第三章 一元线性回归
3.1 什么是线性回归
线性回归要做的事就是:找到一条直线,尽可能准确地描述这种规律,然后用这条直线预测新数据。
线性回归模型
一元线性回归模型
y^=wx+b\hat{y} = wx + by^=wx+b
输入变量x,输出预测值y^\hat{y}y^ (读作"y hat")
其中w 是权重(weight),控制直线的斜率,决定x 每增加1单位时预测值增加多少;b 是偏置(bias),控制直线的截距,决定x=0时预测值是多少。
w和b就是模型的参数,也是需要训练数据学习得出的东西。目标是找到让直线最贴合数据的w和b。
线性回归是理解整个深度学习的最佳起点,一、它包含了机器学习的完整流程;二、神经网络的每一个神经元本质上就是一个线性回归加一个激活函数;第三、线性回归的损失曲面是标准的碗型,只有一个全局最小值,适合理解优化过程,没有局部最小值的干扰。
图中蓝色散点是带噪声的真实数据,红色直线是线性回归找到的最佳拟合线。灰色虚线是每个数据点到直线的距离,叫做残差——线性回归的目标就是让所有残差尽可能小。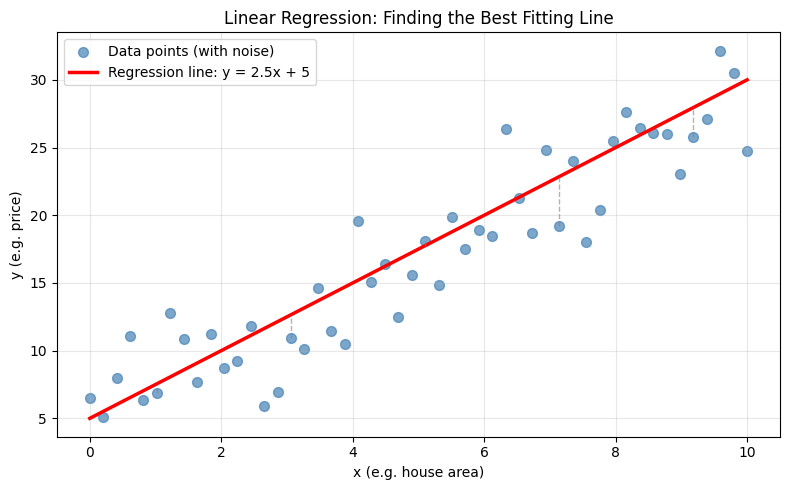
3.2 数据集和特征的表示
数据集的结构
机器学习的一切都从数据开始。一个标准的数据集由若干条样本组成,每条样本包含两部分:特征和标签。特征是输入,标签是我们想预测的输出。
以房价预测为例,一条样本可能长这样:面积100平方米(特征),价格300万(标签)。把50条这样的样本收集在一起,就构成了一个数据集。
在数学上我们用以下符号来表示。用 x(i)x^{(i)}
x(i)x(i)x(i) 表示第i 条样本的特征值,用y(i)y^{(i)}y(i)表示第 iii条样本的真实标签,用 mmm
表示样本总数。所以整个数据集可以写成:
{(x(1),y(1)), (x(2),y(2)), …, (x(m),y(m))}\{(x^{(1)}, y^{(1)}),\ (x^{(2)}, y^{(2)}),\ \ldots,\ (x^{(m)}, y^{(m)})\}{(x(1),y(1)), (x(2),y(2)), …, (x(m),y(m))}
注意这里的上标(i)(i)(i)
是样本编号,不是幂次,这是机器学习里约定俗成的写法,后面看论文时会频繁遇到。
特征与标签的区别
特征(Feature)是模型的输入,是已知的信息,也叫自变量。标签(Label)是模型要预测的目标,是未知的信息,也叫因变量。训练时两者都有,预测时只有特征,让模型估算出标签。
在一元线性回归里特征只有一个,但现实中往往有多个特征——面积、楼层、地段同时影响房价。多个特征的情况在第4章多元线性回归里会详细处理,现在只关注一个特征的情况。
训练集、验证集和测试集
拿到数据集之后不能把所有数据都用来训练,需要把它分成三份。训练集用来训练模型,让模型从中学习规律,通常占总数据的70%到80%。验证集用来在训练过程中监控模型表现,调整超参数(比如学习率),通常占10%到15%。测试集只在最终评估时使用一次,模拟模型在真实世界遇到全新数据时的表现,通常占10%到15%。
为什么要这样划分?因为如果用训练数据来评估模型,模型可能只是"背住"了训练数据,在新数据上表现很差,这叫过拟合。用模型从未见过的测试集来评估,才能真实反映它的泛化能力。这个概念在后面神经网络章节会反复出现。
import numpy as np
np.random.seed(42) # 固定随机种子,保证每次运行结果一致
# 生成50个样本:x是特征(房屋面积),y是标签(价格)
# 真实规律是 y = 2.5x + 5,加上随机噪声模拟现实中的不确定性
m = 50 # 样本总数
x = np.linspace(0, 10, m) # 特征:50个均匀分布的面积值
y = 2.5 * x + 5 + np.random.randn(m) * 3 # 标签:真实规律 + 噪声
# 划分训练集和测试集(80%训练,20%测试)
split = int(0.8 * m) # 分割点在第40个样本
x_train, x_test = x[:split], x[split:] # 前40个用于训练
y_train, y_test = y[:split], y[split:] # 后10个用于测试
print(f"总样本数:{m}")
print(f"训练集大小:{len(x_train)}")
print(f"测试集大小:{len(x_test)}")
# 查看前5条训练样本,感受数据的样子
for i in range(5):
print(f" 样本{i+1}:x^({i+1})={x_train[i]:.2f},y^({i+1})={y_train[i]:.2f}")
np.random.seed(42) 固定了随机种子,保证每次运行生成的随机噪声完全相同,让实验结果可以复现。
3.3 一元线性回归模型
一元线性回归模型的表达式是:
y^(i)=wx(i)+b\hat{y}^{(i)} = wx^{(i)} + by^(i)=wx(i)+b
y^(i)\hat{y}^{(i)}y^(i) 是模型对第 iii 个样本的预测值,y(i)y^{(i)}y(i)是真实标签,两者之差就是误差。模型的任务就是通过调整 www 和 bbb,让所有样本的预测值尽可能接近真实标签。
参数的几何含义
w 和 b 不只是两个数字,它们有直观的几何含义。w 是直线的斜率,决定了特征对预测值的影响程度。w 越大,直线越陡,说明 x 每增加一个单位,预测值增加越多。b 是截距,决定了当 x=0 时预测值是多少,可以理解为基准值。不同的 w 和 b 组合会画出完全不同的直线,我们的目标是从无数条可能的直线中,找到那一条与数据点整体误差最小的。
参数初始化
训练开始之前,w 和 b 的值是未知的,需要给它们一个初始值,然后用梯度下降去优化。通常有两种初始化策略:全部初始化为零,或者随机初始化为一个很小的数。对于线性回归,两种方式都可以,因为它的损失曲面是标准碗形,从任何起点出发都能收敛到同一个最低点。但在神经网络里,全零初始化会导致严重问题,第7章会专门讲这个。
前向传播的概念
给定一组参数 w 和 b,把输入 x 代入公式算出预测值 y^\hat{y}y^ 的过程,叫做
前向传播(Forward Pass)。这个名字在线性回归里用得比较少,但在神经网络里是核心概念,第7章的标题就叫"前向传播"。现在先建立这个印象:数据从输入端流向输出端,经过模型计算得到预测值,这个方向就叫前向。
import numpy as np
# 初始化参数
w = 0.0 # 斜率,初始为0
b = 0.0 # 截距,初始为0
# 前向传播:给定x,计算预测值
def forward(x, w, b):
return w * x + b # 就是 y_hat = wx + b
# 用上一节生成的数据测试
np.random.seed(42)
m = 50
x = np.linspace(0, 10, m)
y = 2.5 * x + 5 + np.random.randn(m) * 3
# 用初始参数做一次预测
y_pred = forward(x, w, b)
print(f"参数:w={w}, b={b}")
print(f"前5个真实值:{y[:5].round(2)}")
print(f"前5个预测值:{y_pred[:5].round(2)}")
print(f"此时预测值全为0,说明模型还什么都没学到,需要训练")
运行后你会看到预测值全是0,真实值却各不相同。这就是训练开始前的状态——模型一无所知。训练的过程就是不断调整 w 和 b,让预测值越来越接近真实值。
模型、损失、优化的三角关系
到这里可以把整个机器学习的流程用一句话概括:定义模型(y^=wx+b\hat{y} = wx+by^=wx+b)→定义损失(预测值和真实值差多少)→ 用梯度下降优化参数(让损失变小)。下一节讲的MSE均方误差就是"定义损失"这一步,之后每一章都是在这个框架里填入不同的模型和损失函数。
3.4 深入理解MSE均方误差
上一节模型作出了预测,但是需要衡量预测有多差,衡量标准就是损失函数(Loss Function),而MSE是线性回归最经典的损失函数(y^(i)−y(i))2(\hat{y}^{(i)} - y^{(i)})^2(y^(i)−y(i))2。
从残差到MSE
每个样本的预测值y^(i)\hat{y}^{(i)}y^(i)
和真实值 y(i)y^{(i)}y(i) 之间的差叫做残差:
e(i)=y^(i)−y(i)e^{(i)} = \hat{y}^{(i)} - y^{(i)}e(i)=y^(i)−y(i)
残差可正可负,正表示预测偏高,负表示预测偏低。我们想把所有样本的残差汇总成一个数字来反映模型整体的误差。直接求和不行,因为正负残差会互相抵消,掩盖真实误差。取绝对值可以,但绝对值函数在零点不可导,对梯度下降不友好。
解决方案是平方——把每个残差平方,消除正负,然后求平均。这就是MSE(Mean Squared Error,均方误差):
MSE=1m∑i=1m(y^(i)−y(i))2=1m∑i=1m(wx(i)+b−y(i))2MSE = \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})^2 = \frac{1}{m}\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})^2MSE=m1∑i=1m(y^(i)−y(i))2=m1∑i=1m(wx(i)+b−y(i))2
m 是样本总数,除以 m 是为了让损失值不随数据集大小变化,方便比较。
平方的三重好处
第一,消除了正负号,所有误差都变成正数,大误差贡献大,小误差贡献小。第二,对大误差惩罚更重——残差为2时平方是4,残差为4时平方是16,模型会更努力地去纠正那些偏差特别大的样本。第三,平方函数处处可导,梯度下降可以顺畅运行。
MSE的几何直觉
回到上一节的图,灰色虚线是每个点到直线的垂直距离(残差)。MSE就是把所有这些距离的平方加起来再取平均。直线越贴近数据点,这些距离越短,MSE越小。找最佳直线的过程,就等价于最小化MSE。
MSE作为 w 和 b 的函数
这里有一个非常重要的视角转换。MSE看起来是预测误差的度量,但把 y^(i)=wx(i)+b\hat{y}^{(i)} = wx^{(i)}+by^(i)=wx(i)+b 代入之后,它实际上是关于参数 w 和 b 的函数:
L(w,b)=1m∑i=1m(wx(i)+b−y(i))2L(w, b) = \frac{1}{m}\sum_{i=1}^{m}(wx^{(i)}+b-y^{(i)})^2L(w,b)=m1∑i=1m(wx(i)+b−y(i))2
数据 x(i)x^{(i)}x(i) 和 y(i)y^{(i)}y(i) 是固定的,变化的只有 w 和 b。这意味着MSE就是一个关于 w 和 b 的二元函数,它的形状是一个标准的碗形曲面,只有一个全局最小值。这正是线性回归如此友好的原因——无论从哪里出发,梯度下降必然收敛到最优解。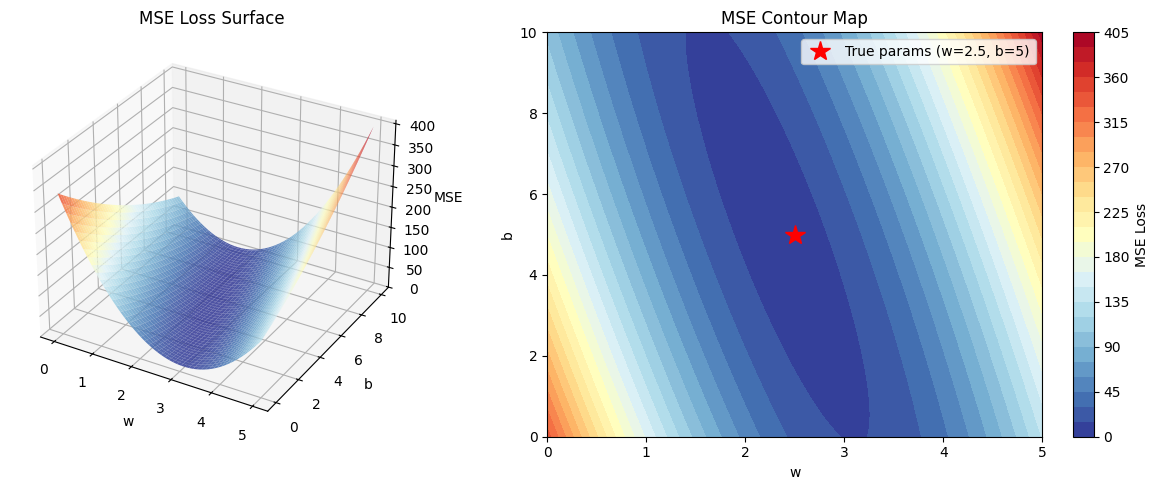
3.5 线性回归的代价函数
损失函数(Loss)与代价函数(Cost)常常混用,但其含义有细微差别。实践过程中二者不做严格区分。
损失函数:衡量单个样本的误差;代价函数:衡量整个训练集的平均误差。
MSE是代价函数—它对所有m个样本求了平均,在深度学习中两次几乎互换使用,基本指代代价函数。
代价函数的标准写法
线性回归的代价函数通常写成:
J(w,b)=12m∑i=1m(y^(i)−y(i))2J(w, b) = \frac{1}{2m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})^2J(w,b)=2m1∑i=1m(y^(i)−y(i))2
和上一节的MSE相比,唯一的区别是分母从 m 变成了 2m,多了一个系数12\frac{1}{2}21。这个 12\frac{1}{2}21 是纯粹为了数学上的方便——后面对 w 求偏导时,平方项会产生一个系数2,和 12\frac{1}{2}21 正好抵消,让梯度公式更简洁。它不影响最优解的位置,只是让推导更干净。
对代价函数求偏导
对 w 求偏导,把 y^(i)=wx(i)+b\hat{y}^{(i)} = wx^{(i)}+by^(i)=wx(i)+b 代入,用链式法则:
∂J∂w=1m∑i=1m(y^(i)−y(i))⋅x(i)\frac{\partial J}{\partial w} = \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)}) \cdot x^{(i)}∂w∂J=m1∑i=1m(y^(i)−y(i))⋅x(i)
对 b 求偏导,同理:
∂J∂b=1m∑i=1m(y^(i)−y(i))\frac{\partial J}{\partial b} = \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})∂b∂J=m1∑i=1m(y^(i)−y(i))
注意观察这两个公式的结构——它们都包含了(y^(i)−y(i))(\hat{y}^{(i)} - y^{(i)})(y^(i)−y(i))
这一项,也就是残差。对 w 的梯度是残差乘以对应的输入 x(i)x^{(i)}x(i)
,对 b 的梯度就是残差本身的平均。这个结构非常直觉:哪里预测错了(残差大),梯度就大,参数更新幅度就大。 模型会优先纠正误差最大的地方。
梯度下降更新公式
把偏导数代入梯度下降的通用公式θ:=θ−α⋅∂J∂θ,\theta := \theta - \alpha \cdot \frac{\partial J}{\partial \theta},θ:=θ−α⋅∂θ∂J,得到线性回归的参数更新规则:
w:=w−α⋅1m∑i=1m(y^(i)−y(i))⋅x(i)w := w - \alpha \cdot \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)}) \cdot x^{(i)}w:=w−α⋅m1∑i=1m(y^(i)−y(i))⋅x(i)
b:=b−α⋅1m∑i=1m(y^(i)−y(i))b := b - \alpha \cdot \frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)} - y^{(i)})b:=b−α⋅m1∑i=1m(y^(i)−y(i))
这两行公式就是线性回归训练的完整核心。每一轮迭代,先用当前参数计算所有样本的残差,然后按上面的公式同时更新 w 和 b,反复执行直到收敛。
为什么要同时更新
w 和 b 必须同时更新,而不是先更新 w 再用新的 w 去算 b 的梯度。原因是两个梯度都是基于同一个时刻的参数状态计算出来的,如果先更新 w,再算 b 的梯度时用的就是新的 w,破坏了一致性,会导致更新方向偏差。正确做法是先把两个梯度都算出来,再同时应用。
import numpy as np
np.random.seed(42)
m = 50
x = np.linspace(0, 10, m)
y = 2.5 * x + 5 + np.random.randn(m) * 3
# 初始化参数
w, b = 0.0, 0.0
lr = 0.01
for step in range(101):
# 前向传播:计算预测值
y_pred = w * x + b
# 计算残差
error = y_pred - y # shape: (m,)
# 计算两个梯度(此时w和b都还是旧值)
grad_w = np.mean(error * x) # ∂J/∂w
grad_b = np.mean(error) # ∂J/∂b
# 同时更新w和b(用旧梯度,不能先更新一个再算另一个)
w = w - lr * grad_w
b = b - lr * grad_b
if step % 20 == 0:
loss = np.mean(error ** 2)
print(f"step {step:3d} | w={w:.4f} b={b:.4f} loss={loss:.4f}")
print(f"\n训练结果:w={w:.4f},b={b:.4f}")
print(f"真实参数:w=2.5000,b=5.0000")
运行结果如下:
step 0 | w=1.0429 b=0.1682 loss=337.3869
step 20 | w=2.9980 b=0.6986 loss=12.6571
step 40 | w=2.9654 b=0.9198 loss=12.1550
step 60 | w=2.9339 b=1.1301 loss=11.7011
step 80 | w=2.9040 b=1.3300 loss=11.2907
step 100 | w=2.8756 b=1.5201 loss=10.9197
训练结果:w=2.8756,b=1.5201
真实参数:w=2.5000,b=5.0000
3.6 数学方法和梯度下降方法
两种求解思路:线性回归是机器学习里极少数既可以用梯度下降迭代求解,也可以用纯数学公式一步计算出答案的。
数学方法:正规方程
既然代价函数 J(w,b)是一个碗形曲面,最低点处梯度必然为零。我们可以直接令两个偏导数等于零,解出 w 和 b。对于一元线性回归,解出来的公式是:
w=∑i=1m(x(i)−xˉ)(y(i)−yˉ)∑i=1m(x(i)−xˉ)2w = \frac{\sum_{i=1}^{m}(x^{(i)} - \bar{x})(y^{(i)} - \bar{y})}{\sum_{i=1}^{m}(x^{(i)} - \bar{x})^2}w=∑i=1m(x(i)−xˉ)2∑i=1m(x(i)−xˉ)(y(i)−yˉ)
b=yˉ−wxˉb = \bar{y} - w\bar{x}b=yˉ−wxˉ
其中 xˉ\bar{x}xˉ 是所有 x 的均值,yˉ\bar{y}yˉ 是所有 y 的均值。这个公式叫做正规方程(Normal Equation),不需要任何迭代,代入数据直接算出最优参数。第4章讲矩阵时会把它推广到多元线性回归的矩阵形式
(XTX)−1XTy(X^TX)^{-1}X^Ty(XTX)−1XTy。
梯度下降方法回顾
梯度下降是从一个初始点出发,反复执行:
w:=w−α⋅∂J∂ww := w - \alpha \cdot \frac{\partial J}{\partial w}w:=w−α⋅∂w∂J
b:=b−α⋅∂J∂bb := b - \alpha \cdot \frac{\partial J}{\partial b}b:=b−α⋅∂b∂J
需要设置学习率、迭代次数,经过很多步才能逼近最优解。
两种方法的正面对比
这两种方法的差异,本质上是精确但有局限和近似但通用的取舍。
正规方程的优点是一步到位,不需要调学习率,不需要担心迭代次数,结果精确。缺点是当特征数量很多时,公式里涉及矩阵求逆,计算量随特征数的立方增长,特征超过几万个就慢得无法接受。更致命的是,它只对线性回归这种特殊结构有效,换成神经网络就完全无法使用。
梯度下降的优点是通用性极强,无论模型多复杂、参数多少,只要能算出梯度就能用。整个深度学习大厦都建在梯度下降之上。缺点是需要调学习率,收敛需要时间,而且只能保证找到局部最优解。
import numpy as np
np.random.seed(42)
m = 50
x = np.linspace(0, 10, m)
y = 2.5 * x + 5 + np.random.randn(m) * 3
# ===== 方法一:正规方程,一步求解 =====
x_mean = np.mean(x)
y_mean = np.mean(y)
w_exact = np.sum((x - x_mean) * (y - y_mean)) / np.sum((x - x_mean)**2)
b_exact = y_mean - w_exact * x_mean
print("===== 正规方程(数学方法)=====")
print(f"w = {w_exact:.4f},b = {b_exact:.4f}")
# ===== 方法二:梯度下降,迭代求解 =====
w, b = 0.0, 0.0
lr = 0.01
for step in range(2000): # 改成2000步,让它充分收敛
y_pred = w * x + b
error = y_pred - y
w = w - lr * np.mean(error * x)
b = b - lr * np.mean(error)
print("\n===== 梯度下降(迭代方法)=====")
print(f"w = {w:.4f},b = {b:.4f}")
print("\n===== 真实参数 =====")
print(f"w = 2.5000,b = 5.0000")
运行结果
===== 正规方程(数学方法)=====
w = 2.3260,b = 5.1933
===== 梯度下降(迭代方法)=====
w = 2.3306,b = 5.1628
===== 真实参数 =====
w = 2.5000,b = 5.0000
正规方程只能用于线性回归,神经网络的损失函数不是简单的碗型,无法令梯度为0直接解方程,梯度下降需要迭代但通用
正规方程给出了当前数据下的精准解,和真实参数之间的微小差异来自数据早上,是数据局限非方法局限。两种方法都正确
3.7 纯Python实现线性回归
本节讲前面所讲概念(数据集、模型、MSE损失、梯度推导、梯度下降)串联成完整的训练流程
完整训练流程的五个模块
完整的机器学习训练流程由五个模块组成,包括线性回归和神经网络。
五个模块分别为:准备数据、定义模型、定义损失、执行训练、评估结果。
import numpy as np
import matplotlib.pyplot as plt
# ==================== 模块一:准备数据 ====================
np.random.seed(42)
m = 50
x = np.linspace(0, 10, m)
y = 2.5 * x + 5 + np.random.randn(m) * 3 # 真实规律 + 噪声
# 划分训练集和测试集(80%训练,20%测试)
split = int(0.8 * m)
x_train, x_test = x[:split], x[split:]
y_train, y_test = y[:split], y[split:]
# ==================== 模块二:定义模型 ====================
def forward(x, w, b):
return w * x + b # 线性模型:y_hat = wx + b
# ==================== 模块三:定义损失 ====================
def compute_loss(y_pred, y_true):
return np.mean((y_pred - y_true) ** 2) # MSE
# ==================== 模块四:执行训练 ====================
w, b = 0.0, 0.0 # 参数初始化
lr = 0.01
epochs = 2000 # epoch:过一遍完整训练集叫一个epoch
loss_history = [] # 记录每步损失,用于画损失曲线
for epoch in range(epochs):
# 前向传播
y_pred = forward(x_train, w, b)
# 计算损失
loss = compute_loss(y_pred, y_train)
loss_history.append(loss)
# 计算梯度
error = y_pred - y_train
grad_w = np.mean(error * x_train) # ∂J/∂w
grad_b = np.mean(error) # ∂J/∂b
# 同时更新参数
w = w - lr * grad_w
b = b - lr * grad_b
# ==================== 模块五:评估结果 ====================
y_test_pred = forward(x_test, w, b)
test_loss = compute_loss(y_test_pred, y_test)
print(f"训练完成:w={w:.4f},b={b:.4f}")
print(f"真实参数:w=2.5000,b=5.0000")
print(f"测试集MSE:{test_loss:.4f}")
# 画两张图:损失曲线 + 拟合效果
fig, axes = plt.subplots(1, 2, figsize=(13, 5))
# 左图:损失曲线,观察训练是否正常收敛
axes[0].plot(loss_history, color='steelblue', linewidth=1.5)
axes[0].set_title('Training Loss Curve') # 训练损失曲线
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('MSE Loss')
axes[0].grid(True, alpha=0.3)
# 右图:拟合效果,对比预测直线和真实数据
x_line = np.linspace(0, 10, 100)
axes[1].scatter(x_train, y_train, color='steelblue', alpha=0.6, label='Train data')
axes[1].scatter(x_test, y_test, color='orange', alpha=0.8, label='Test data')
axes[1].plot(x_line, forward(x_line, w, b), 'r-', linewidth=2, label=f'Fitted: y={w:.2f}x+{b:.2f}')
axes[1].plot(x_line, 2.5*x_line + 5, 'g--', linewidth=2, label='True: y=2.5x+5')
axes[1].set_title('Fitting Result') # 拟合结果
axes[1].set_xlabel('x')
axes[1].set_ylabel('y')
axes[1].legend()
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
一个epoch表示模型把整个训练集完整过了一遍。在这里数据量小,每个epoch就是一次参数更新。但在后面的神经网络训练中,数据量很大,一个epoch会包含很多次小批量更新。你在所有深度学习代码里都会看到"训练100个epoch"这样的说法,指的就是把训练集完整过了100遍。
运行后得到损失曲线从一个较高的值快速下降,然后逐渐平缓趋于稳定,这是正常收敛的标志。拟合图里红色实线(训练结果)和绿色虚线(真实参数)应该非常接近,蓝色散点是训练数据,橙色散点是测试数据,红线对两者都应该拟合得不错,说明模型有良好的泛化能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)