三维点云处理-聚类 3.3 GMM (高斯混合模型)
一、高斯混合模型介绍
高斯混合模型(GMM)通过高斯分布描述每个类别的数据分布。与K-means仅提供中心点不同,GMM采用概率模型实现soft assignment,可计算每个数据点属于各类别的概率。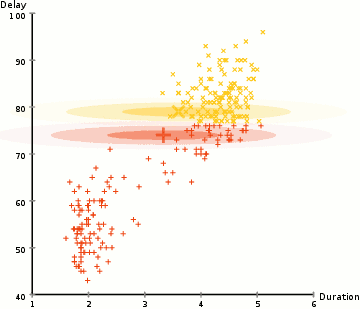
高斯混合模型的最大似然估计流程分为两步迭代:
-
E-step:计算后验概率γ(zₙₖ)=πₖN(xₙ|μₖ,Σₖ)/∑ⱼπⱼN(xₙ|μⱼ,Σⱼ),实现软分配
-
M-step:更新模型参数
- μₖ更新为当前簇的加权均值
- Σₖ更新为加权协方差
- πₖ更新为簇占比
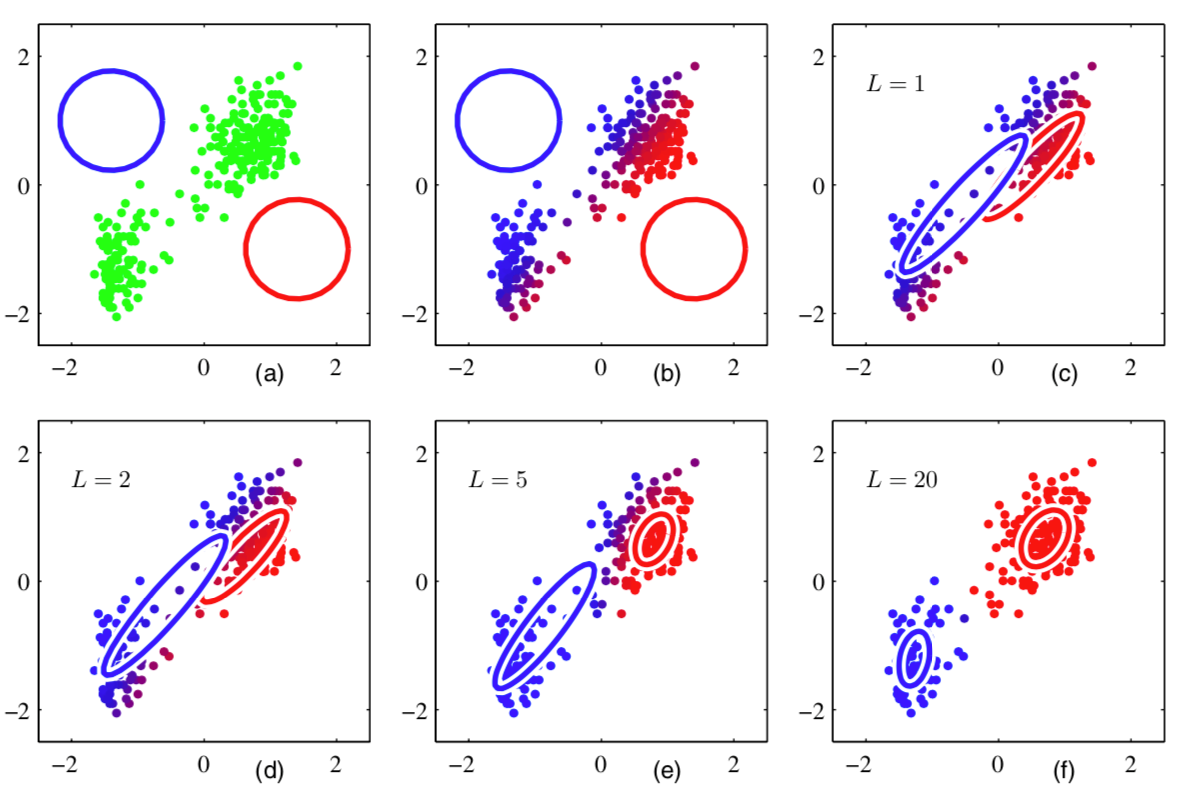
- 初始化需指定各高斯分布的权重、均值和协方差。迭代过程中,协方差矩阵可能从各向同性(圆形)发展为各向异性(椭圆),最终收敛至数据分布的最优表示。
这张图片是对高斯混合模型(Gaussian Mixture Model, GMM) 的简明总结,内容涵盖其时间复杂度、优势与劣势,具体如下:
二、时间复杂度
O(t⋅k⋅n⋅d) O(t \cdot k \cdot n \cdot d) O(t⋅k⋅n⋅d)
其中:
- $ t $:EM 算法的迭代次数
- $ k $:预设的高斯成分(簇)数量
- $ n $:数据点总数
- $ d $:每个数据点的维度(特征数)
→ 表明 GMM 的计算开销随维度、样本量和簇数线性增长,对大规模高维数据可能较慢。
三、主要优势
- 提供不确定性估计(soft assignment):不同于 K-means 的硬聚类,GMM 给出每个点属于各簇的概率分布(如:点 x 以 70% 概率属簇 A,30% 属簇 B),更适合建模模糊边界或重叠结构。
- 对离群点(outliers)更鲁棒:因基于概率密度建模,单个异常点对整体参数影响相对较小(相比基于距离的算法如 K-means 更不易被拉偏)。
四、主要劣势
- 需预先指定簇数 kkk:无自动确定最优 kkk 的内置机制(常依赖 BIC/AIC 或交叉验证)。
- 仅适用于近似凸形/椭球形簇:因每个成分是多元高斯分布,等概率面为椭球,难以拟合弯曲、带状或非凸结构(如环形、月牙形)。
- 存在奇异性(singularity)问题:当某个高斯成分坍缩到单个点(协方差矩阵行列式 → 0),对数似然趋于无穷,导致 EM 算法崩溃——需通过正则化、协方差约束或先验(如 Bayesian GMM)缓解。
你这段代码其实是一个「从零实现 + 演示」版的 GMM(高斯混合模型),用 EM 算法做聚类,并用 KMeans 做初始化。我们按模块拆开讲,一步步把它“拆开看懂”。
代码相关
一、代码介绍
代码做的事情可以概括成:
- 生成三簇二维高斯分布的数据(
generate_X) - 用 GMM 对这些数据做聚类(
GMM.fit+GMM.predict) - 把聚类结果画出来(不同颜色表示不同簇,灰色点表示均值)
二、GMM 类的核心属性
class GMM(object):
def __init__(self, n_clusters, max_iter=50):
self.__K = n_clusters
self.__max_iter = max_iter
self.__posteriori = None # 后验概率 γ_{k,n}
self.__mu = None # 每个高斯分量的均值 μ_k
self.__cov = None # 每个高斯分量的协方差 Σ_k
self.__priori = None # 每个高斯分量的先验概率 π_k
__K:簇的个数(高斯分量个数)__posteriori:大小为(K, N),第k行第n列表示样本n属于簇k的后验概率 (\gamma_{k,n})__mu:形状(K, D),每一行是一个簇的均值向量__cov:形状(K, D, D),每个簇一个协方差矩阵__priori:形状(K, 1),每个簇的混合系数 (\pi_k),且 (\sum_k \pi_k = 1)
三、fit:EM 算法的主循环
def fit(self, data):
N, _ = data.shape
# 1. 用 KMeans 初始化 GMM 参数
self.__init_kmeans(data)
# 2. EM 迭代
for i in range(self.__max_iter):
# E 步:更新后验概率 γ_{k,n}
self.__get_expectation(data)
# 有效样本数 N_k = ∑_n γ_{k,n}
effective_count = np.sum(self.__posteriori, axis=1)
# M 步:更新 μ_k
self.__mu = np.asarray(
[np.dot(self.__posteriori[k], data)/effective_count[k] for k in range(self.__K)]
)
# M 步:更新 Σ_k
self.__cov = np.asarray(
[
np.dot(
(data - self.__mu[k]).T,
np.dot(np.diag(self.__posteriori[k].ravel()), data - self.__mu[k])
)/effective_count[k] for k in range(self.__K)
]
)
# M 步:更新 π_k
self.__priori = (effective_count / N).reshape((self.__K, 1))
1)初始化
- 调用
self.__init_kmeans(data),用 KMeans 的结果来初始化:- 均值
μ_k= KMeans 的簇中心 - 协方差
Σ_k= 每个簇内样本的协方差 - 先验
π_k= 每个簇样本数 / 总样本数 - 后验
γ_{k,n}先设为 0
- 均值
2)E 步:计算后验概率
在循环中,先调用 __get_expectation(data),它会根据当前的 μ_k, Σ_k, π_k 计算每个样本属于每个簇的概率(后面单独讲)。
3)M 步:更新参数
-
有效样本数:
对应代码:
effective_count = np.sum(self.__posteriori, axis=1) # 形状 (K,) -
更新均值:
对应代码:
self.__mu = np.asarray( [np.dot(self.__posteriori[k], data)/effective_count[k] for k in range(self.__K)] )这里
self.__posteriori[k]是形状(N,),data是(N, D),点乘后得到(D,),再除以N_k。 -
更新协方差:
对应代码:
self.__cov = np.asarray( [ np.dot( (data - self.__mu[k]).T, np.dot(np.diag(self.__posteriori[k].ravel()), data - self.__mu[k]) )/effective_count[k] for k in range(self.__K) ] )解释一下:
data - self.__mu[k]:形状(N, D)np.diag(self.__posteriori[k].ravel()):形状(N, N),对角线上是 γ_{k,n}- 中间那一乘相当于对每个样本的偏差
(x_n - μ_k)乘上权重 γ_{k,n} - 最后左乘转置
(D, N),得到(D, D)的协方差矩阵
-
更新先验概率:
对应代码:
self.__priori = (effective_count / N).reshape((self.__K, 1))
四、predict:用后验概率做分类
def predict(self, data):
self.__get_expectation(data)
result = np.argmax(self.__posteriori, axis = 0)
return result
- 先重新计算一次后验概率
γ_{k,n} - 对每个样本
n,找出后验概率最大的簇k,作为该样本的类别标签 self.__posteriori形状是(K, N),axis=0表示对每一列(每个样本)取最大值所在的行索引
五、初始化方法:随机 & KMeans
1)随机初始化(代码里没用到,但实现了)
def __init_random(self, data):
N, _ = data.shape
self.__posteriori = np.zeros((self.__K, N))
self.__mu = data[np.random.choice(np.arange(N), size=self.__K, replace=False)]
self.__cov = np.asarray([np.cov(data, rowvar=False)] * self.__K)
self.__priori = np.ones((self.__K, 1)) / self.__K
- 随机选
K个样本作为初始均值 - 协方差全部用整体数据的协方差
- 先验概率均匀分布
2)KMeans 初始化(实际使用的)
def __init_kmeans(self, data):
N, _ = data.shape
k_means = KMeans(init='k-means++', n_clusters=self.__K)
k_means.fit(data)
category = k_means.labels_
self.__posteriori = np.zeros((self.__K, N))
self.__mu = k_means.cluster_centers_
self.__cov = np.asarray(
[np.cov(data[category == k], rowvar=False) for k in range(self.__K)]
)
value_counts = pd.Series(category).value_counts()
self.__priori = np.asarray(
[value_counts[k]/N for k in range(self.__K)]
).reshape((self.__K, 1))
- 用 KMeans 的结果来:
- 均值:直接用簇中心
- 协方差:对每个簇内的数据单独算协方差
- 先验:每个簇的样本数 / 总样本数
这样初始化通常比完全随机更稳定,EM 更容易收敛到“好一点”的解。
六、E 步:计算后验概率 __get_expectation
def __get_expectation(self, data):
for k in range(self.__K):
self.__posteriori[k] = multivariate_normal.pdf(
data,
mean=self.__mu[k], cov=self.__cov[k]
)
self.__posteriori = np.dot(
np.diag(self.__priori.ravel()), self.__posteriori
)
self.__posteriori /= np.sum(self.__posteriori, axis=0)
这一步对应 EM 算法中的 E-step:
-
计算似然 ( p(x_n | z_n = k) )
multivariate_normal.pdf(data, mean=self.__mu[k], cov=self.__cov[k])对所有样本
data计算在第k个高斯分布下的概率密度,得到形状(N,)的数组,存到self.__posteriori[k]中。 -
乘上先验 ( \pi_k )
self.__posteriori = np.dot( np.diag(self.__priori.ravel()), self.__posteriori )这里相当于对每一行(每个簇)乘上对应的
π_k。 -
归一化,得到后验概率:
对应代码:
self.__posteriori /= np.sum(self.__posteriori, axis=0)对每一列(每个样本)做归一化,使得对所有簇的概率和为 1。
七、数据生成函数 generate_X
def generate_X(true_Mu, true_Var):
num1, mu1, var1 = 400, true_Mu[0], true_Var[0]
X1 = np.random.multivariate_normal(mu1, np.diag(var1), num1)
num2, mu2, var2 = 600, true_Mu[1], true_Var[1]
X2 = np.random.multivariate_normal(mu2, np.diag(var2), num2)
num3, mu3, var3 = 1000, true_Mu[2], true_Var[2]
X3 = np.random.multivariate_normal(mu3, np.diag(var3), num3)
X = np.vstack((X1, X2, X3))
return X
- 一共三簇数据,每簇是一个二维高斯分布:
- 均值:
true_Mu[i] - 协方差:用
np.diag(true_Var[i])构造对角矩阵,也就是两个维度之间不相关
- 均值:
- 每簇样本数分别是 400、600、1000
- 最后用
vstack拼成一个(2000, 2)的数据集
八、主程序:训练 + 可视化
if __name__ == '__main__':
K = 3
true_Mu = [[0.5, 0.5], [5.5, 2.5], [1, 7]]
true_Var = [[1, 3], [2, 2], [6, 2]]
X = generate_X(true_Mu, true_Var)
gmm = GMM(n_clusters=K)
gmm.fit(X)
category = gmm.predict(X)
color = ['red','blue','green','cyan','magenta']
labels = [f'Cluster{k:02d}' for k in range(K)]
for k in range(K):
plt.scatter(X[category == k][:,0], X[category == k][:,1], c=color[k], label=labels[k])
mu = gmm.get_mu()
plt.scatter(mu[:,0], mu[:,1] ,s=300, c='grey', marker='P', label='Centroids')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.title('GMM Testcase')
plt.show()
流程:
- 生成数据:三簇二维高斯
- 创建 GMM 模型:
GMM(n_clusters=3) - 训练:
gmm.fit(X),执行 EM 算法 - 预测类别:
category = gmm.predict(X) - 画图:
- 不同簇用不同颜色散点
- 用
gmm.get_mu()得到每个簇的均值,用灰色大点标出来

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)