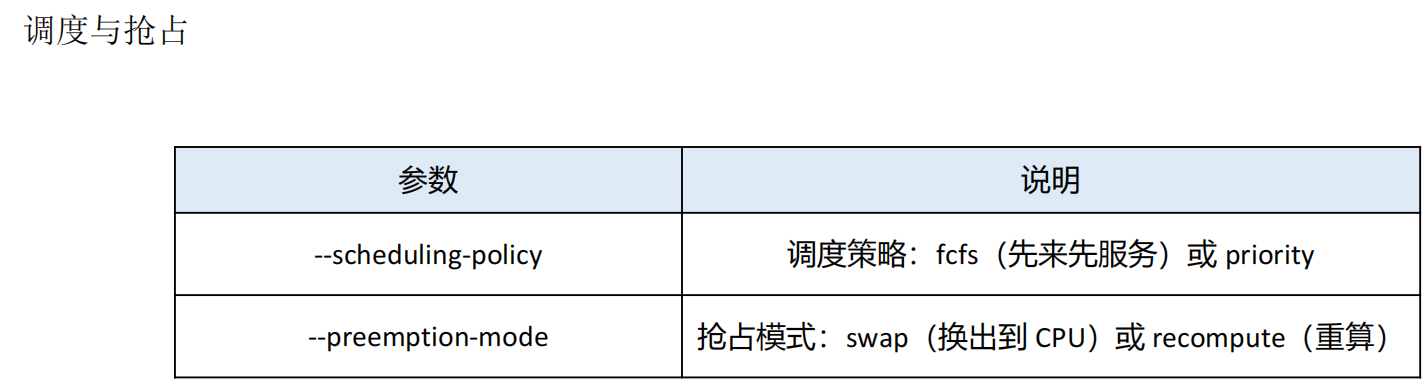
vLLM 核心优化参数
Q&A
Q:如何评估一套LLM实例所能够服务的并发数的上限?如何系统地优化并发上限?
测试,8个并发,16个并发,32个并发,128个并发
=> 输出的token性能
Q:在企业里面比如用vllm部署了一个大模型,各个部门都用上,还需要哪些
vllm 部署底层 => API服务器endpoint
Agent开发框架 => LangChain/LangGraph, Qwen-Agent, LlamaIndex
Q:知识库做excel和pdf的chunk有没有什么好的方案呢?
pdf =》 chunk 切片 =》 embedding相似度检索
excel =》 sql查询 => 精确查询
Q:在开发层面有没有什么好用的skill呢?
clawhub
Q:pdf中的表格呢
minerU解析 => html格式
Q:pdf rag 有没有公开数据集 可以用于练习
huggingface
Model 参数 => 部署环境 (加速,medusa, eagle) VLLM
https://github.com/SafeAILab/EAGLE
bash 1-启动vLLM服务.sh basic
Q:模型越小,是不是生成速度越快?
和模型参数量相关,参数量越小 => 速度越快
Q:我们能够部署300B模型嘛
可以用 8个A800
Q:vllm是不是只能在英伟达的gpu环境上跑,不能在CPU上试用
CPU用不了
Q:vllm 是不是始终霸占显存,不像ollama可以随时释放
--gpu-memory-utilization 0.4
Q:多大算大BATCH
针对你的GPU,可以将GPU显卡利用率占的很慢的batch
batch = 128
batch = 4
Q:这节课大纲
vllm:
1)PagedAttention
2)Continuous Batching
===
推测解码
1)target model, draft model
2)medusa, eagle
3) vllm 里面可以配置
===
vllm指标监控

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)