kokoro的安装使用
经过测试 使用中文标点符号效果很好 停顿自然
例如 顾家少爷穿越了,好消息是他是王城七大家族的主脉独苗,坏消息是他是个弑神体,还是个将死之人。
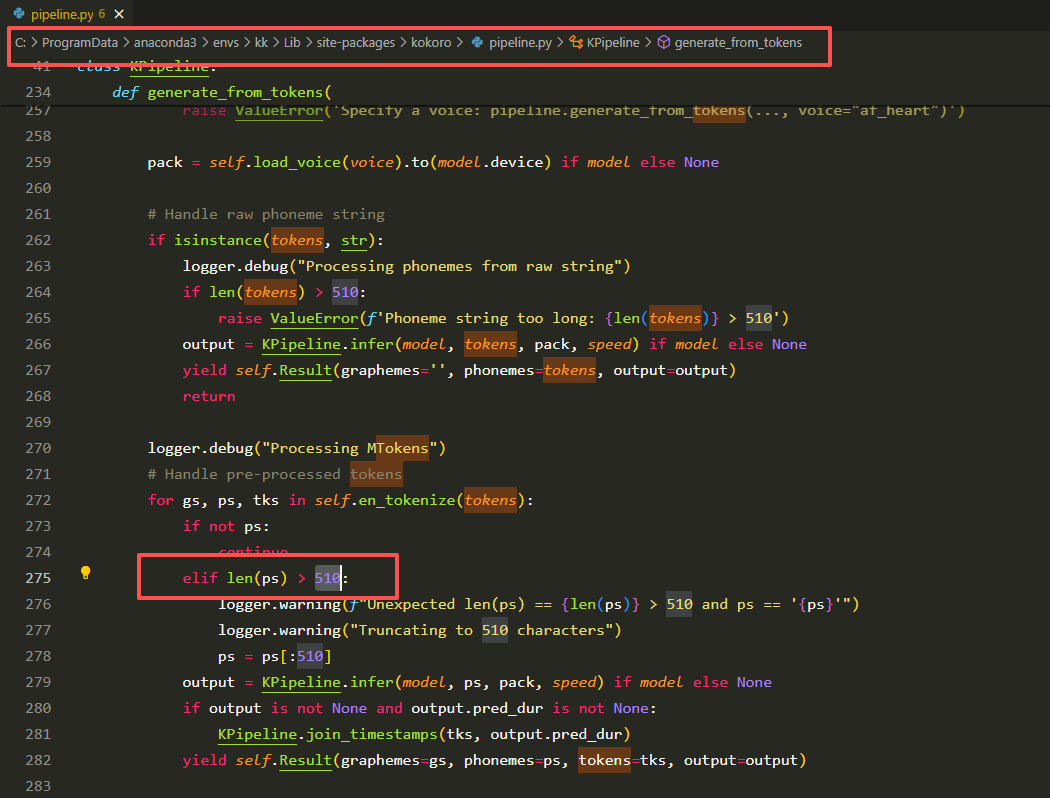
每次有字数限制 默认限制510token
可以修改解除限制 但是我改了没用就很奇怪 最后看 模型本身就只支持510
IndexError: index 595 is out of bounds for dimension 0 with size 510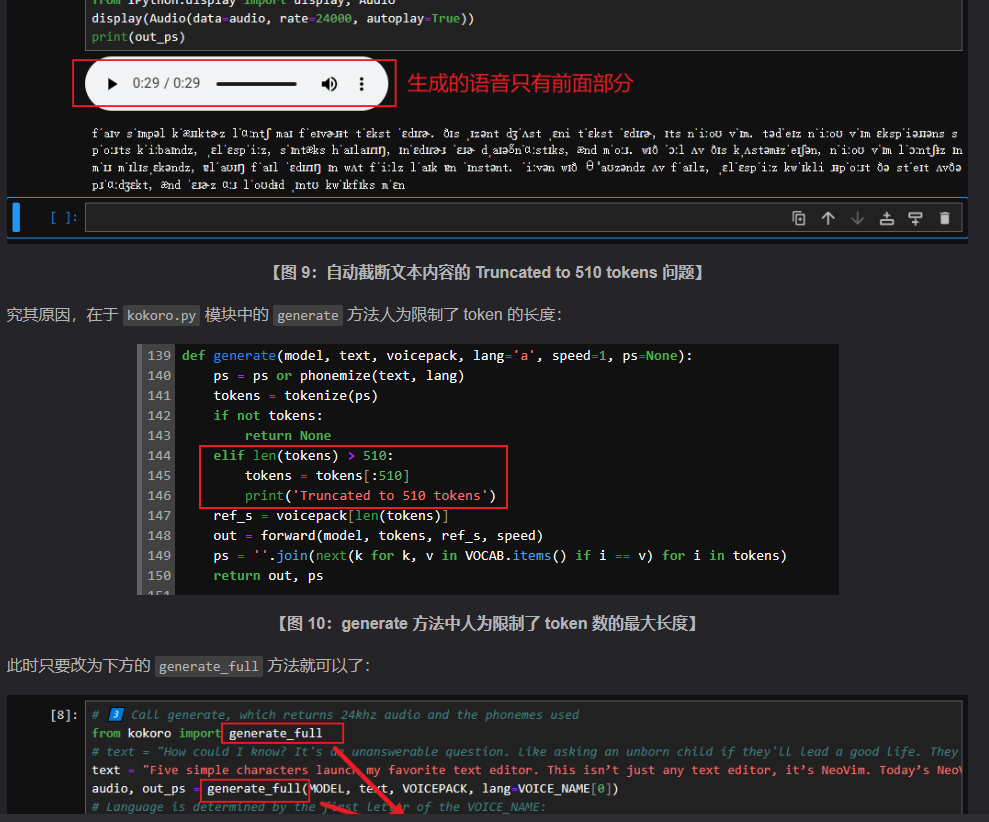
Kokoro-82M 实战:最强 TTS 开源模型 Windows 本地极简部署完全攻略_kokoro tts 部署流程-CSDN博客
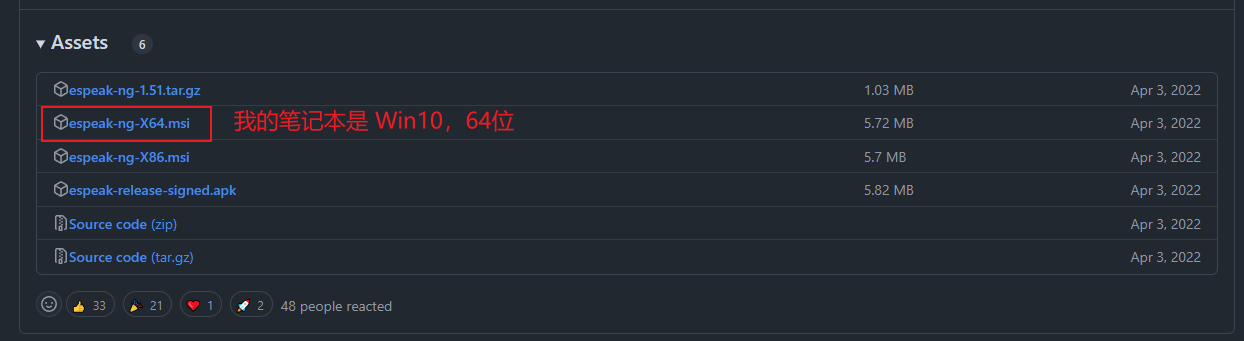
https://github.com/espeak-ng/espeak-ng
espeak-ng
注意看!这个被女友嫌弃、被生活逼到绝境的普通修理工林辰,只因意外激活超级黄金手,人生彻底开挂!手掌触物便解锁顶级技能,修啥啥精通,废品秒变珍宝,昔日嘲讽他的人全被狠狠打脸。母亲的病有了救,背叛的女友追悔莫及,各路大佬争相攀附。从底层修理工到都市逆袭大佬,林辰凭一双黄金手
先安装espeak-ng
创建python3.10版本
直接 pip install kokoro
然后看可能会存在没安装的 然后手动安装

num2words安装不了是因为我是阿里源 没找到这个包 那就换回官方源
https://pypi.org/simple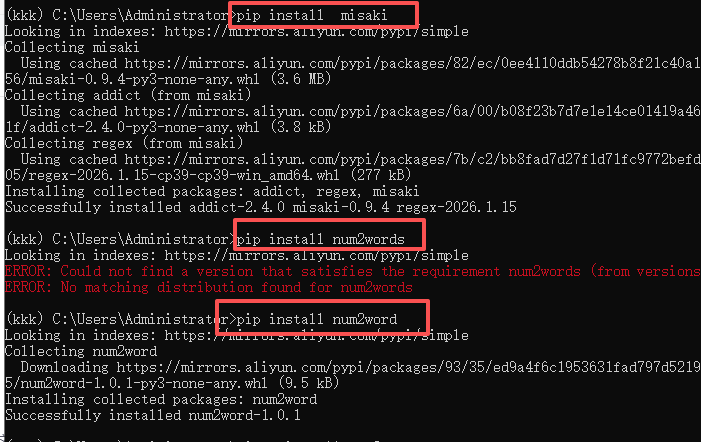
然后会发现kokoro没安装好 那就继续重新 pip install kokoro
缺什么补什么就行 反正很慢 因为还要加载模型然后调用 发现缺什么包
如果不想补的 就直接去下载克隆他的项目
pip install .安装到本地
kokoro-tts-zh/app.py at main · ardorleo/kokoro-tts-zh
3.9的python不行 官方说支持 但是各种报错
Python 3.10.19可以
下面是整个环境的模块包 注意 报错torchcodec 就是pip uninstall torch torchvision torchaudio -y这三个版本不兼容
后来用的这个pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1
下面是gpu版本从阿里云下载 自己设置版本
pip3 install torch torchvision torchaudio -f https://mirrors.aliyun.com/pytorch-wheels/cu126
安装不了gpu版本就用下面这个
pip3 install torch==2.5.1+cu121 torchvision==0.20.1+cu121 torchaudio==2.5.1+cu121 -f https://mirrors.aliyun.com/pytorch-wheels/cu121
不用安装torchcodec 可能是因为新版需要单独安装torchcodec 旧版不要吧
accelerate==1.12.0
addict==2.4.0
annotated-doc==0.0.4
annotated-types==0.7.0
anyio==4.12.1
asttokens==3.0.1
attrs==25.4.0
audioread==3.1.0
babel==2.18.0
backcall==0.2.0
beautifulsoup4==4.14.3
black==26.1.0
bleach==6.3.0
blinker==1.9.0
blis==1.3.3
catalogue==2.0.10
certifi==2026.2.25
cffi==2.0.0
charset-normalizer==3.4.4
chattts @ git+https://github.com/2noise/ChatTTS.git@c26573a61ebde14ac456d8ed4b9f96908d3dd8fa
click==8.3.1
cloudpathlib==0.23.0
cn2an==0.5.23
colorama==0.4.6
confection==0.1.5
contourpy==1.3.2
coverage==7.13.4
csvw==3.7.0
curated-tokenizers==0.0.9
curated-transformers==0.1.1
cycler==0.12.1
cymem==2.0.13
decorator==5.2.1
defusedxml==0.7.1
dlinfo==2.0.0
docopt==0.6.2
einops==0.8.2
einx==0.3.0
en_core_web_sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.8.0/en_core_web_sm-3.8.0-py3-none-any.whl#sha256=1932429db727d4bff3deed6b34cfc05df17794f4a52eeb26cf8928f7c1a0fb85
encodec==0.1.1
espeakng-loader==0.2.4
exceptiongroup==1.3.1
executing==2.2.1
fastapi==0.133.1
fastjsonschema==2.21.2
filelock==3.24.3
flake8==7.3.0
Flask==3.1.3
flask-cors==6.0.2
fonttools==4.61.1
frozendict==2.4.7
fsspec==2026.2.0
h11==0.16.0
hf-xet==1.3.1
httpcore==1.0.9
httpx==0.28.1
huggingface_hub==1.4.1
idna==3.11
iniconfig==2.3.0
ipython==8.12.3
isodate==0.7.2
itsdangerous==2.2.0
jedi==0.19.2
jieba==0.42.1
Jinja2==3.1.6
joblib==1.5.3
jsonschema==4.26.0
jsonschema-specifications==2025.9.1
jupyter_client==8.8.0
jupyter_core==5.9.1
jupyterlab_pygments==0.3.0
kiwisolver==1.4.9
kokoro==0.9.4
language-tags==1.2.0
lazy_loader==0.4
librosa==0.11.0
librt==0.8.1
llvmlite==0.46.0
loguru==0.7.3
markdown-it-py==4.0.0
MarkupSafe==3.0.3
matplotlib==3.10.8
matplotlib-inline==0.2.1
mccabe==0.7.0
mdurl==0.1.2
misaki==0.9.4
mistune==3.2.0
mpmath==1.3.0
msgpack==1.1.2
murmurhash==1.0.15
mypy==1.19.1
mypy_extensions==1.1.0
nbclient==0.10.4
nbconvert==7.17.0
nbformat==5.10.4
networkx==3.4.2
noisereduce==3.0.3
num2words==0.5.14
numba==0.64.0
numpy==2.2.6
OpenCC==1.2.0
ordered-set==4.1.0
packaging @ file:///C:/miniconda3/conda-bld/packaging_1761049101700/work
pandas==2.3.3
pandocfilters==1.5.1
parso==0.8.6
pathspec==1.0.4
phonemizer-fork==3.3.2
pickleshare==0.7.5
pillow==12.1.1
pipreqs==0.5.0
platformdirs==4.9.2
pluggy==1.6.0
pooch==1.9.0
preshed==3.0.12
proces==0.1.7
prompt_toolkit==3.0.52
psutil==7.2.2
pure_eval==0.2.3
pybase16384==0.3.8
pycodestyle==2.14.0
pycparser==3.0
pydantic==2.12.5
pydantic_core==2.41.5
pyflakes==3.4.0
Pygments==2.19.2
pyparsing==3.3.2
pypinyin==0.55.0
pypinyin-dict==0.9.0
pytest==9.0.2
pytest-cov==7.0.0
python-dateutil==2.9.0.post0
pytokens==0.4.1
pytz==2025.2
PyYAML==6.0.3
pyzmq==27.1.0
rdflib==7.6.0
referencing==0.37.0
regex==2026.2.19
requests==2.32.5
resampy==0.4.3
rfc3986==1.5.0
rich==14.3.3
rpds-py==0.30.0
safetensors==0.7.0
scikit-learn==1.7.2
scipy==1.15.3
segments==2.3.0
shellingham==1.5.4
six==1.17.0
smart_open==7.5.1
soundfile==0.13.1
soupsieve==2.8.3
soxr==1.0.0
spacy==3.8.11
spacy-curated-transformers==0.3.1
spacy-legacy==3.0.12
spacy-loggers==1.0.5
srsly==2.5.2
stack-data==0.6.3
starlette==0.52.1
sympy==1.13.1
termcolor==3.3.0
thinc==8.3.10
threadpoolctl==3.6.0
tinycss2==1.4.0
tokenizers==0.22.2
toml==0.10.2
tomli==2.4.0
torch==2.5.1
torchaudio==2.5.1
torchvision==0.20.1
tornado==6.5.4
tqdm==4.67.3
traitlets==5.14.3
transformers==5.2.0
typer==0.24.1
typer-slim==0.24.0
types-requests==2.32.4.20260107
typing-inspection==0.4.2
typing_extensions==4.15.0
tzdata==2025.3
uritemplate==4.2.0
urllib3==2.6.3
uvicorn==0.41.0
vector-quantize-pytorch==1.27.21
vocos==0.1.0
wasabi==1.1.3
wcwidth==0.6.0
weasel==0.4.3
webencodings==0.5.1
webrtcvad==2.0.10
Werkzeug==3.1.6
win32_setctime==1.2.0
wrapt==2.1.1
yarg==0.1.9
import torchaudio
from kokoro import KModel, KPipeline
import warnings
warnings.filterwarnings("ignore")
REPO_ID = 'hexgrad/Kokoro-82M-v1.1-zh'
# 1. 加载模型
model = KModel(repo_id=REPO_ID).to('cpu').eval()
# 2. 创建英文pipeline(用于音素转换)
en_pipeline = KPipeline(lang_code='a', repo_id=REPO_ID, model=False)
# 3. 定义英文转换函数
def en_callable(text):
return next(en_pipeline(text)).phonemes
# 4. 创建中文pipeline(这才是关键!)
zh_pipeline = KPipeline(
lang_code='z', # 注意这里是 'z' 不是 'a'!
repo_id=REPO_ID,
model=model, # 传入模型
en_callable=en_callable # 传入英文处理函数
)
# 5. 生成中文语音
text = "你好世界, hello world差不多是这意思!model设为False时,它会默认加载v1.1的中英混合模型,所以不用传回调就能混读;要是设为True或者传入model实例,就会强制用纯中文模型,这时候就得传en_callable才能处理英文了。"
voice = 'zm_029' # 中文男声
audio_segments = []
# 使用中文pipeline生成
results = list(zh_pipeline(text, voice=voice))
audio_segments = [a.audio for a in results]
import soundfile as sf
import numpy as np
if audio_segments:
full_audio = np.concatenate(audio_segments)
sf.write('output_full.wav', full_audio, 24000)
print(f"✅ 成功生成 {len(audio_segments)} 个片段,总时长 {len(full_audio)/24000:.2f} 秒")它加载模型我每次都不能单独传路径进去 就只能用c盘
那我就直接mklink创建一个链接
- mklink /J "C:\Users\Administrator\.cache\huggingface\hub\models--hexgrad--Kokoro-82M-v1.1-zh" "D:\AI\models--hexgrad--Kokoro-82M-v1.1-zh"

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)