带你轻松学习PostgreSQL
目录
一、为什么 PostgreSQL 和 MySQL 值得放在一起比较

一、为什么 PostgreSQL 和 MySQL 值得放在一起比较
在关系型数据库领域,MySQL 和 PostgreSQL 经常被同时提起。
原因并不只是它们都很流行,而是因为它们都在解决同一类问题:
- 如何可靠地存储业务数据
- 如何支持事务
- 如何处理并发访问
- 如何加速查询
- 如何在故障后恢复
但它们的解决方式并不完全一样。
很多时候,真正值得比较的不是:
- 谁的语法更好记
- 谁的工具更多
而是它们如何处理数据版本、事务一致性、并发冲突、日志恢复以及索引组织。
这也是本文的重点。
并且在当下,PostgreSQL往往在关系型数据库领域中成为更优的选择,其原因也会在本文中进行展开
二、核心差异
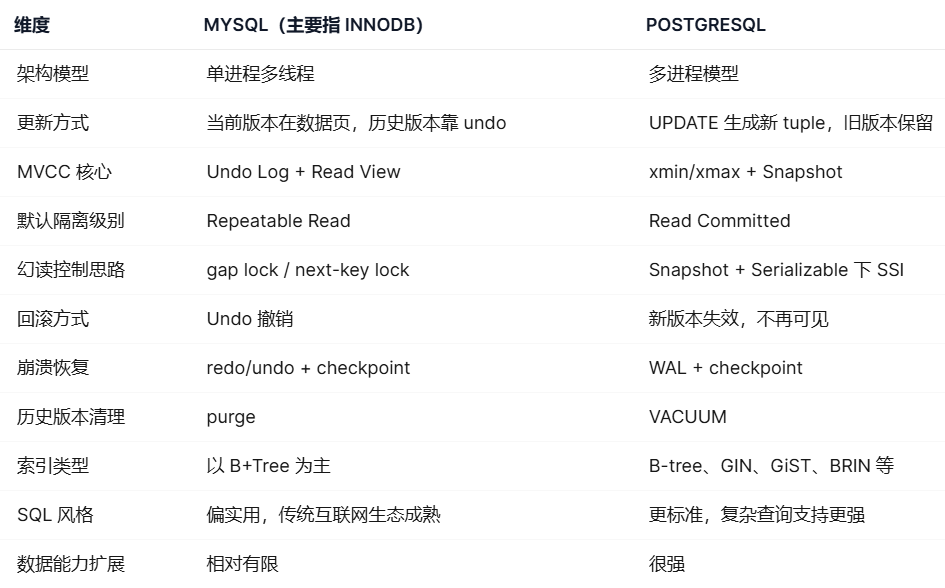
这里用这个表格大体总览一下,后续会进行详细展开。
三、PostgreSQL是什么
PostgreSQL 是一个开源的对象-关系型数据库管理系统。
很多人会把它简单理解成另一个支持事务的关系数据库,就像MySQL一样。
这些说法都不算错,但不够准确。
PostgreSQL 是一个以事务一致性、多版本并发控制、复杂查询能力和扩展性见长的数据库系统。
它不仅关注把数据存进去,还关注:
- 如何严谨地表达事务
- 如何优雅地处理并发
- 如何支持复杂类型和复杂查询
- 如何让数据库能力本身具备平台化特征
MySQL 的成功来自大量互联网业务实践,它在经典 OLTP 场景里非常稳。
而 PostgreSQL 的优势在于,很多机制不是后来补上的能力,而是一开始就在围绕事务、快照、版本和扩展性做统一设计。
这种差异会在后面的 MVCC、锁、事务与索引章节里越来越明显。
四、架构模型
1. MySQL:单进程多线程
MySQL 通常以一个 mysqld 进程运行,内部通过多个线程完成工作,例如:
- 处理客户端连接
- 执行 SQL
- 管理 buffer pool
- redo 日志刷盘
- 后台清理
- 主从复制相关任务
这种方式的特点是:
- 线程模型比较经典
- 对大量连接的适配相对自然
- 线程切换成本通常低于进程切换
2. PostgreSQL:多进程模型
PostgreSQL是:
- 一个主控进程
postmaster - 每个连接通常对应一个 backend 进程
- 另外有多个后台进程负责不同职责
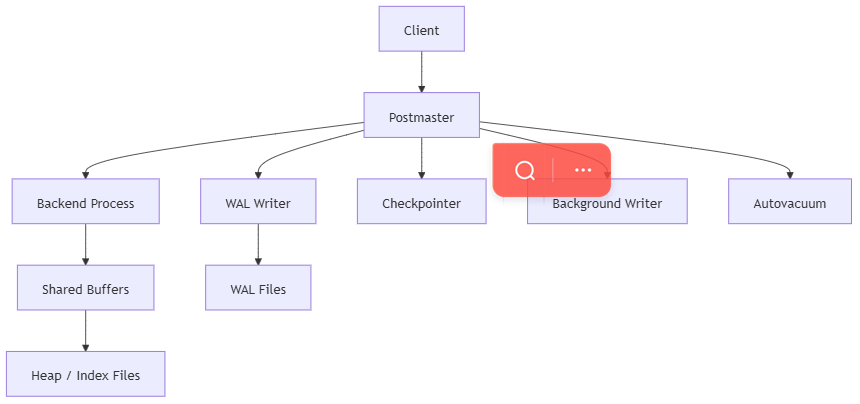
优势
- 连接进程之间隔离更明显
- 单个连接崩溃影响更局部
- 后台职责划分更清晰
代价
- 连接成本更高
- 更依赖连接池
- 太多空闲连接会造成资源浪费
五、MVCC
1. 什么是 MVCC?
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。
它要解决的问题很简单:
在有并发事务时,怎样尽量做到读不阻塞写,写不阻塞读,同时保证隔离性。
如果数据库只允许当前值存在,那么:
- 一个事务正在写
- 另一个事务读同一行
- 就很容易发生阻塞
MVCC 的核心思路是:
- 不只保留一个版本
- 而是允许同一条记录存在多个版本
- 不同事务根据自己的快照,看到不同版本
这就是多版本的本质。
2. MySQL vs PostgreSQL
MySQL(InnoDB)的做法
- 数据页中保存当前版本
- 历史版本保存在 undo log
- 查询旧版本时,需要通过 undo 链回溯
PostgreSQL 的做法
- 旧版本和新版本都直接保留在表里
- UPDATE 不做原地修改,而是插入一个新版本
- 事务根据 snapshot 决定自己看到哪个版本
可以用一句话概括就是:MySQL 是当前值 + undo 回溯过去,PostgreSQL 是过去和现在都保留,由快照决定看哪个。
在 PostgreSQL 里,一条记录不是单纯的一行值,更准确地说,是一个个tuple version。
每个版本都会带一些隐藏系统字段,最重要的是:
xmin:创建该版本的事务 IDxmax:使该版本失效的事务 ID
这两个字段,几乎就是 PostgreSQL 可见性判断的核心。
看一条很普通的 SQL:UPDATE users SET name = 'Bob' WHERE id = 1;
很多人下意识会认为数据库做的是:
- 找到记录
- 把 name 从 Alice 改成 Bob
但 PostgreSQL 的真实思路是先旧版本被标记为“已被当前事务更新”,再插入一个新版本,后续事务根据快照选择看到旧版本还是新版本。
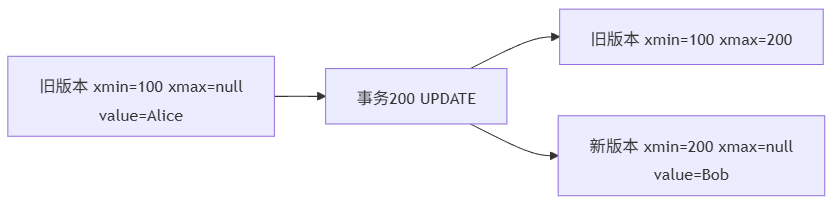
这意味着 PostgreSQL 的 UPDATE 本质不是“原地改写”,而是“版本追加”。
为什么同一行数据,不同事务看到的结果可能不同?
在 PostgreSQL 里,判断一条记录是否“存在”,不是简单看磁盘上有没有那条数据。
它更像是在问:这个版本对当前事务是否可见?判断依据通常包括:
- 创建该版本的事务是否已提交
- 删除或更新该版本的事务是否已提交
- 当前事务的 snapshot 中,这些事务是否可见
所以 PostgreSQL 对数据的理解不是绝对当前值,而是:
- 版本 + 事务状态 + 快照
什么是Snapshot?
PostgreSQL 会为事务或语句分配 snapshot。
你可以把它理解成一张当前数据库世界的快照。这张照片里包含:
- 哪些事务已经提交
- 哪些事务仍然活跃
- 哪些事务对当前事务来说还不可见
于是同一张表,不同事务可能读到不同版本,这不是异常,而是 PostgreSQL 设计的一部分。
那PostgreSQL的Snapshot不就和MySQL的Read View一样吗?
概念确实非常相似,但是实现链路不一样。
MySQL
- 先看到当前版本
- 如果不可见,沿 undo log 往回找历史版本
- 再判断哪个版本可见
PostgreSQL
- 直接扫描到 tuple 版本
- 根据
xmin/xmax + snapshot判断该版本是否可见所以从实现观感上看:
- MySQL:更像当前数据 + 历史回放
- PostgreSQL:更像版本天然共存 + 快照选择
这也是很多人觉得 PostgreSQL 的 MVCC 更原生的原因。
六、VACUUM
UPDATE 和 DELETE 都不会立刻把旧版本物理删除。
于是就会留下那些:
- 对当前和未来事务都已经没有意义
- 但物理上还占着空间的版本。
这些无效版本就叫dead tuples。
既然 PostgreSQL 会保留旧版本,那一个自然的问题就是:
旧版本什么时候清理?
这就是 VACUUM 存在的原因。
VACUUM 的主要职责包括:
- 清理 dead tuples
- 回收空间供后续复用
- 更新可见性信息
- 防止事务 ID 回卷问题
什么是事务ID回卷问题?
就是数据库的事务编号不是无限的,编号用久了会绕回去,如果旧事务信息没有及时清理,就可能导致可见性判断错误,严重时数据库会停止写入以自保。
VACUUM的处理方式就是把那些已经古老到不可能再变化的数据,标记成“足够老、永远可见”,这样即使事务 ID 回绕,也不会误判。
注意一个常见误区:普通 VACUUM 并不一定马上缩小表文件大小,它更多是在回收内部可复用空间。
为什么 PostgreSQL 特别怕长事务?
长事务会一直持有旧 snapshot。
只要这个 snapshot 还在,某些旧版本就可能仍然“理论上可见”,因此 VACUUM 不敢清理。结果就是:
- dead tuples 堆积
- 表膨胀
- 索引膨胀
- autovacuum 压力上升
- 查询性能变差
因此长事务是 PostgreSQL 的典型性能风险之一。
什么是autovacuum?
线上几乎不会靠人工频繁执行 VACUUM。
PostgreSQL 依赖的是autovacuum,它会自动做vacuum。如果说 MySQL 线上很多时候重点关注的是慢 SQL、锁等待、索引命中
那么 PostgreSQL 通常还必须把这几个问题加入重点观察:
- autovacuum 是否跟得上
- 是否存在长事务
- 是否发生 heap / index bloat
七、事务与隔离级别
MySQL和PostgreSQL都支持经典的 ACID 特性:
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
但 PostgreSQL 经常给人的感觉是它不只是支持事务,而是很多机制从一开始就是围绕事务一致性设计出来的。
需要注意,MySQL 默认级别是RR,而PostgreSQL是RC。
RC的并发粒度比RR要小,行为对很多业务开发来说更加直观,锁开销更小,更适合当下企业业务场景。
除此之外,PostgreSQL中的RU级别其实完全等同于RC级别。
按SQL标准,RU级别是允许出现脏读的。
而PostgreSQL的MVCC设计,只允许select读取的是一个已经提交并且可见的版本。
PostgreSQL宁可取消一个隔离级别,也不愿意去放开不一致读取。
这也非常能体现出PostgreSQL的设计理念。
针对Serializable,二者的实现差异也很大。
MySQL
依赖、gap lock、next-key lock、范围锁
本质上是更偏“提前锁住潜在风险”。
PostgreSQL
PostgreSQL 的 Serializable 采用的是SSI(Serializable Snapshot Isolation)
它的工作方式大致是:
- 先按快照隔离执行事务
- 系统跟踪事务之间的读写依赖
- 如果发现可能形成不可串行化的冲突,就中止其中一个事务
这是一种非常有代表性的现代数据库设计思路:
尽量保持并发,而不是一开始就把所有可能性锁死。
也正因为如此,很多人会觉得 PostgreSQL 的事务控制更“高级”,因为它不是简单依靠“加更多锁”来实现更高隔离。
八、锁机制
有了 MVCC,并不意味着锁失效了。
MVCC 解决的是版本可见性,而不是所有并发问题。
例如:
- 两个事务同时更新同一行
- DDL 和 DML 冲突
- 外键约束检查
- 唯一约束竞争
- 某些业务需要显式互斥
这些仍然需要锁。
那么PostgreSQL有哪些锁?
常见可以分为:
- 表级锁
- 行级锁
- 页级锁
- 咨询锁
- 谓词锁
什么是咨询锁?
咨询锁是数据库提供给应用程序使用的业务级自定义锁,它不直接锁表或锁行,而是让开发者基于某个自定义 key 做互斥控制,比如防止同一任务重复执行、同一用户并发处理等,但前提是所有代码都要主动遵守这套规则。
也就是说:数据库只是提供这把锁,至于大家用不用、遵不遵守,要靠应用自己约定。
什么是谓词锁?
谓词锁则是 PostgreSQL 在
SERIALIZABLE隔离级别下自动使用的一种内部并发控制机制,它不是给业务手工加的,也不是像 MySQL 的 gap lock 那样直接阻止别人插入,而是用来记录事务读过的条件范围,当其他事务修改了这个范围时,系统再基于 SSI 检测是否存在不可串行化冲突,必要时回滚其中一个事务。简而言之,就是这个锁负责记录读过的范围,如果有其他事务对这个范围的tuple进行了修改或者增删了,系统就会立即检测到两个事务发生了冲突,有可能造成不可重复读或者幻读等问题,就会回滚其中一个事务。
这里我们就重点讲解一下行级锁:
MySQL 的行锁本质上更依赖索引,锁的往往不只是某条记录,还可能连同索引间隙一起锁住,也就是常说的 record lock、gap lock 和 next-key lock;而 PostgreSQL 的行锁更偏向锁住实际命中的那几行记录本身,通常不会顺带把某个索引范围内未来可能插入的数据也锁住。
这就导致在 MySQL 中,像 SELECT ... FOR UPDATE 或范围更新语句,在RR级别下很可能不仅阻塞别人修改已有行,还会阻塞别人往这个范围里插入新行,以防止幻读;而 PostgreSQL 一般只阻塞别人修改或删除已锁定的行,不会天然阻止新行插入,因此并发更高。
MySQL的间隙锁和临键锁是为了防止幻读的,因此牺牲了部分并发换取数据安全。而PostgreSQL的锁只是单纯锁住了tuple,那不会出现幻读问题吗?
快照读情况下不必多说,只需要遵循同一份快照自然就避免了幻读问题。
关键是当前读的情况,PostgreSQL里其实并没有MySQL中当前读的说法,我们这里实际上指的是select for update/update/delete这类情况,这类情况不能使用旧快照,但是PG也不会让他们破坏快照,而是先按照事务找到候选行,如果这行被别的事务更改过则先等待,当那个事务提交之后,若这行版本与事务开始时不一致,则会报错。
所以PG宁愿是走报错方式,也不愿意破坏快照。
因此RR级别下的PG也是完美避开了幻读问题。
有些同学会觉得,PostgreSQL 在 RR 级别下遇到并发更新时需要等待、重新检查,甚至直接报错回滚重试,这不是降低并发吗?
确实,从单个发生冲突的事务来看,并发度是下降了,因为它可能被阻塞或失败重试。但 PostgreSQL 的优势在于:它不会为了防止幻读或保证一致性,像MySQL那样大量使用范围锁、间隙锁去阻塞其他事务,而是依靠 MVCC 快照读,让大多数普通
SELECT都可以在不加锁的情况下直接读取一致性视图,不会被写事务阻塞,也不会去阻塞写事务。这样虽然少数“读后又要修改”的事务会在冲突时付出代价,但从整个系统看,更多请求都能并行执行,快照一致性也没有被破坏,因此总体并发性通常更高。
在死锁方面,PG和MySQL的处理方式大致相同:
- 自动检测死锁
- 中止其中一个事务
- 返回错误给应用
- 由应用决定是否重试
PG不像MySQL拥有间隙锁和临键锁,所以死锁的概率会小一些。通常是因为访问顺序交错导致的哲学家问题。
九、回滚与恢复
在MySQL InnoDB 中,undo log 既承担:
- 一致性读构造旧版本
- 事务失败时撤销修改
也就是说,undo 是一个双重角色:
- 既服务 MVCC
- 又服务回滚
而PostgreSQL的 UPDATE 本来就是生成新版本。
因此当事务回滚时:
- 这些新版本不会成为有效数据
- 对其他事务来说本来就不可见
- 后续由 VACUUM 清理即可
所以 PostgreSQL 的回滚更像是:
让当前事务生成的新版本永远失效,而不是把值原地改回旧状态。
这是一种更符合多版本思维的实现方式。
十、WAL 与 Checkpoint
事务最终一定要落到一个问题上:如果数据库突然宕机,已提交的数据如何保证不丢?
PG的策略则是WAL,核心原则就是在数据页落盘之前必须先让日志落盘。
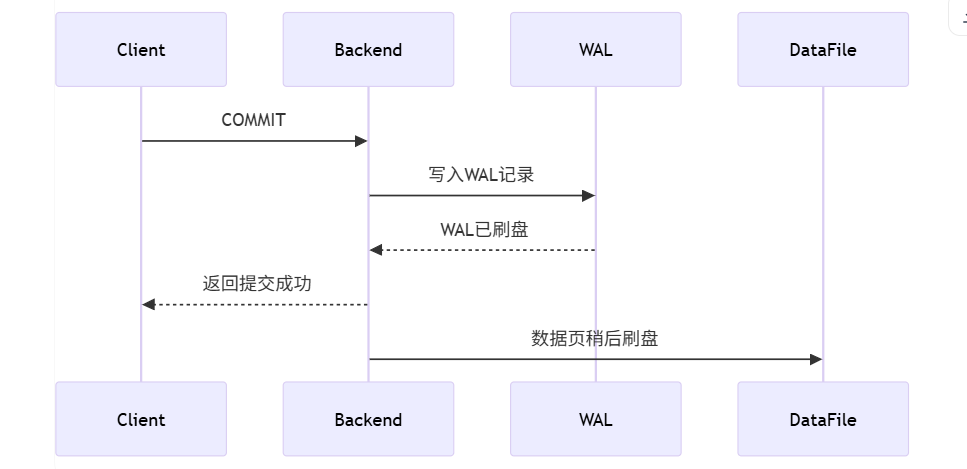
所以对于PG来说:事务提交成功的判据,不是数据页已经刷回表文件,而是 WAL 已经持久化。
但是如果数据库每次崩溃恢复都要从很久以前的 WAL 开始重放,恢复时间会非常长。
因此 PostgreSQL 需要 checkpoint。
Checkpoint 的作用是:
- 把部分脏页刷回磁盘
- 记录恢复起点
- 缩短后续崩溃恢复时间
但 checkpoint 也有平衡问题:
- 太频繁:刷盘压力大、I/O 抖动明显
- 太少:恢复时间变长、WAL 堆积更多
这也是 PostgreSQL 调优里经常要关注的一类参数。
PostgreSQL 在备份恢复上的一项非常强的能力是:PITR(Point-In-Time Recovery)
基本思路是:
- 做 base backup
- 持续归档 WAL
- 恢复时先恢复基线备份
- 再把 WAL 回放到某个目标时间点
这意味着:
- 误删数据后可以恢复到误删前一刻
- 灾难恢复更可控
- 一致性恢复链路很清晰
MySQL 也能通过全量备份 + binlog 实现类似能力,但 PostgreSQL 的 WAL 体系在这一点上更统一、原生。
十一、索引体系
MySQL InnoDB 的核心索引结构是 B+Tree。
它非常适合:
- 主键查询
- 范围查询
- 排序
- 常见 OLTP 业务
对于传统互联网场景来说,这套体系已经非常成熟,也非常高效。
所以如果业务模型比较经典,MySQL 的索引并不弱。
而PG的索引优势则体现在多样性。
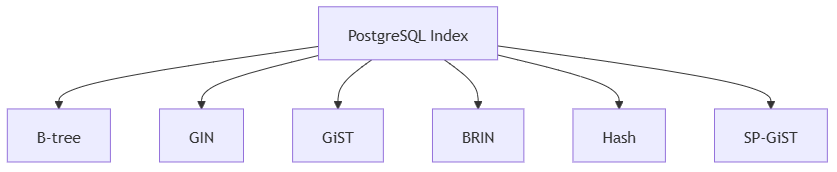
PG支持的常见索引类型包括:
- 查询 JSON 字段里的某个属性
- 模糊检索文本
- 搜索数组元素
- 地理空间范围查询
- 时间范围日志检索
- 区间重叠判断
- 文档或向量相关查询
在这些场景下,B+Tree 往往不是唯一答案,甚至不是最佳答案。
这时 PostgreSQL 的索引体系就会显得更自然。
最常用的如下:
1. B-tree
适合等值、范围、排序,是最通用的索引。
2. GIN
适合:
- JSONB
- 数组
- 全文检索
3. GiST
适合:
- 地理空间
- 范围类型
- 相似搜索
4. BRIN
适合超大表,尤其是按时间或顺序追加的数据。
它不保存每行细节,而保存块范围摘要,因此:
- 索引体积很小
- 创建很快
- 非常适合日志表、时间序列表
除了多样性以外,PG还有两个高价值特性:表达式索引和部分索引:
表达式索引
-- 表示当使用小写参数时索引生效
CREATE INDEX idx_lower_email ON users(lower(email));部分索引
-- 只有当deleted字段为false的情况下才会建索引
CREATE INDEX idx_active_user ON users(id) WHERE deleted = false;这两个索引在实际业务场景都非常使用,可以实现加速查询的同时节省空间。
最后,HOT Update也是PG不可忽视的特性之一。
Heap-Only Tuple Update,意思是只在堆表里完成的更新。
如果一次 UPDATE 没有修改任何索引列,那么 PostgreSQL 尽量只在表(heap)里生成新版本,而不去更新索引。
当满足条件时:
- 旧 tuple 保留
- 新 tuple 写到同一个 heap page
- 旧 tuple 指向新 tuple,形成一条 HOT 链
- 索引仍然指向这条链的起点,不需要新增索引项
查询时,PG 通过这个链找到当前可见的版本。
因此,HOT Update的好处有很多:
- 减少了索引维护的开销,不需要变动索引页
- 降低了WAL量,不需要变更索引,日志量自然也变少了
- 减轻了索引膨胀,不会为每次更新都产生新的索引项
- 提高高频更新场景的性能,无需变动索引页,更新效率大大提高
十二、系统性
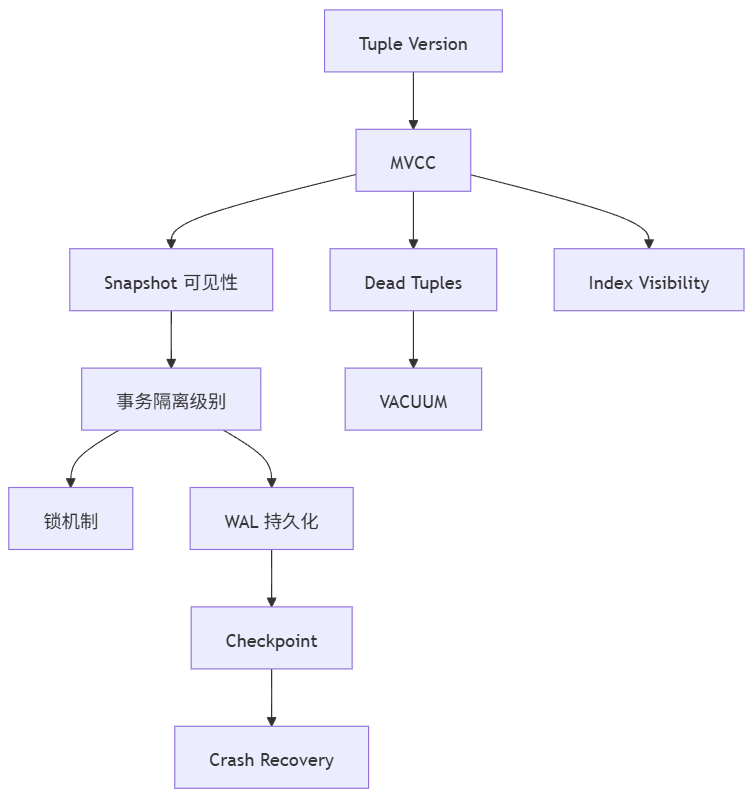
这张图说明 PostgreSQL 的核心机制并不是一堆彼此独立的模块,而是围绕几个底层基础不断展开的:
- tuple version
- snapshot
- WAL
- VACUUM
- 索引可见性
因此你会发现:
- MVCC 会影响事务可见性
- MVCC 会影响 VACUUM
- VACUUM 又会影响索引扫描表现
- WAL 影响提交与恢复
- Serializable 又建立在快照与依赖分析之上
这就是 PostgreSQL 常被评价为“设计统一”的原因。
十三、pgvector
在近几年的 AI 应用中,向量检索已经成为一个很常见的需求。
PostgreSQL 本身不是专门的向量数据库,但它可以通过扩展 pgvector 来支持这类场景。
它为 PG 增加了:
- 向量类型
vector(n) - 向量距离计算
- 相似度查询
- 向量索引能力
安装扩展后,可以直接在表中定义向量字段,例如:
CREATE EXTENSION vector;
CREATE TABLE documents (
id bigserial PRIMARY KEY,
content text,
embedding vector(768)
);这里的 embedding vector(768) 表示该字段存储一个 768 维向量。
pgvector 的意义不只是PostgreSQL 也能查向量,而是PostgreSQL 可以把关系数据、JSON 数据、事务能力、SQL 过滤条件和向量检索放到同一个系统里处理。
比如你可以一边做向量相似度搜索,一边加上业务过滤条件:
SELECT id, content
FROM documents
WHERE tenant_id = 1001
ORDER BY embedding <=> '[...]'
LIMIT 10;十四、总结
到这里,其实已经不需要再去单独讨论“为什么 PostgreSQL 越来越受关注”了。
因为从上面的机制对比中,结论已经很自然:
- 当你只需要一个成熟、稳定、经典的事务型数据库时,MySQL 依然非常优秀
- 但当系统开始要求更强的事务语义、更统一的多版本模型、更灵活的索引、更复杂的查询和更强的扩展能力时,PostgreSQL 往往会更自然地适配这些需求
PostgreSQL 的优势,不在某个单点能力,而在于它把 MVCC、事务、锁、恢复和索引做成了一套统一系统。
~码文不易,留个赞再走呗~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)