[特殊字符] 即插即用黑科技:GSV-Conv 模块全面解析与实战教程
🚀 即插即用黑科技:GSV-Conv 模块全面解析与实战教程
来源声明:
本文介绍的模块与代码来源于近期的优秀开源工作 REAS-Det。
- 📄 论文地址: A Multi-Strategy Framework for Enhancing Shatian Pomelo Detection in Real-World Orchards (arXiv:2510.09948)
- 💻 官方源码: Genk641/REAS-Det (GitHub)
如果您在研究中使用了该模块,请支持并引用原作者的工作!🙌
欢迎来到本期的技术博客!今天我们要介绍的是一个非常强大的即插即用视觉模块——GSV-Conv(及其变体 GSVAdaptiveConv、GSVConvLarge)。它巧妙地结合了自适应卷积(Adaptive Convolution)与状态空间模型(Mamba / SSM),能够显著提升模型的特征提取能力。
无论你是在使用 YOLO 系列(YOLOv8、YOLOv9、,还是前沿的 RT-DETR、SAM2,都可以轻松将它作为一个“即插即用”的组件集成到你的网络架构中,带来精度上的涨点。📈
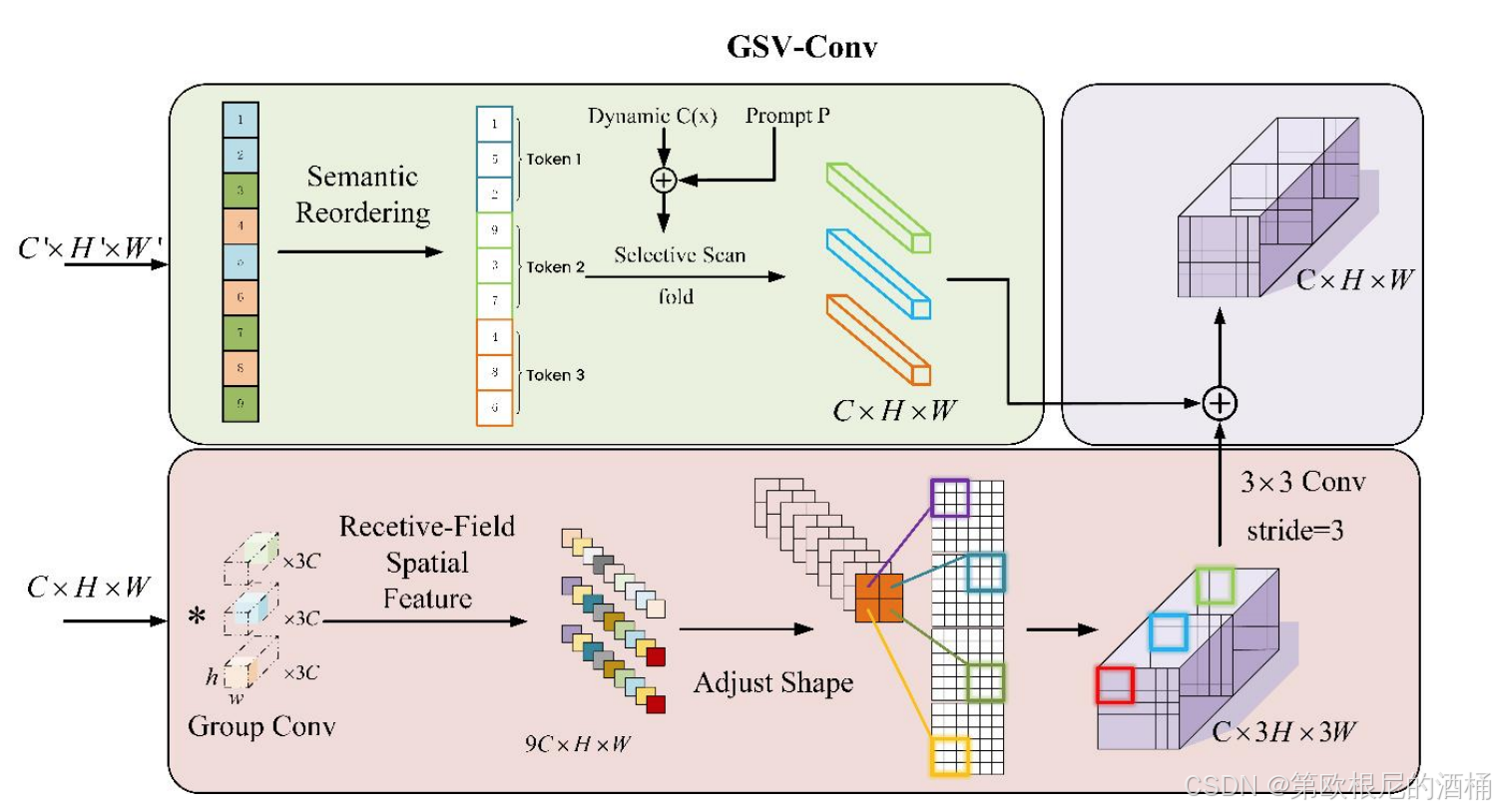
🌟 1. 什么是 GSV-Conv?
GSV-Conv 是一个混合特征提取器。它的核心工作流可以分为两步:
- 感受野自适应卷积(GSVAdaptiveConv):通过池化和卷积动态生成权重,对输入特征进行空间上的自适应加权和重排,能够更好地捕捉局部细节。
- 序列建模(GSVSequenceBlock):引入了视觉 Mamba(SSM, State Space Model)的核心算子
selective_scan_fn,对扁平化后的特征进行长依赖序列建模。
最终,通过残差连接(y + x)输出精细化后的特征。由于其标准的输入输出维度设计(in_channel -> out_channel),它可以完美替代传统的 Conv2d 或 Conv 模块。
🛠️ 2. 环境依赖准备
由于 GSV-Conv 依赖了 Mamba 的底层算子来实现高效的长序列建模,在开始之前,你需要确保安装了 mamba-ssm:
pip install torch torchvision
pip install mamba-ssm
(注意:编译 mamba-ssm 可能需要配置好 CUDA 环境以及 nvcc)
💻 3. 核心代码概览
我们可以将 GSVConv 的代码保存在 ultralytics/nn/extra_modules/GSVConv.py 中。它的核心结构非常清晰:
import torch.nn as nn
from mamba_ssm.ops.selective_scan_interface import selective_scan_fn
# ... 其他依赖 ...
class GSVConv(nn.Module):
"""
混合特征提取器:自适应卷积 + 序列建模 + 残差细化
"""
def __init__(self, in_channel, out_channel, kernel_size, stride=1, d_state=16, num_tokens=64, inner_rank=128, mlp_ratio=2.0):
super().__init__()
if selective_scan_fn is None:
raise ImportError("请先安装 mamba-ssm")
# 1. 自适应卷积
self.adaptive_conv = GSVAdaptiveConv(in_channel, out_channel, kernel_size, stride=stride)
self.norm = nn.BatchNorm2d(out_channel)
self.act = nn.SiLU()
# 2. 序列建模 (Mamba)
self.sequence_block = GSVSequenceBlock(
dim=out_channel, d_state=d_state, num_tokens=num_tokens, inner_rank=inner_rank, mlp_ratio=mlp_ratio
)
def forward(self, x):
x = self.adaptive_conv(x)
x = self.act(self.norm(x))
y = self.sequence_block(x)
return y + x # 残差输出
🧩 4. 如何在 YOLO 系列与 RT-DETR 中插入 GSV-Conv?
Ultralytics 框架(支持 YOLOv8~v12 及 RT-DETR)具有极高的可扩展性。我们只需 3 步即可完成修改。
第一步:注册模块 📝
打开 ultralytics/nn/tasks.py 文件:
- 在文件顶部引入我们的模块:
from ultralytics.nn.extra_modules.GSVConv import GSVAdaptiveConv, GSVConv, GSVConvLarge - 找到
parse_model函数,在解析模块的逻辑中,将它们加入支持列表:if m in (Conv, GhostConv, GSVAdaptiveConv, GSVConv, GSVConvLarge, ...): c1, c2 = ch[f], args[0] if c2 != no: # 如果不是输出通道不等于类别数 c2 = make_divisible(c2 * gw, 8)
第二步:编写修改版的 YAML 配置文件 ⚙️
以 YOLOv8 为例(替换主干或颈部的下采样 Conv):
你可以创建一个新的 YAML 文件(例如 yolov8-GSV.yaml),将原本用作降采样(Stride=2)的普通 Conv 替换为 GSVAdaptiveConv 或 GSVConv。
# YOLOv8-GSV backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, GSVAdaptiveConv, [128, 3, 2]] # 1-P2/4 (替换为GSV)
- [-1, 3, C2f, [128, True]]
- [-1, 1, GSVAdaptiveConv, [256, 3, 2]] # 3-P3/8 (替换为GSV)
- [-1, 6, C2f, [256, True]]
# ... 继续替换其他的 Conv
对于 RT-DETR:
RT-DETR 的 Backbone 通常是 HGNetv2 或 ResNet。你可以在 Neck 部分(Hybrid Encoder)将 Conv 替换为 GSVConv 以增强跨尺度特征融合时的全局感受野:
# RT-DETR head
head:
- [-1, 1, GSVConv, [256, 1, 1]] # 替换原本的 1x1 映射卷积
- [-1, 1, AIFI, [1024, 8]]
# ...
(注:YOLOv9、v10、v11、v12 的配置文件结构类似,直接在 .yaml 的网络拓扑中替换对应的 Conv 即可。)
🎯 5. 如何在 SAM2 (Segment Anything 2) 中使用?
SAM2 主要基于 Transformer 架构,其图像编码器(Image Encoder)通常是 Hiera。要在 SAM2 中插入 GSV-Conv,思路是替换 FPN 颈部(Neck)或特征投影层的卷积块。
- 找到 SAM2 代码库中构建 FPN 特征金字塔的地方(例如
sam2/modeling/backbones/image_encoder.py里的投影层)。 - 导入模块:
from GSVConv import GSVConv - 替换原有的通道转换逻辑。例如,原本可能是:
你可以将其升级为:self.lateral_conv0 = nn.Conv2d(dim0, out_dim, kernel_size=1)self.lateral_conv0 = GSVConv(in_channel=dim0, out_channel=out_dim, kernel_size=1)
这样可以让 SAM2 在融合多尺度特征时,利用 Mamba 的线性时间复杂度捕获更加全局的序列依赖,从而提升零样本分割(Zero-shot Segmentation)的边缘精细度!
💡 总结
GSV-Conv 结合了感受野自适应卷积和**SSM(Mamba)**的强大建模能力。作为即插即用的模块:
- 轻量级改造:可以直接使用
GSVAdaptiveConv替换普通卷积。 - 重度改造:使用完整的
GSVConv或加大深度的GSVConvLarge,在牺牲极少推理时间的前提下,换取可观的 mAP 涨点。
赶快在你的模型里试用一下吧!如果你在配置过程中遇到关于 mamba-ssm 编译或者通道维度对齐的报错,欢迎在评论区留言交流!👇
(觉得有用的话,别忘了点赞和收藏哦 ⭐)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)