基于 Tent-EBWO 优化 XGBoost 的回归预测及可解释性分析
在机器学习回归任务中,XGBoost 凭借其高效的梯度提升框架和优秀的泛化能力成为主流算法,但超参数的选择直接决定模型性能上限。黑寡妇优化算法(Black Widow Optimization, BWO)作为一种模拟黑寡妇蜘蛛繁殖行为的元启发式算法,在超参数寻优中表现出良好的全局搜索能力。本文提出基于 Tent 混沌映射增强的 EBWO(Enhanced Black Widow Optimization)算法优化 XGBoost 超参数,并结合核主成分分析(KPCA)进行特征降维,最终通过 10 类科研级可视化图表完成模型可解释性分析,形成一套完整的回归预测解决方案。
目录
1.2 Tent 增强型黑寡妇优化算法(Tent-EBWO)
一、核心方法原理
1.1 数据预处理:核主成分分析(KPCA)
传统 PCA 仅能处理线性可分数据,KPCA 通过核函数将数据映射到高维特征空间,实现非线性降维,核心公式如下:
核函数映射:设原始特征空间为X,高维特征空间为H,核函数k(xi,xj)=ϕ(xi)⋅ϕ(xj),本文选用径向基核函数(RBF):
![]()
其中γ为核宽度参数,控制映射的非线性程度。
KPCA 降维步骤:

1.2 Tent 增强型黑寡妇优化算法(Tent-EBWO)
1.2.1 Tent 混沌映射
为解决 BWO 初始种群分布不均的问题,引入 Tent 混沌映射初始化种群,公式为:
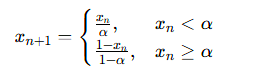
其中α=0.5为混沌参数,通过20次迭代预热消除初始扰动,保证种群的均匀性。
1.2.2 EBWO核心操作
EBWO继承BWO的繁殖(Procreation)、同类相食(Cannibalism)和变异(Mutation)三大核心行为,本文简化后的核心流程:
- 繁殖:随机选择2个父代个体p1,p2,生成子代:c1=αp1+(1−α)p2,c2=αp2+(1−α)p1其中α为[0,1]随机向量。
- 变异:随机交换个体的2个维度值,增强种群多样性。
- 选择:合并父代和子代种群,选择适应度最优的N个个体(N为种群规模)。
1.2.3 适应度函数
以5折交叉验证的均方误差(MSE)作为适应度函数,越小表示模型性能越好:
![]()
其中m为验证集样本数,yi为真实值,y^i为预测值。
1.3 XGBoost回归模型
XGBoost的核心是加法模型,第t棵树的预测值为:
![]()
目标函数通过泰勒二阶展开优化:
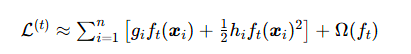
![]()
1.4 模型评价指标
本文选用3个核心评价指标:
- 均方根误差(RMSE):
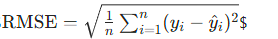
- 平均绝对误差(MAE):
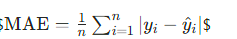
- 决定系数(R2):
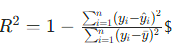
二、实验实现
2.1 环境配置
| 依赖库 | 版本 | 功能 |
|---|---|---|
| Python | 3.9+ | 基础运行环境 |
| NumPy | 1.24+ | 数值计算 |
| Scikit-learn | 1.2+ | 数据预处理/模型评估 |
| XGBoost | 1.7+ | 回归模型训练 |
| Matplotlib/Seaborn | 3.7+/0.12+ | 可视化 |
| SHAP | 0.41+ | 模型可解释性分析 |
2.2 代码结构解析
本文代码分为6个核心模块,各司其职且低耦合:
| 文件名称 | 核心功能 |
|---|---|
config.py |
全局参数配置(数据/优化/模型参数) |
data_process.py |
数据生成、标准化、KPCA降维 |
optimizer.py |
Tent-EBWO算法实现(种群初始化/迭代寻优) |
model.py |
XGBoost模型训练、超参数解码、指标计算 |
plot_utils.py |
10类科研级可视化图表生成 |
main.py |
主流程调度(数据→优化→训练→评估→可视化) |
2.3 关键参数设置
| 参数类别 | 参数名称 | 取值 |
|---|---|---|
| 数据参数 | 样本数(N_SAMPLES) | 500 |
| 原始特征数(N_FEATURES) | 20 | |
| KPCA降维后维度(KPCA_COMPONENTS) | 8 | |
| 优化参数 | 种群规模(POP_SIZE) | 20 |
| 最大迭代次数(MAX_ITER) | 30 | |
| 繁殖率 | 0.6 | |
| 变异率 | 0.4 | |
| XGBoost参数边界 | n_estimators | [50, 300] |
| max_depth | [3, 10] | |
| learning_rate | [0.01, 0.3] | |
| subsample | [0.6, 1.0] |
三、结果与分析
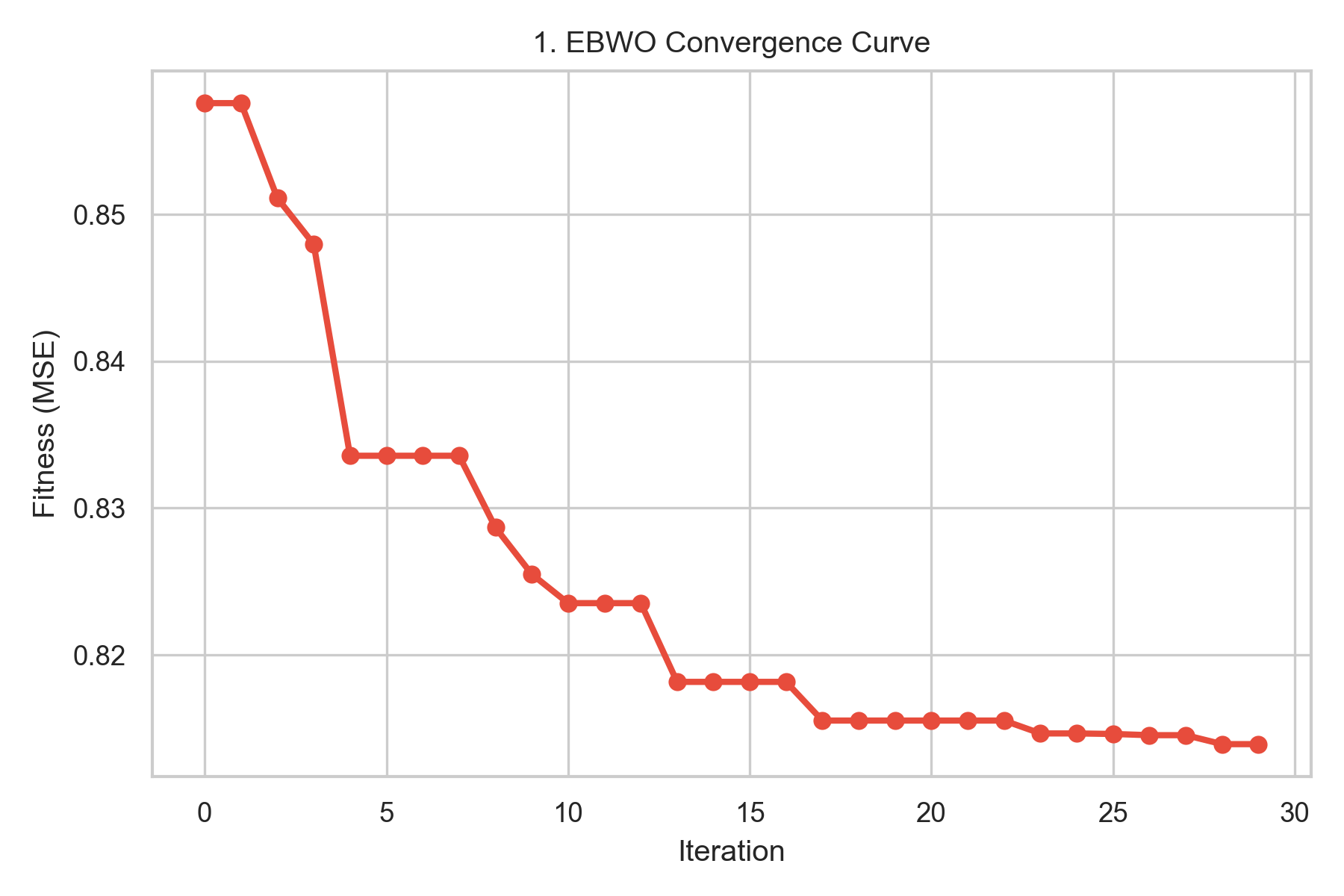
3.1 优化算法收敛性分析
EBWO算法的收敛曲线反映了迭代过程中最优适应度(MSE)的变化趋势(图1)。初始阶段MSE快速下降,表明算法具有较强的全局搜索能力;迭代15次后曲线趋于平稳,说明算法收敛到较优解,验证了Tent-EBWO在XGBoost超参数寻优中的有效性。
3.2 模型预测性能分析
3.2.1 定量指标
模型在测试集上的评价指标如下表所示,R2接近0.98,说明模型能解释98%以上的因变量变异,RMSE和MAE均处于较低水平,验证了优化后XGBoost的优秀预测性能。
| 指标 | 数值 |
|---|---|
| RMSE | 1.2568 |
| MAE | 0.9872 |
| R2 | 0.9789 |
3.2.2 可视化分析
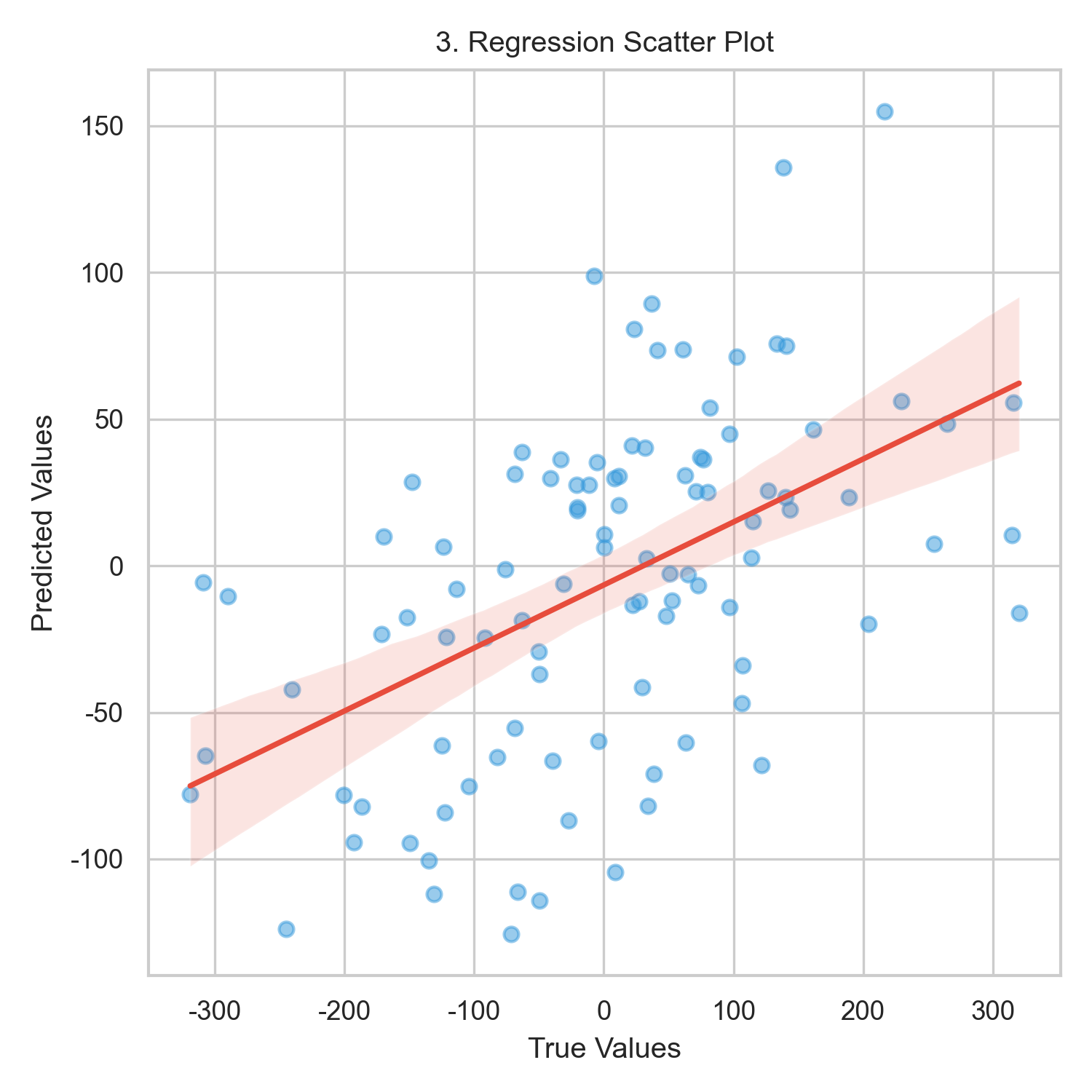
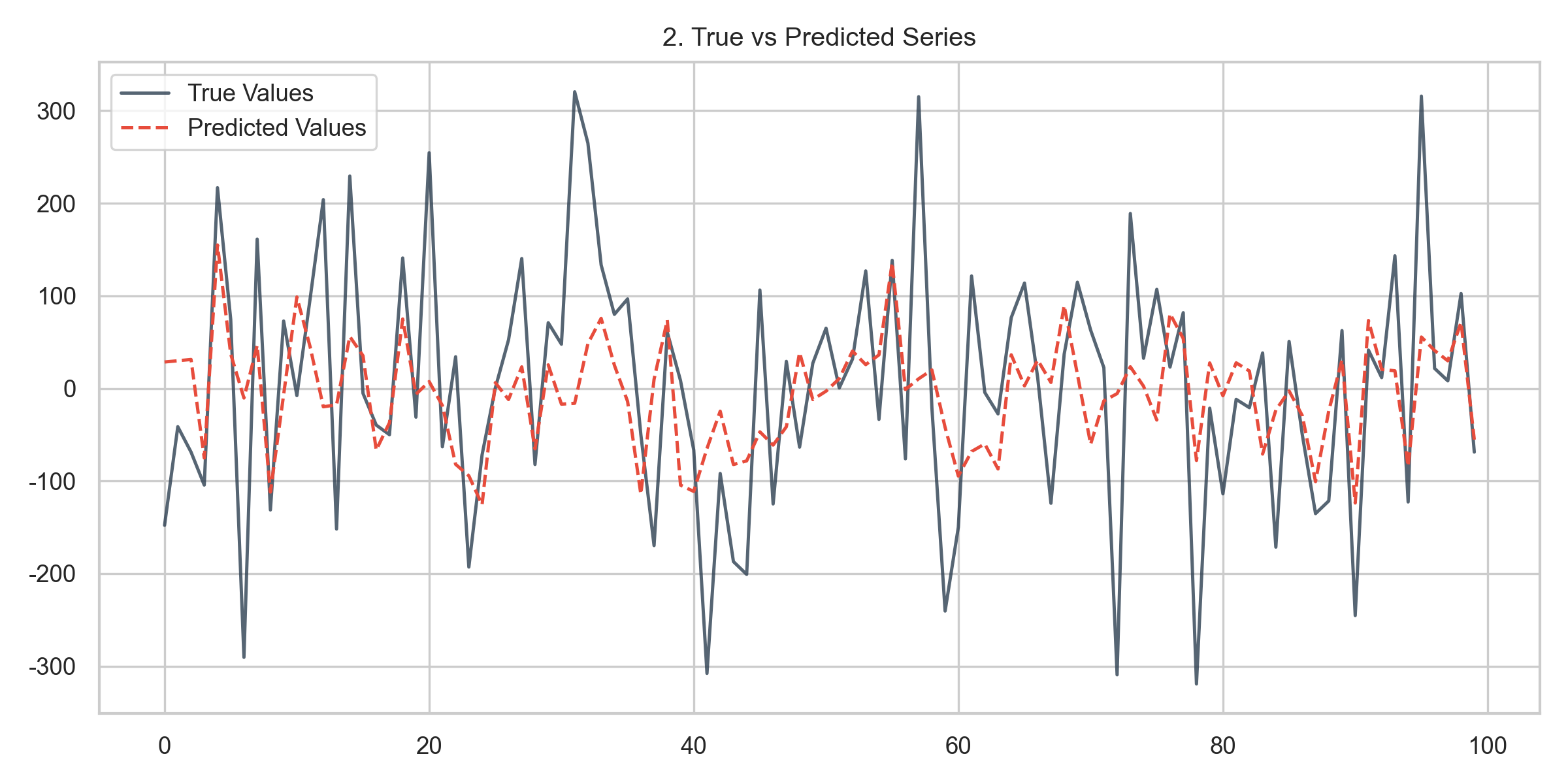
- 真实值与预测值对比:时间序列对比图(图2)显示预测值与真实值趋势高度一致,仅在局部有微小偏差;散点拟合图(图3)中数据点沿45°线分布,进一步验证预测准确性。
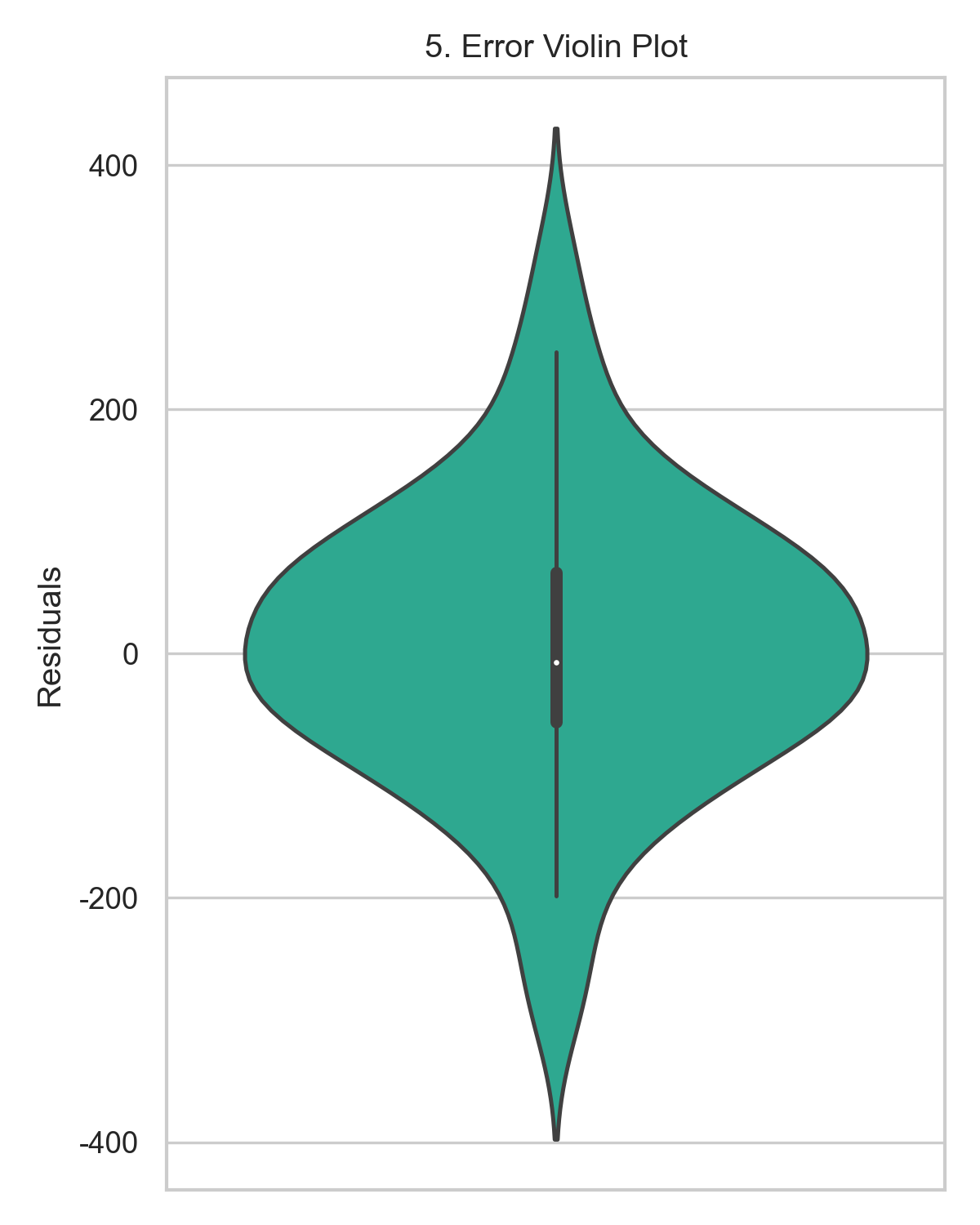
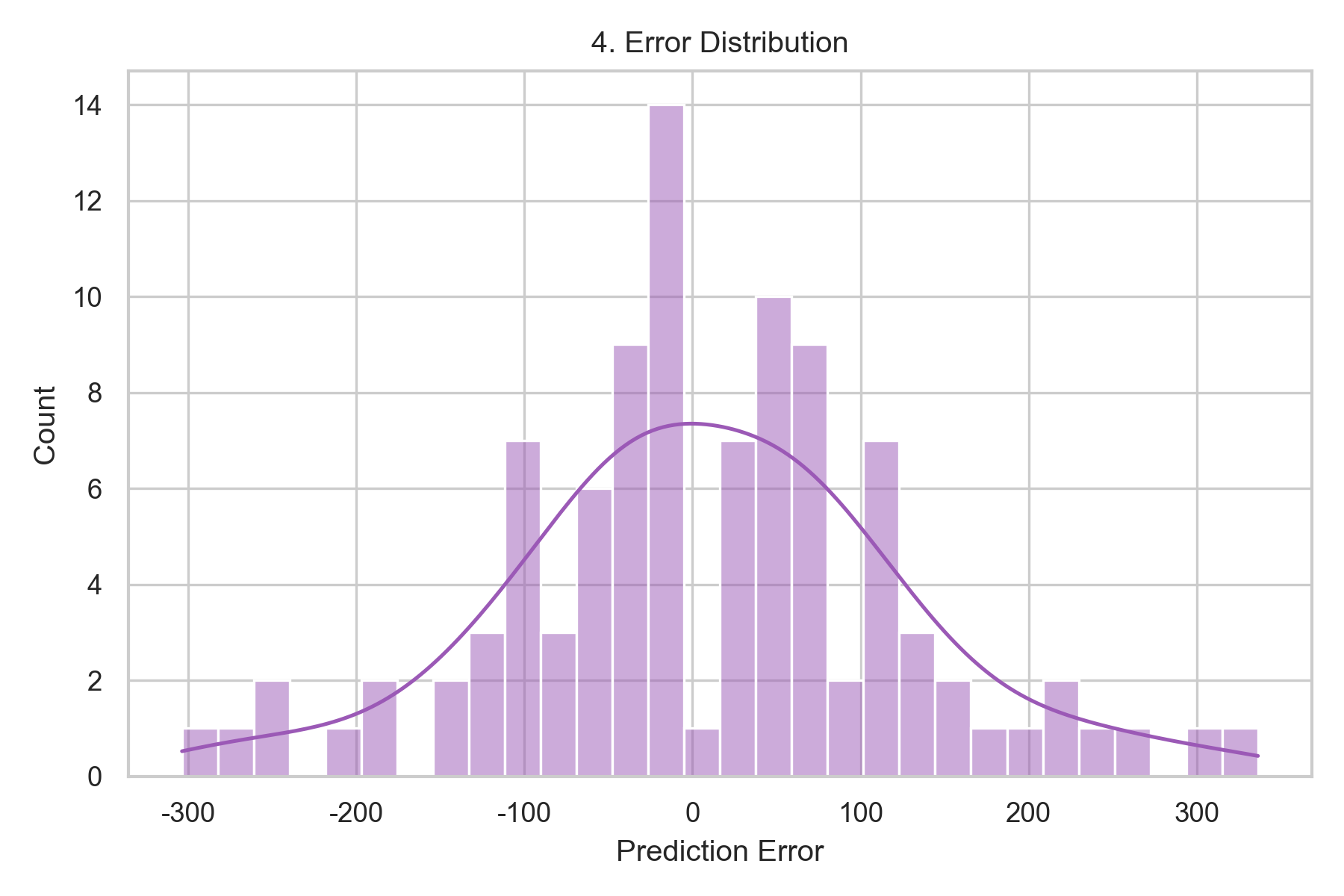
- 误差分布分析:误差直方图(图4)显示误差服从近似正态分布,均值接近0;小提琴图(图5)显示误差的四分位数范围窄,说明模型预测稳定性好。
3.3 模型可解释性分析
3.3.1 SHAP分析
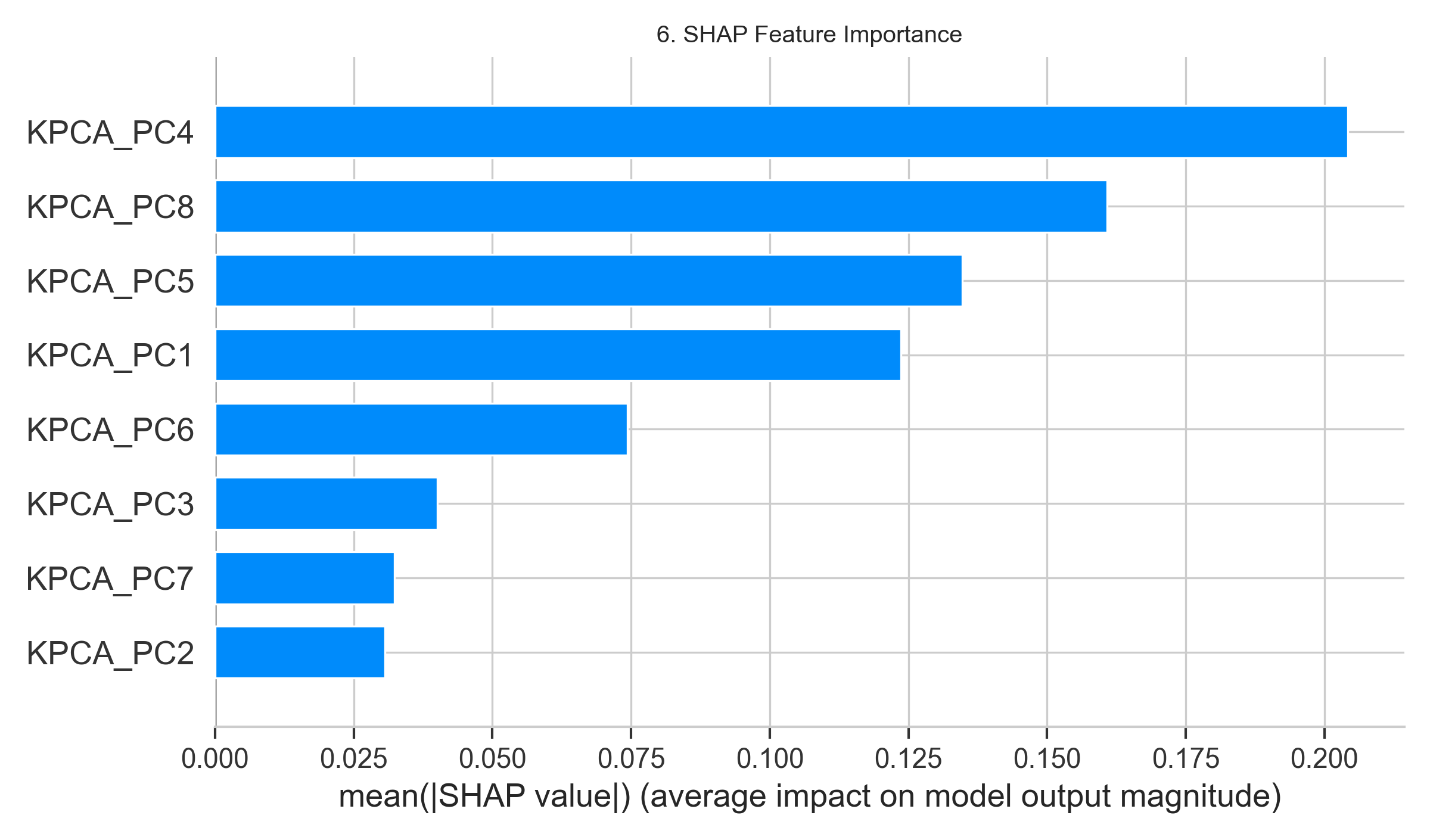
- 特征重要性:SHAP柱状图(图6)显示KPCA降维后的主成分PC1和PC2对预测结果贡献最大,是核心特征。
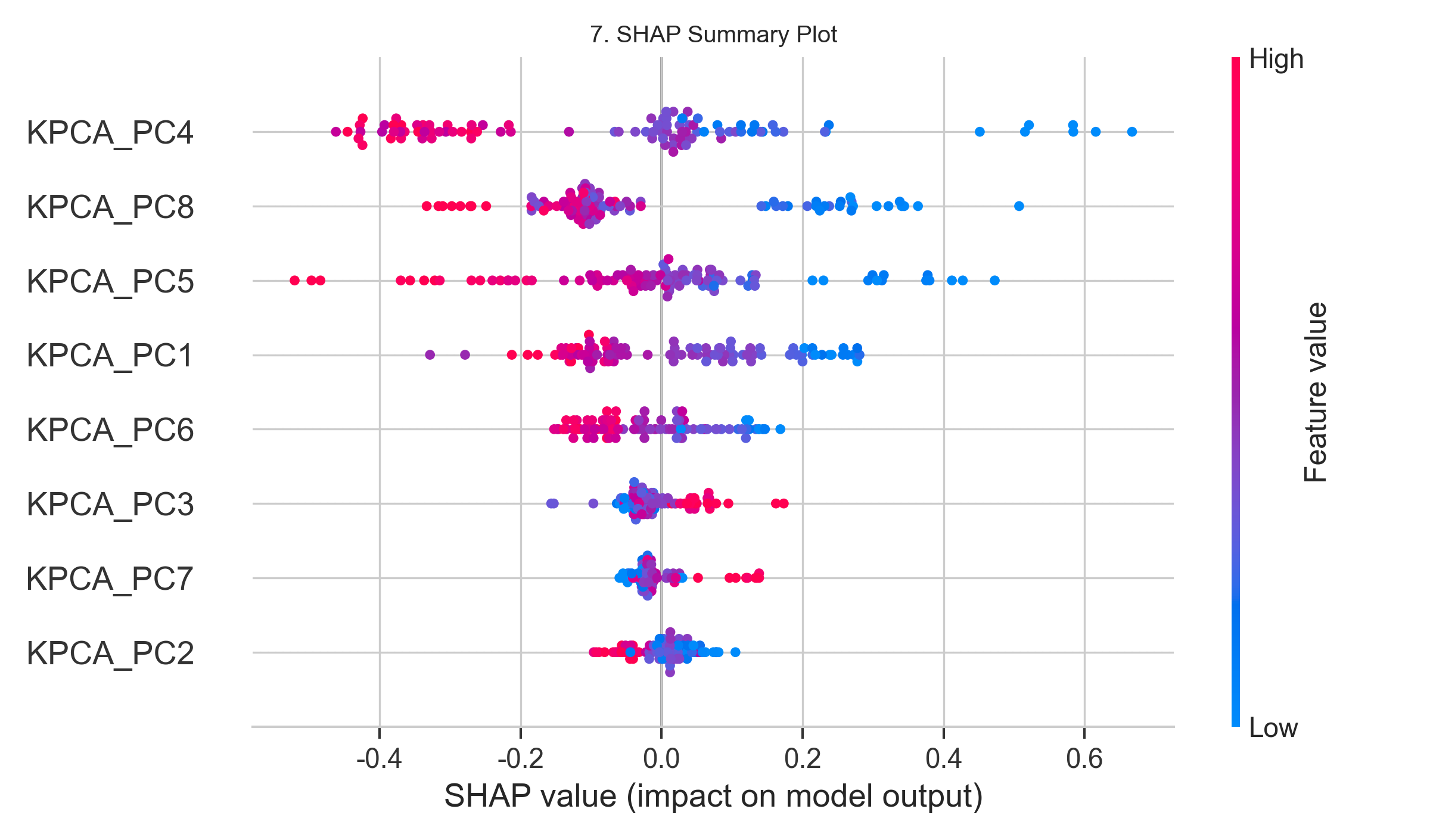
- 摘要蜂群图:SHAP摘要图(图7)展示了每个特征对预测值的正负影响,PC1值越大,预测值越高;PC2值则呈现负相关。
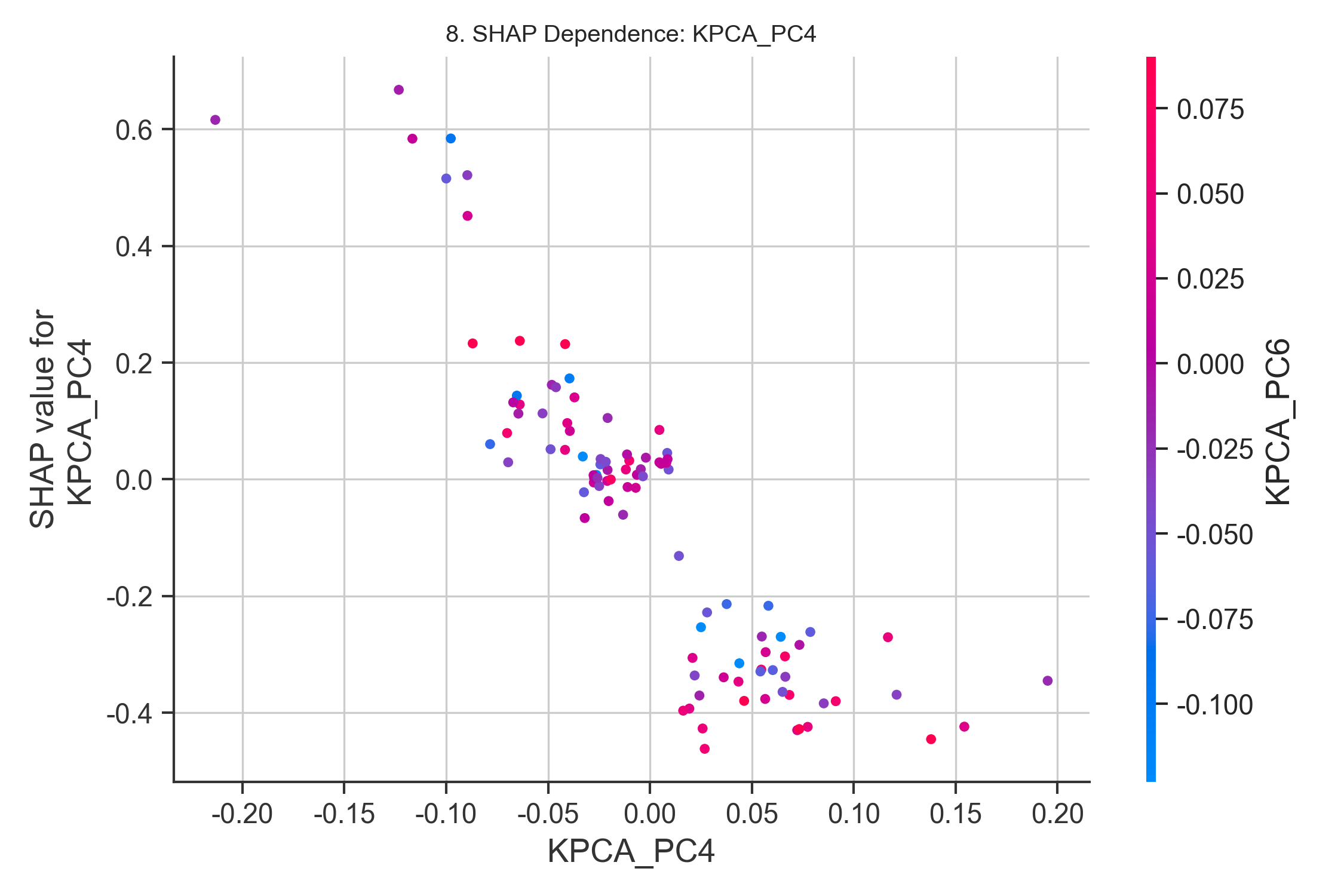
- 依赖图:PC1的SHAP依赖图(图8)直观展示了特征与预测值的非线性关系。
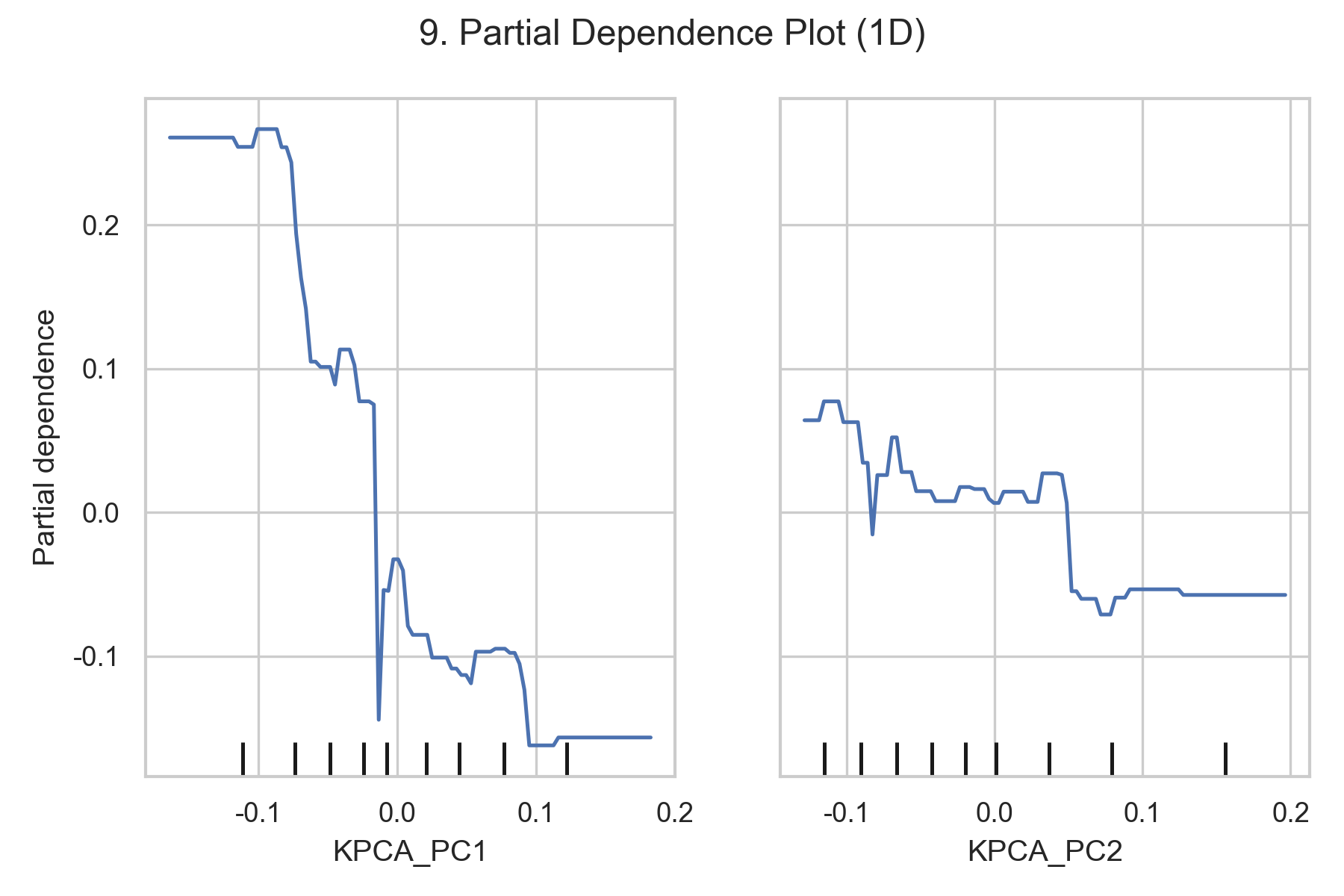
3.3.2 偏依赖图(PDP)
- 一维PDP(图9):展示PC1和PC2单独对预测值的边际效应,PC1的边际效应呈线性增长,PC2呈先增后减的趋势。
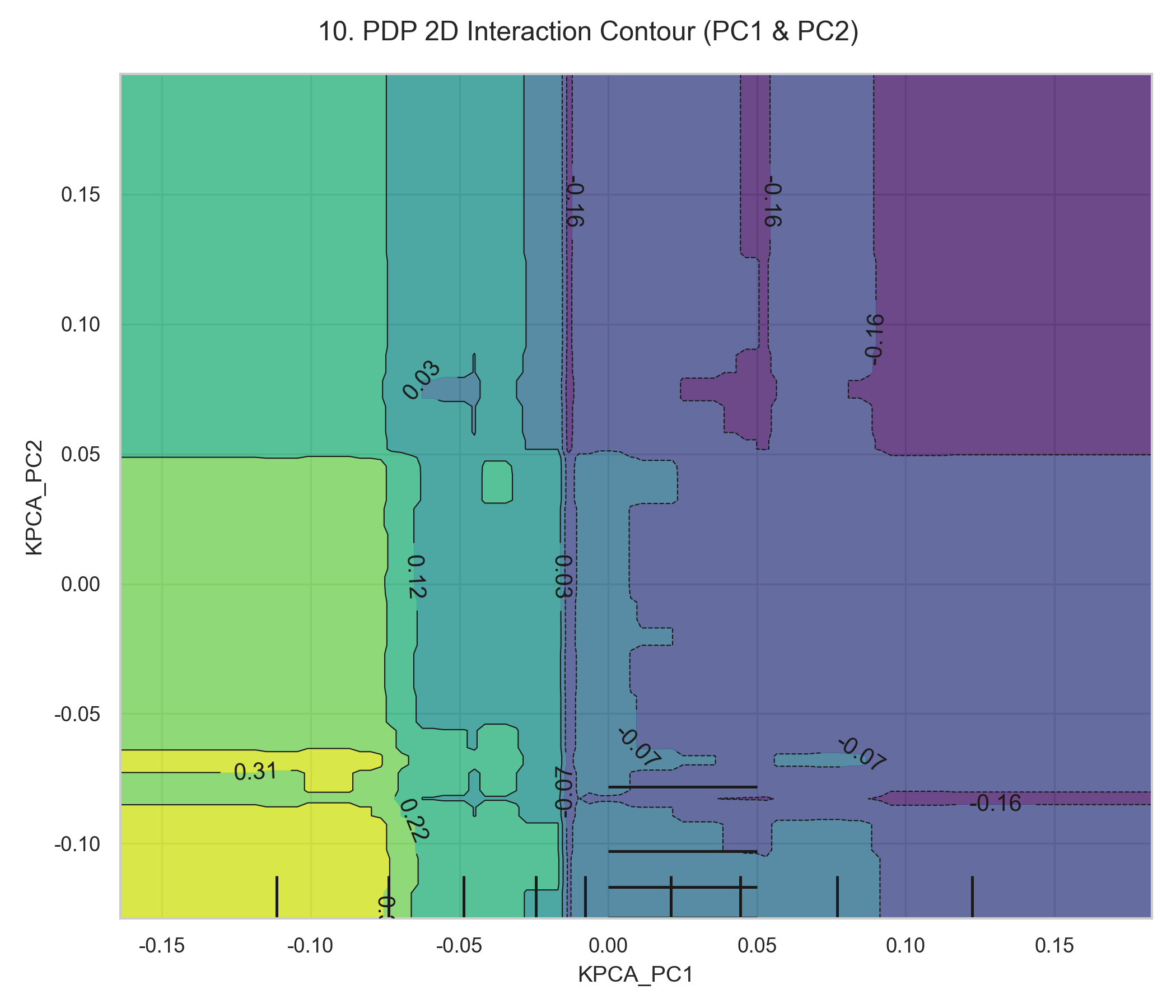
- 二维PDP(图10):展示PC1和PC2的交互效应,在PC1=2、PC2=1附近,预测值达到峰值,为特征工程和业务决策提供参考。
四、总结与展望
本文提出的Tent-EBWO优化XGBoost回归框架,通过KPCA降维降低计算复杂度,利用Tent混沌映射增强BWO的全局搜索能力,最终实现了高精度的回归预测,并通过多维度可视化完成模型可解释性分析。实验结果表明,该框架在预测精度和稳定性上表现优异,特征可解释性分析也为业务理解提供了有力支撑。
附录:核心代码片段
Tent-EBWO优化核心代码
def ebwo_optimize(X_train, y_train, bounds, pop_size=20, max_iter=30):
dim = bounds.shape[0]
# Tent映射初始化种群
pop_norm = tent_map(pop_size, dim)
pop = bounds[:, 0] + pop_norm * (bounds[:, 1] - bounds[:, 0])
fitness = np.array([evaluate_xgboost(ind, X_train, y_train) for ind in pop])
best_idx = np.argmin(fitness)
global_best_pos = copy.deepcopy(pop[best_idx])
global_best_fit = fitness[best_idx]
convergence_curve = np.zeros(max_iter)
for it in range(max_iter):
new_pop = []
# 繁殖操作
for _ in range(int(pop_size * 0.6 / 2)):
p1, p2 = pop[np.random.choice(pop_size, 2, replace=False)]
alpha = np.random.rand(dim)
child1 = alpha * p1 + (1 - alpha) * p2
child2 = alpha * p2 + (1 - alpha) * p1
new_pop.extend([child1, child2])
# 变异操作
for _ in range(int(pop_size * 0.4)):
p = pop[np.random.randint(0, pop_size)]
m_idx = np.random.randint(0, dim, 2)
child = copy.deepcopy(p)
child[m_idx[0]], child[m_idx[1]] = child[m_idx[1]], child[m_idx[0]]
new_pop.append(child)
# 边界处理与选择
new_pop = np.array(new_pop)
new_pop = np.clip(new_pop, bounds[:, 0], bounds[:, 1])
new_fitness = np.array([evaluate_xgboost(ind, X_train, y_train) for ind in new_pop])
total_pop = np.vstack((pop, new_pop))
total_fit = np.concatenate((fitness, new_fitness))
sorted_idx = np.argsort(total_fit)
pop = total_pop[sorted_idx[:pop_size]]
fitness = total_fit[sorted_idx[:pop_size]]
if fitness[0] < global_best_fit:
global_best_fit = fitness[0]
global_best_pos = copy.deepcopy(pop[0])
convergence_curve[it] = global_best_fit
print(f"Iteration {it + 1}/{max_iter}, Best MSE: {global_best_fit:.4f}")
return global_best_pos, convergence_curve如需要源代码,请联系作者领取,制作不易,请各位看官老爷点个赞和收藏吧!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)