▲基于Q-Learning强化学习的三维环境下无人机避障和路径规划算法matlab仿真
目录
1.引言
基于Q-Learning强化学习算法的路径规划方法。首先构建包含静态障碍物簇和多运动模式动态障碍物的三维栅格环境模型;其次设计综合考虑碰撞惩罚、目标趋近引导、动态危险区域规避及飞行平滑度的多因子奖励函数;然后采用ε-greedy探索策略和稀疏Q表存储机制进行Q-Learning训练;最后通过反循环贪心策略提取最优路径。仿真实验表明,该方法能在2000轮训练后收敛,成功率超过85%,有效实现动态环境下的无人机三维自主避障路径规划,所得路径兼具安全性和经济性。
2.本系统基本原理
2.1 问题描述

2.2 三维栅格环境建模
将连续三维空间离散化为栅格地图。定义三维栅格空间:

2.3 强化学习模型构建
Q-Learning是一种无模型(model-free)的时序差分(Temporal Difference, TD)强化学习算法。其核心思想是学习动作-价值函数Q(s,a),表示在状态𝑠采取动作𝑎后所能获得的期望累积折扣奖励:
![]()
其中γ∈[0,1) 为折扣因子,控制未来奖励的重要程度。
Q值的迭代更新公式为:
![]()
其中α∈(0,1]为学习率。
2.4 多因子奖励函数
奖励函数的设计是强化学习成功的关键。本文设计包含七个因子的综合奖励函数:
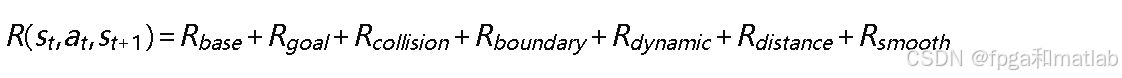
其中:
| 奖励因子 | 符号 | 数值 | 作用 |
|---|---|---|---|
| 基础步惩罚 | RbaseRbase | −1−1 | 缩短路径 |
| 目标到达奖励 | RgoalRgoal | +1000+1000 | 引导到达目标 |
| 碰撞惩罚 | RcollisionRcollision | −500−500 | 避免障碍物 |
| 越界惩罚 | RboundaryRboundary | −500−500 | 保持边界内 |
| 动态危险惩罚 | RdynamicRdynamic | −100∼0−100∼0 | 远离动态障碍物 |
| 趋近奖励 | RcloserRcloser | +5∼+10+5∼+10 | 引导趋近目标 |
| 远离惩罚 | RfartherRfarther | −3−3 | 阻止远离目标 |
| 平滑度奖励 | RsmoothRsmooth | +0.5+0.5 | 平滑飞行轨迹 |
| 高度调整奖励 | RheightRheight | +1+1 | 引导高度调整 |
2.5 探索-利用策略
采用ε-greedy策略平衡探索与利用:

2.5 完整训练算法
Q-Learning训练算法的完整流程如下算法所示。

3.仿真实验与结果分析
实验在MATLAB R2024b平台上进行,实验参数设置如表3所示。
3.1 仿真参数
| 参数 | 符号 | 数值 |
|---|---|---|
| 栅格尺寸 | Nx×Ny×NzNx×Ny×Nz | 20×20×1020×20×10 |
| 起点 | ss | (1,1,1)(1,1,1) |
| 终点 | gg | (20,20,8)(20,20,8) |
| 静态障碍物数 | NstaticNstatic | 50 |
| 动态障碍物数 | NdynamicNdynamic | 5 |
| 训练回合数 | KK | 2000 |
| 最大步数 | TmaxTmax | 300 |
| 学习率 | α0α0 | 0.1 |
| 折扣因子 | γγ | 0.95 |
| 初始探索率 | ε0ε0 | 1.0 |
| 最终探索率 | εminεmin | 0.01 |
| 探索率衰减系数 | λελε | 0.998 |
3.2 部分matlab程序
% --- 环境参数 ---
params.grid_size = [20, 20, 10]; % 三维栅格大小 [X, Y, Z]
params.start = [1, 1, 1]; % 起点
params.goal = [20, 20, 8]; % 终点
params.num_static_obs = 50; % 静态障碍物数量
params.num_dynamic_obs = 5; % 动态障碍物数量
params.dynamic_obs_speed = 1; % 动态障碍物每步最大移动距离
% --- Q-Learning参数 ---
params.num_episodes = 2000; % 训练回合数
params.max_steps = 300; % 每回合最大步数
params.alpha = 0.1; % 学习率
params.gamma = 0.95; % 折扣因子
params.epsilon_start = 1.0; % 初始探索率
params.epsilon_end = 0.01; % 最终探索率
params.epsilon_decay = 0.998; % 探索率衰减系数
% --- 奖励参数 ---
params.reward_goal = 1000; % 到达终点奖励
params.reward_collision = -500; % 碰撞惩罚
params.reward_out_of_bounds = -500; % 越界惩罚
params.reward_step = -1; % 每步惩罚
params.reward_closer = 5; % 靠近目标奖励
params.reward_farther = -3; % 远离目标惩罚
params.reward_dynamic_danger = -100; % 接近动态障碍物额外惩罚3.3 仿真结果
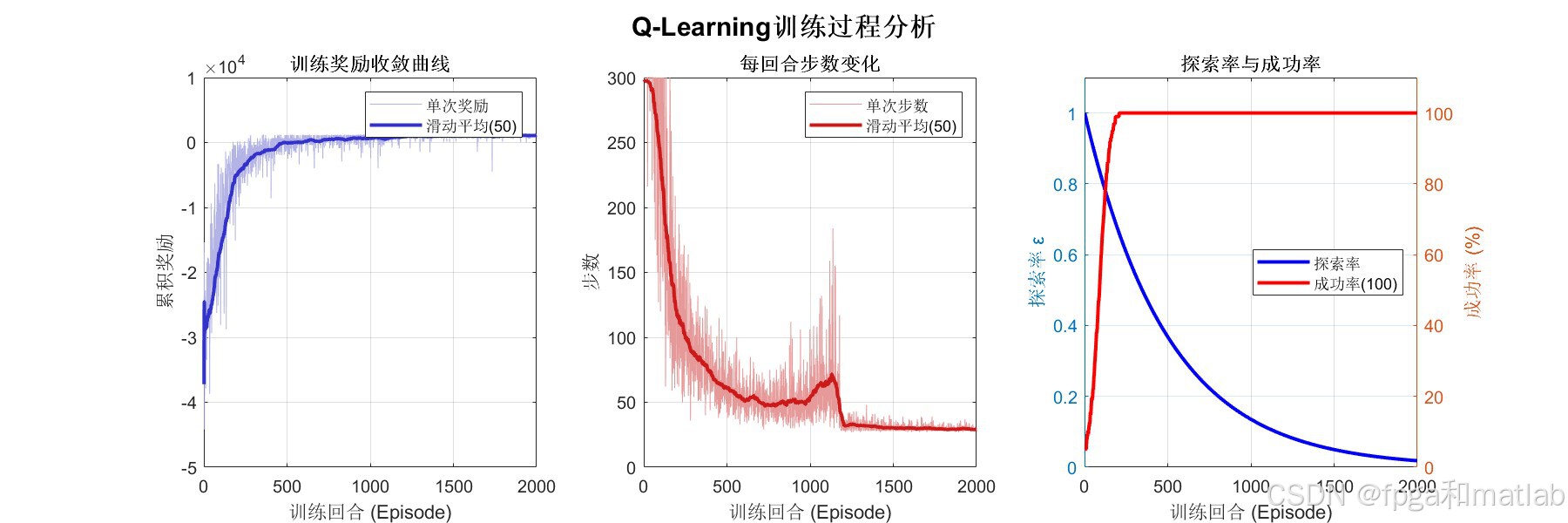
训练初期(0~500轮),由于高探索率,智能体频繁碰撞障碍物或越界,累积奖励多为负值,波动剧烈。中期(500~1200轮),随着探索率衰减和Q表逐步完善,智能体学会基本的避障策略,奖励明显上升。后期(1200~2000轮),滑动平均奖励趋于稳定正值,表明算法收敛。
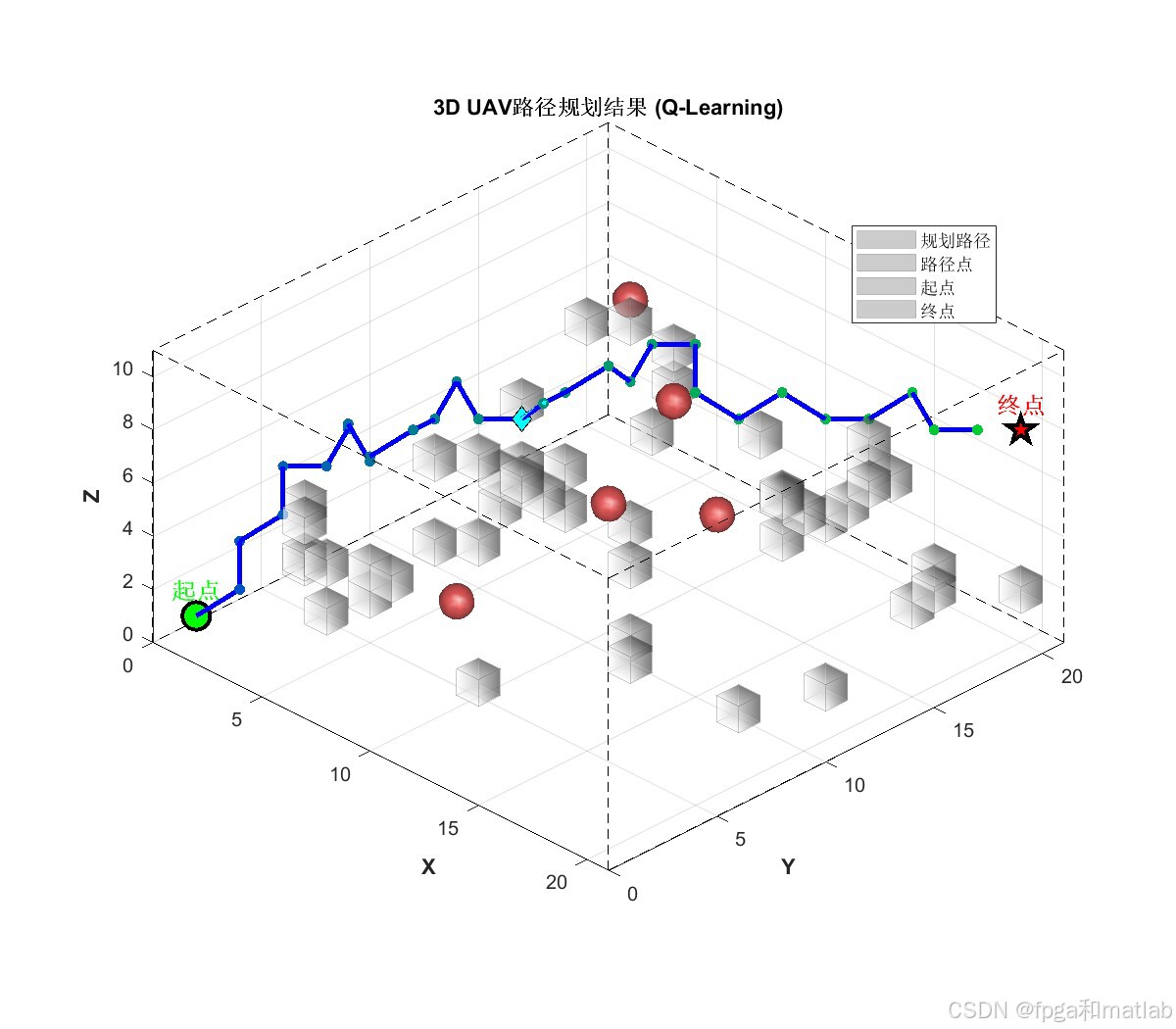
训练完成后的最优路径三维可视化。路径从起点(1,1,1) 出发,在避开所有静态障碍物簇和动态障碍物的同时,平滑地飞向终点 (20,20,8)。
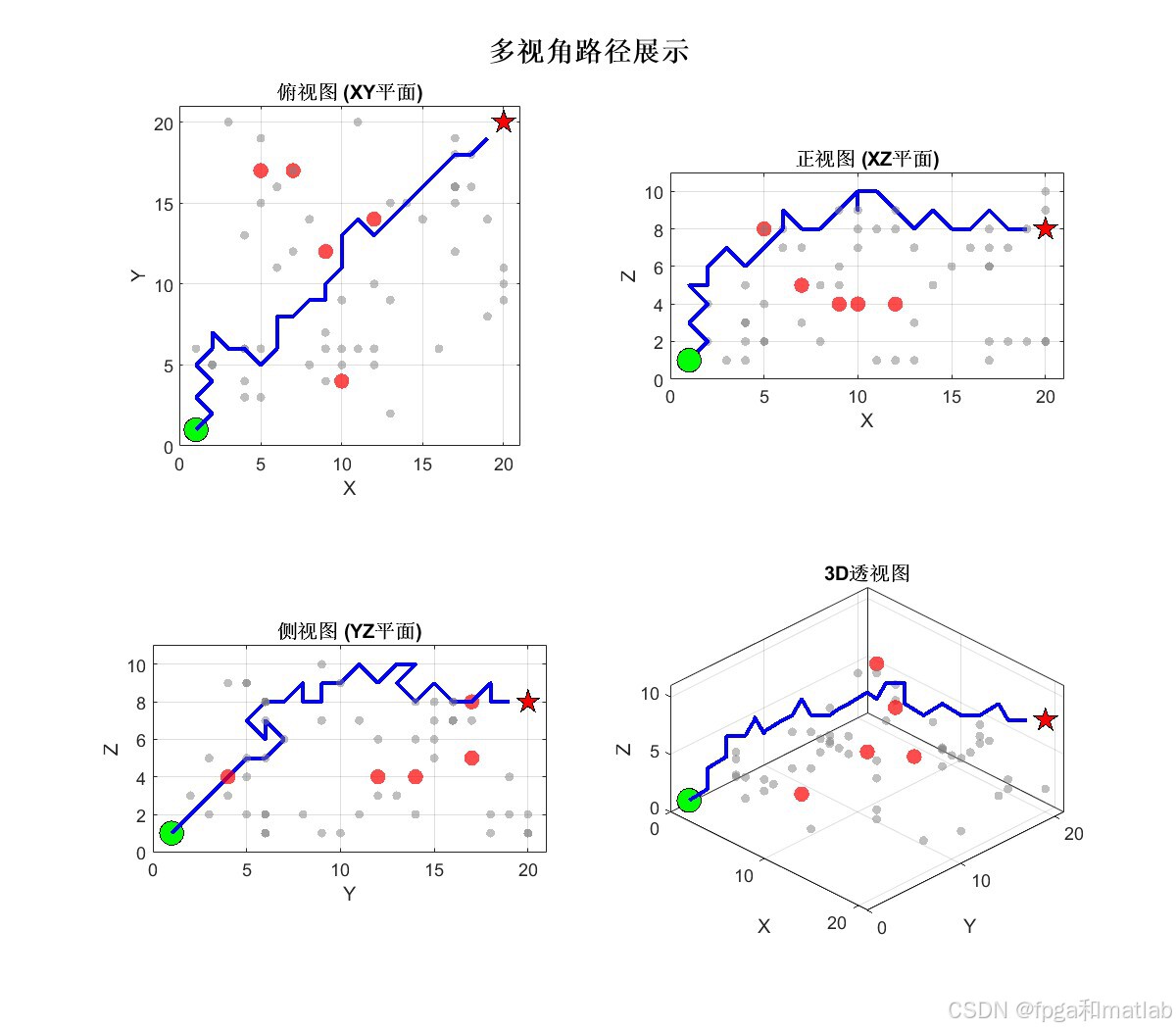
展示了多视角(俯视、正视、侧视、透视)下的路径投影。
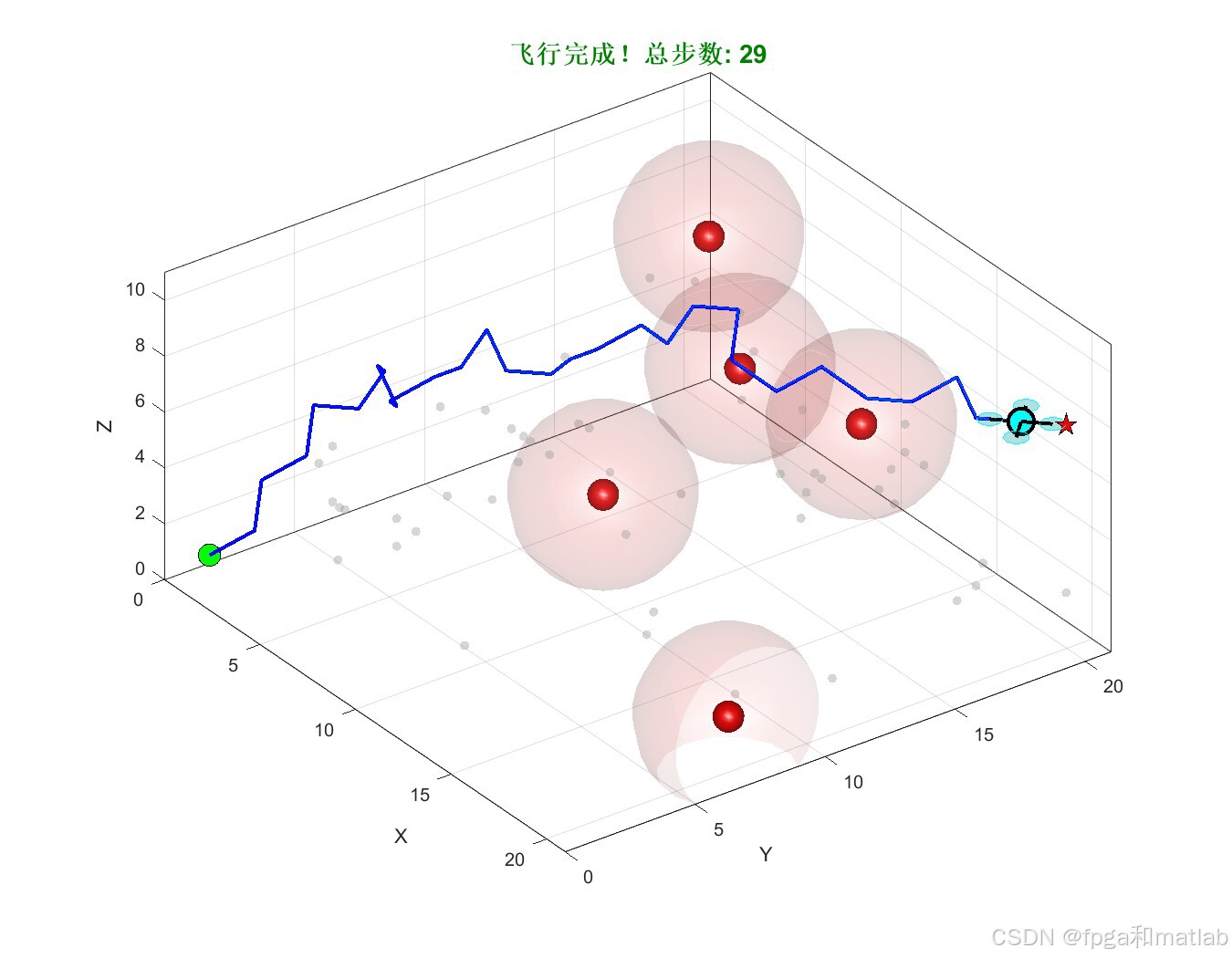
图为无人机飞行动态动画截图,展示了无人机在飞行过程中实时避开运动障碍物的能力。
4.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)