机器学习三种评估方法
机器学习中常见的模型评估方法有三种,留出法、K-折交叉验证法、自助法,它们主要用于衡量模型的泛化能力。
首先是第一种方法:留出法(Hold-out Method)
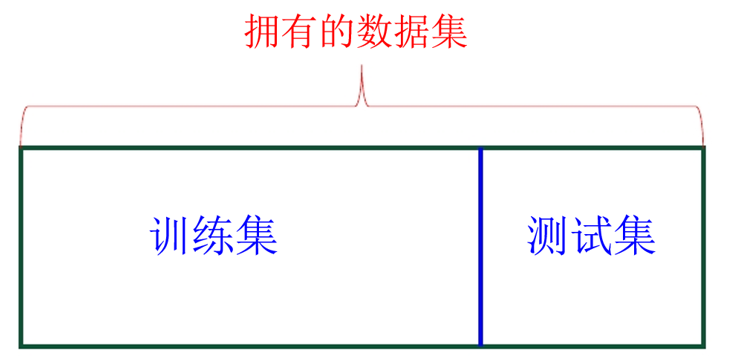
核心思想:
将数据集一次性划分为两部分:训练集(Train Set)、测试集(Test Set).
本质:
用“没有见过的数据”来检验模型是否真的学会了。
流程:
第一步:先随机打乱数据(shuffle)
第二步:按照比例进行划分,比如:70%训练 + 30%测试;
第三步:在训练集上训练模型;
第四步:在测试集上评估模型的性能。
(在这里有个注意事项:需要保持数据分布的一致性;需要多次进行重复划分,得出的100次结果取平均值;测试集不能太大也不能太小。)
留出法的优缺点:
优点:简单易实现;计算速度快;适合大数据。
缺点:结果不稳定;数据利用率低;对划分方式敏感。
缺陷:
它的训练集不能太小,假设我们想要的效果是"M100",但是我们分出来的训练集只有“M80”,我们的目的是为了让“M80”去近似逼近“M100”,如果“M80”变小,那么近似能力就会变差,而我们希望要的是“M100”的效果,所以“M80”是不可以变小的,测试集越大越好;假设“err80”是测试集,如果测试集越来越小,“err80”测得越不准,所以我们希望err也要大一点,测试集越大越好。现在面临着一个情况,训练集越大越好,测试集也是越大越好,但是数据就摆在这里,就那么点数据,两边都需要越大越好,这就起了冲突。
问题:
在留出法中,总有一些数据从始至终都没有被用到过,就算我们迭代了100次,也会有一点数据从未被用到过。打个比方,就像老师在上面讲知识点,老师说这个知识点不用记,它从来没有在考试中出现过,然后你就真的没有学这个知识点,突然!在一次考试中这个知识点非常罕见的出现在了考试中,并且它还不是选择题不能瞎蒙蒙混过关怎么办?自认倒霉咯。换算到机器学习中,训练集从来没有被迭代训练过的那一点数据在测试集当中出现了!那我们的模型准确率就会降低。
怎么解决这个问题?→→“K-折交叉验证法”
第二种方法:K-折交叉验证法(K-Fold Cross Validation)
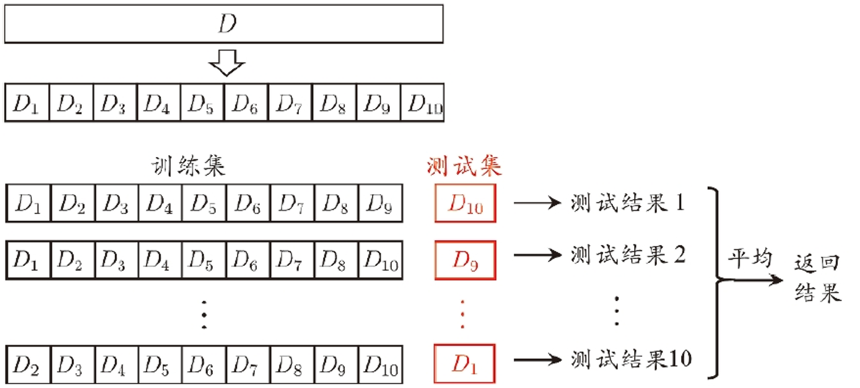
核心思想:
将数据集分成K份,轮流使用其中一份做测试,其余做训练,最后取平均结果。
本质:
用多次“不同划分”的结果,替代一次不稳定的输出法。
流程:
假设k=10
第一步:将数据随机打乱;
第二步:将数据集平均分成5份(F1、F2、……、F9、F10);
第三步:进行十次训练:
| 轮次 | 训练集 | 测试集 |
|---|---|---|
| 第一次 | F2+F3+~+F9+F10 | F1 |
| 第二次 | F1+F3+~+F9+F10 | F2 |
| …… | …… | …… |
| 第九次 | F1+F2+~+F8+F10 | F9 |
| 第十次 | F1+F2+~+F8+F9 | F10 |
第四步:得到十个评估结果;
第五步:将十个结果取平均值作为最终性能。
这里又有一个问题:K取多少合适?
当K=5时,它更常用,效率很高;
当K=10时,更稳定(推荐);
当K值很大,就会变成留一法(后面会讲到)。
K-折交叉验证法优缺点:
优点:结果更稳定;数据利用率高;泛化能力评估更可靠。
缺点:计算成本高;实现比留出法更复杂。
基于流程的第三步,训练:
当我们的k=10时,相当于做了10次测试,模型的每一次测试就将其中的一个子集(也就是其中一份)做测试集,剩下9个子集做训练集进行训练,这样整个数据集都在测试集中出现过,最后将10个结果平均就是模型的最终结果。
但是!在切分数据集时也会有不同的划分,就是在最初划分子集时不是只划分一次就没事了,在最初划分子集时就会有不同的划分,这也会导致数据子集发生变化,这个变化也会影响模型估计的性能,所以我们将最初的切分也随机切分十次,然后再进行后续的训练。这种方法就叫做“10乘10交叉验证法”,最后也是做了100次实验,和留出法一样都做了100次。
那么此时的训练集我们划分为“M90”,因为“M90”要比留出法的“M80”更接近“M100”,测得更准。如果我们要做到极致,每一次只留出来一个样本做测试,剩下的99个样本作为训练集,再将所有的样本再测试一遍,此时的“M99”来估计“err99”来逼近“M100”,这样会更加准确,这个方法也就是我们上面提到的“留一法”(leave-one-out,LOO)。
问题:
当我们要做一个“M100”的模型,但是数据太少,每次用“M99”用来做模型,但是给测试集留下的数据只有“err1”,但是如果给测试集多留一点,留“err40”,那训练集的“M60”又与“M100”之间差距很大。有没有一个方式可以在训练时就能够训练出“M100”同时又可以留出很多数据用来做测试?有的兄弟,有的,这个方法就叫做“自助法”。
第三种方法:自助法(Bootstrap)
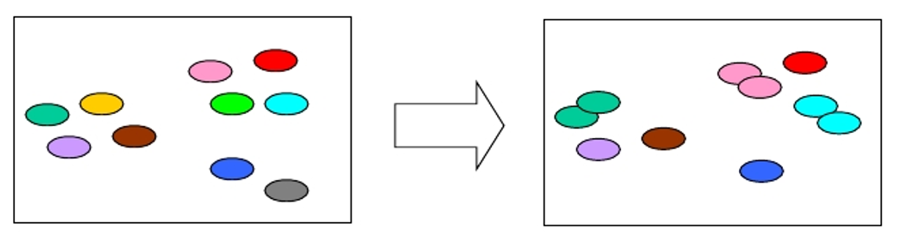
自助法,基于自动采样(Bootstrap Sampling),亦称“有放回采样”、“可重复采样”。
核心思想:
通过“有放回抽样”生成多个训练集。
本质:
用“重采样的数据”去近似“真实数据分布”。
流程:
第一步:从原数据集中“有放回抽样”得到新训练集;
第二步:未被抽到的数据作为测试集;
第三步:重复多次,取平均结果。
自助法的优缺点:
优点:数据利用率很高(核心优势);自带“测试集”(就是那36.8%);实现简单,通用性强。
缺点:引入偏差(最大的问题);有效样本减少(只有约63.2%);对异常值敏感。
观察上图:
一个盒子里放了十个球,每次摸一个球就copy以下,再将球放回去,下次再取一个球,再copy一下,再将球放回去,多次重复上述操作,此时就会有球被多次拿出来过,也有的球一次都没有被拿出来过。我们已经取出过很多个球进行copy并放回盒子里了,此时如果我们再取球,还是可以在盒子中的十个球随机抽取一个,也就是盒子里还是有十个球。
假设要用100个数据做模型,这时就可以采样出100个数据去做模型,同时没有被采样出过的数据就可以去做测试集,那没有被出现过的数据大概有多少呢?
假设数据集中有M个球,每一次从中有放回抽样M次。每一次抽样抽到该球的概率为1/M,那没有被抽到的球的概率为1-1/M,那我们取M次,M次都没被抽到的概率是(1-1/M)**M。就变成了一个经典求极限:limM→∞(1-1/M)=e**-1,而e**-1≈0.368。约有36.8%是没被抽到的球的概率。这种方式就叫“包外估计”(out-of-bag estimation),那么这36.8%的球就可以用来做测试集了。【这个方法也在后续的集成学习中会很常见。】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)