(论文速读)GGS-NNs:门控图序列神经网络
论文题目:GATED GRAPH SEQUENCE NEURAL NETWORKS(门控图序列神经网络)
会议:ICLR2016
摘要:图结构数据经常出现在化学、自然语言语义、社会网络和知识库等领域。在这项工作中,我们研究了图结构输入的特征学习技术。我们的出发点是之前在图神经网络(Scarselli et al., 2009)上的工作,我们将其修改为使用门控循环单元和现代优化技术,然后扩展到输出序列。结果是一种灵活且广泛有用的神经网络模型,当问题是图结构的时候,相对于纯粹基于序列的模型(例如lstm),它具有有利的归纳偏差。我们在一些简单的人工智能(bAbI)和图算法学习任务上展示了这种能力。然后我们展示了它在程序验证的问题上实现了最先进的性能,其中子图需要被描述为抽象的数据结构。
深度解读门控图序列神经网络
引言:图无处不在,我们如何让神经网络"看懂"图?
在深度学习的世界里,我们已经看到了卷积神经网络在图像领域的辉煌成就,循环神经网络在序列数据上的卓越表现。但是,还有一类重要的数据结构——图(Graph),它们广泛存在于我们的生活中:
- 🧪 化学分子是原子通过化学键连接的图
- 🌐 社交网络是人与人关系的图
- 🧠 知识图谱是概念间关系的图
- 💻 程序的内存状态是指针连接的图
今天,我要为大家介绍一篇发表在ICLR 2016的开创性论文:Gated Graph Sequence Neural Networks(门控图序列神经网络,GGS-NNs)。这篇论文不仅优雅地解决了图数据的深度学习问题,更重要的是,它首次让神经网络能够在图上进行序列推理。
第一章:问题的起源——为什么图数据这么难?
1.1 图数据的特殊性
与图像和文本不同,图数据有三个独特的挑战:
挑战1:不规则结构
- 图像是规则的2D网格,文本是1D序列
- 图的每个节点可以有任意数量的邻居
- 没有固定的"卷积核"可以应用
挑战2:排列不变性
- 同一个图,节点编号改变后,本质不变
- 模型需要学习排列不变的表示
挑战3:长距离依赖
- 图中两个节点可能相距很远
- 信息需要沿着图的边传播多步
1.2 已有方法的困境
在这篇论文之前,研究者们主要使用Graph Neural Networks(GNN)来处理图数据。GNN的核心思想很简单:
重复迭代直到收敛:
每个节点收集邻居信息
更新自己的表示
听起来很美好?但实际使用中有个致命问题:
为了保证收敛,模型参数必须满足"收缩映射"(contraction map)约束。
这意味着什么?论文在附录A用数学证明了一个令人沮丧的事实:
在收缩映射约束下,距离为δ的两个节点间信息传递的衰减率是ρ^δ(其中ρ<1)
直白地说:节点距离越远,信息传递越困难,长距离依赖几乎无法学习!
1.3 更大的野心:序列输出
更重要的是,原始GNN只能做单步预测:
- ✅ 节点分类(这个蛋白质是什么功能?)
- ✅ 图分类(这个分子有毒吗?)
- ❌ 路径预测(从A到B的最短路径是什么?)
- ❌ 序列生成(如何用逻辑公式描述这个数据结构?)
但现实世界的许多任务需要序列输出!比如:
- 🗺️ 在地图上规划路径
- 🔍 生成知识图谱查询
- 🛡️ 为程序验证生成逻辑公式
这就是作者们要解决的核心问题。
第二章:创新的解决方案——GG-NNs和GGS-NNs
2.1 第一步:改进GNN得到GG-NN
作者们的第一个创新是借鉴了RNN领域的成功经验:用门控机制替代简单递归。
关键改进1:引入GRU单元
传统GNN的更新公式:
h_v^(t) = f(邻居信息, 上一步状态)
GG-NN的更新公式(类似GRU):
更新门 z = σ(W_z·a + U_z·h_old) # 决定保留多少旧信息
重置门 r = σ(W_r·a + U_r·h_old) # 决定如何结合新信息
候选值 h̃ = tanh(W·a + U·(r ⊙ h_old))
新状态 h = (1-z)⊙h_old + z⊙h̃ # 插值组合
为什么这样好?
- 门控机制让模型自己学习如何保持长距离记忆
- 类似LSTM如何解决RNN的梯度消失问题
关键改进2:固定步数展开
原始GNN:迭代到收敛(可能需要无限步) GG-NN:展开固定T步(比如T=5或10)
这带来两个好处:
- 训练更简单:用标准的反向传播(BPTT)
- 不需要收缩映射约束:参数可以自由学习!
关键改进3:节点标注(Node Annotations)
这是个巧妙的设计。让我用一个例子说明:
问题:判断节点t是否可以从节点s到达?
GG-NN的做法:
# 初始化
x_s = [1, 0] # 标记s为"起点"
x_t = [0, 1] # 标记t为"终点"
x_others = [0, 0] # 其他节点
# 传播过程会自动学习:
# 第1维从s沿边传播,标记所有可达节点
# 第2维定位t的位置
# 最后检查t的第1维是否为1
这种设计让模型能够编码任务相关的结构信息。
2.2 第二步:扩展到序列输出得到GGS-NN
现在到了最精彩的部分:如何让模型输出序列?
核心思想:分步预测 + 状态传递
想象你要在一个图上找路径,人类怎么思考的?
- 看当前位置和目标
- 选择下一步
- 更新对图的理解("我已经走过这里了")
- 重复2-3直到到达目标
GGS-NN就是模拟这个过程!
架构设计
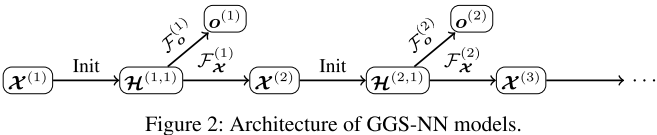
输入图 → [节点标注 X^(1)]
↓
[GG-NN F_o^(1)] → 输出 o^(1)
↓
[GG-NN F_X^(1)] → 更新标注 X^(2)
↓
[GG-NN F_o^(2)] → 输出 o^(2)
↓
...
每一步包含两个GG-NN:
- F_o:根据当前标注预测输出
- F_X:更新节点标注(传递状态)
一个具体例子:路径查找
假设要找从B到A的路径(B→E→A):
步骤1:
输入:B和A的标注
输出:"向西(w)"
标注更新:标记"B已访问","E现在活跃"
步骤2:
输入:更新后的标注(E活跃)
输出:"向南(s)"
标注更新:标记"E已访问","A现在活跃"
步骤3:
输出:"结束"
2.3 两种训练模式
GGS-NN支持两种训练方式:
模式1:观察标注训练
- 中间标注已知(像监督学习)
- 每步可以独立训练
- 适合有领域知识的场景
模式2:端到端训练
- 只有输入图和最终输出序列
- 中间标注作为隐藏变量
- 反向传播贯穿整个序列
- 更通用,但训练难度更大
第三章:惊人的实验结果
3.1 在bAbI任务上的碾压性优势
bAbI是Facebook提出的一套AI推理测试任务。作者们将其中的故事转换成图:
- 实体→节点
- 关系→边
结果1:单步任务(100%碾压)


看这个对比表就够了:


| 任务 | 内容 | GG-NN | RNN | LSTM |
|---|---|---|---|---|
| Task 15 | 基础演绎 | 50样本→100% | 950样本→48.6% | 950样本→50.3% |
| Task 16 | 基础归纳 | 50样本→100% | 950样本→33.0% | 950样本→37.5% |
震撼点:
- GG-NN只需50个样本就完美解决
- RNN/LSTM用20倍数据还不如随机猜测!
结果2:序列任务(Task 19)

Task 19(路径查找)被认为是最难的bAbI任务。在此之前,没有方法能在无强监督的情况下超过20%准确率。
GGS-NN的表现:
- 50样本:71.1%
- 100样本:92.5%
- 250样本:99.0%
而RNN/LSTM即使用950样本:
- RNN:24.7%
- LSTM:28.2%
结果3:图算法学习
作者们设计了两个新任务:
- 最短路径:在图上找两点间最短路径
- 欧拉回路:找经过所有边恰好一次的路径
结果令人震惊:
- GGS-NN:50样本→100%准确率
- RNN:950样本→9.7%
- LSTM:950样本→10.5%
为什么差距这么大?
论文在附录B详细分析了原因。简单说:
- 序列太长:转换成token后约80个,RNN难以保持长距离记忆
- 顺序无关:图边的输入顺序不影响答案,但RNN/LSTM对顺序敏感
- 结构重要:图的连接关系是核心,GGS-NN直接建模它
3.2 真实应用:程序验证
这是论文最有实际价值的部分。
问题背景
考虑这个C函数:

node* concat(node* a, node* b) {
if (a == NULL) return b;
node* cur = a;
while (cur.next != NULL)
cur = cur->next;
cur->next = b;
return a;
}
要证明这个函数正确(不会崩溃,真的连接了两个链表),需要为循环找到不变式(invariant):
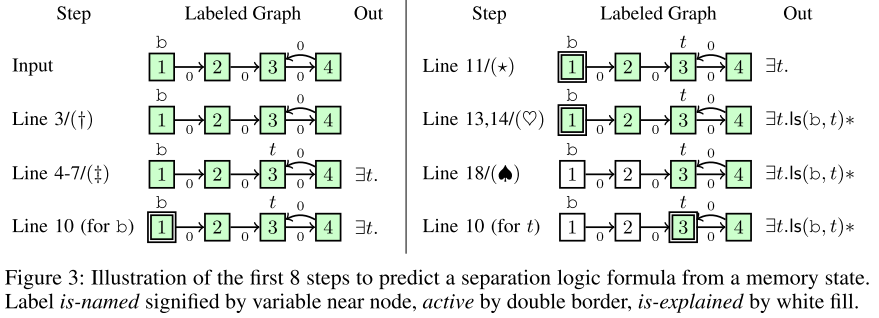
∃t. ls(a,cur) ∗ ls(cur,NULL) ∗ ls(b,t)
这是分离逻辑(separation logic)公式,描述了内存的形状。
挑战
- 传统方法:程序员手写(费时费力)
- 之前的机器学习方法:需要大量手工特征工程
GGS-NN的解决方案
输入:内存堆图(节点=内存地址,边=指针) 输出:分离逻辑公式(序列形式)
生成过程(算法1和2):
1. 决定是否需要存在量词(∃变量)
2. 如果需要,选择哪个节点命名
3. 对每个命名变量:
a. 预测数据结构类型(list/tree/none)
b. 如果是list,选择结束节点
c. 递归预测嵌套结构(list of lists)
d. 更新节点标注(标记"已解释")

结果
数据集:
- 327个公式
- 每个公式498个堆图
- 共约160,000个样本
准确率对比:
- 之前最好(Brockschmidt et al. 2015):89.11%(需要大量手工特征)
- GGS-NN:89.96%(零特征工程!)
实际验证: 成功为多个程序生成正确不变式,包括:
- Traverse(遍历链表)
- Concat(连接链表)
- Copy(复制链表)
- Insert(插入节点)
- Remove(删除节点)
例如,对Insert程序生成的不变式:
curr≠NULL ∗ curr≠elt ∗ elt≠NULL ∗ elt≠lst ∗ lst≠NULL
∗ ls(elt,NULL) ∗ ls(lst,curr) ∗ ls(curr,NULL)
这个公式被证明器成功用于证明程序的内存安全性!
第四章:为什么GGS-NN这么强?
4.1 样本效率的秘密
结构化归纳偏置(Structured Inductive Bias)
GGS-NN内置了图结构的先验知识:
- 节点通过边连接
- 信息沿边传播
- 图的拓扑结构很重要
而RNN/LSTM把一切都当成序列,需要从数据中重新学习图的结构。
类比:
- CNN用于图像:利用了"局部像素相关"的先验
- GGS-NN用于图:利用了"沿边传播"的先验
4.2 长距离依赖的克服
传统GNN的问题:
信息衰减 ∝ ρ^距离 (ρ<1,exponential decay)
GG-NN的解决:
门控机制 + 无收缩约束 = 可学习的信息保持
类似于LSTM如何解决RNN的梯度消失!
4.3 序列输出的优雅设计
核心洞察:在图上做序列推理时,需要:
- 记住已经处理过的部分(通过节点标注)
- 知道当前关注哪里(通过"active"标记)
- 逐步构建输出(通过多步GG-NN链)
这比让RNN/LSTM从线性序列中重建图结构要自然得多!
第五章:深入理解——几个关键技术细节
5.1 参数共享的艺术
看这个关键的传播公式:
a_v = A_v: · [h_1, h_2, ..., h_N]^T + b
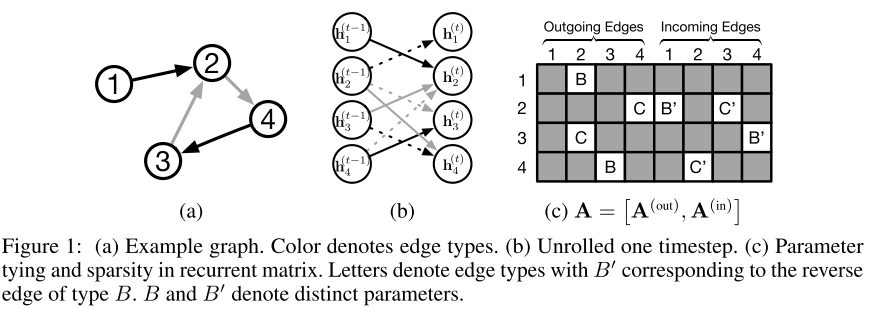
矩阵A的结构非常巧妙(Figure 1c):
- 稀疏性:只有图中实际存在的边对应的位置非零
- 参数绑定:相同类型和方向的边共享参数
- 方向敏感:B和B'(反向边)有不同参数
效果:
- 模型大小不随图大小增长
- 自然处理可变大小的图
- 保持排列不变性
5.2 注意力机制的早期应用
图级表示的公式:
h_G = tanh(Σ_v σ(i(h_v, x_v)) ⊙ tanh(j(h_v, x_v)))
这里的σ(i(h_v, x_v))是软注意力机制!
- i()计算每个节点的重要性分数
- σ将其转为0-1的权重
- 加权求和得到图表示
历史地位:这是2016年的论文,比Transformer(2017)还早!
5.3 批量预测的技巧
在程序验证中,需要从多个堆图预测单个公式。
解决方案:
# 对每个图运行GGS-NN
# 聚合预测:
对于节点选择:score(变量t) = Σ_图g score_g(t对应的节点)
对于分类:p(类别k) = Π_图g p_g(类别k)
这确保了生成的公式对所有输入图都有效!
第六章:局限性与未来方向
6.1 当前的局限
作者们诚实地指出了几个问题:
1. 时间信息丢失
- bAbI转换忽略了事件的时间顺序
- 解决方向:级联多个GG-NN,每个处理一个时间步
2. 高阶关系难处理
- "John went to the garden yesterday"(三元关系)难以表示
- 解决方向:用因子图(factor graph)表示
3. 问题与事实分离
- 当前模型先看所有事实,再看问题
- 期望:先看问题,动态推导需要的事实
4. 自然语言鸿沟
- 论文用的是符号形式,不是真正的自然语言
- 需要研究:如何从文本端到端学习图表示
6.2 开创的研究方向
这篇论文实际上开启了多个后续研究方向:
-
消息传递神经网络(MPNN)
- 统一了各种图神经网络范式
- GG-NN是MPNN的特例
-
图注意力网络(GAT)
- 进一步发展了注意力机制
- 学习动态的边权重
-
图与语言结合
- 知识图谱问答
- 视觉场景图生成
-
程序分析的深度学习
- 代码表示学习
- 神经程序合成
第七章:实现建议与最佳实践
如果你想实现或使用GGS-NN,这里有一些建议:
7.1 超参数选择
根据论文实验:
# 传播步数
T = 5 # 简单任务(bAbI单步)
T = 10 # 复杂任务(程序验证)
# 节点表示维度
D = 4-6 # bAbI任务
D = 8-16 # 程序验证
D = 20 # 图算法学习
# 训练
optimizer = Adam # 论文使用Adam
batch_size = 20 # 程序验证用的批大小
7.2 设计节点标注
原则:
- 标注应该编码任务相关的状态
- 保持简洁(通常2-5位足够)
- 考虑使用one-hot编码标记特殊节点
示例:
# 路径查找
x_start = [1, 0, 0] # [是起点, 是终点, 已访问]
x_end = [0, 1, 0]
x_other = [0, 0, 0]
# 分离逻辑预测
x = [is_named, is_active, is_explained]
7.3 避免常见陷阱
陷阱1:过度参数化
- GGS-NN的威力来自结构,不是参数量
- 论文最大模型<5K参数,依然表现出色
陷阱2:忽视边的方向和类型
- 方向很重要:A→B和B→A可能含义不同
- 类型区分:不同类型的边应该有不同参数
陷阱3:固定图结构
- 应该支持可变大小的图
- 用padding或动态批处理
结语:从论文到现在
这篇2016年的论文现在(2025年)有超过3500次引用,影响深远。它的核心思想——用神经网络在图上做推理——已经成为GNN领域的基石。
主要贡献回顾:
-
✅ 技术创新
- 用GRU单元改进GNN(解决长距离依赖)
- 首次实现图到序列的神经模型
- 节点标注机制(编码状态)
-
✅ 实验洞察
- 证明了结构化归纳偏置的威力
- 展示了GNN在多个领域的潜力
- 提供了大量可复现的基准
-
✅ 实际应用
- 程序验证的突破(零特征工程达SOTA)
- 为后续程序分析研究铺路
现代视角:
虽然现在有了更新的GNN变体(GAT、GraphSAGE、GIN等),但GGS-NNs的核心思想依然相关:
- 门控机制→现在各种GNN都有类似设计
- 序列输出→启发了graph-to-sequence模型
- 程序分析→发展成了热门的Code Intelligence方向
适合阅读此论文的读者:
- 🎓 想深入理解GNN的研究者
- 💻 做程序分析/形式化验证的开发者
- 🧠 对结构化推理感兴趣的ML工程师
- 📚 研究知识图谱/图算法的学生
最后的话:
好的研究不仅解决当下的问题,更开启未来的可能。GGS-NNs就是这样一篇论文——它在2016年就预见了图神经网络的潜力,用优雅的设计证明了结构化先验的价值,并在实际应用中展现了惊人的效果。
如果你正在处理图结构数据,或者需要在结构化输入上做序列推理,这篇论文值得你反复研读。它不仅会教你如何设计模型,更会改变你思考问题的方式。
希望这篇博客能帮助你深入理解这篇经典论文!如有问题,欢迎讨论。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)