一文读懂NVIDIA Dynamo:AI推理的“智能交通指挥官”
想象一下,你经营着一座繁忙的“AI工厂”,里面挤满了成千上万个GPU“工人”。每天都有海量的AI请求像车辆一样涌入,有的请求需要处理超长文本,有的则需要快速生成图像。如何高效地调度这些“工人”,让每辆车都走最短的路、花最少的钱、用最快的速度完成任务?这就是NVIDIA Dynamo要解决的核心问题。
简单来说,NVIDIA Dynamo是NVIDIA推出的一个开源、模块化的AI推理“交通指挥官”。它不是一个独立的AI模型,而是一个运行在GPU集群之上的智能软件框架,旨在将AI推理的效率、性能和成本优化提升到一个全新的水平。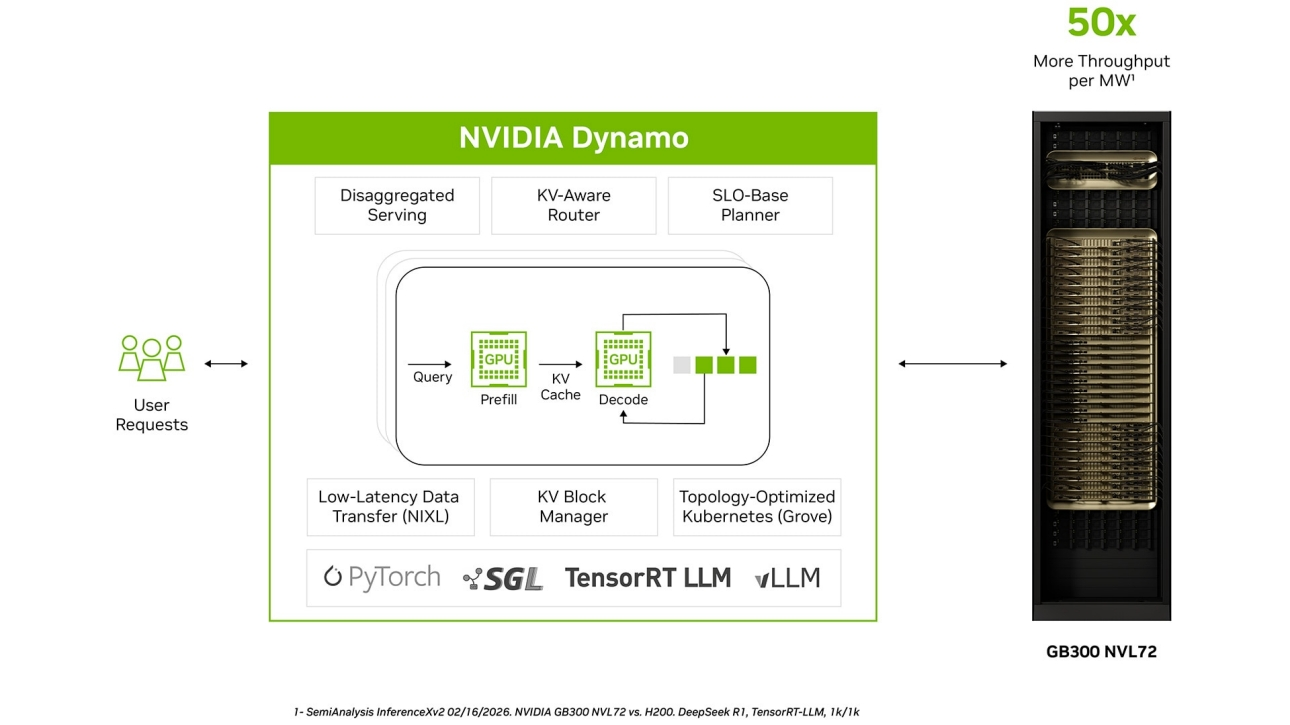
🤔 为什么我们需要Dynamo?
在Dynamo出现之前,部署大规模AI模型(尤其是大语言模型)面临着几大痛点:
- 资源浪费:传统的部署方式常常将所有计算任务堆在同一个GPU上,导致GPU在处理不同阶段的任务时,算力或显存出现闲置,利用率不高。
- 重复计算:当多个用户的请求内容相似时(例如,都问“今天天气如何?”),系统会傻傻地重复计算,浪费宝贵的算力。
- 扩展困难:随着用户量激增,如何平滑地增加GPU数量来应对流量,同时不破坏现有服务,是一个复杂的工程难题。
- 成本高昂:上述所有问题最终都指向一个结果——推理成本居高不下。
NVIDIA Dynamo正是为了解决这些挑战而生。它通过一系列创新技术,让AI推理变得更聪明、更高效。
🧩 Dynamo的核心“黑科技”
Dynamo的强大之处在于它包含了一系列协同工作的核心组件,每个组件都像一个专业的部门,共同保障“AI工厂”的高效运转。
-
分离式服务
这是Dynamo最核心的理念之一。它将AI生成回答的过程拆分为两个阶段:- 预填充(Prefill):理解你的问题(提示词),进行复杂的计算。
- 解码(Decode):一个字一个字地生成答案。
Dynamo可以将这两个阶段分配给不同类型的GPU。例如,用算力强的GPU专门处理“预填充”,用显存带宽高的GPU专门负责“解码”。这样,每个GPU都能“术业有专攻”,整体效率大幅提升。
-
KV感知路由器
你可以把它想象成一个超级智能的导航系统。它会“记住”之前处理过的请求内容(技术上称为KV Cache)。当一个新的请求到来时,它会先检查一下,如果发现有GPU已经“记住”了相关内容,就会直接把请求派给那个GPU,从而避免了重复计算,显著加快了响应速度。 -
KV块管理器
处理超长文本(比如一本书)时,中间数据(KV Cache)会大到连顶级GPU的显存都装不下。KV块管理器就像一个智能仓储系统,它会把不常用的数据从昂贵的GPU显存(HBM)自动“卸载”到更便宜的CPU内存(DRAM)甚至固态硬盘(SSD)上,需要时再快速取回。这使得处理超长上下文成为可能,且成本可控。 -
低延迟通信库
在“分离式服务”的架构下,负责“预填充”和“解码”的GPU之间需要频繁、快速地交换数据。NIXL就是为这个任务量身打造的“超高速数据通道”。它能在不同类型的内存和设备之间(如GPU到GPU,GPU到SSD)实现极低延迟的数据传输,确保整个流程顺畅无阻。 -
SLO规划器
这是一个自动化的资源调度中心。它会根据你设定的服务目标(例如,保证99%的请求在1秒内响应),实时监控流量和GPU负载。当流量高峰来临时,它会自动增加处理请求的GPU数量;当流量低谷时,它又会自动减少,从而实现成本与性能的最佳平衡。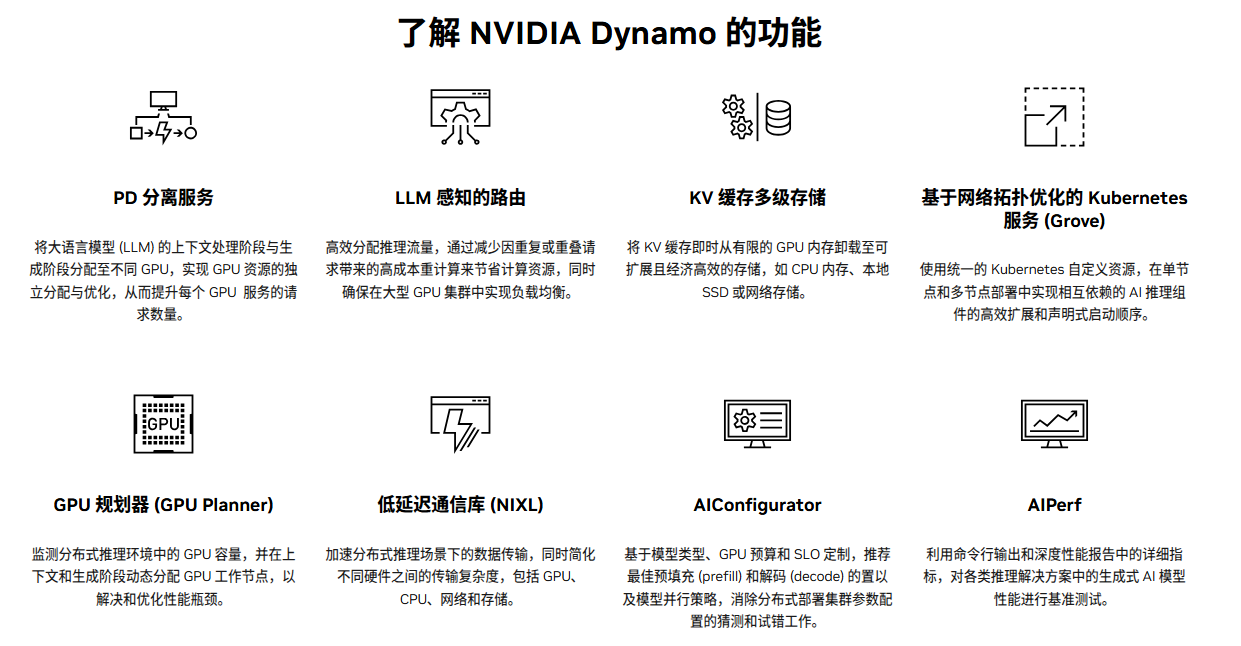
✨ Dynamo 1.0:从蓝图到量产
如果说早期的Dynamo版本是展示了美好的蓝图,那么2026年GTC大会上发布的Dynamo 1.0则标志着它已经是一个成熟、稳定、可用于大规模生产的“交钥匙”方案。
Dynamo 1.0带来了几个关键升级,进一步简化了部署并提升了性能:
- 模型极速启动:通过“检查点恢复”和“模型权重流”两项新功能,新启动的GPU实例不再需要从零开始加载庞大的模型文件。它可以从一个已经准备好的“快照”中瞬间恢复,或者从其他GPU直接通过高速网络接收模型数据。这使得大规模扩展时,新节点的启动速度提升了高达7倍。
- 零配置部署:全新的“Dynamo图部署请求”功能,让开发者只需在网页界面简单填写模型、硬件和性能目标,Dynamo就能自动生成最优的部署方案并一键启动,大大降低了使用门槛。
- 支持更多模型:除了大语言模型,Dynamo 1.0还原生支持了视频生成和多模态模型,展现了其强大的通用性。
🚀 实际效果:性能与成本的双重胜利
理论再美好,也需要实践检验。Dynamo在真实世界中已经取得了令人瞩目的成果:
- Workato:这家自动化平台公司在其AI工作流中部署Dynamo后,实现了每GPU吞吐量提升67%,端到端延迟降低79%,同时将模型成本降低了67%。
- 72B模型部署案例:一个技术团队在部署720亿参数的大模型时,利用Dynamo的分离式服务,在响应时间减半的同时,成功节约了50%的成本。
总而言之,NVIDIA Dynamo通过其智能的架构和一系列创新技术,正在成为大规模AI推理部署的新标准。它不仅解决了当前AI落地面临的性能和成本瓶颈,也为未来更复杂、更庞大的AI模型应用铺平了道路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)