(2025|Meta,ViT,大规模自监督训练稳定性,Gram 锚定/patch一致性,高分辨率训练,多学生并行蒸馏,RoPE,密集视觉特征,分类/分割/检测)DINOv3
DINOv3

论文地址:https://arxiv.org/abs/2508.10104
项目页面:https://github.com/facebookresearch/dinov3
dinov3-tutorial:https://dinov3.org/dinov3-tutorial
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
7.1 适用于各种场景的 Vision Transformer
7.2 适用于资源受限环境的 Efficient ConvNeXts
7.3 基于 dino.txt 的 DINOv3 零样本推理
1. 引言
基础模型 已成为现代计算机视觉的核心构建模块,通过单个可重用(reuse)的模型实现跨任务和领域的广泛泛化能力。
自监督学习(self-supervised learning,SSL)是一种训练此类模型的强大方法。
- 它直接从原始像素数据中学习,并利用图像中模式的自然共现性(co-occurrences)。与需要图像与高质量元数据配对的弱监督和全监督预训练方法不同,SSL 可以在海量原始图像集上进行训练。由于拥有几乎无限的训练数据,这对于训练大规模的视觉编码器尤为有效。DINOv2 例证了这些优势,在图像理解任务中取得了令人印象深刻的结果,并实现了在复杂领域(如组织病理学)的预训练。
- 通过 SSL 训练的模型还具有其他理想特性:它们对输入分布变化具有鲁棒性,提供强大的全局和局部特征,并生成有助于物理场景理解的丰富嵌入。由于 SSL 模型并非针对任何特定下游任务进行训练,它们会产生通用且鲁棒的特征。例如,DINOv2 模型在不同任务和领域上都表现出色,无需特定任务的微调,允许一个冻结的骨干网络服务于多种目的。
- 重要的是,自监督学习特别适合训练组织病理学、生物学、医学影像、遥感、天文学甚至高能物理等领域可用的大量观测数据。这些领域通常 缺乏元数据,并且已被证明可以从 DINOv2 等基础模型中受益。
- 最后,SSL 不需要人工干预,非常适合随着网络数据量增长而进行持续学习。
(2024|TMLR|Meta,DINOv2,ViT,自蒸馏,iBOT,SwAV 中心化,判别式自监督预训练,分类/分割,分辨率调整)无监督稳健的视觉特征学习
然而,在实践中,SSL 通过利用大量无约束数据来生成任意大且强大的模型,在规模化时仍然面临挑战。虽然 Oquab 等人提出的启发式方法缓解了 模型不稳定和崩溃 的问题,但进一步扩大规模出现了更多问题。
- 首先,如何从未标记的集合中收集有用的数据尚不明确。
- 其次,在通常的训练实践中,采用余弦调度意味着需要预先知道优化周期,这在大型图像语料库上训练时很困难。
- 第三,在早期训练后,特征的性能逐渐下降,通过检查 patch 相似度图可以证实这一点。这种现象出现在使用大于 ViT-Large 规模(300M 参数)的模型进行长时间训练时,降低了扩展 DINOv2 的效用。
解决上述问题促成了本文的工作,即 DINOv3,它在规模化 SSL 训练方面取得了进展。本文证明,一个单一的、冻结的 SSL 骨干网络可以作为一个通用的视觉编码器,在具有挑战性的下游任务上达到最先进的性能,优于监督式和依赖元数据的预训练策略。
本文的研究遵循以下目标:
- 训练一个跨任务和领域通用的基础模型,
- 改进现有 SSL 模型在密集特征上的不足,
- 发布一个可以直接使用的模型系列。
1)强大且通用的基础模型。DINOv3 旨在通过扩展模型大小和训练数据,在两个维度上提供高水平的通用性。
- 首先,SSL 模型的一个关键理想属性是在保持冻结的情况下也能实现卓越的性能,理想情况下能达到与专门模型相似的先进水平。在这种情况下,一次前向传递即可在多个任务上获得领先结果,从而节省大量计算资源——这对于实际应用,尤其是边缘设备,是一个至关重要的优势。
- 其次,一个不依赖元数据的可扩展 SSL 训练流程为众多科学应用打开了大门。通过在多样化的图像集(无论是网络图像还是观测数据)上进行预训练,SSL 模型可以泛化到大量的领域和任务。
- 如下图所示,从高分辨率航拍图像中提取的 DINOv3 特征的 PCA 结果清晰地区分了道路、房屋和绿地,突显了模型的特征质量。

2)通过格拉姆锚定(Gram Anchoring)实现更优的特征图。
- DINOv3 的另一个关键特点是 密集特征图的显著改进。
- DINOv3 的 SSL 训练策略旨在生成在高级语义任务上表现出色,同时又能产生适用于解决几何任务(如深度估计或 3D 匹配)的优秀特征图的模型。特别是,模型应产生可直接使用或仅需少量后处理的密集特征。当使用大量图像进行训练时,密集表示和全局表示之间的权衡尤其难以优化,因为高级理解的目标可能与密集特征图的质量相冲突。这些相互矛盾的目标会导致大型模型和长时间训练下密集特征的崩溃。
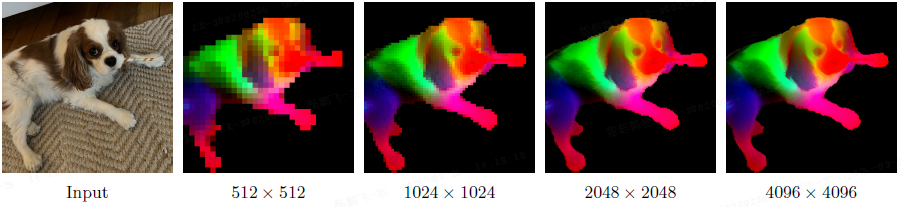
- 本文新的 “格拉姆锚定” 策略有效地缓解了这种崩溃。因此,DINOv3 获得了比 DINOv2 明显更好的密集特征图,即使在非常高的分辨率下也能保持清晰(见下图)。

图 3:高分辨率密集特征。
- 该图展示了通过 DINOv3 输出特征计算得到的带有红色叉标记的图像块与所有其他图像块之间的余弦相似度图。
- 输入图像尺寸为 4096×4096。
3)DINOv3 模型系列
- 通过格拉姆锚定解决密集特征图的退化问题,释放了扩展的能力。因此,使用 SSL 训练更大的模型会带来显著的性能提升。
- 本文成功训练了一个具有 7B 参数的 DINO 模型。由于如此大的模型运行需要大量资源,本文应用蒸馏将其知识压缩到更小的变体中。最终,本文展示了 DINOv3 视觉模型系列,这是一个全面的套件,旨在应对广泛的计算机视觉挑战。
- 该模型系列旨在通过提供适应不同资源约束和部署场景的可扩展解决方案,来推动技术水平的发展。
- 蒸馏过程产生了多种尺度的模型变体,包括 Vision Transformer(ViT)的 Small、Base 和 Large 版本,以及基于 ConvNeXt 的架构。值得注意的是,高效且广泛采用的 ViT-L 模型在各种任务上的性能接近原始的 7B 参数教师模型。
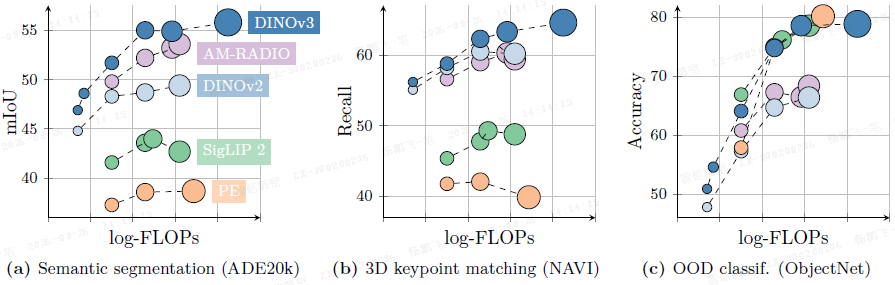
- 总体而言,DINOv3 系列在广泛的基准测试中表现出强大的性能,在全局任务上与竞争模型相当或超过,同时在密集预测任务上显著优于它们,如下图所示。
3. 无监督下的规模化训练
3.1 数据准备
数据规模是大型基础模型成功的关键因素之一,但简单地增加数据量并不总能带来更好的性能。成功的扩展通常涉及精心设计的数据整理流程。
数据收集与整理: 本文从公开的 Instagram 帖子中收集了约 17B 图像作为原始数据池。在此之上,本文构建了三部分数据:
-
聚类整理: 应用 Vo et al. (2024) 的层次化(hierarchical) k-means 方法,生成了一个包含 1689M 图像、覆盖广泛视觉概念的数据集(LVD-1689M)。
-
检索整理: 采用 Oquab et al. (2024) 的方法,从数据池中检索与选定种子数据集相似的图像,以覆盖下游任务相关的视觉概念。
-
公共数据集: 使用 ImageNet1k, ImageNet22k, Mapillary 等公开数据集。
数据采样:
- 预训练时,本文采用混合采样器。
- 灵感来自 Charton and Kempe (2024),在每次迭代,随机采样同质 batch(仅来自 ImageNet1k)或异质 batch(混合所有其他数据)。
- 同质 batch 数据占训练的 10%

数据消融: 对比实验表明,没有单一的数据精选技术在所有基准上表现最佳,而本文的混合流程综合了各种方法的优点。
3.2 大规模自监督训练
大多数 SSL 算法在扩展到更大模型时面临训练稳定性或表示能力不足的问题。DINOv2 是一个例外,本文在此基础上进行扩展。
学习目标:
- 沿用 DINOv2 的混合损失,包括图像级目标 L_DINO 和 patch 级潜在重建目标 L_iBOT。
- DINO 中的中心化被替换为 SwAV 中的 Sinkhorn-Knopp 算法。
- 每个目标都是通过位于骨干网络顶部的专用头(head)的输出来计算得出的,这使得在计算损失之前能够对特征进行一定程度的专门化处理。此外,还对局部和全局裁剪的骨干网络输出应用了一个专用的层归一化操作。通过实验发现,这一改变在训练后期稳定了 ImageNet kNN 分类并提高了密集性能。
- 此外,还添加了 Koleo 正则化器 L_Koleo 以鼓励 batch 内特征均匀分布。
- 初始训练阶段优化以下损失:
![]()
更新的模型架构:
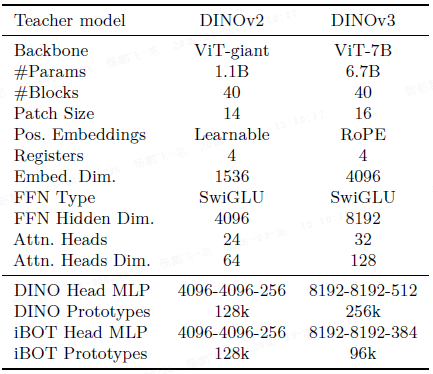
- 将模型扩展到 7B 参数(ViT-7B)。
- 主要改变包括:使用 patch 大小 16,引入个性化 RoPE,并采用 RoPE-box 抖动(随机缩放坐标框)以提高对不同分辨率的鲁棒性。
优化:
- 为克服难以预知最优训练周期的难题,本文放弃所有参数调度,采用恒定的学习率、权重衰减和教师 EMA 动量。
- 本文只使用线性预热(warmup)。
- 使用 AdamW 优化器,总 batch 大小为 4096,分布在 256 个 GPU 上。
- 采用多裁剪策略(2 个全局裁剪,8 个局部裁剪)。使用边长为 256/112 像素的正方形图像来进行全局/局部裁剪,再加上图像大小的变化,使得每张图像的有效序列长度与 DINOv2 相同,每 batch 的总序列长度为 3.7M token。
4. 格拉姆锚定:一种用于密集特征的正则化方法
延长训练时间虽能提升全局任务性能,但会导致密集任务性能下降(如上图所示),原因是 patch 级特征表示出现不一致。本文提出格拉姆锚定来解决此问题。
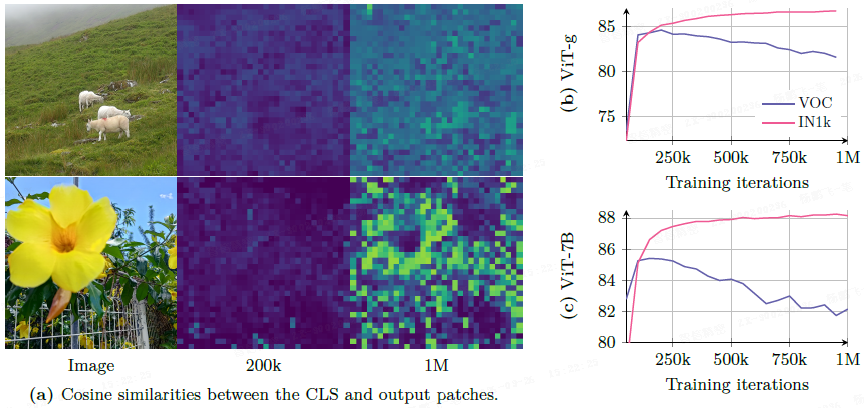
4.1 训练过程中 patch 级一致性的丧失
随着训练进行,分类性能持续提升,但分割性能在约 200K 次迭代后开始下降(如上图所示)。
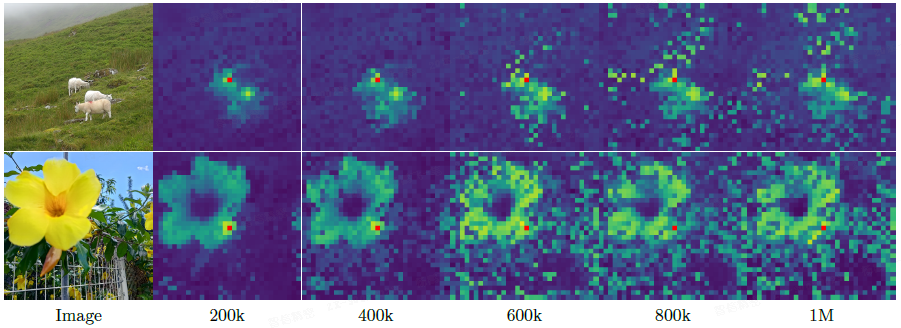
可视化显示,相似度图从平滑、局部化变得嘈杂,无关区域也与参考 patch 高度相似。
这与 patch 范数异常不同。
- 事实上,在训练过程中,patch 范数保持稳定,而 CLS token 和 patch 输出间的余弦相似度逐渐增加。
- 这是意料之中的现象,但这也意味着图像块特征的局部性有所减弱。
4.2 格拉姆锚定目标
本文引入一个新目标,通过强制保持 patch 级一致性来缓解退化。
- 该损失作用于格拉姆矩阵(图像中所有 patch 特征对的点积矩阵)。
- 本文希望将学生模型的格拉姆矩阵推向一个早期模型(格拉姆教师)的矩阵,该早期模型具有更好的密集特性。
- 通过对格拉姆矩阵而非特征本身进行操作,局部特征能够自由移动,只要相似性的结构保持不变即可。
损失定义:
![]()
其中,X_S 和 X_G 分别是学生和教师 L2 归一化后的局部特征矩阵。
应用:
- 该损失只在全局裁剪上计算。
- 为了效率,在训练 1M 次迭代后才开始应用此损失。观察到,在较晚阶段应用 L_Gram 仍能修复非常退化的局部特征。
- 为了进一步提高性能,每 10K 迭代更新一次 Gram 教师,此时 Gram 教师将与主 EMA 教师完全相同。此阶段被称为 “精炼阶段”,该阶段优化目标:
![]()
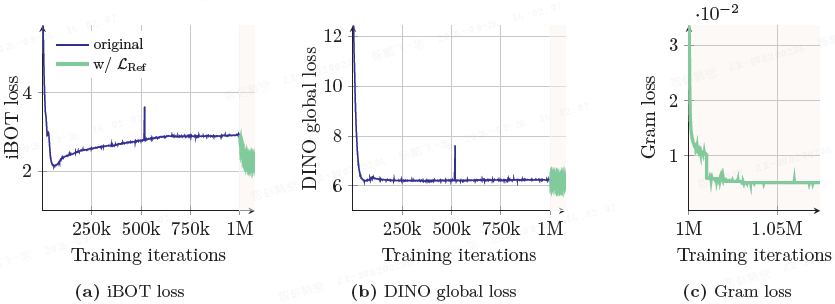
效果: 如上图所示,
- 应用格拉姆目标后(1M),iBOT 损失下降更快。这表明,由稳定的格拉姆教师引入的稳定性对 iBOT 目标产生了积极影响。
- 相比之下,格拉姆目标对 DINO 损失没有显著影响。这一观察结果表明,格拉姆目标和 iBOT 目标对特征的影响方式相似,而 DINO 损失对它们的影响则有所不同。
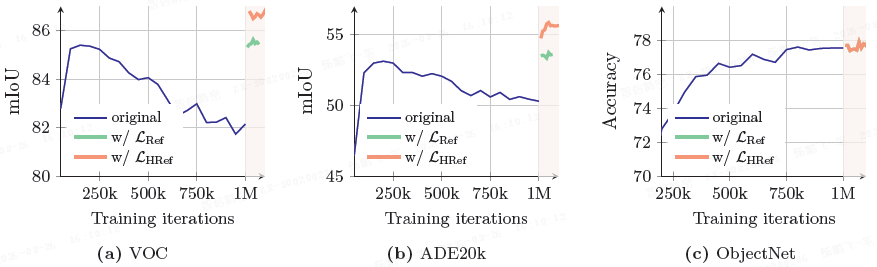
如上图所示(H 表示高分辨率特征),使用格拉姆锚定后,密集任务性能显著提升,且随着格拉姆教师更新而持续受益。
4.3 利用更高分辨率特征
方法:
- 向格拉姆教师输入双倍分辨率的图像,得到更精细的特征图,然后通过双三次插值进行 2 倍下采样,以匹配学生输出大小。如下图 a 所示(256→512→Ds)。
- 观察到,在更高分辨率特征中所具有的卓越的块级一致性在降采样过程中得以保留,从而形成了更平滑且更具连贯性的块级表示。
- 由于采用 RoPE,模型能够无缝处理不同分辨率的图像,无需进行任何调整。
- 本文计算了下采样特征的格拉姆矩阵,并将其用于替换目标函数中的 X_G。新的优化目标标记为 L_HRef。这种方法使得格拉姆目标能够有效地将平滑后的高分辨率特征的改进的 patch 一致性提炼到学生模型中。

效果:
- 这种高分辨率精炼目标 L_HRef 在 L_Ref 的基础上进一步提升了密集任务性能(如上上图所示)。
- 格拉姆教师的选择对结果影响不大,但使用太晚的(1M 次迭代)教师会因自身一致性差而产生负面影响(如上表所示)。
- 使用格拉姆锚定后的 patch 级一致性的可视化效果如下图所示。

5. 后训练
5.1 分辨率缩放
模型训练时使用较低分辨率(256)。推理时也不使用固定的分辨率,而是根据实际需求调整。为适应高分辨率应用,本文增加了一个高分辨率适应步骤。
方法:
- 使用混合分辨率训练 10K 次额外迭代,全局裁剪大小从 {512, 768} 中采样,局部裁剪从 {112, 168, 224, 336} 中采样。
- 此阶段同样加入了格拉姆锚定(使用 7B 教师作为格拉姆教师),这对于维持密集任务性能至关重要。
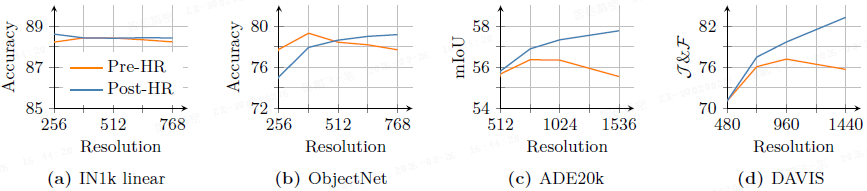
效果:
- 如上图所示,适应后的模型在图像分类(a)上略有提升,在对象识别 OOD 任务(b)上低分辨率略有下降但高分辨率提升,在分割(c)和跟踪(d)等密集任务上则随分辨率提高而显著改善。
- 如下图所示,模型甚至能处理远高于训练分辨率(>4k)的输入,且特征保持稳定。
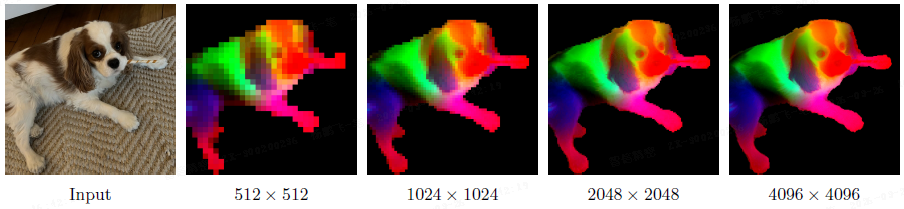
5.2 模型蒸馏
为满足不同使用场景,本文将 ViT-7B 模型蒸馏成更小的变体(ViT-S, B, L, S+, H+ 和 ConvNeXt 模型)。
方法:
- 蒸馏使用与初始训练相同的目标,但使用固定的 7B 模型作为教师,不再使用 EMA 更新。
- 由于未发现 patch 一致性问题,因此未采用格拉姆锚定技术。这种策略使得蒸馏后的模型能够继承教师模型丰富的表示能力,同时又更便于部署和实验。
高效多学生蒸馏:
- 本文设计了一个并行蒸馏流程,允许同时训练多个学生。
- 所有学生共享教师推理的计算成本,新增学生只增加其自身的训练成本,从而显著提高整体效率。
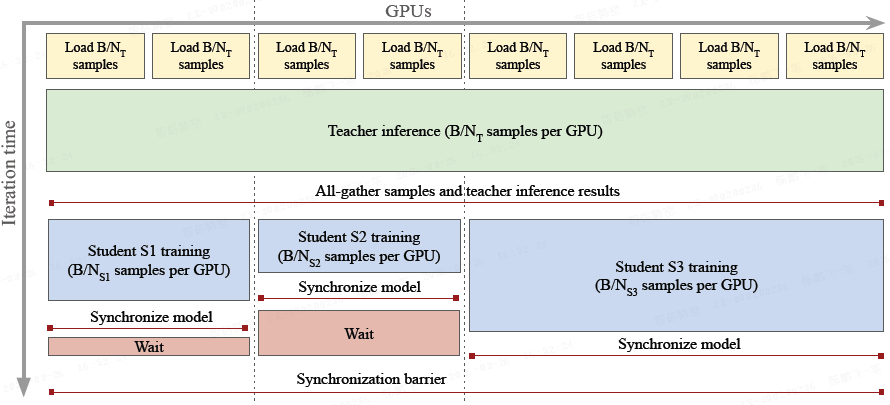
多学生蒸馏流程。在该图中,同时对 3 名学生进行蒸馏:
- 首先,将教师的推理结果在所有 T 节点之间共享以节省计算资源,并在所有 GPU 上收集输入和结果。
- 然后,较小的小组负责学生训练工作。
- 通过调整这些小组的规模,来确保所有学生在每个训练步骤中的持续时间相同,从而最大程度地减少在同步壁垒处等待的时间。
5.3 将 DINOv3 与文本对齐
虽然 CLIP 已经展现出了出色的零样本识别能力,但其对全局特征的侧重限制了其捕捉精细且局部对应关系的能力。
本文为 DINOv3 ViT-L 模型训练一个文本编码器,实现零样本能力。
(2025|CVPR|Meta,dino.txt,冻结 ViT,拼接类别和图像嵌入,基于对比的图文对齐,LiT)DINOv2 遇见文本:用于图像和像素的视觉语言对齐框架
遵循 dino.txt 的流程:
- 保持视觉编码器冻结,从零训练一个文本编码器,并利用对比学习将图像和文本特征对齐到共享空间。
- 为了在视觉方面留有一定的灵活性,在冻结的视觉骨干之上引入了两个 transformer 层。
- 该方法的一个关键改进之处在于,在将视觉嵌入与文本嵌入进行匹配之前,将均值池化的 patch embedding 与输出的 CLS token 进行连接。这使得能够将全局(CLS token)和局部(patch)的视觉特征与文本进行对齐,从而在密集预测任务中实现了性能的提升,且无需额外的规则或技巧。
6. 评估
DINOv3 在广泛的任务上进行了评估,证明其强大的密集特征和鲁棒的全局描述符能力。所有评估均使用冻结的视觉骨干网络,除非另有说明。
6.1 DINOv3 提供高质量密集特征

可视化: PCA 可视化显示,DINOv3 的特征比其他骨干网络(如 SigLIP 2, PEspatial, DINOv2)更清晰、噪声更少、语义一致性更强。
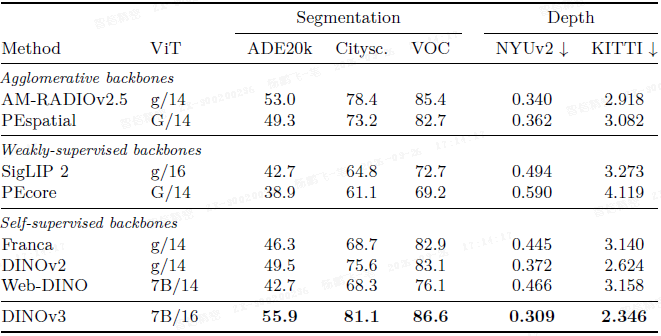
密集线性探测: 在 ADE20k(55.9 mIoU)、Cityscapes(81.1 mIoU)和 VOC(86.6 mIoU)语义分割上,DINOv3 显著优于所有自监督和弱监督基线,甚至超越了从 SAM 蒸馏的模型。在 NYUv2 和 KITTI 单目深度估计上,DINOv3 同样取得了最佳 RMSE。
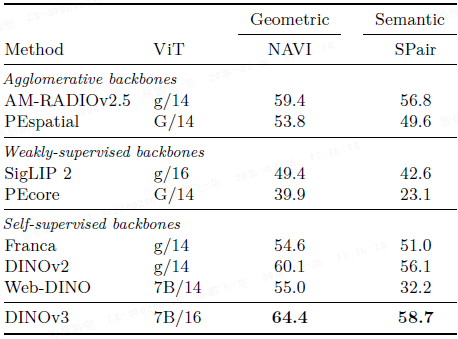
3D 对应估计: 在 NAVI(几何)和 SPair(语义)数据集上,DINOv3 在关键点匹配召回率(recall)上超过所有比较模型,表明其强大的 3D 感知能力。
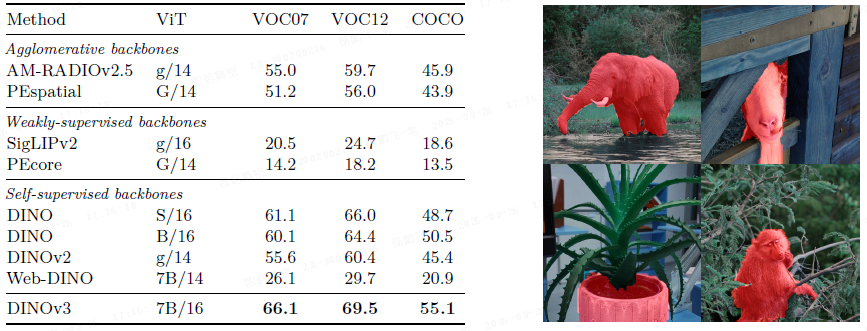
无监督对象发现: 在 VOC07/12 和 COCO20k 上,使用 TokenCut 算法,DINOv3 的 CorLoc 指标超越所有基线,包括原版 DINO,证明其特征兼具语义强度和良好的定位能力。
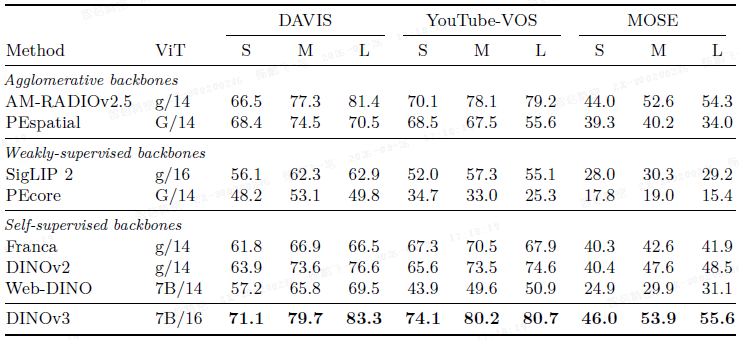

视频分割跟踪: 在 DAVIS、YouTube-VOS 和 MOSE 数据集上,DINOv3 的特征用于非参数标签传播,取得了最佳 J&F 分数,且随分辨率提高性能稳定增长,表明其时序一致性优越。
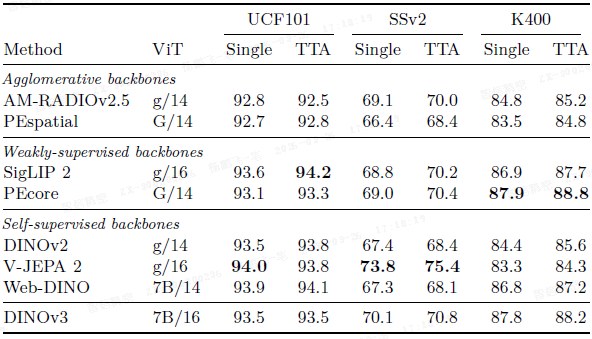
视频分类: 使用注意力探针,DINOv3 在 UCF101、Something-Something V2 和 Kinetics-400 上的表现与弱监督模型相当,优于其他 SSL 模型,适用于视频任务。
6.2 DINOv3 拥有鲁棒且通用的全局图像描述符
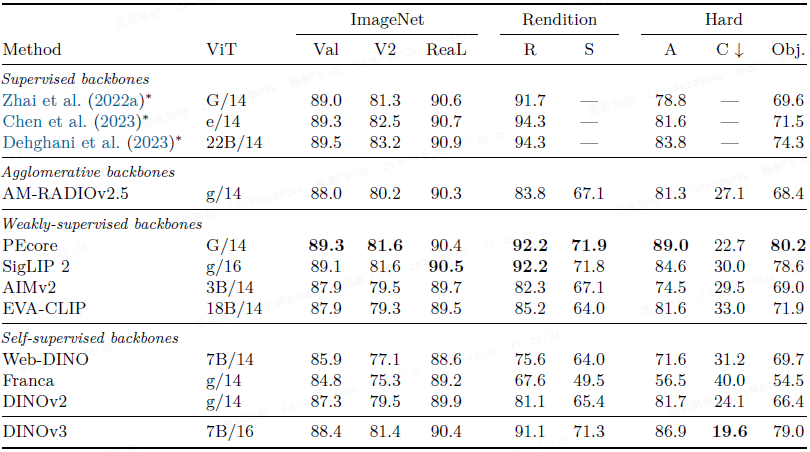
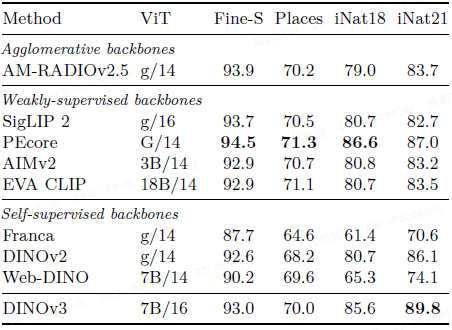
线性探测分类:
- 在 ImageNet 及其变体(V2, Real, Rendition, Sketch, Adversarial, ObjectNet, Corruption)上,DINOv3 的线性分类性能超越了所有之前的自监督模型,并首次在图像分类上与顶级弱监督模型(SigLIP 2, PE)持平。
- 在 iNaturalist21 等细粒度分类任务上,DINOv3 甚至超越了弱监督模型。
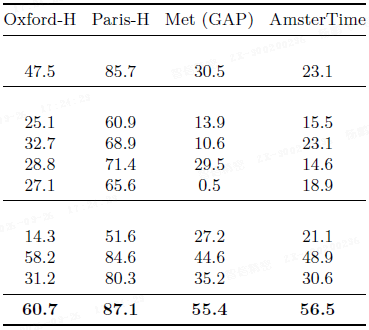
实例识别: 在牛津、巴黎、Met 和 AmsterTime 数据集上进行非参数检索,DINOv3 的表现远超其他模型,包括 DINOv2 和弱监督模型,展示了其强大的实例级识别能力。
6.3 DINOv3 作为复杂计算机视觉系统的基础
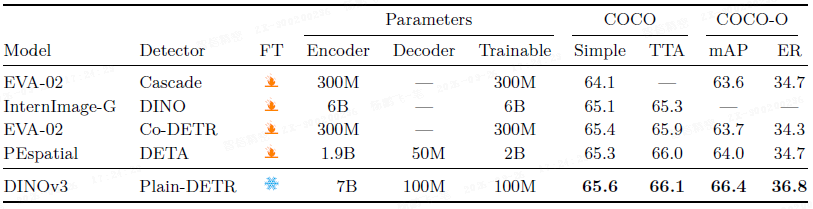
目标检测: 在冻结的 DINOv3 骨干网络上训练轻量级 Plain-DETR 解码器,在 COCO 和 COCO-O 数据集上达到了最先进的 mAP,且训练参数远少于其他系统。
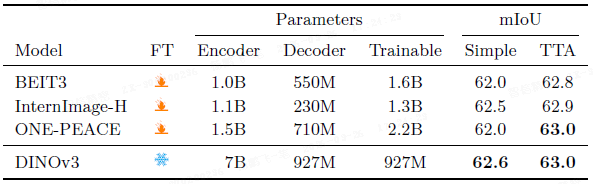
语义分割: 在冻结的 DINOv3 上训练 Mask2Former 解码器,在 ADE20k 上达到了 63.0 mIoU,与当前最先进水平持平,并在 COCO-Stuff 和 VOC2012 上创下新高。
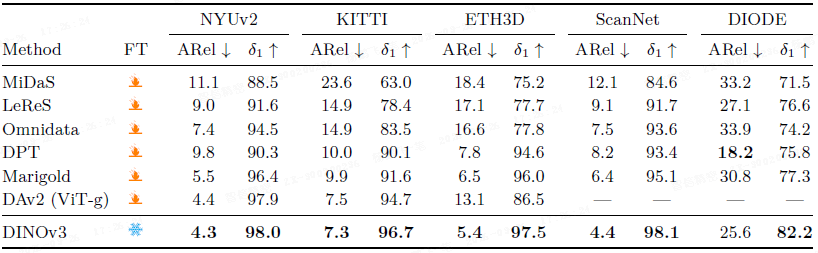
单目深度估计: 将 Depth Anything V2 中的 DINOv2 替换为 DINOv3(冻结),在 NYUv2、KITTI 等 5 个数据集上取得了新的最先进结果,证明了其强大的 Sim-to-Real 迁移能力。
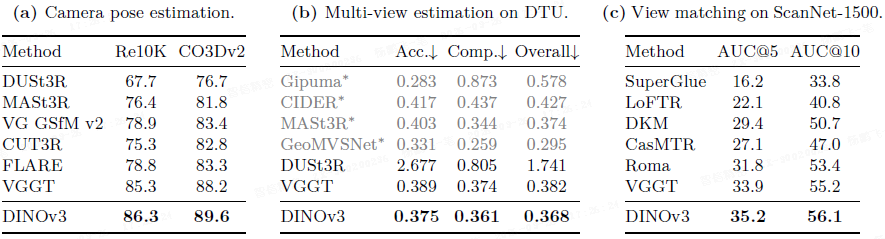
3D 理解 (VGGT): 将 VGGT 中的 DINOv2 替换为 DINOv3 ViT-L,在相机姿态估计、多视图深度估计和两视图匹配任务上均取得了一致的性能提升。
7. 评估完整的 DINOv3 模型家族
DINOv3 家族包括从 7B 教师蒸馏出的各种规模的 ViT 和 ConvNeXt 模型,覆盖不同计算预算。
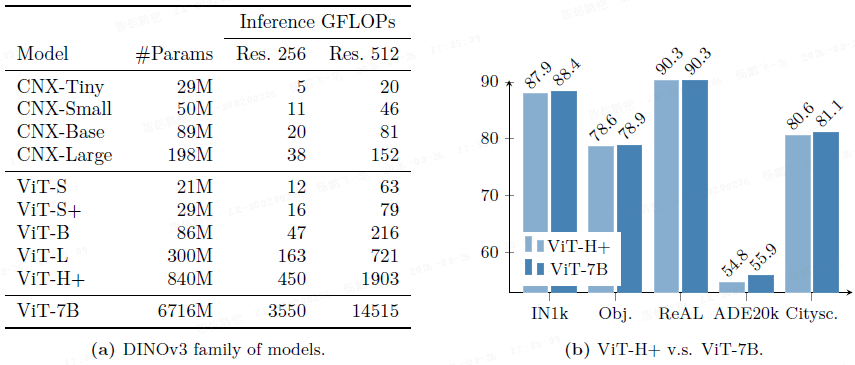
上图对比了 DINOv3 ViT-H+ 与其 7B 参数规模的教师模型,尽管参数数量少近 10 倍,但 ViT-H+ 的性能却与 DINOv3 7B 参数版本相当。
7.1 适用于各种场景的 Vision Transformer
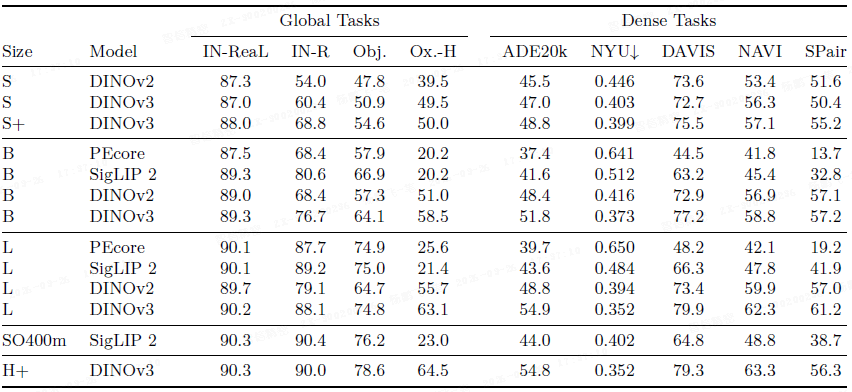
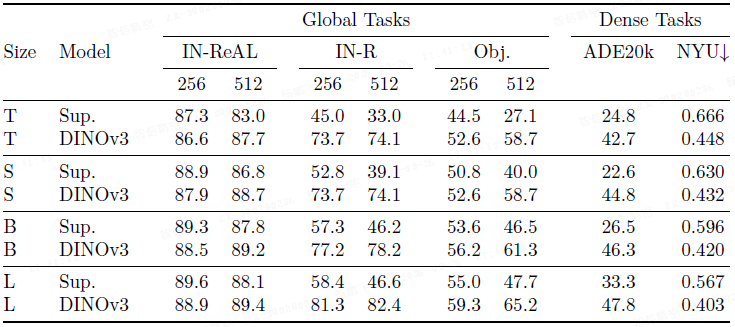
DINOv3 的 ViT-S, B, L, H+ 模型在密集任务上显著优于相同规模的 DINOv2、SigLIP 2 和 PE 模型。
- 例如,ViT-L 在 ADE20k 上比 DINOv2 高出 6 个 mIoU 点以上,同时保持了分类任务的竞争力。
- 最大的 ViT-H+ 学生模型性能接近其 7B 参数的教师模型。
7.2 适用于资源受限环境的 Efficient ConvNeXts
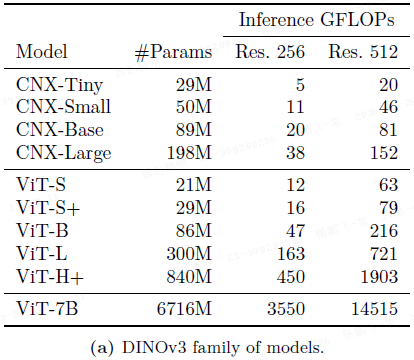
从 ConvNeXt 蒸馏出的 CNX(T, S, B, L)模型,在密集任务上相比监督式 ConvNeXt 有巨大提升(如 CNX-T 在 ADE20k 上 mIoU 从 24.8 提升至 42.7),同时保持了在 512 分辨率下的分类性能,且具有更好的鲁棒性。
7.3 基于 dino.txt 的 DINOv3 零样本推理
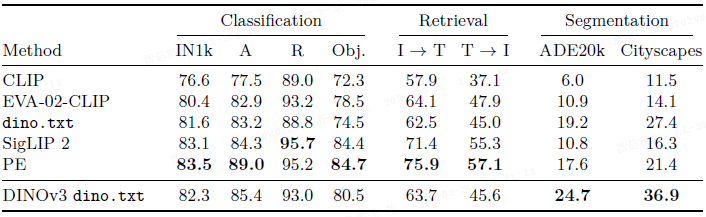
文本对齐后的 DINOv3 ViT-L 在零样本分类和图像-文本检索上表现有竞争力,同时在开放词汇分割(ADE20k, Cityscapes)上取得了领先的 mIoU,得益于其清晰的patch特征。
【注:更多应用结果见原论文】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)