查看填补数据的相关情况

下面的内容摘录自《用R探索医药数据科学》专栏文章的部分内容(原文5665字)。
2篇2章6节:R的多重填补法中随机回归填补法的应用,MICE包的实际应用和统计与可视化评估-CSDN博客
在数据分析中,缺失数据是常见且具有挑战性的问题。缺失数据可能影响统计分析的结果和决策的准确性。因此,填补缺失数据成为数据预处理的重要步骤之一。多重填补法是处理缺失数据的一个先进方法,它通过生成多个填补数据集,进行分析后汇总结果,从而提高了估计的准确性和可信度。本文将深入探讨R语言中多重填补法的应用,包括其基本概念、实现方法和实际案例。
多重填补法
多重填补法(Multiple Imputation, MI)是一种处理缺失数据的统计方法。缺失数据问题在实际数据分析中十分常见,如何有效处理这些缺失值是确保分析结果可靠性的关键。多重填补法的核心理念是生成多个可能的填补值,以形成若干个完整的数据集,然后对这些完整的数据集进行分析,并将分析结果加以综合,以得到最终的分析结论。
4、查看填补数据的相关情况
当程序完成填补后,我们用print函数查看 imputed_data 的信息,显示关于插补过程和结果的简要概况,包括各变量的插补情况、迭代次数、插补的有效性等。
# 打印插补数据对象的信息
print(imputed_data)结果可见:
Class: mids
Number of multiple imputations: 5
Imputation methods:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
"norm" "norm" "norm" "" ""
PredictorMatrix:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Sepal.Length 0 1 1 1 1
Sepal.Width 1 0 1 1 1
Petal.Length 1 1 0 1 1
Petal.Width 1 1 1 0 1
Species 1 1 1 1 0上面结果显示了多重插补结果的关键信息。首先,
imputed_data对象的类类型为mids,表示这是一个多重插补数据集,且总共进行了5次插补,生成了5个不同的数据集。对于插补方法,Sepal.Length、Sepal.Width和Petal.Length使用了"norm"方法,即正态线性回归来插补缺失值,而Petal.Width和Species没有进行插补,因为这些变量没有缺失值或选择不对其插补。接下来,
PredictorMatrix展示了插补过程中每个变量的预测关系。矩阵中的行表示被插补的变量,列表示用作预测的变量。值为1表示该列变量被用作预测变量,而0表示不作为预测变量。例如,Sepal.Length的插补是通过Sepal.Width、Petal.Length、Petal.Width和Species这些变量来预测的,而这些变量也会分别作为其他变量的预测因子,帮助填补缺失值。
5、填补后数据集的具体情况
我们也可以分别检查填补结果。mice包生成的填补数据集存储在imputed_data对象中。我们可以使用complete函数提取其中的一个填补数据集:
# 提取第一个填补数据集
completed_data1 <- complete(imputed_data, 1)
# 查看填补后的数据集的前几行
head(completed_data1, 10)结果可见:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.400000 0.2 setosa
2 4.9 3.0 1.400000 0.2 setosa
3 4.7 3.2 1.300000 0.2 setosa
4 4.6 3.1 1.500000 0.2 setosa
5 5.0 3.6 1.305053 0.2 setosa
6 5.4 3.9 1.700000 0.4 setosa
7 4.6 3.4 1.400000 0.3 setosa
8 5.0 3.4 1.500000 0.2 setosa
9 4.4 2.9 1.400000 0.2 setosa
10 4.9 3.1 1.500000 0.1 setosa

市面上的 R 语言培训班和书籍(包括网络上的文章或视频),由于受限于培训时间或书籍篇幅,往往难以深入探讨 R 语言在数据科学或人工智能中的具体应用场景,内容泛泛而谈,最终无法真正解决实际工作中的问题。同时,它们也缺乏针对医药领域的深度结合与讨论。为了解决这些痛点,我们推出了《用 R 探索医药数据科学》专栏。该专栏将持续更新,不仅为您提供系统化的学习内容,更致力于成为您掌握最新、最全医药数据科学技术的得力助手。
- 每篇文章篇幅在5000字 至9000字之间。
- 内容涵盖试验统计、预测模型、科研绘图、数据库、机器学习等热点领域。
重要更新
我们精心构建的《用R探索医药数据科学》学习地图,已于2026年3月中旬正式完成部署并上线。我们将专栏的核心内容重构为结构化的可视化知识图谱,不仅替代了原有的线性列表,更为学习者提供了清晰的进阶路径,订阅后的同学可以在PC端点击链接,查看目录:https://bestmd.coze.site/
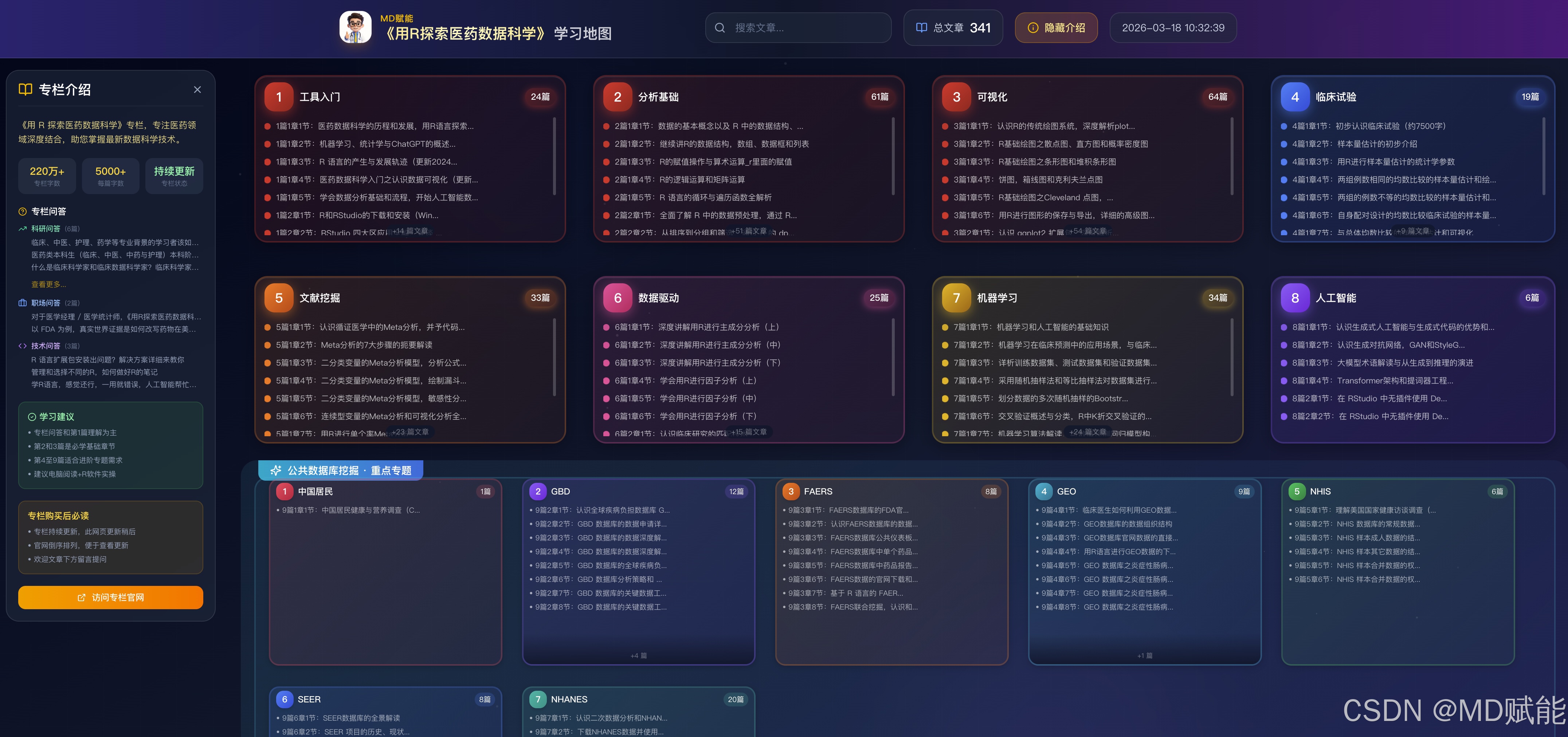
专栏购买后的 6 点必读
1、本专栏目前共包含 10 个模块,核心内容由 9 大篇章构成。专栏内容将持续更新,更新节奏不严格遵循固定目录顺序,而是结合团队实际工作进展,灵活选择对应章节发布。后续我们也会根据新技术发展与行业动态持续补充内容;若新增技术与现有体系差异较大,将酌情增设全新篇章。
2、建议大家按照以下路径高效学习:以专栏问答和第1篇作为理论基础重点理解,将第2篇和第3篇作为必修的核心操作基础,待基础夯实后,可根据科研需求针对性学习第4至9篇的进阶专题。为了保证最佳学习效果,建议大家在电脑端配合R软件进行同步实操练习。
3、结合当前临床数据科学的研究热点,在学习完前 3 篇内容后,可按自身需求选择后续学习方向:1)若用于自有课题数据,建议重点学习第二章 常规分析技术、第六篇 数据驱动分析及第七篇 机器学习与预测建模;2)若希望快速上手、尽早产出成果,且不介意稿件可能被期刊归类为综述,可选择第五篇 文献挖掘相关技术;3)若开展临床公共数据挖掘,建议结合自身研究方向与兴趣,从第九篇所列数据库中选取其一进行深度学习与实践;如有其他新技术需求,也欢迎在文章评论区留言。
4、本文目录支持直接点击跳转至具体文章,内容按 “篇 - 节” 正向顺序排列,方便按需学习。专栏问答板块以解答疑惑为主,若从基础入门,可直接从第一篇第一章第一节开始系统学习。

5、专栏官网地址(https://blog.csdn.net/2301_79425796/category_12729892.html)的内容显示为倒序排列,便于快速查看最新更新章节。需注意,专栏更新不严格遵循章节顺序,会结合技术热度灵活追加内容,可能连续数周更新已有篇章的补充内容,虽页面显示无明显章节变动,但每周都会有新文章上线,专栏处于持续更新状态。同时,每新增一篇文章后,会第一时间同步更新本文目录,确保目录与专栏内容实时匹配。
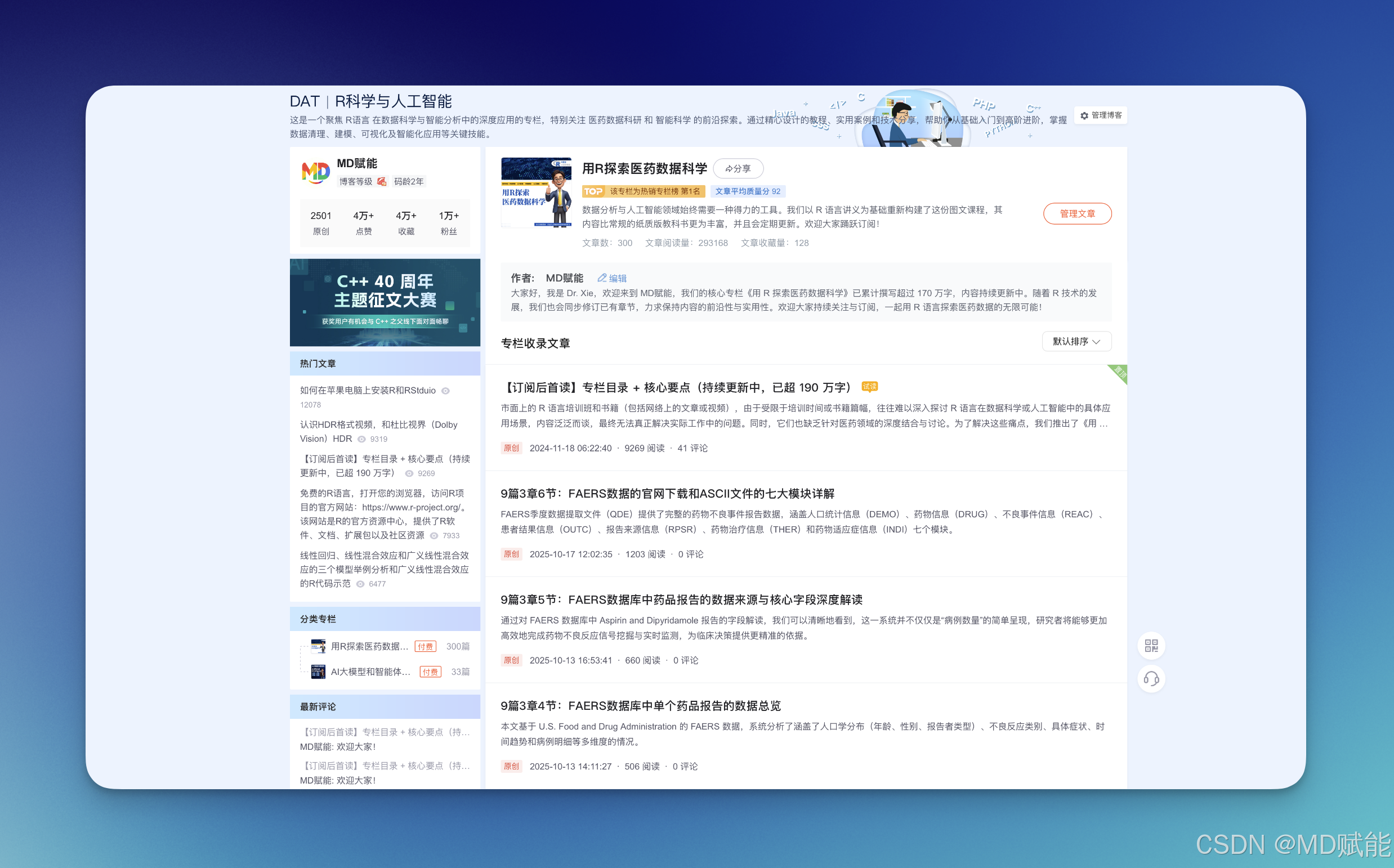
6、建议大家优先用电脑阅读(而非手机),同时打开 R 软件,直接复制文中代码实操练习、模仿复现,再一步步拆解理解背后的逻辑。学习完每篇文章后,也推荐大家写下学习感悟:一来可作为笔记留存,清晰记录学习进度与核心重点;二来能梳理思路、加深对技术知识点的理解,还能和其他学习者交流分享心得、互相启发。若学习过程中遇到具体问题,欢迎直接在文章下方留言评论。我们会及时关注你的疑问,结合问题场景与细节给出针对性解答和指导,帮你顺畅掌握专栏中的技术内容。
https://datch.blog.csdn.net/article/details/143842464?spm=1011.2415.3001.5331
专栏问答
科研问答
科研问答:临床、中医、护理、药学等专业背景的学习者该如何认识 R 语言学习,让科研真正为自己服务?
科研问答:医药类本科生(临床、中医、中药与护理)本科阶段是否需要开展科研学习?
科研问答:什么是临床科学家和临床数据科学家?临床科学家在我国培养和NIH的资助有哪些?
科研问答:公共数据库发表能发表国际学术期刊吗?能够成为本硕博的毕业论文主要研究吗?以NHANES数据库为例
职场问答
职场问答:对于医学经理 / 医学统计师,《用R探索医药数据科学》这套专栏对职场有何帮助?
职场问答:以 FDA 为例,真实世界证据是如何改写药物在美上市的审批规则?
技术问答
技术问答:学R语言,感觉还行,一用就错误,人工智能帮忙写代码也看不懂错误,怎么办?
第一篇:介绍和工具的使用
1篇1章:认识数据科学和R
1篇1章1节:医药数据科学的历程和发展,用R语言探索数据科学
1篇1章2节:机器学习、统计学与ChatGPT的概述,与R语言的相关
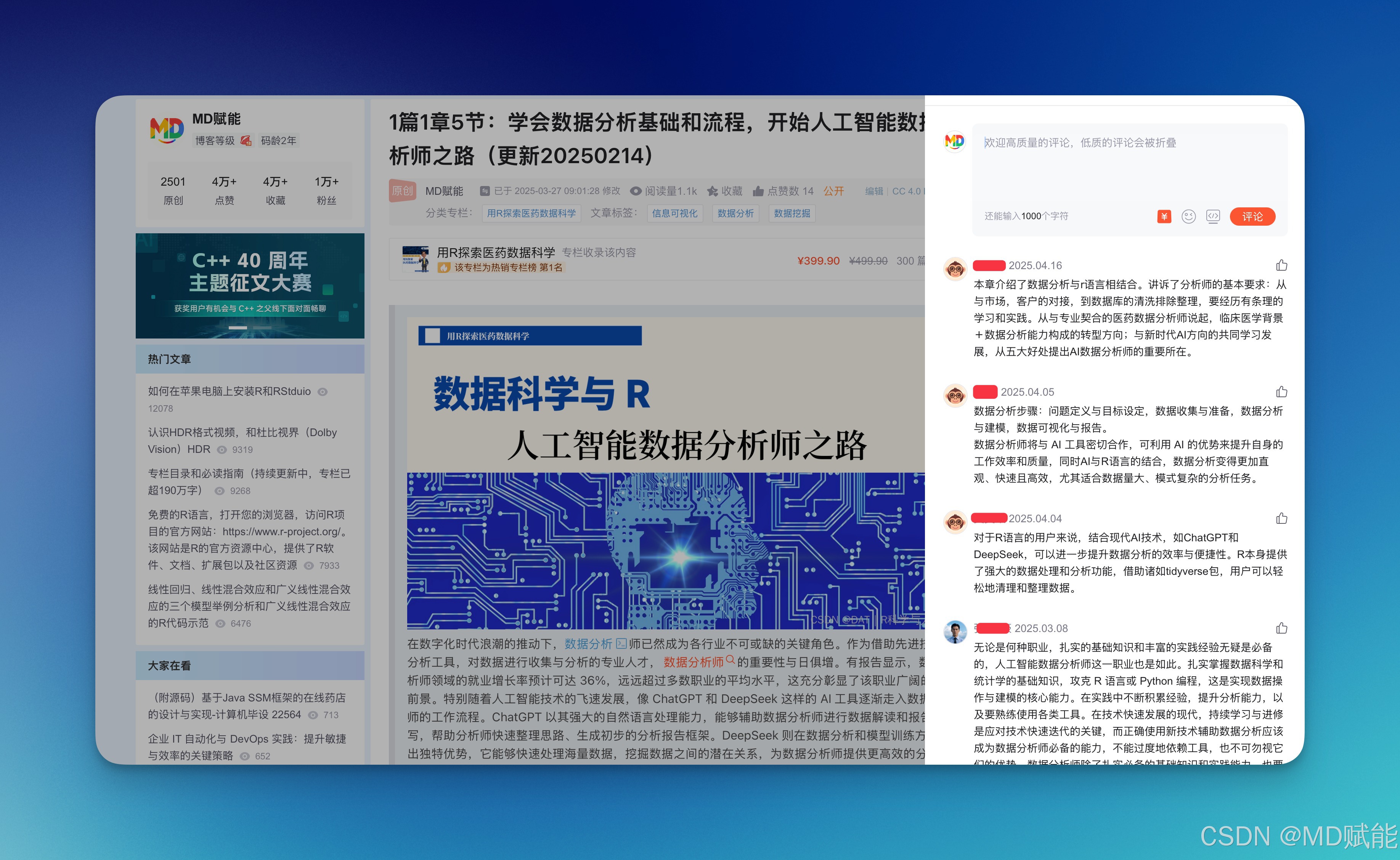
1篇1章5节:学会数据分析基础和流程,开始人工智能数据分析师之路
1篇2章:R的安装和数据读取
1篇2章1节:R和RStudio的下载和安装(Windows 和 Mac)
1篇2章2节:RStudio 四大区应用全解,兼谈 R 的代码规范与相关文件展示
1篇2章3节:RStudio的高效使用技巧,自定义RStudio环境
1篇2章4节:用RStudio做项目管理,静态图和动态图的演示,感受ggplot2的魅力
1篇2章5节:R包管理,从模糊安装到自动更新,和工作目录和工作空间的设置
1篇2章6节:R的数据集读取和利用,如何高效地直接复制黏贴数据到R
1篇2章7节:用R读写RDS、RData、CSV和TXT格式文件
1篇2章8节:用R读写Excel、SPSS、SAS、Stata和Minitab等产生的数据文件
1篇3章:文档和课件输出
1篇3章1节:用R写作,先认识 NoteBook 和 Markdown
1篇3章2节:如何在 R Markdown 和 R Notebook 中创建使用
1篇3章3节:R Markdown的创建详解和直接使用学术期刊和出版社的模板
1篇3章4节:R Markdown 的文档开头(YAML),从基础到扩展包
1篇3章6节:R Markdown 的代码块、绘图与数学公式解析
1篇3章8节:HTML Widgets,将 JavaScript 可视化库封装成 R 函数
1篇3章9节:使用 R Markdown 和 Shiny 结合R语言进行数据报告和交互式应用的创建
第二篇:常规的分析技术
2篇1章:认识数据
2篇1章1节:数据的基本概念以及 R 中的数据结构、向量与矩阵的创建及运算
2篇2章:数据的预处理
2篇2章1节:全面了解 R 中的数据预处理,通过 R 基本函数实施数据查阅
2篇2章2节:从排序到分组和筛选,通过 R 的 dplyr 扩展包来操作
2篇2章3节:处理医学类原始数据的重要技巧,R语言中的宽长数据转换,tidyr包的使用指南
2篇2章5节:数据科学中的缺失值的处理,删除和填补的选择,K最近邻填补法
2篇2章6节:R的多重填补法中随机回归填补法的应用,MICE包的实际应用和统计与可视化评估
2篇2章9节:用R做数据重塑,增加变量和赋值修改,和mutate()函数的复杂用法
2篇2章10节:用R做数据重塑,变体函数应用详解和可视化的数据预处理介绍
2篇2章12节:R语言中字符串的处理,正则表达式的基础要点和特殊字符
2篇2章13节:R语言中Stringr扩展包进行字符串的查阅、大小转换和排序
2篇2章14节:R语言中字符串的处理,提取替换,分割连接和填充插值
2篇2章15节:字符串处理,提取匹配的相关操作扩展,和Stringr包不同函数的重点介绍和举例
2篇3章:定量数据的统计描述
2篇3章1节:用R语言进行定量数据的统计描述,文末有众数的自定义函数
2篇3章2节:离散趋势的描述,文末1个简单函数同时搞定20个结果
2篇3章9节:组间差异的非参数检验,Wilcoxon秩和检验和Kruskal-Wallis检验
2篇4章:定性数据的统计描述
2篇4章1节:定性数据的统计描述之列联表,文末有优势比计算介绍
2篇4章2节:认识birthwt数据集,EpiDisplay和Gmodels扩展包的应用
2篇4章3节:独立性检验,卡方检验,费希尔精确概率检验和Cochran-Mantel-Haenszel检验
2篇4章5节:分类型变量的Spearman相关分析,偏相关分析和相关图分析
2篇4章6节:相关图的GGally扩展包,和制表的Tableone扩展包
2篇5章:常见类型回归分析
2篇5章7节:构建因变量为分类变量的二分类Logistic回归模型
2篇5章8节:详解不同逻辑回归模型的比较,和如何进行变量优化
2篇5章9节:深度讲解有序多分类Logistic回归模型的分析
2篇6章:生存分析模型
2篇6章4节:认识比例风险模型和Cox比例风险模型,学会从协变量的调整选择最优模型
2篇6章5节:用逐步回归方法来选择模型协变量,比例风险假定的检验和森林图的绘制
2篇7章:高级回归分析
2篇7章5节:Lasso 回归的原理和应用场景,并用R进行代码演示
2篇7章6节:弹性网(Elastic Net)回归的原理和应用场景,并用R进行代码演示
2篇7章7节:逐步回归的原理和应用场景,并用R进行代码演示包的高级应用
2篇7章8节:主成分回归的原理和应用场景,并用R进行代码演示
2篇7章9节:神经网络回归的原理和应用场景,并用R进行代码演示
2篇7章10节:分位数回归的原理和应用场景,并用R进行代码演示
第三篇:数据可视化技术
3篇1章:R的传统绘图
3篇1章1节:认识R的传统绘图系统,深度解析plot()函数和par()函数的使用
3篇1章5节:R基础绘图之Cleveland 点图,马赛克图和等高图
3篇2章:R的进阶绘图
3篇2章1节:认识 ggplot2 扩展包,深度解析 qplot() 函数的使用
3篇2章2节:ggplot2绘图之原理逻辑分解,掌握绘图步骤
3篇2章4节:ggplot2绘图之几何体解析(一),参考线和基准线与分布图和频数图
3篇2章5节:ggplot2绘图之几何体解析(二),关系图和时间序列图与误差条和高级图形平滑曲线
3篇2章8节:让 ggplot2 绘图进行顶级科研杂志的配色
3篇3章:基于gglot2的扩展包应用
3篇3章6节:绘制切尔诺夫面图(疼痛评分的笑脸可视化)和时间序列数据的日历热图
3篇3章12节:可视化扩展包,从主成分分析到时间序列,从K-means聚类到广义线性模型
3篇3章13节:绘制大数据级别的字母值箱线图(Letter-Value Boxplot)
3篇3章14节:绘制美观和直观的蜂群图(Bee Swarm Plot)
3篇3章15节:用不同方法绘制高级云雨图(Raincloud Plot)
3篇4章:三维图形可视化
3篇4章2节:深度讲解如何绘制三维透视图,从内置函数到扩展包函数
3篇4章4节:绘制三维切片图和三维切片轮廓图,文末添加三维文本信息
3篇4章5节:如何绘制三维曲面图、三维球面图和三维曲面地形图-CSDN博客
3篇4章6节:绘制三维等值面图、三维等值体素图和三维多边形图
3篇4章9节:如何将 ggplot2 对象转化为三维图形-CSDN博客
3篇5章:科研绘图新利器(plotthis 包)
3篇5章1节:科研绘图,这个 R 包可能比 ggplot2 更适合你,绘制渐变面积图
3篇5章11节:绘制 Chord Diagram(弦图)和 Circos Plot(环形关系图)
3篇5章12节:降维可视化的DimPlot与FeatureDimPlot应用
第四篇:临床试验特定技术
4篇1章:临床试验的常规统计
4篇1章4节:两组例数相同的均数比较的样本量估计和绘制功效曲线
4篇1章6节:自身配对设计的均数比较临床试验的样本量估计和可视化
4篇2章:样本量估计的进阶技术
4篇2章4节:三因素(2b × 3w × 2b)混合设计功效模拟实战,以抗高血压药物试验为例
4篇2章7节:基于分层生存模型的功效计算,以糖尿病临床试验为例
第五篇:文献挖掘的技术
5篇1章:Meta分析攻略
5篇1章1节:认识循证医学中的Meta分析,并予代码演示分析绘图
5篇1章3节:二分类变量的Meta分析模型,分析公式构建和结果解读
5篇1章4节:二分类变量的Meta分析模型,绘制漏斗图和应用剪补法,绘制和解读轮廓增强漏斗图
5篇1章5节:二分类变量的Meta分析模型,敏感性分析和亚组分析,绘制森林图
5篇2章:高级Meta分析
5篇2章3节:在经典临床研究中进行二次固定效应剂量-反应建模和预测
5篇2章6节:贝叶斯 Meta 分析在小样本、高异质性及稀疏数据下的应用(上篇:核心函数)
5篇2章7节:贝叶斯 Meta 分析在小样本、高异质性及稀疏数据下的应用(中篇:具体建模)
5篇2章8节:贝叶斯 Meta 分析在小样本、高异质性及稀疏数据下的应用(下篇:可视化)
5篇2章9节:累积Meta分析在循证医学中的应用及R语言实操
5篇3章:文献计量学
5篇3章2节:数据库的数据采集,WOS数据库和PUBMED数据库的文献信息批量下载和分析
5篇3章3节:国际六大科研文献数据库的数据加载与格式转换解析
5篇3章12节:耦合网络可视化,从常规网络图到耦合分析聚类图的深度讲解
5篇3章13节:共被引网络、历史共被引网络和共词网络的可视化
5篇3章14节:概念结构图,贡献度最高文献因子图和最被引用文献因子图
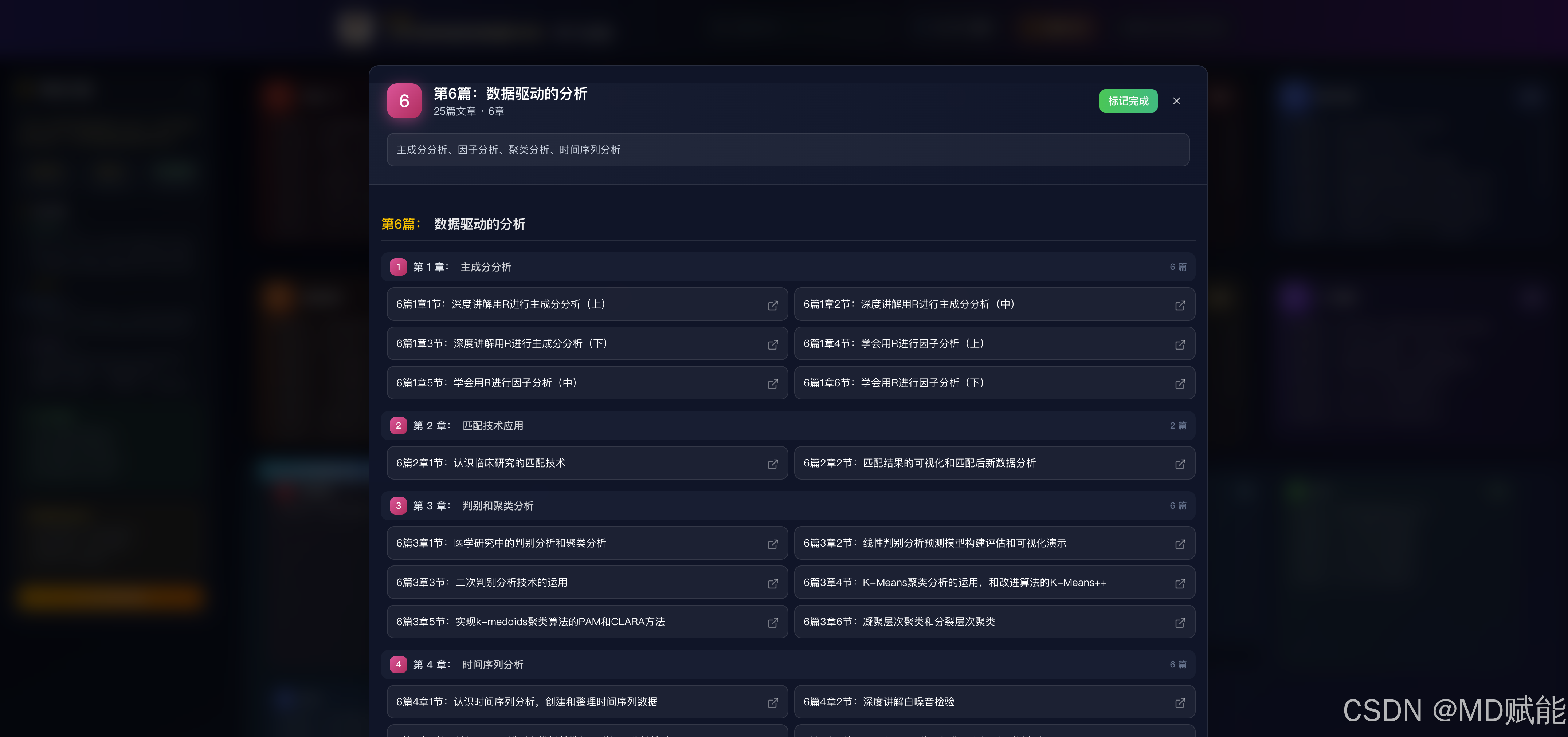
第六篇:数据驱动的分析
6篇1章:主成分分析
6篇2章:匹配技术应用
6篇3章:判别和聚类分析
6篇3章4节:K-Means聚类分析的运用,和改进算法的K-Means++
6篇3章5节:实现k-medoids聚类算法的PAM和CLARA方法
6篇4章:时间序列分析
6篇4章3节:认识ARIMA模型和模拟其数据,讲解平稳性检验
6篇4章5节:如何应用SARIMA模型来进行时间序列数据的预测
6篇4章6节:Facebook 的时间序列预测的 Prophet 模型
6篇5章:数据因果分析
6篇6章:孟德尔随机化
6篇6章1节:认识孟德尔与孟德尔定律,为流行病学因果研究提供方法指导
第七篇:机器学习和预测
7篇1章:机器学习入门
7篇1章2节:机器学习在临床预测中的应用场景,与临床预测模型的关键步骤解析
7篇1章3节:详析训练数据集、测试数据集和验证数据集及其划分策略
7篇1章4节:采用随机抽样法和等比抽样法对数据集进行二份及三份的划分
7篇1章5节:划分数据的多次随机抽样的Bootstrap法和加权随机抽样法
7篇1章6节:交叉验证概述与分类,R中K折交叉验证的详细解析
7篇1章12节:认识机器学习的模型评估,掌握数值型数据的模型评估方法
7篇1章15节:六大ROC曲线扩展包的对比,和其它评估曲线的绘制
7篇2章:抽样与重抽样技术
7篇3章:特征工程技术
第八篇:R与人工智能
8篇1章:人工智能理论
8篇1章4节:Transformer架构和提词器工程学的出现
8篇2章:R与人工智能
8篇2章1节:在 RStudio 中无插件使用 DeepSeek(基本篇)
8篇2章2节:在 RStudio 中无插件使用 DeepSeek(进阶篇)
第九篇:公共数据库挖掘
9篇1章:中国居民数据库
9篇1章1节:中国居民健康与营养调查(CHNS)数据库的官网解析和数据下载(2026版)
9篇2章:GBD 数据库
9篇2章6节:GBD 数据库分析策略和 SDI 指数的应用解读,并以高血压为例
9篇2章9节:多源数据联合应用在全球疾病负担(GBD)分析中的策略分析
9篇2章10节:2025年基于GBD数据的柳叶刀子刊研究深度解析(全网最深度解读)
9篇2章12节:不同临床科室可基于GBD进行数据挖掘的方向举例(联合分析)
9篇3章:FAERS 数据库(包括其它药物警戒数据库)
9篇3章1节:FAERS数据库的FDA官方讲解,对期刊投稿设限的FAERS数据库的客观评价!
9篇3章2节:认识FAERS数据库的数据和公共仪表板(分析前必看)
9篇3章5节:FAERS数据库中药品报告的数据来源与核心字段深度解读
9篇3章6节:FAERS数据的官网下载和ASCII文件的七大模块详解
9篇3章8节:FAERS联合挖掘,认识和获取VigiBase数据库资料
9篇4章:GEO 数据库
9篇4章5节:GEO 数据库之炎症性肠病基因表达分析演示(一)
9篇4章6节:GEO 数据库之炎症性肠病基因表达分析演示(二)
9篇4章7节:GEO 数据库之炎症性肠病基因表达分析演示(三)
9篇4章8节:GEO 数据库之炎症性肠病基因表达分析演示(四)
9篇4章9节:GEO 数据库之炎症性肠病基因表达分析演示(五)
9篇5章:NHIS 数据库
9篇6章:SEER 数据库
9篇6章3节:SEER数据库的数据下载权限申请(2026版)
9篇6章4节:SEER数据库 SEERStat、SEERPrep、HDCalc 工具介绍
9篇6章6节:SEER 数据库的2025年数据集中的数据选择(2026年版)
9篇6章7节:SEER 数据库的2025年数据变量多条件组合选择(2026年版)
9篇6章8节:用 Export 功能导出 SEER 数据的全流程操作演示(2026年版)
9篇7章:NHANES 数据库
9篇7章6节:深度讲解不同NHANES的权重的种类选择和R包
9篇7章9节:一步一步构建高效读取NHANES数据的自定义函数
9篇7章10节:如何解决 NHANES 数据合并所遇原表差异问题
9篇7章11节:2025年后如何使用扩展包访问、下载和分析 NHANES 数据
9篇7章13节:根据关键词检索NHANES变量和得到相关信息,并且通过指定URL直接下载数据
9篇7章14节:下载 NHANES 的数据清单、搜索表格和表格里面的变量汇总
9篇7章15节:快速获取 NHANES 特定的表格信息和变量信息
9篇7章16节:NHANES 2017–2023 数据的样本设计、无应答偏差评估与分析说明
9篇7章17节:特殊的NHANES数据解读,包括NNYFS、NHEFS、NHES 和 HHANES 等数据
9篇7章18节:复现NHANES的美国成人抑郁症患病率研究(上)
9篇7章19节:复现NHANES的美国成人抑郁症患病率研究(中)
9篇7章20节:复现NHANES的美国成人抑郁症患病率研究(下)
9篇8章:MIMIC 数据库
9篇9章:SHARE 数据库
本专栏多次荣获 热销专栏榜 第一名

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)