从边缘到语义:Transformer 层级特征演化全解析
从边缘到语义:Transformer 层级特征演化全解析
一个直觉性的问题
想象你第一次看到一幅陌生的画。你的眼睛先注意到什么?不是"这是一条狗"这种高级判断,而是线条、光影、颜色块。然后逐渐地,这些局部信息拼接成轮廓,轮廓拼接成形状,形状最终被识别为具体的对象。
深度神经网络的"思维方式"和这个过程惊人地相似。不管是 CNN(卷积神经网络)、BERT(语言模型),还是 ViT(视觉 Transformer)和 LLaVA 这类视觉-语言大模型——它们都在用层级的方式处理信息:浅层抓低级特征,深层理解高级语义。
这篇文章就是要把这个过程讲清楚:每一层在干什么,层与层之间发生了什么变化,以及这套规律是怎么在不同架构里被反复发现的。
第一章:CNN——这一切的起点(Zeiler & Fergus, 2014)
一次"打开黑盒"的尝试
在 2014 年之前,人们知道 CNN 效果好,但不知道它"在想什么"。Matthew Zeiler 和 Rob Fergus 做了一件非常直接的事:把每一层的激活值"投影"回输入图像空间,看看每层神经元最喜欢看到的是什么图像模式。[1][2]
他们用的工具叫 DeconvNet(反卷积网络)——简单说,就是把正向传播的计算反过来走,从某一层的激活出发,追溯到它在原始图像上对应的是什么区域、什么结构。[^3]
五层,五个世界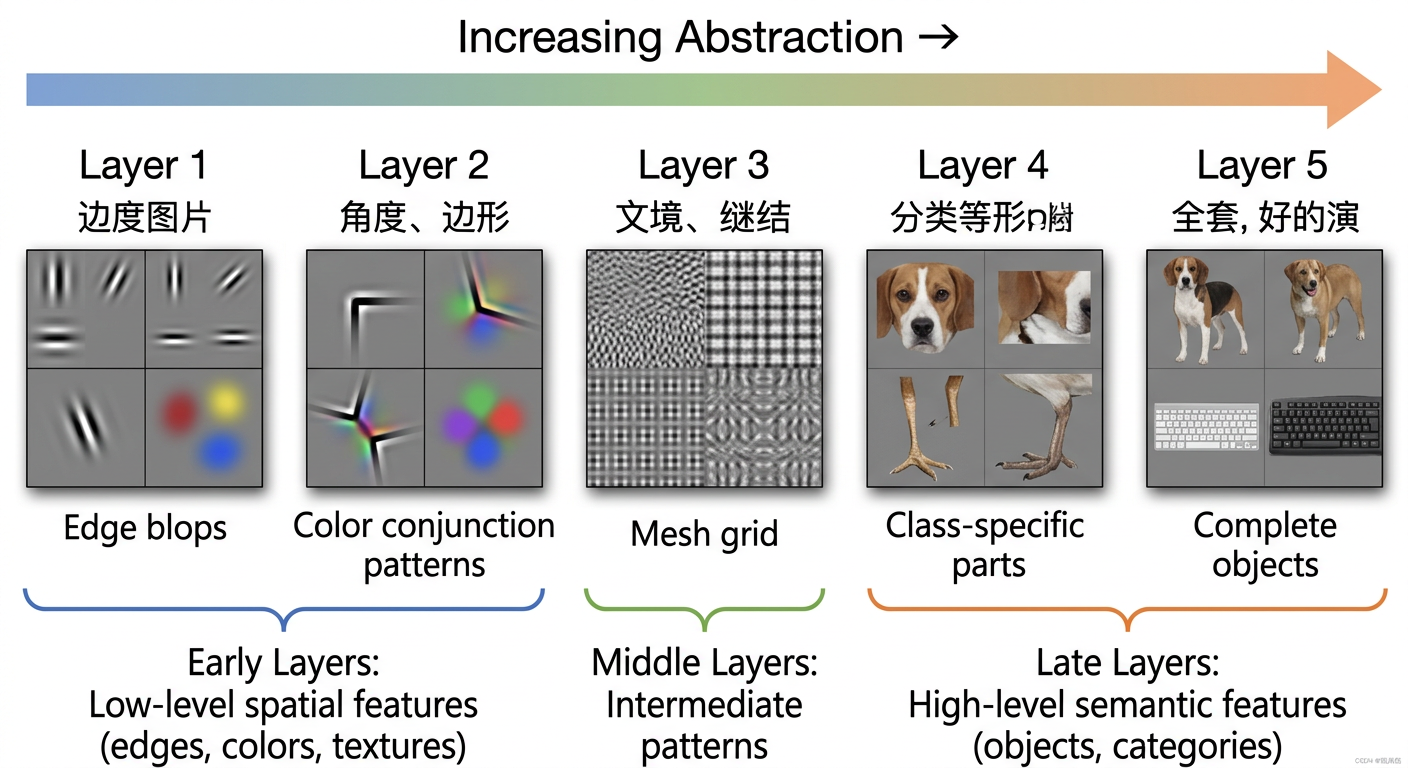
结果令人震惊地清晰:[1][2]
第 1 层(最浅层):神经元响应的是最简单的东西——颜色斑块、定向边缘(45°的线、水平的线、垂直的线)。这层完全不知道什么是"狗",它只知道"这里有一条向右倾斜的深色边缘"。
第 2 层:开始对"角点"和"颜色交汇处"有反应。就好像第 1 层认识了字母,第 2 层开始认识两个字母拼成的组合——是更复杂的局部结构,但依然是抽象的图案,没有任何语义。[1][2]
第 3 层:捕捉纹理。比如"网格状图案"、“文字的排列规律”、“重复的格子”。这一层开始有"感觉"了——虽然还不知道具体是什么,但能感知到规律性的视觉结构。[^2]
第 4 层:出现了类别专属的特征。狗脸、鸟腿、车轮——这些激活图里开始有了可辨识的视觉部位。还不是整体,但已经是有意义的局部。[^1]
第 5 层(最深层):整个对象出现了,还带着各种姿态变化。一只键盘从不同角度拍、一条狗站着趴着跑着,这一层都能识别出来。[^1]
为什么会这样?
直觉上很好理解:神经网络是逐层"堆积"感受野的。第 1 层只看一个 7×7 的小窗口;第 2 层的神经元的感受野覆盖了若干个第 1 层的窗口;越往后,每个神经元"看到"的原始像素区域越大,能整合的信息越多,自然就能识别越复杂的结构。[4][5]
这个发现确立了一个影响深远的框架:低层 = 低级特征(边缘、纹理),高层 = 高级语义(对象、类别)。[^6]
第二章:BERT——语言世界里的同一个故事(2019)
CNN 的层级发现是在图像领域。几年后,当研究者开始"解剖" BERT 这类语言模型时,他们发现了一个惊人的镜像结构。
Probing:给每一层"出考题"
研究者们的方法叫做 Probing(探针实验)。具体做法很简单:从 BERT 的某一层提取出句子的向量表示,然后训练一个小的线性分类器,测试这个向量能不能完成某个特定的语言任务——比如词性标注、句法分析、语义角色标注。如果能,说明这一层"懂"这个语言现象;如果不能,说明这层还没学到这个知识。[7][8]
BERT 重现了 NLP 流水线(Tenney et al., ACL 2019)
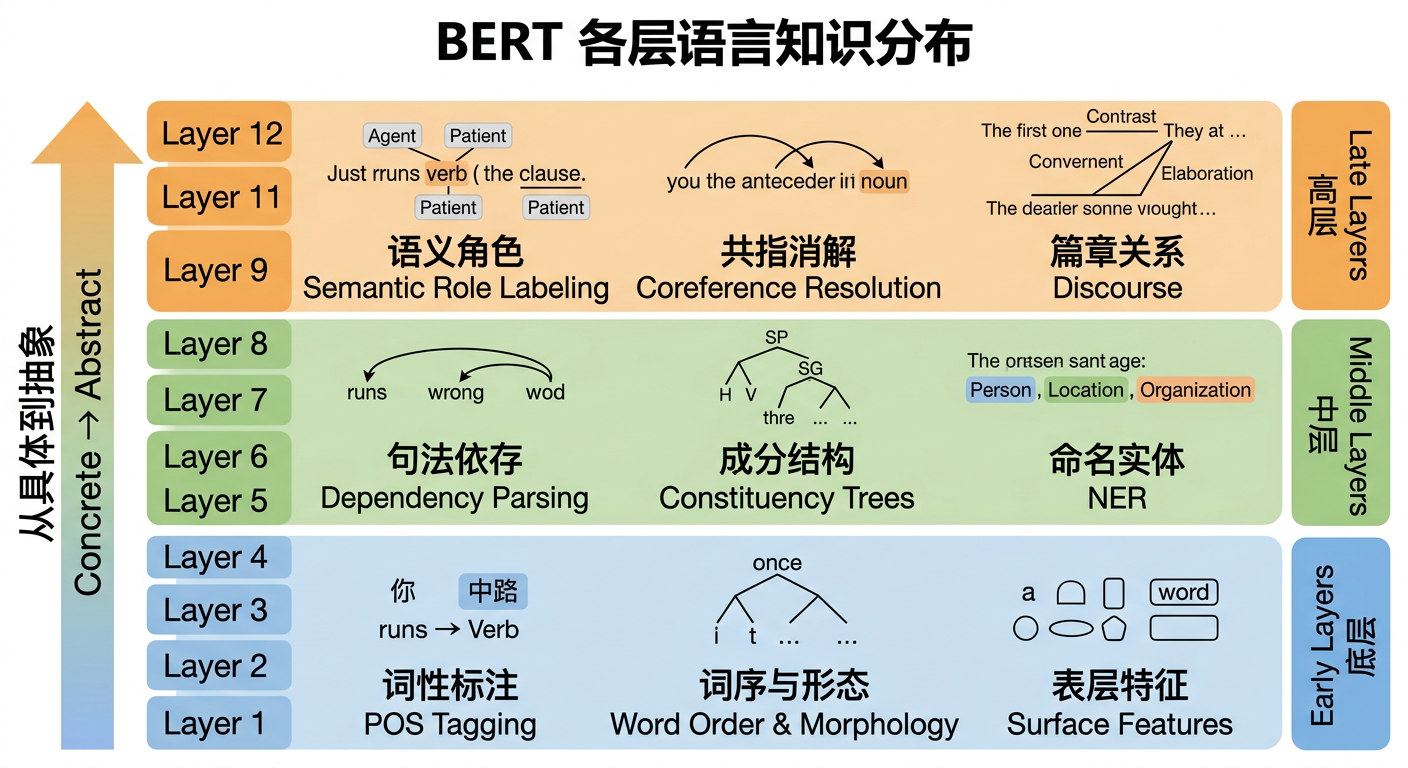
Ian Tenney 等人用这个方法分析了 BERT 的每一层在 8 个语言任务上的表现。结论是:BERT 从底层到高层,自动学出了人类 NLP 工程师花了几十年才设计出来的处理流程。[9][10][^11]
具体顺序是:
-
底层(1–4 层):词性标注(这个词是名词还是动词?)、词序规律、词汇形态。这相当于 CNN 里识别边缘——是最"表面"的语言特征。[7][9]
-
中层(5–8 层):句法结构开始出现。依存关系(“主语是谁,谓语是什么”)、成分结构树(句子的层次分组)在这些层里被编码得最好。研究发现,BERT-base 的 6–9 层在重建句法依存树时准确率最高。[12][13][^7]
-
高层(9–12 层):语义信息登场。语义角色(“谁对谁做了什么”)、共指消解(“这个’他’指的是前面哪个人”)在这些层里处理得最准。[14][7]
Jawahar et al. 的补充(ACL 2019)
同年,Ganesh Jawahar 等人更直接地总结道:[15][16]
“BERT 的中间层编码了丰富的语言信息层次:底层是表层特征,中层是句法特征,顶层是语义特征。”
他们还观察到一个有趣的细节:短语级别的信息在低层最容易被检测到,随着层数增加,这种细粒度的局部信息逐渐被更抽象的整体信息替代。[^16]
GPT-2 和现代大语言模型的验证
这套规律不只存在于 BERT。2026 年的一项研究对 BERT、GPT-2、DeBERTa、Llama 等多种模型进行了系统性分析,得出一致结论:[^14]
“现代语言模型一致地重发现了经典 NLP 流水线:早层处理表层和句法信息,中层侧重语义和实体信息,晚层捕捉篇章级别的特征。”[^14]
GPT-2 还表现出一个有趣的信息瓶颈现象:在第 2→3 层和第 8→9 层之间,互信息出现急剧下降,这对应了注意力跨度的突变,标志着计算模式的相位转变。[^7]
第三章:ViT——视觉 Transformer 的"异同"(Raghu et al., NeurIPS 2021)
一个关键问题
2020 年,Google 提出了 ViT(Vision Transformer)——把图像切成 16×16 的 patch,用 Transformer 而非卷积来处理视觉信息。大家自然要问:它还会有层级特征吗?它跟 CNN 的处理方式一样吗?
Maithra Raghu 等人在 2021 年用 **CKA(中心核对齐,Centered Kernel Alignment)**这个工具,对 ViT 和 ResNet 进行了系统的层间相似度分析。[17][18]
CKA 是什么?
可以把 CKA 理解成一种"相似度温度计":对网络中任意两层提取的特征向量,计算它们表示同一批图像的方式有多相似。相似度高 = 这两层在"做同一件事";相似度低 = 这两层处理方式截然不同。[^19]
最关键的发现:ViT 和 CNN 的根本差异
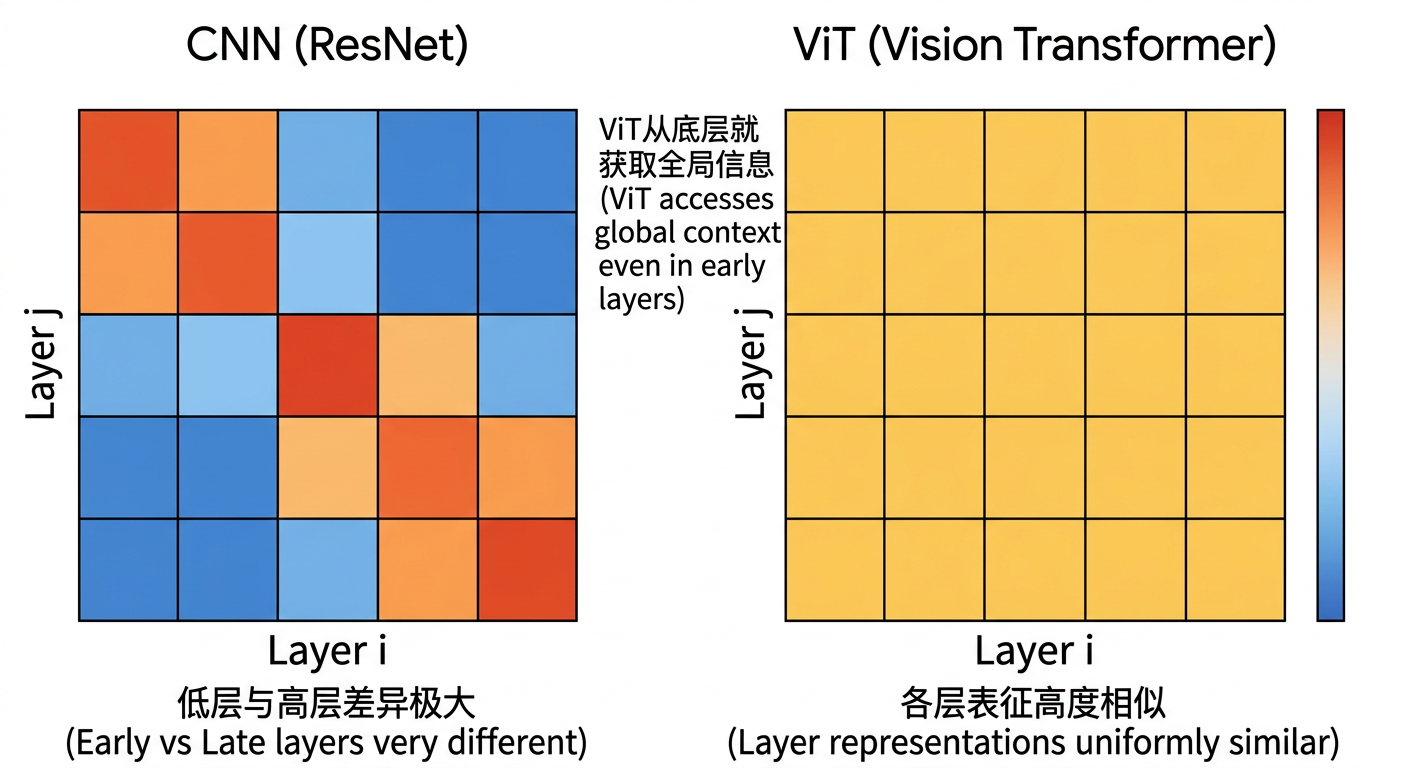
CNN(ResNet)的 CKA 热力图:呈现出明显的"块状"结构——浅层之间相互相似,深层之间相互相似,但浅层和深层之间几乎没有相似性。这反映了 CNN 的本质:感受野是从小到大逐层扩展的,早期层和晚期层在做完全不同的事情。[20][18]
ViT 的 CKA 热力图:整个矩阵都是高相似度——无论比较第 2 层和第 20 层,还是第 10 层和第 30 层,相似度都很高。这说明 ViT 各层的表征方式非常均匀,层间分化远不如 CNN 明显。[21][22][^20]
这是为什么?因为 ViT 的 Self-Attention 机制从第 1 层就允许每个 patch 直接"看到"图像中的所有其他 patch。CNN 的第 1 层只能看到 7×7 的邻域,ViT 的第 1 层已经在处理全局信息了。[23][24]
ViT 的独特性:空间信息的高层保留
Raghu et al. 还发现了 ViT 一个特别重要的特性:ViT 的 token 在深层依然保留了与输入 patch 的空间对应关系。[20][18]
具体实验是:比较最终层的每个 token 与输入图像上对应位置 patch 的 CKA 相似度。ViT 表现出清晰的对角线结构——第 i 个位置的 token,在经过 30 多层变换之后,仍然主要编码第 i 个位置的图像信息。而 ResNet 的对应矩阵则高度混乱,说明 CNN 在深层已经把空间位置信息大量混合掉了。[25][20]
这个发现解释了为什么 ViT 在密集预测任务(分割、检测)上有优势——它在深层仍然保有精确的空间定位能力。
浅层"全局",不等于浅层"什么都懂"
一个常见的误解是:既然 ViT 浅层就能访问全局信息,那它是不是浅层就"很厉害"了?
并不完全是。研究发现,ViT 的深层表征仍然比浅层更复杂、对识别任务更关键。浅层的"全局视野"更像是一种原材料收集——把全局上下文都纳入考虑;真正的语义提炼、类别判断,还是在深层完成的。Raghu et al. 观察到 CLS token 存在一个相位转变:从浅层主导到中-深层的 patch token 主导,标志着从全局感知到语义聚焦的切换。[21][24][^22]
另外,一个特别有意思的发现是:在数据量不足时,ViT 的浅层无法学到有效的局部特征,整个模型的性能会大幅下降。这说明浅层的局部特征(类似 CNN 低层的边缘纹理)虽然看起来"低级",却是高层语义理解的必要基础。[^20]
第四章:VLM——多模态世界的新复杂性(2024–2026)
问题变得更难了
当图像和语言被放进同一个模型,"层级特征"的故事变得更复杂,但同样更有趣。问题变成了:在一个处理图像+文字的模型里,视觉信息和语言信息分别在哪些层被处理?它们什么时候、在哪里"相遇"并融合?
三阶段处理框架(LLaVA 实验证据)
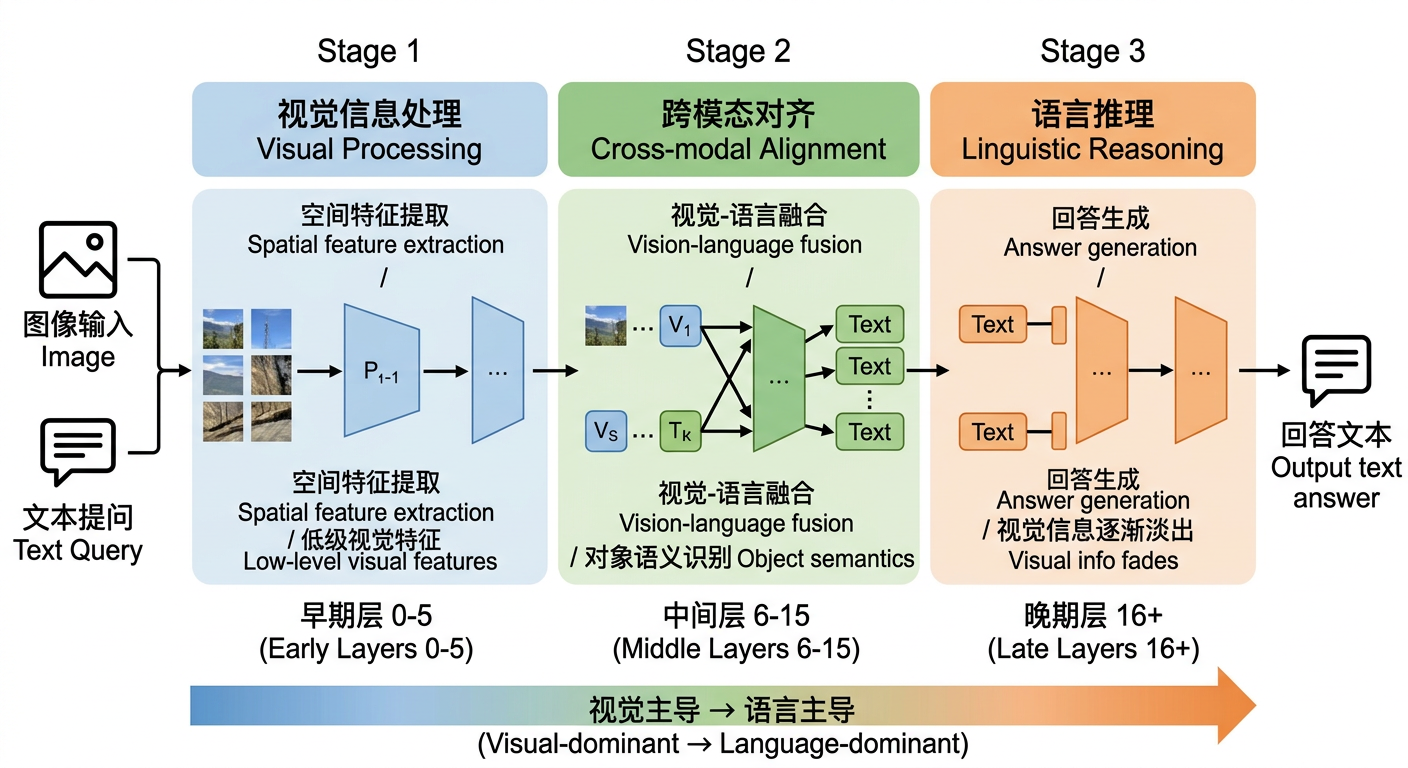
多项研究对 LLaVA、InstructBLIP 等 VLM 进行了分析,呈现出非常一致的三阶段模式:[26][27]
第一阶段——早层(Layer 0–5):视觉信息的独立处理
在模型的最浅层,视觉 token 和文字 token 几乎是"各过各的"——视觉 token 在提取空间特征和低级视觉模式,文字 token 在处理任务识别。研究发现,这些层里视觉 token 在跨模态信息传递方面大量冗余,即使剪掉很多视觉 token 对这阶段的输出影响也不大。[28][27]
第二阶段——中层(Layer 6–15):跨模态对齐与融合
这是整个 VLM 最关键的阶段。视觉 token 开始把信息"注入"文字 token 的表示空间,对象级别的语义信息(“这张图里有一只猫”)在这个阶段被整合进去。研究表明,视觉信息在中层被最充分地表征——VaLR 等框架的实验专门测试了在前(第4层)、中(第12层)、后(第27层)三个位置进行视觉对齐的效果,中层表现最好。[29][30][^31]
第三阶段——深层(Layer 16+):语言主导的推理
进入模型的深层,视觉 token 的影响力急剧衰减。模型逐渐转向纯语言推理,根据已经融合的视觉-语言表示生成答案。一项使用偏信息分解(PID)工具的分析在 LLaVA-1.5 上得出了精确的量化结论:[26][28]
“视觉独特信息在早层达到峰值,随深度单调衰减;语言独特信息在晚层激增,主导最终预测。”
跨模态"相遇"发生在哪里?
一项使用稀疏自编码器(SAE)作为探针的研究(2025)精确定位了视觉-语言表征的收敛点:在 26 层的模型里,视觉输入的特征要到第 18 层附近才真正与语言特征对齐。[^32]
这个发现有重要的实践意义:即使视觉编码器已经把图像转换成了和语言 token 形状相同的向量,前面十几层的 LLM 对这些视觉信息依然是"陌生"的——它需要花相当多的层来"消化"这些不熟悉的输入,才能把它真正纳入语言处理的框架里。[^32]
ViT 的哪一层应该连接 LLM?
这引出了一个很实际的工程问题:VLM 的视觉编码器(一般是 ViT)应该把哪一层的特征送给语言模型?
常见做法是取最后一层。但 TGIF 等研究发现这并不总是最优的:[^33]
- 对于需要精细局部特征的任务(OCR、文字识别),浅中层 ViT 特征更有用——因为深层 ViT 已经把局部细节大量抽象掉了
- 对于需要整体语义理解的任务(图像问答),深层特征更合适
这说明 ViT 的层级结构和 VLM 的任务需求之间存在一个复杂的匹配关系——不同任务需要 ViT 不同深度的"视角"。[24][33]
第五章:这些结论有多可靠?争议与修正
说了这么多一致的结论,也需要诚实地讲一讲:这套框架并不是铁板钉钉的真理,它有被质疑的地方。
"三分法"未必有清晰边界
COLING 2022 的一项重新分析对 Tenney et al. 的结论进行了直接挑战:他们用更严格的统计方法重新检验,发现句法任务和语义任务的层位分布很难区分——并不是"句法=中层,语义=高层"那么泾渭分明。更准确的描述可能是:表层任务偏向底层,但句法和语义任务的信息几乎平行地分布在 BERT 的各层。[^34]
不同架构,不同层位
Rogers et al. 的综述指出,ELECTRA 和 XLNet 等模型虽然总体符合层级规律,但具体的最佳层位不同。这说明层级结构不只由"任务本身的复杂度"决定,也受预训练目标、架构设计的深刻影响。[^13]
ViT 的"均匀性"质疑"三分法"的强度
Raghu et al. 的 CKA 分析本身证明,ViT 的层间分化远比 CNN 弱。这意味着"早层低级、晚层高级"在 ViT 上的表现是一个连续光滑的渐变,而非像 CNN 那样有清晰的阶段边界。用"三分法"来描述 ViT,更多是一种粗粒度的简化,而非精确的刻画。[19][18]
VLM 中的"非对称依赖"打破了简单对应
VLM 的研究还揭示了一个非直觉的现象:浅层的 LLM 有时需要去访问深层 ViT 的语义信息;而深层的 LLM 有时又需要回头提取浅层 ViT 的细粒度空间信息。这种跨层级的"非对称依赖"打破了"低层对低层、高层对高层"的简单对应关系。[^35]
整合视角:为什么是这个规律?
把上面四章的内容放在一起,可以总结出一个统一的理解:
信息处理的"层级性"不是被人为设计出来的,而是神经网络在优化过程中自发涌现的。
原因在于:无论是图像中的对象识别,还是语言中的语义理解,都天然具有层级组合性——边缘组成纹理,纹理组成形状,形状组成对象;词组成短语,短语组成句子,句子组成篇章。能学到这种层级结构的网络,表达能力更强,泛化更好——所以梯度下降自然地把网络推向这个方向。
这也解释了为什么不同架构(CNN、BERT、ViT、LLaVA)会出现如此相似的规律:它们面对的问题有相同的内在结构。架构的不同只是影响了层级出现的具体位置和边界清晰程度,而不改变这个基本规律的存在。
| 维度 | CNN (ResNet) | BERT | ViT | VLM (LLaVA) |
|---|---|---|---|---|
| 早层 | 边缘、颜色斑点[^1] | 词性、词序[^16] | 局部纹理 + 部分全局[^23] | 视觉特征提取[^27] |
| 中层 | 纹理、局部图案[^2] | 句法结构、依存关系[^9] | 特征精炼(均匀演变)[^22] | 视觉-语言跨模态融合[^31] |
| 晚层 | 对象部位、整体对象[^1] | 语义角色、共指消解[^14] | 语义概念 + 空间位置保留[^18] | 语言主导推理、答案生成[^26] |
| 层间分化强度 | 极强,早晚层差异巨大 | 较强,有清晰转换点 | 弱,表征均匀渐变 | 中等,三阶段相对清晰 |
| 是否保留空间信息到深层 | 否(分辨率不断下降) | N/A | 是(位置对应关系保留)[^20] | 部分(视觉信息在深层衰减)[^28] |
结语:一个框架,不是一条定律
“早层空间低级,晚层语义高级”——这套三分法已经在四种不同架构、两种不同模态上被反复验证。它是目前对神经网络内部信息处理规律最有力的描述框架之一。
但它是一个框架,不是定律。真实情况更复杂:层的边界是模糊的,任务会影响最优层位,架构差异会改变分化强度,跨模态的交互引入了新的维度。每一篇试图精确化或挑战这个框架的论文,都让我们对神经网络的理解更深了一层。
这本身,也是一种层级——从粗糙的直觉,到精确的科学理解。
References
-
[PDF] LNCS 8689 - Visualizing and Understanding Convolutional Networks - We introduce a novel visualization technique that gives insight into the function of intermediate fe…
-
[PDF] Visualizing and Understanding Convolutional Networks - In this paper we introduce a visualization technique that reveals the in- put stimuli that excite in…
-
How convolutional neural networks see the world - ar5iv - Adapted from “Visualizing and Understanding Convolutional Networks,” by M.D. Zeiler, 2014. … Vince…
-
[PDF] Deliberative Explanations: visualizing network insecurities - NIPS - This has shown that early layers tend to capture low-level features, such as edges or texture, while…
-
[PDF] A Guide - arXiv - The CNNs learn mean- ingful feature spaces with rich information from low-level features to high-lev…
-
27 Learned Features – Interpretable Machine Learning - Deep neural networks learn high-level features in the hidden layers. This is one of their greatest s…
-
A Hierarchical Framework for Interpreting Large Language Models - demonstrated that BERT layers encode progressively more abstract information, from surface features …
-
Probing Classifiers: Decoding What Language Models Learn - This layer analysis typically shows that syntactic information peaks in the middle layers of BERT (l…
-
[PDF] BERT Rediscovers the Classical NLP Pipeline - Ian Tenney - BERT by Layer … - Linguistic abstractions appear in a consistent order, with POS tagging in lower …
-
[1905.05950] BERT Rediscovers the Classical NLP Pipeline - Our experiments are based on the “edge probing” approach of Tenney et al. … layers of the BERT net…
-
BERT Rediscovers the Classical NLP Pipeline - ACL Anthology - We find that the model represents the steps of the traditional NLP pipeline in an interpretable and …
-
[PDF] What’s so special about BERT’s layers? A closer look at the NLP … - Peeking into the inner workings of BERT has shown that its layers resemble the classical. NLP pipeli…
-
A Primer in BERTology: What We Know About How BERT Works - This paper is the first survey of over 150 studies of the popular BERT model. We review the current …
-
Echoes of BERT: Do Modern Language Models … - Extensive work has established that early transformer models (BERT, GPT-2) learn hierarchical lingui…
-
(PDF) What Does BERT Learn about the Structure of Language? - BERT is a recent language representation model that has surprisingly performed well in diverse langu…
-
[PDF] What Does BERT Learn about the Structure of Language? - In this work, we use probing tasks to assess individual model layers in their ability to encode diff…
-
Do Vision Transformers See Like Convolutional Neural … - by M Raghu · 2021 · Cited by 1807 — Recent work has shown that (Vision) Transformer models (ViT) can…
-
[PDF] Do Vision Transformers See Like Convolutional Neural Networks? - We compute a CKA heatmap comparing all layers of ViT to all layers of ResNet, for two different ViT …
-
[PDF] reliability of cka as a similarity measure in deep learning - arXiv - (2022) found that the previously observed high CKA similarity between representations of later layer…
-
Do Vision Transformers See Like Convolutional Neural Networks … - ViT has more similarity between the representations obtained in shallow and deep layers compared to …
-
Similarity of Processing Steps in Vision Model … - We contribute an extensive quantitative and qualitative cross-layer and cross-model analysis, tracin…
-
Do Vision Transformers See Like Convolutional Neural … - We compute a CKA heatmap comparing all layers of ViT to all layers of ResNet, for two different ViT …
-
[PDF] Do Vision Transformers See Like Convolutional Neural Networks? - We compute a CKA heatmap comparing all lay- ers of ViT to all layers of ResNet, for two dif- ferent …
-
Attentive Multi-Layer Fusion for Vision Transformers - This mechanism learns to identify the most relevant layers for a target task and combines low-level …
-
Understanding Transformer-based Vision Models through … - RSA studies using CKA (Raghu et al., 2021) quantify alignment or separability of features across lay…
-
HiDrop: Hierarchical Vision Token Reduction in MLLMs via Late … - Prior work observes that removing early layers degrades performance and thus concludes that these la…
-
[PDF] VisiPruner: Decoding Discontinuous Cross-Modal Dynamics for … - The framework separates visual-text inte- gration into three key stages: Shallow Layers focus on tas…
-
A Layer-wise Information-Theoretic Analysis of Multimodal Reasoning - Across six semantically diverse tasks, both LLaVA-1.5 and LLaVA-1.6 exhibit strikingly consistent tr…
-
Vision-aligned Latent Reasoning for Multi-modal Large … - arXiv - In this paper, we introduce Vision-aligned Latent Reasoning (VaLR), a novel multi-modal reasoning fr…
-
[PDF] Concept-Aligned Neurons for Visual Comparison of Deep Neural … - From the collapsed bar plot in CAN, we observe that the most salient difference between the vision t…
-
[PDF] TOWARDS INTERPRETING VISUAL INFORMATION PROCESSING … - To understand the representations in the visual inputs for VLM and how the VLM processes them, we st…
-
How Visual Representations Map to Language Feature … - We reveal the layer-wise progression through which visual representations gradually align with langu…
-
Text-Guided Layer Fusion Mitigates Hallucination in Multimodal LLMs - Integrated into LLaVA-1.5-7B, TGIF provides consistent improvements across hallucination, OCR, and V…
-
[PDF] Does BERT Rediscover a Classical NLP Pipeline? - ACL Anthology - The difference score of every probing task in. Tenney et al. (2019a) peaks in the first four layers,…
-
Dynamic Cross-Layer Injection for Deep Vision-Language … - Vision-Language Models (VLMs) create a severe visual feature bottleneck by using a crude, asymmetric…

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)