【世界模型】Compositional Generative Model of Unbounded 4D Cities

标题:无边界四维城市的组合式生成模型
原文链接:https://arxiv.org/abs/2501.08983
源码链接:https://github.com/hzxie/CityDreamer4D?tab=readme-ov-file
发表:TPAMI-2026
摘要
近年来,三维场景生成受到了越来越多的关注并取得了显著进展。相较于三维场景,四维城市的生成难度更高,原因在于城市中存在建筑、车辆等结构复杂、视觉特征多样的物体,且人类对城市环境中的视觉畸变更为敏感。为解决上述问题,本文提出了CityDreamer4D——一款专为无界四维城市生成设计的组合式生成模型。本文的核心见解为:1)四维城市生成应将动态物体(如车辆)与静态场景(如建筑、道路)分离;2)四维场景中的所有物体均应由适用于建筑、车辆和背景元素的不同类型神经场构成。具体而言,本文提出了交通场景生成器和无界布局生成器,利用高度紧凑的鸟瞰视角(BEV)表示生成动态交通场景与静态城市布局。四维城市中的物体通过融合面向背景元素的神经场和面向实例的神经场生成,分别适配背景、建筑和车辆的生成需求。为契合背景元素与实例的独特特征,上述神经场采用定制化的生成式哈希网格和周期性位置嵌入作为场景参数化方式。此外,本文还构建了一套适用于城市生成的综合数据集,包括开放街道地图(OSM)数据集、谷歌地球(GoogleEarth)数据集和城市乌托邦(CityTopia)数据集。其中,OSM数据集提供了多种真实世界的城市布局,GoogleEarth数据集和CityTopia数据集则提供了带有三维实例标注的大规模、高质量城市影像。依托组合式设计,CityDreamer4D支持实例编辑、城市风格化、城市仿真等一系列下游任务,同时在生成真实感四维城市方面达到了当前最优的性能表现。
索引词
城市生成;四维生成;生成模型;神经辐射场(NeRF)
1 引言
在元宇宙快速发展的背景下,三维和四维资产生成受到了广泛关注。目前,研究人员在三维物体[1][2][3]、三维虚拟化身[4][5][6]、三维场景[7][8][9]以及四维物体[10][11]、四维虚拟化身[12][13][14]的生成领域均取得了显著成果。城市作为元宇宙中最重要的资产之一,被广泛应用于城市规划、环境仿真、游戏资产开发等各类场景。因此,让艺术家、研究人员、游戏玩家等更多人群能够便捷地进行三维/四维城市的构建,成为一项兼具重要性和实际价值的研究课题。
近年来,场景生成领域取得了诸多突破性进展。基于视频的方法[15][16][17]以输入图像为条件生成视频,进而实现三维场景生成,但这类方法无法保证时间一致性。基于外推的方法[18][19][20]通过对红、绿、蓝(RGB)图像和深度图像进行连续外推生成三维场景,却缺乏紧凑的场景表示,导致生成的场景规模通常较小。基于程序化内容生成(PCG)的方法[21][22][23]将大语言模型(LLMs)与程序化内容生成技术结合,实现了无界城市的生成,但其生成城市的多样性受限于所使用的三维资产。以GANCraft[24]和SceneDreamer[7]为代表的基于三维感知生成对抗网络(GAN)的方法,利用体神经渲染技术,结合三维坐标和对应的语义标签生成三维场景中的图像。这类方法通过利用SPADE[25]生成的伪真实图像,在三维自然场景生成中取得了良好的效果。InfiniCity[26]采用类似的流程进行三维城市生成,但相较于三维自然场景,三维城市生成的复杂度更高——建筑和车辆的外观变化更为丰富,而自然场景中同一语义标签对应的物体外观相对一致。这种外观的多样性会导致当同一类别下的所有实例被赋予相同语义标签时,生成的建筑和车辆质量下降。此外,四维场景生成比三维场景生成面临更大的挑战,现有方法[27][28][29][30]要么无法保证时间一致性,要么仅能生成小尺度的四维场景。
为解决上述问题,本文提出了适用于无界四维城市生成的组合式生成模型CityDreamer4D。如图1所示,该无界四维城市生成框架将动态物体与静态场景进行分离。静态场景由无界布局生成器生成的城市布局定义,布局中规划了道路、高速公路、植被、建筑等元素的位置,且能够外推至无界区域。动态物体(如车辆)由交通场景生成器生成的交通场景定义,交通场景将动态物体定位在由城市布局衍生的高精地图上。与现有将所有物体的生成整合在单个模块中的方法不同,CityDreamer4D将生成过程划分为三个独立的模块:建筑实例生成器、车辆实例生成器和城市背景生成器。这些生成器利用高度紧凑的鸟瞰视角(BEV)场景表示,保证了生成的效率和可扩展性。
本文的场景参数化设计充分考虑了背景元素与实例的独特特征:背景元素的外观通常具有相似性,且纹理不规则,而建筑和车辆的外观多样,且存在规则的周期性模式。为应对这些特征差异,本文为背景生成采用生成式哈希网格,为每个实例的生成应用周期性位置嵌入。同时,将建筑置于以物体为中心的坐标空间,将车辆置于物体规范坐标空间,并采用专门的方法捕捉其紧凑的形状特征。合成器将渲染后的背景元素与建筑、车辆实例融合,生成统一的图像。
为提升生成城市的真实感,本文构建了一套综合数据集,包括OSM、GoogleEarth和CityTopia数据集。其中,源自开放街道地图[31]的OSM数据集包含全球80座城市的语义地图和高度场,覆盖面积超过 6000 km 2 6000 \ \text{km}^2 6000 km2。语义地图标注了道路、建筑、城市绿地和水域的位置,高度场则主要表征建筑的高度。GoogleEarth数据集是利用谷歌地球工作室[32]收集的真实世界数据集,包含纽约市的400条无人机环绕飞行轨迹,共计24000张真实城市图像,所有类别均带有三维语义标注,建筑还带有三维实例标注。CityTopia数据集是基于虚幻引擎5的城市样本项目[33]中的三维资产生成的高质量合成数据集,覆盖11座城市,包含37500张高保真的街景和无人机视角图像,所有类别均带有精准的二维和三维语义标注,建筑和车辆还带有三维实例标注。
本文的研究贡献总结如下:
- 提出了CityDreamer4D,这是首个实现动态物体与静态场景解耦的无界四维城市生成模型,支持实例编辑、城市风格化和城市仿真等任务;
- 引入了面向背景元素的神经场和面向实例的神经场,用于生成四维场景中的背景元素和实例(建筑、车辆),有效捕捉了其视觉多样性;
- 构建了一套适用于城市生成的综合数据集,利用OSM数据集提供真实的城市布局,利用GoogleEarth和CityTopia数据集提供带有三维语义和实例标注的精细化城市视觉数据;
- 实验验证,所提出的CityDreamer4D在生成无界、多样化的四维城市方面具备优异的能力,且支持对生成城市进行实例级编辑。
本文的初步研究成果以CityDreamer为名发表于2024年计算机视觉与模式识别会议(CVPR 2024)[34],本研究在初步版本的基础上进行了多方面扩展:1)将CityDreamer升级为CityDreamer4D,通过引入交通场景生成器和车辆实例生成器实现四维城市生成,有效分离了动态物体与静态场景;2)对高度紧凑的BEV表示进行优化,增加了自下而上的高度图,能够表示城市中的中空结构(如高速公路);3)提出了交通场景生成器,基于城市布局生成高精地图,进而在无界城市中生成真实的交通场景和车辆分布;4)提出了车辆实例生成器,基于规范特征空间的新型场景参数化方法,实现城市中车辆实例的生成;5)构建了CityTopia数据集,提供了近4万张带有二维和三维语义、实例标注的高质量街景和无人机视角图像。
2 相关工作
2.1 三维感知生成对抗网络
依托二维生成对抗网络[35][36]的近期研究成果,研究人员提出了多种利用生成对抗网络生成三维内容的方法。这类方法的核心思想是采用三维表示刻画生成的场景,并通过渲染技术从不同视角生成图像,从而实现图像级的对抗学习[37]。早期方法采用体素[38][39][40]、网格[41]、三维基元[42]等显式形状表示,从不同视角渲染图像,但这类表示的表达能力和效率有限,难以合成复杂场景和具有照片真实感的细节。以高保真新视角合成为优势的神经辐射场(NeRF)[43]被引入三维感知生成模型中,然而基于神经辐射场的生成对抗网络计算成本较高,限制了早期相关研究[44][45][46][47]生成高质量图像。为解决这一问题,后续诸多研究[48][49][50][51][52]通过对低分辨率特征图进行二维超分辨率处理,避免了高分辨率的神经辐射场渲染,但这一做法会损失三维一致性。为严格保证三维一致性,新的研究方法转向稀疏三维表示,如稀疏体素[53]、辐射流形[54]、多平面图像[55],实现了直接的高分辨率渲染。尽管如此,这类方法大多基于针对有界场景构建的数据集进行训练,例如人脸[56][57]、人体[58][59]和物体[60][61]数据集。
2.2 三维场景生成
先进的二维生成模型主要聚焦于单一类别或常见物体的生成,而场景级内容的生成面临更大挑战,原因在于场景具有极高的多样性和复杂性[62]。早期方法[15][16]通过合成视频生成场景,但缺乏三维感知能力,无法保证三维一致性。语义图像合成方法[24][63]通过以像素级稠密对应关系(如语义分割图、深度图)为条件,在场景级内容生成中取得了良好效果。部分技术[18][19][20]通过对红、绿、蓝(RGB)图像或特征图进行内插和外推生成三维场景,但大多数方法仅能从输入视角进行有限距离的插值或外推,不具备真正的生成能力。已有大量研究将程序化内容生成(PCG)应用于自然场景[21][64]、室内场景[65][66][67]和城市场景[23][68][69][70]的生成,但生成场景的多样性受限于所使用的三维资产。近期研究方法[7][9][26]通过无界布局外推,实现了无限尺度的三维一致性场景生成。其他方法[71][72][73]聚焦于室内场景合成,依赖于成本高昂的三维数据集[74][75]或计算机辅助设计(CAD)物体检索技术[76][77][78]。
2.3 四维场景生成
近年来,研究人员提出了动态神经辐射场(D-NeRF)[79]、可变形三维高斯体[80]等表示方法,应用于四维物体和人体的生成。然而,四维场景生成仍处于发展初期,原因在于现有表示方法并非为大尺度场景生成设计。主流方法通常将四维场景生成转化为四维占据率生成[81][82],并通过视频扩散模型蒸馏实现[27][28][29][30],但这类方法缺乏紧凑的表示形式,限制了生成场景的尺度。
3 方法
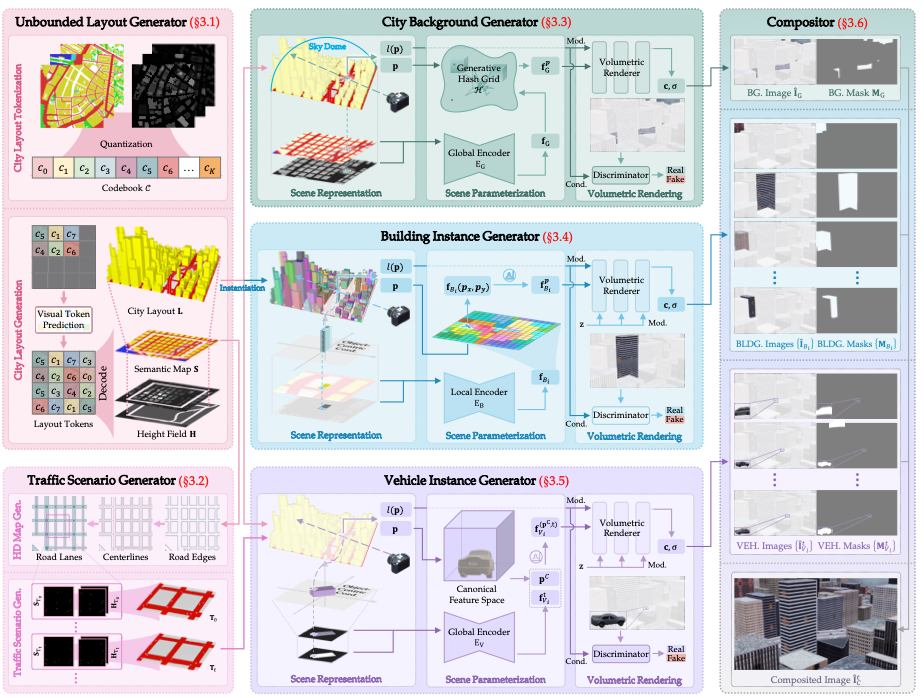
图1 CityDreamer4D模型整体框架。四维城市生成包含静态场景与动态场景两部分,其生成过程分别以无界布局生成器输出的城市布局 L L L、交通场景生成器输出的时变交通场景 T t T_t Tt为条件。城市背景生成器利用城市布局 L L L,生成道路、植被、天空等背景元素的图像 I ^ G \hat{I}_{G} I^G;建筑实例生成器则对城市内的建筑实例 { I ^ B i } \{\hat{I}_{B_{i}}\} {I^Bi}完成渲染。车辆实例生成器以时变交通场景 T t T_t Tt为依据,在时间步 t t t生成车辆实例 { I ^ V i t } \{\hat{I}_{V_{i}}^{t}\} {I^Vit}。最终由合成器将渲染后的背景、建筑实例与车辆实例融合,生成单张统一且连贯的图像 I ^ C t \hat{I}_{C}^{t} I^Ct。文中标注的“Gen.”“Mod.”“Cond.”“BG.”“BLDG.”“VEH.”分别为“Generation(生成)”“Modulation(调制)”“Condition(条件)”“Background(背景)”“Building(建筑)”“Vehicle(车辆)”的缩写。
如图1所示,CityDreamer4D将无界四维城市生成解耦为静态场景生成和动态物体生成两个部分。在静态场景生成阶段,无界布局生成器(3.1节)生成任意尺度的城市布局 L L L;随后,城市背景生成器(3.3节)生成背景图像 I ^ G \hat{I}_{G} I^G及其对应的掩码 M G M_{G} MG;接着,建筑实例生成器(3.4节)生成建筑实例的图像 I ^ B i i = 1 n B {\hat{I}_{B_{i}}}_{i=1}^{n_{B}} I^Bii=1nB及其对应的掩码 M B i i = 1 n B {M_{B_{i}}}_{i=1}^{n_{B}} MBii=1nB,其中 n B n_B nB为建筑实例的数量。在动态物体生成阶段,交通场景生成器(3.2节)首先为时间步 t t t生成交通场景 T t T_{t} Tt;然后,车辆实例生成器(3.5节)基于 T t T_{t} Tt生成本时间步车辆实例的图像 I ^ V i t i = 1 n V {\hat{I}_{V_{i}}^{t}}_{i=1}^{n_{V}} I^Viti=1nV及其对应的掩码 M V i t i = 1 n V {M_{V_{i}}^{t}}_{i=1}^{n_{V}} MViti=1nV,其中 n V n_{V} nV为车辆实例的数量。最后,合成器(3.6节)将渲染后的背景、建筑实例和车辆实例融合,生成时间步 t t t的统一连贯图像 I C t I_{C}^{t} ICt。
3.1 无界布局生成器
城市布局表示
城市布局定义了城市中静态三维物体的位置,这些物体被划分为道路、高速公路、建筑、植被、水域等类别,同时引入空类别表征三维空间中的空白区域。CityDreamer4D中,城市布局以三维体 L L L表示,由语义地图 S L S_{L} SL的像素根据其在高度场 H L = H ‾ L B U , H L T D H_{L}={\overline{H}_{L}^{BU}, H_{L}^{TD}} HL=HLBU,HLTD中的对应值拉伸得到,其中 H L B U H_{L}^{BU} HLBU和 H L T D H_{L}^{TD} HLTD分别表示自下而上的高度和自上而下的高度。具体而言, L L L在坐标 ( i , j , k ) (i, j, k) (i,j,k)处的取值定义为:
L ( i , j , k ) = { S L ( i , j ) i f H L B U ( i , j ) ≤ k ≤ H L T D ( i , j ) 0 o t h e r w i s e ( 1 ) L(i, j, k)=\left\{ \begin{array} {ll}{S_{L}(i, j)}&{if \ H_{L}^{BU}(i, j) \leq k\leq H_{L}^{TD}(i, j)}\\ {0}&{otherwise}\end{array} \right. (1) L(i,j,k)={SL(i,j)0if HLBU(i,j)≤k≤HLTD(i,j)otherwise(1)
其中,0表示三维体中的空白区域。
城市布局生成
无界城市布局的生成被转化为可扩展语义地图和高度场的生成问题。为实现这一目标,本文基于MaskGIT[83]设计了无界布局生成器,该模型天然支持图像内插和外推。具体而言,本文利用矢量量化变分自编码器(VQVAE)[84]对语义地图和高度场的图像块进行令牌化,将其编码至带有码本 C = c k ∣ c k ∈ R d C k = 1 d K C={c_{k} | c_{k} \in \mathbb{R}^{d_{C}}}_{k=1}^{d_{K}} C=ck∣ck∈RdCk=1dK的离散潜空间。在推理阶段,布局令牌通过自回归方式生成,再由矢量量化变分自编码器的解码器重建出语义地图 S L S_{L} SL和高度场 H L H_{L} HL。由于矢量量化变分自编码器的输出尺寸固定,本文通过图像外推生成任意尺度的布局,具体采用重叠率为25%的滑动窗口,在每一步迭代预测局部布局令牌。
损失函数
矢量量化变分自编码器将高度场和语义地图的生成分解为两个独立任务,分别采用L1损失和交叉熵损失 ε \varepsilon ε进行优化。为提升建筑边缘附近高度场的清晰度,本文额外引入了平滑损失 s s s[85],总损失定义为:
ℓ V Q = λ R ∥ H ^ L p − H L p ∥ + λ S S ( H ^ L p , H L p ) + λ E E ( S ^ L p , S L p ) \ell_{VQ}=\lambda_{R}\left\| \hat{H}_{L}^{p}-H_{L}^{p}\right\| +\lambda_{S} \mathcal{S}\left(\hat{H}_{L}^{p}, H_{L}^{p}\right)+\lambda_{E} \mathcal{E}\left(\hat{S}_{L}^{p}, S_{L}^{p}\right) ℓVQ=λR
H^Lp−HLp
+λSS(H^Lp,HLp)+λEE(S^Lp,SLp)
其中, H ^ L p \hat{H}_{L}^{p} H^Lp和 S ^ L p \hat{S}_{L}^{p} S^Lp分别表示生成的高度场和语义地图图像块, H L p H_{L}^{p} HLp和 S L p S_{L}^{p} SLp为对应的真实值。MaskGIT中的自回归变换器采用重加权的证据下界(ELBO)损失[86]进行优化。
3.2 交通场景生成器
交通场景表示
城市布局 L L L定义了无界城市的静态元素,而交通场景则刻画了城市的动态特征,交通场景表示为 T = T t t = 1 n T T={T_{t}}_{t=1}^{n_{T}} T=Ttt=1nT,其中 n T n_{T} nT为帧数。与城市布局 L L L类似, T t T_{t} Tt同样由语义地图 S T t S_{T_{t}} STt和高度场 H T t = H T t B U , H T t T D H_{T_{t}}={H_{T_{t}}^{BU}, H_{T_{t}}^{TD}} HTt=HTtBU,HTtTD推导得到,其中语义地图标注了动态物体的位置,高度场定义了动态物体的高程。具体而言, T t T_{t} Tt在坐标 ( i , j , k ) (i, j, k) (i,j,k)处的取值为:
T t ( i , j , k ) = { S T t ( i , j ) i f H T t B U ( i , j ) ≤ k ≤ H T t T D ( i , j ) 0 o t h e r w i s e T_{t}(i, j, k)= \begin{cases}S_{T_{t}}(i, j) & if \ H_{T_{t}}^{BU}(i, j) \leq k \leq H_{T_{t}}^{TD}(i, j) \\ 0 & otherwise \end{cases} Tt(i,j,k)={STt(i,j)0if HTtBU(i,j)≤k≤HTtTD(i,j)otherwise
其中,0表示三维体中的空白区域。
交通场景生成
交通场景 T T T的生成被定义为逐帧生成语义地图 S T = S T t t = 1 n T S_{T}={S_{T_{t}}}_{t=1}^{n^{T}} ST=STtt=1nT和高度场 H T = H T t t = 1 n T H_{T}={H_{T_{t}}}_{t=1}^{n^{T}} HT=HTtt=1nT的过程。为保证动态物体放置的真实性和连续性,本文基于城市布局 L L L生高精(HD)地图。与仅标注道路和高速公路位置的城市布局不同,高精地图包含车道、交叉口、交通信号灯等细节信息。利用生成的高精地图,通过成熟的开源模型[87]确定动态物体在每一帧的边界框,并基于该边界框生对应的语义地图和高度场。
高精地图生成
在高精地图的构建中,本文采用韦莫运动数据集(Waymo Motion)[88]中的实体定义,包括道路边缘、车道、道路标线、停车标志和交通信号灯,各实体的生成方式如下:
- 道路边缘:表征道路的边界,通过对 S L S_{L} SL进行坎尼边缘检测[89]得到连续边缘,再通过矢量化将其转化为图结构,具体包括角点检测和角点的顺序连接;
- 车道:表征车辆可行驶的车道中心线,通过对 S L S_{L} SL进行骨架提取[90]得到道路结构,并识别多边缘交汇的交叉口,再通过基于图的遍历将图像转化为道路中心线图;车道的数量和位置由道路宽度确定,交叉口处的车道通过贝塞尔曲线连接;
- 道路标线:如单白实线、双黄实线等,根据车道的位置和属性生成;
- 停车标志和交通信号灯:布置在多条车道交汇的交叉口位置。
3.3 城市背景生成器
场景表示
本文借鉴SceneDreamer[7]的方法,采用鸟瞰视角(BEV)表示场景,该表示方式兼具效率和表达能力,尤其适用于无界场景。与GANCraft[24]和InfiniCity[26]在体素顶点处对特征进行参数化不同,本文的鸟瞰视角表示利用由高度场和语义地图构建的无特征三维体,构建方式如公式(1)所示。具体而言,从城市布局 L L L中提取分辨率为 N G H × N G W × N G D N_{G}^{H} ×N_{G}^{W} ×N_{G}^{D} NGH×NGW×NGD的局部窗口,该局部窗口 L G ~ L^{\tilde{G}} LG~由对应的高度场 H L G H_{L}^{G} HLG和语义地图 S L G S_{L}^{G} SLG生成。
场景参数化
为实现跨场景的通用三维表示学习,并使内容与三维语义对齐,需要将场景表示参数化至潜空间,从而降低对抗学习的难度。针对背景元素,本文采用生成式神经哈希网格[7],通过对三维空间之外的高维空间建模,学习跨场景的通用特征。具体而言,首先利用全局编码器 E G E_{G} EG对局部场景 ( H L G , S L G ) (H_{L}^{G}, S_{L}^{G}) (HLG,SLG)进行编码,生成紧凑的场景级特征 f G ∈ R d G f_{G} \in \mathbb{R}^{d_{G}} fG∈RdG,即:
f G = E G ( H L G , S L G ) ( 4 ) f_{G}=E_{G}\left(H_{L}^{G}, S_{L}^{G}\right) (4) fG=EG(HLG,SLG)(4)
利用可学习的神经哈希函数 H \mathcal{H} H,将三维位置 p ∈ R 3 p \in \mathbb{R}^{3} p∈R3映射至高维空间 R 3 + d G → R N G C \mathbb{R}^{3+d_{G}} \to \mathbb{R}^{N_{G}^{C}} R3+dG→RNGC,得到该位置的索引特征 f G P f_{G}^{P} fGP,即:
f G p = H ( p , f G ) = ( ⨁ i = 1 d G f G i π i ⨁ j = 1 3 p j π j ) m o d N E f_{G}^{p}=\mathcal{H}\left(p, f_{G}\right)=\left(\bigoplus_{i=1}^{d_{G}} f_{G}^{i} \pi^{i} \bigoplus_{j=1}^{3} p^{j} \pi^{j}\right) mod N_{E} fGp=H(p,fG)=(i=1⨁dGfGiπij=1⨁3pjπj)modNE
其中, ⊕ \oplus ⊕表示按位异或操作, π i \pi^{i} πi和 π j \pi^{j} πj为互不相同的大素数。为捕捉多尺度特征,本文构建了 N H L N_{H}^{L} NHL层的多分辨率哈希网格,每层包含最多 N E N_{E} NE个条目, N G C N_{G}^{C} NGC表示每个特征向量的通道数。
体渲染
在透视相机模型中,图像中的每个像素都对应一条相机射线 r ( t ) = o + t v r(t)=o+t v r(t)=o+tv,该射线从投影中心 o o o出发,沿方向 v v v延伸。像素值 C ( r ) C(r) C(r)通过沿该射线的积分计算得到,即:
C ( r ) = ∫ 0 ∞ A ( t ) c ( f G r ( t ) , l ( r ( t ) ) ) σ ( f G r ( t ) ) d t C(r)=\int_{0}^{\infty} A(t) c\left(f_{G}^{r(t)}, l(r(t))\right) \sigma\left(f_{G}^{r(t)}\right) d t C(r)=∫0∞A(t)c(fGr(t),l(r(t)))σ(fGr(t))dt
其中, A ( t ) = exp ( − ∫ 0 t σ ( f G r ( s ) ) d s ) A(t)=\exp (-\int_{0}^{t} \sigma(f_{G}^{r(s)}) d s) A(t)=exp(−∫0tσ(fGr(s))ds)为累积透射率, l ( p ) l(p) l(p)表示三维位置 p p p处的语义标签, c c c和 σ \sigma σ分别对应颜色和体密度。
损失函数
城市背景生成器采用融合重建损失和对抗损失的混合目标函数进行优化,具体包括L1损失、感知损失 P \mathcal{P} P[91]和生成对抗网络损失 G \mathcal{G} G[92],总损失定义为:
ℓ G = λ G L 1 ∥ I ^ G − I G ∥ + λ G P P ( I ^ G , I G ) + λ G G G ( I ^ G , S G ) \ell_{G}=\lambda_{G}^{L 1}\left\| \hat{I}_{G}-I_{G}\right\| +\lambda_{G}^{P} \mathcal{P}\left(\hat{I}_{G}, I_{G}\right)+\lambda_{G}^{G} \mathcal{G}\left(\hat{I}_{G}, S_{G}\right) ℓG=λGL1
I^G−IG
+λGPP(I^G,IG)+λGGG(I^G,SG)
其中, I G I_{G} IG为真实背景图像, S G S_{G} SG为透视视角的语义地图,由沿每条射线对 L G ~ L^{\tilde{G}} LG~中的语义标签采样并累加得到; λ G L 1 \lambda_{G}^{L 1} λGL1、 λ G P \lambda_{G}^{P} λGP和 λ G G \lambda_{G}^{G} λGG为三个损失的权重。需注意,该损失仅作用于语义标签为背景元素的像素。
3.4 建筑实例生成器
场景表示
建筑实例生成器同样采用鸟瞰视角(BEV)的场景表示方式,从城市布局 L L L中提取分辨率为 N B H × N B W × N B D N_{B}^{H} ×N_{B}^{W} ×N_{B}^{D} NBH×NBW×NBD的局部窗口 L B i L^{B_{i}} LBi,该窗口以建筑实例 B i B_{i} Bi的二维坐标 ( c x B i , c y B i ) (c_{x}^{B_{i}}, c_{y}^{B_{i}}) (cxBi,cyBi)为中心。构建 L B i L^{B_{i}} LBi所用的高度场和语义地图分别表示为 H L B i H_{L}^{B_{i}} HLBi和 S L B i S_{L}^{B_{i}} SLBi。由于 S L S_{L} SL中所有建筑共享同一个语义标签,本文通过连通域检测实现建筑的实例化。值得注意的是,真实世界中建筑的外立面和屋顶呈现出截然不同的视觉分布特征,为捕捉这一特征,本文在 L B i L^{B_{i}} LBi中为每个建筑实例 B i B_{i} Bi的外立面和屋顶分配不同的语义标签,其中屋顶被分配至最顶层体素,其余建筑实例则被赋值为0以排除在 L B i L^{B_{i}} LBi之外。
场景参数化
与城市背景生成器不同,建筑实例生成器采用独特的场景参数化方式,通过编码器 E B E_{B} EB对局部场景 ( H L B i , S L B i ) (H_{L}^{B_{i}}, S_{L}^{B_{i}}) (HLBi,SLBi)进行编码,生成分辨率为 N B H × N B W × N B C N_{B}^{H} \times N_{B}^{W} ×N_{B}^{C} NBH×NBW×NBC的像素级特征 f B f_{B} fB,即:
f B i = E B ( H L B i , S L B i ) ( 8 ) f_{B_{i}}=E_{B}\left(H_{L}^{B_{i}}, S_{L}^{B_{i}}\right) (8) fBi=EB(HLBi,SLBi)(8)
对于三维位置 p = ( p x , p y , p z ) p=(p_{x}, p_{y}, p_{z}) p=(px,py,pz),其对应的特征 f B i p f_{B_{i}}^{p} fBip计算方式为:
f B i p = O ( C o n c a t ( f B i ( p x , p y ) , p z ) ) f_{B_{i}}^{p}=\mathcal{O}\left(Concat\left(f_{B_{i}}\left(p_{x}, p_{y}\right), p_{z}\right)\right) fBip=O(Concat(fBi(px,py),pz))
其中, C o n c a t ( ⋅ ) Concat(\cdot) Concat(⋅)表示拼接操作, f B i ( p x , p y ) ∈ R N B C f_{B_{i}}(p_{x}, p_{y}) \in \mathbb{R}^{N_{B}^{C}} fBi(px,py)∈RNBC为坐标 ( p x , p y ) (p_{x}, p_{y}) (px,py)对应的特征向量, O ( ⋅ ) \mathcal{O}(\cdot) O(⋅)为标准神经辐射场(NeRF)[43]中采用的位置编码函数,其定义为:
O ( x ) = { s i n ( 2 i π x ) , c o s ( 2 i π x ) } i = 0 N P L − 1 ( 10 ) \mathcal{O}(x)=\left\{sin \left(2^{i} \pi x\right), cos \left(2^{i} \pi x\right)\right\}_{i=0}^{N_{P}^{L}-1} \quad(10) O(x)={sin(2iπx),cos(2iπx)}i=0NPL−1(10)
需注意, O ( ⋅ ) \mathcal{O}(\cdot) O(⋅)会独立作用于特征 x x x的每个元素,且元素值会被归一化至 [ − 1 , 1 ] [-1, 1] [−1,1]区间。
体渲染
与城市背景生成器的体渲染方式不同,建筑实例生成器引入了风格码 Z Z Z以捕捉建筑外观的多样性,像素值 C ( r ) C(r) C(r)通过积分过程计算得到:
C ( r ) = ∫ 0 ∞ A ( t ) c ( f B i r ( t ) , z , l ( r ( t ) ) ) σ ( f B i r ( t ) ) d t ( 11 ) C(r)=\int_{0}^{\infty} A(t) c\left(f_{B_{i}}^{r(t)}, z, l(r(t))\right) \sigma\left(f_{B_{i}}^{r(t)}\right) d t \quad(11) C(r)=∫0∞A(t)c(fBir(t),z,l(r(t)))σ(fBir(t))dt(11)
其中, r ( t ) = o + t v − [ c x B i , c y B i , 0 ] T r(t)=o+t v-[c_{x}^{B_{i}}, c_{y}^{B_{i}}, 0]^{T} r(t)=o+tv−[cxBi,cyBi,0]T,该变换用于将建筑置于其局部坐标系统的中心位置。
损失函数
建筑实例生成器的训练仅采用生成对抗网络损失 G \mathcal{G} G,损失函数定义为:
ℓ B = G ( I ^ B i , S B i ) ( 12 ) \ell_{B}=\mathcal{G}\left(\hat{I}_{B_{i}}, S_{B_{i}}\right) \quad(12) ℓB=G(I^Bi,SBi)(12)
其中, S B S_{B} SB为建筑实例 B i B_{i} Bi的透视视角语义地图,生成方式与 S G S_{G} SG一致。需注意,该损失仅作用于语义标签为对应建筑实例的像素。
3.5 车辆实例生成器
场景表示
与建筑实例生成器类似,车辆实例生成器同样采用鸟瞰视角(BEV)的场景表示方式,从交通场景 T t T_{t} Tt中提取分辨率为 N V H × N V W × N V D N_{V}^{H} ×N_{V}^{W} ×N_{V}^{D} NVH×NVW×NVD的局部窗口 T t V i T_{t}^{V_{i}} TtVi,用于生成本场景中的车辆实例,该窗口以车辆实例 V i V_{i} Vi的二维坐标 ( c x V i , c y V i ) (c_{x}^{V_{i}}, c_{y}^{V_{i}}) (cxVi,cyVi)为中心。构建 T t V i T_{t}^{V_{i}} TtVi所用的高度场和语义地图分别表示为 H T i V i H_{T_{i}}^{V_{i}} HTiVi和 S T t V i S_{T_{t}}^{V_{i}} STtVi。与建筑不同,车辆实例在交通场景生成阶段已完成实例化,除 V i V_{i} Vi外的其他实例均被赋值为0以排除在 T t V i T_{t}^{V_{i}} TtVi之外。
场景参数化
相较于建筑实例,车辆实例的结构规则性更强,且外观特征与其相对位置高度相关。例如,同一车辆的车头、车尾和车身外观特征迥异,但这些结构特征在不同车辆间具有一致性。基于这一观察,本文提出了一种基于规范特征空间的场景参数化方法。对于三维位置 p = ( p x , p y , p z ) p=(p_{x}, p_{y}, p_{z}) p=(px,py,pz),其规范点 p C p^{C} pC的计算方式为:
p C = R ( p − [ c x V i , c y V i , c z V i ] T ) p^{C}=R\left(p-\left[c_{x}^{V_{i}}, c_{y}^{V_{i}}, c_{z}^{V_{i}}\right]^{T}\right) pC=R(p−[cxVi,cyVi,czVi]T)
其中, c x V i c_{x}^{V_{i}} cxVi、 c y V i c_{y}^{V_{i}} cyVi、 c z V i c_{z}^{V_{i}} czVi分别为车辆 V i V_{i} Vi在 x x x、 y y y、 z z z轴上的中心坐标, R R R为用于将三维点归一化至规范特征空间的旋转矩阵,其定义为:
R = [ c o s θ s i n θ 0 − s i n θ c o s γ c o s θ c o s γ s i n γ s i n θ s i n γ − c o s θ s i n γ c o s γ ] R=\left[\begin{array}{ccc} cos \theta & sin \theta & 0 \\ -sin \theta cos \gamma & cos \theta cos \gamma & sin \gamma \\ sin \theta sin \gamma & -cos \theta sin \gamma & cos \gamma\end{array}\right] R=
cosθ−sinθcosγsinθsinγsinθcosθcosγ−cosθsinγ0sinγcosγ
其中, θ ∈ ( − 180 ∘ , 180 ∘ ] \theta \in(-180^{\circ}, 180^{\circ}] θ∈(−180∘,180∘]为偏航角,表示车辆在 X Y XY XY平面内相对于 − y -y −y轴的行驶方向; γ ∈ ( − 90 ∘ , 90 ∘ ) \gamma \in(-90^{\circ}, 90^{\circ}) γ∈(−90∘,90∘)为俯仰角,正值和负值分别表示车辆相对于 X Y XY XY平面向上和向下倾斜。车辆 V i V_{i} Vi在时间步 t t t、规范点 p C p^{C} pC处对应的特征 f V i ( p C , t ) f_{V_{i}}^{(p^{C}, t)} fVi(pC,t)推导方式为:
f V i ( p C , t ) = O ( C o n c a t ( f V i t , p C ) ) f_{V_{i}}^{\left(p^{C}, t\right)}=\mathcal{O}\left(Concat\left(f_{V_{i}}^{t}, p^{C}\right)\right) fVi(pC,t)=O(Concat(fVit,pC))
其中, f V i t ∈ R d V f_{V_{i}}^{t} \in \mathbb{R}^{d_{V}} fVit∈RdV为全局编码器 E V E_V EV对局部场景 ( H ˙ T t V i , S T t V i ) (\dot{H}_{T_{t}}^{V_{i}}, S_{T_{t}}^{V_{i}}) (H˙TtVi,STtVi)提取得到的特征,即:
f V i t = E V ( H T t V i , S T t V i ) f_{V_{i}}^{t}=E_{V}\left(H_{T_{t}}^{V_{i}}, S_{T_{t}}^{V_{i}}\right) fVit=EV(HTtVi,STtVi)
体渲染
车辆实例生成器的体渲染方式与建筑实例生成器一致,引入风格码 Z Z Z以表示车辆外观的多样性,像素值 C ( r ) C(r) C(r)通过公式(11)所示的积分过程计算,相机射线 r ( t ) r(t) r(t)则根据公式(13)归一化至规范特征空间。
损失函数
车辆实例生成器采用融合重建损失和对抗损失的混合目标函数进行优化,具体训练过程中引入L1损失、感知损失 P \mathcal{P} P和生成对抗网络损失 G \mathcal{G} G,以平衡生成结果的保真度和真实感,总损失定义为:
ℓ V = λ V L 1 ∥ I ^ V i t − I V i t ∥ + λ V P P ( I ^ V i t , I V i t ) + λ V G G ( I ^ V i t , S V i t ) ( 17 ) \ell _{V}=\lambda _{V}^{L1}\left\| \hat {I}_{V_{i}}^{t}-I_{V_{i}}^{t}\right\| +\lambda _{V}^{P}\mathcal {P}(\hat {I}_{V_{i}}^{t},I_{V_{i}}^{t})+\lambda _{V}^{G}\mathcal {G}(\hat {I}_{V_{i}}^{t},S_{V_{i}}^{t}) (17) ℓV=λVL1
I^Vit−IVit
+λVPP(I^Vit,IVit)+λVGG(I^Vit,SVit)(17)
其中, I V i t I_{V_{i}}^{t} IVit为时间步 t t t时车辆实例 V i V_{i} Vi的真实图像, S V i t S_{V_{i}}^{t} SVit为对应的透视视角语义地图,生成方式与 S G S_{G} SG一致; λ V L 1 \lambda_{V}^{L 1} λVL1、 λ V P \lambda_{V}^{P} λVP和 λ V G \lambda_{V}^{G} λVG为三个损失的权重。需注意,该损失仅作用于语义标签为对应车辆实例的像素。
3.6 合成器
由于城市背景生成器、建筑实例生成器和车辆实例生成器的输出无对应的真实图像,训练神经网络融合这些图像存在较大难度。因此,合成器直接将生成的各部分图像及其对应的掩码融合为一张统一的图像,融合公式为:
I C t = I ^ G M G + ∑ i = 1 n B I ^ B i M B i + ∑ i = 1 n V I ^ V i t M V i t ( 18 ) I_{C}^{t}=\hat{I}_{G} M_{G}+\sum_{i=1}^{n_{B}} \hat{I}_{B_{i}} M_{B_{i}}+\sum_{i=1}^{n_{V}} \hat{I}_{V_{i}}^{t} M_{V_{i}}^{t} (18) ICt=I^GMG+i=1∑nBI^BiMBi+i=1∑nVI^VitMVit(18)
4 数据集
4.1 OSM数据集
OSM数据集基于开放街道地图[31]构建,包含全球80座城市的栅格化语义地图和高度场,覆盖总面积超过 6000 km 2 6000 \ \text{km}^2 6000 km2。在栅格化步骤中,矢量数据被转换为图像,具体将经纬度坐标转换为EPSG:3857坐标系(缩放级别18),该坐标系下的像素分辨率约为0.597米/像素。语义分割地图采用不同颜色表征不同城市元素:红色代表道路,黄色代表建筑,绿色代表城市绿地,青色代表建筑施工区域,蓝色代表水域。高度场主要捕捉建筑的高程信息,基于开放街道地图数据构建;其中道路的高度值设为4,水域设为0,城市绿地的高度值则通过柏林噪声[104]在8至16米的范围内随机生成。
4.2 GoogleEarth数据集
CityDreamer4D对城市中的每个建筑实例进行独立生成,以适配建筑的外观多样性,这一设计需要密集的三维实例标注。现有数据集均无法同时提供密集的三维语义标注和实例标注,为解决这一问题,本文通过经纬度对谷歌地球和开放街道地图进行地理对齐,为GoogleEarth数据集自动生成了密集的三维语义标注和建筑实例标注。
GoogleEarth数据集基于谷歌地球工作室[32]收集,包含纽约市的400条环绕飞行轨迹,共生成24000张分辨率为960×540的图像,环绕轨道半径范围为125至813米,拍摄高度为112至884米,且谷歌地球工作室为每张图像提供了相机的内参和外参参数。
二维和三维标注生成
三维标注的生成步骤为:1)对OSM语义地图进行连通域检测,生成建筑的实例地图,背景元素的标签保持不变;2)基于OSM数据集的高度值,将实例地图中的像素拉伸为三维体,得到三维标注。利用谷歌地球工作室提供的相机参数,将三维体投影至图像上,即可由密集的三维标注生成二维标注。该自动化标注流程高效且可便捷迁移至全球任意城市的标注生成中。
4.3 CityTopia数据集
GoogleEarth数据集虽提供了带有密集三维语义和实例标注的图像,但仍存在三方面问题:1)由于谷歌地球工作室在近地面的三维重建效果不佳,该数据集缺乏街景图像;2)其标注数据源自开放街道地图,不同数据源导致标注存在一定的不精确性;3)开放街道地图中缺失高架道路等高架结构的高度数据,导致这类结构未被标注。为解决上述问题,本文构建了CityTopia数据集,该数据集包含高保真的日间和夜间街景、无人机视角图像,且带有精准的三维密集标注,是目前规模最大、城市场景多样性最丰富、标注最详尽的数据集。
虚拟城市生成
为构建CityTopia数据集,本文在Houdini和虚幻引擎中设计了11座虚拟城市,生成了三维标注并在可控的光照条件下渲染出真实感图像。具体采用来自城市样本项目[33]的约5000个高质量三维资产,在Houdini中程序化生成城市原型,该原型存储了城市中所有三维资产的六维位姿;通过表面采样为每个三维点分配语义标签和实例标签;将城市原型在虚幻引擎中实例化,得到完整的生成式虚拟城市。
图像收集
虚拟城市在虚幻引擎中实例化后,设置相机轨迹进行图像渲染:对含建筑的城市,每段轨迹生成3000张图像;对仅含车辆的城市,每段轨迹生成7500张图像。为每段轨迹分别渲染日间和夜间场景,并移除阳光光照,以帮助网络更易学习生成过程中的光照一致性。为避免摩尔纹效应,渲染过程中对每张图像进行8倍空间采样和32倍时间采样。CityTopia数据集的视角范围更广,仰角变化区间更大,且包含大量近地面拍摄的街景图像,相比GoogleEarth数据集具有更丰富的视角多样性。
二维和三维标注
虚拟城市生成流程可原生生成精准的三维标注,在虚幻引擎中设置好相机位姿后,利用给定的相机参数将三维标注投影至图像,即可生成二维标注。CityTopia数据集中的二维和三维实例标注与街景、无人机视角图像实现了完美对齐,其中仅含车辆的场景可强化车辆生成的学习效果,精准的车辆标注验证了该流程的有效性,且可通过增加三维资产实现流程的规模化扩展。
5 实验
5.1 评估协议
本文通过生成1024个独特的城市布局对所提方法进行评估,为每个布局随机采样风格码 Z Z Z生成20种变体。针对每种变体,采用随机相机轨迹渲染分辨率为960×540像素的图像,并根据具体评估指标的要求,从渲染结果中随机选取帧进行评估。本文采用的评估指标如下:
- FID和KID:弗雷歇初始距离(FID)[109]和核初始距离(KID)[110]用于衡量图像生成质量,计算15000张生成帧与从数据集中随机采样的15000张图像之间的FID和KID值;
- VBench:视频生成模型综合评估指标(VBench)[111]从背景一致性、运动平滑度、动态程度、美学质量和成像质量等维度,对视频生成模型进行全面评估。该指标基于150段视频计算,每段视频包含100帧,帧率为16帧/秒;
- 深度误差(DE):为评估三维几何生成效果,本文沿用EG3D[52]的方法计算深度误差。利用预训练模型[112]通过累积体密度 σ \sigma σ生成伪真实深度图,深度误差为归一化后深度图之间的L2距离,每种方法基于100帧计算该指标;
- 相机误差(CE):为评估多视角一致性,本文沿用SceneDreamer[7]的方法计算相机误差。在静态三维场景中,将推断得到的相机轨迹与COLMAP[113]估计的相机轨迹进行对比,计算该指标。该指标基于沿环绕轨迹渲染的600帧图像计算,定义为生成的相机位姿与重建的相机位姿之间的尺度不变归一化L2距离。
5.2 实现细节
超参数
- 无界布局生成器:码本大小 d K d_{K} dK设为512,每个码的维度 d C d_{C} dC为512;将高度场和语义地图的图像块裁剪至512×512的分辨率,并以16倍的比例进行压缩;损失权重设置为 λ R = 10 \lambda_{R}=10 λR=10、 λ S = 10 \lambda_{S}=10 λS=10、 λ E = 1 \lambda_{E}=1 λE=1。
- 城市背景生成器:在GoogleEarth数据集上,局部窗口分辨率设为 N ˉ G H = 1536 \bar{N}_{G}^{H}=1536 NˉGH=1536、 N G W = 1536 N_{G}^{W}=1536 NGW=1536、 N G D = 640 N_{G}^{D}=640 NGD=640;在CityTopia数据集上,局部窗口分辨率设为 N G H = 3072 N_{G}^{H}=3072 NGH=3072、 N G W = 3072 N_{G}^{W}=3072 NGW=3072、 N G D = 2560 N_{G}^{D}=2560 NGD=2560;场景级特征的维度 d G d_{G} dG为2;生成式哈希网格的参数设置为 N H L = 16 N_{H}^{L}=16 NHL=16、 N E = 2 19 N_{E}=2^{19} NE=219、 N G C = 8 N_{G}^{C}=8 NGC=8;公式(5)中使用的素数为 π 1 = 1 \pi^{1}=1 π1=1、 π 2 = 2654435761 \pi^{2}=2654435761 π2=2654435761、 π 3 = 805459861 \pi^{3}=805459861 π3=805459861、 π 4 = 3674653429 \pi^{4}=3674653429 π4=3674653429、 π 5 = 2097192037 \pi^{5}=2097192037 π5=2097192037;损失函数权重设置为 λ G L 1 = 10 \lambda_{G}^{L 1}=10 λGL1=10、 λ G P = 10 \lambda_{G}^{P}=10 λGP=10、 λ G G = 0.5 \lambda_{G}^{G}=0.5 λGG=0.5。
- 建筑实例生成器:在GoogleEarth数据集上,局部窗口分辨率设为 N B H = 672 N_{B}^{H}=672 NBH=672、 N B W = 672 N_{B}^{W}=672 NBW=672、 N B D = 640 N_{B}^{D}=640 NBD=640;在CityTopia数据集上,局部窗口分辨率设为 N B H = 768 N_{B}^{H}=768 NBH=768、 N B W = 768 N_{B}^{W}=768 NBW=768、 N B D = 2560 N_{B}^{D}=2560 NBD=2560;像素级特征的通道数为63( N B C = 63 N_{B}^{C}=63 NBC=63),维度 N P L N_{P}^{L} NPL设为10。
- 车辆实例生成器:场景级特征的维度 d V d_{V} dV为2;局部窗口分辨率设为 N V H = 32 N_{V}^{H}=32 NVH=32、 N V W = 32 N_{V}^{W}=32 NVW=32、 N V D = 32 N_{V}^{D}=32 NVD=32;损失函数权重设置为 λ V L 1 = 10 \lambda_{V}^{L 1}=10 λVL1=10、 λ V P = 10 \lambda_{V}^{P}=10 λVP=10、 λ V G = 0.5 \lambda_{V}^{G}=0.5 λVG=0.5。
训练细节
- 无界布局生成器:矢量量化变分自编码器(VQVAE)模型的训练迭代次数为1250000次,批次大小为16,采用Adam优化器( β = ( 0.5 , 0.9 ) \beta=(0.5,0.9) β=(0.5,0.9)),学习率为 7.2 × 10 − 5 7.2×10^{-5} 7.2×10−5;自回归变换器的训练迭代次数为250000次,批次大小为80,采用Adam优化器( β = ( 0.9 , 0.999 ) \beta=(0.9,0.999) β=(0.9,0.999)),学习率为 2 × 10 − 4 2×10^{-4} 2×10−4。
- 背景与实例生成器:城市背景生成器、建筑实例生成器和车辆实例生成器均采用Adam优化器( β = ( 0 , 0.999 ) \beta=(0, 0.999) β=(0,0.999))训练,学习率为 10 − 4 10^{-4} 10−4;判别器采用相同的优化器配置,学习率为 10 − 5 10^{-5} 10−5;训练迭代次数为298500次,批次大小为8,训练过程中对图像随机裁剪至192×192的分辨率。
5.3 主要结果
对比方法
本文将CityDreamer4D与多种当前最优方法进行对比,包括SGAM[105]、PersistentNature[106]、SceneDreamer[7]和InfiniCity[26]。由于目前尚无专门的四维场景生成方法,本文选取四维新视角合成方法DreamScene4D[107]和四维视频生成方法DimensionX[108]作为竞争性基线方法。为保证对比的公平性,除InfiniCity和DimensionX外,所有方法均使用其开源代码在GoogleEarth和CityTopia数据集上重新训练。由于SceneDreamer无法生成城市布局和交通场景,其输入由本文提出的无界布局生成器和交通场景生成器提供;此外,因GoogleEarth数据集缺乏动态物体的标注,为支持四维生成,车辆生成模型基于CityTopia数据集训练。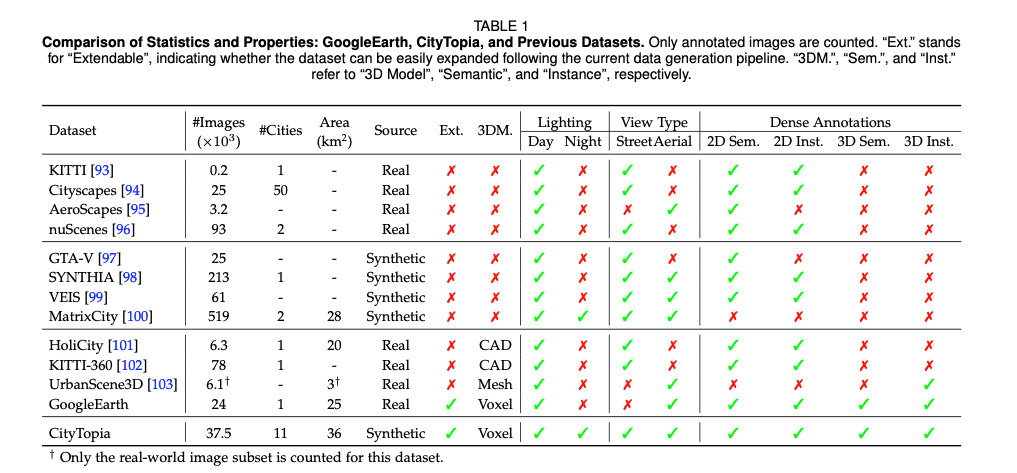
定性对比
本文在GoogleEarth和CityTopia数据集上,将所提方法与基线方法进行定性对比(结果分别见图4、图5)。SGAM因难以对复杂的四维城市进行视角外推,生成结果的真实感不足且无法保证多视角一致性;采用三平面表示的PersistentNature同样难以生成真实的渲染结果;InfiniCity和SceneDreamer均采用鸟瞰视角(BEV)地图作为场景表示,但由于将同一类别下的所有实例赋予相同的语义标签,二者在建筑、车辆等实例级物体的生成中出现严重的结构畸变;DreamScene4D无法直接生成四维场景,仅能通过将动态物体与背景解耦,将单目视频转化为四维场景,且难以准确重建物体的三维形状;DimensionX在生成环绕式四维视频时出现严重畸变,且生成结果无法保持多视角一致性。相比之下,本文提出的CityDreamer4D生成的结果比所有基线方法更具真实感和多样性。

定量对比
表2展示了各方法的定量评估指标结果,CityDreamer4D在FID、KID和VBench指标上均优于所有基线方法,体现了其在运动平滑度、动态程度和美学质量方面的优势;同时,CityDreamer4D取得了最低的深度误差和相机误差,证明其在三维几何生成、视角一致性和照片真实感图像生成方面的优异表现。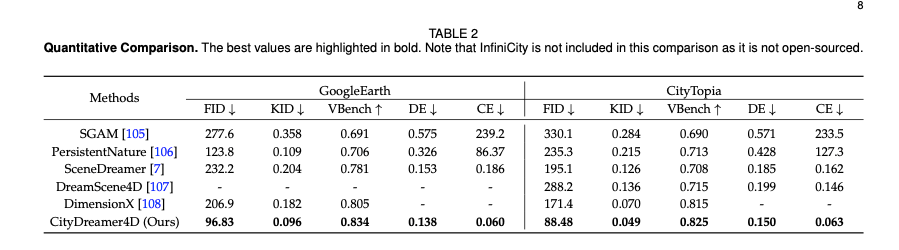
用户研究
为更全面地评估无界四维城市生成的多视角一致性和生成质量,本文沿用CityDreamer[34]的方案开展用户研究。本次调研邀请25名志愿者从三个维度对各方法生成的城市进行评分:1)感知质量;2)四维真实感;3)视角一致性。评分采用1-5分制,5分为最高分。结果如图6所示,本文提出的CityDreamer4D在评分上显著优于所有基线方法。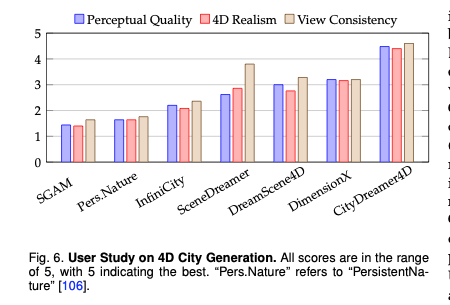
5.4 消融研究
无界布局生成器的有效性
无界布局生成器(ULG)是生成“无界”城市布局的核心模块。为验证其有效性,本文将其与InfiniCity中使用的InfinityGAN[115],以及基于规则的城市布局生成方法IPSM[114]进行性能对比。本文沿用InfiniCity[26]的方法,采用FID和KID指标定量评估生成布局的质量。表3的结果显示,与IPSM和InfinityGAN相比,无界布局生成器在所有指标上均取得最优结果;图7的定性结果也证明了该方法能生成高质量、多样化的城市布局。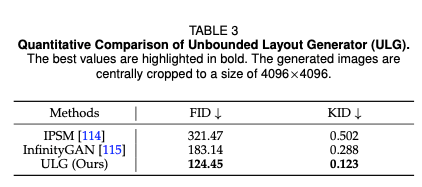

建筑实例生成器的有效性
建筑实例生成器(BIG)是实现无界四维城市高质量生成的关键模块。为验证其有效性,本文对该模块开展消融研究,首先将其与两种替代设计方案对比:1)从CityDreamer4D中移除建筑实例生成器,模型退化为SceneDreamer;2)使用建筑实例生成器同时生成所有建筑,且未引入实例标签。表4前两行和图8a、8b的结果显示,两种替代设计均导致生成质量显著下降,证明了建筑实例生成器和实例标签的重要性。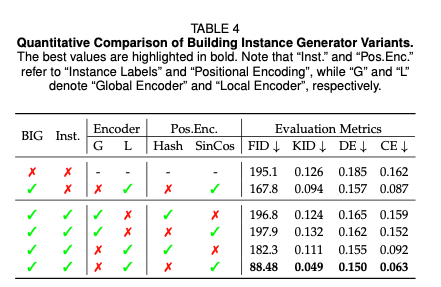

场景参数化直接影响四维城市的生成质量,本文提出的建筑实例生成器将标准的正余弦位置编码与局部编码器提取的像素级特征相结合。为验证该参数化方式的有效性,本文将其与其他场景参数化设计方案对比。表4最后四行和图8c-8f的结果显示,采用生成式哈希网格位置编码会导致建筑外立面畸变,而将全局编码器与正余弦编码结合会使建筑外立面出现重复的图案。上述对比结果证明,建筑实例生成器的参数化设计是实现真实、多样化建筑生成的关键。
车辆实例生成器的有效性
车辆实例生成器(VIG)在四维城市的车辆生成中发挥关键作用。为验证其有效性,本文对该模块开展消融研究,将其与两种替代设计方案对比:1)从CityDreamer4D中移除车辆实例生成器,将车辆视为背景元素,由城市背景生成器完成车辆生成;2)生成车辆时未引入规范化操作,即未在规范特征空间中生成车辆。表5前两行和图9a、9b的结果显示,两种替代设计均导致生成结果出现严重畸变,证明了车辆实例生成器和规范化操作的重要性。
场景参数化对车辆实例生成器的性能同样至关重要,为验证这一点,本文对比了该模块中不同的场景参数化设计方案。本文提出的车辆实例生成器将标准的正余弦位置编码与全局编码器提取的全局级特征相结合,在规范特征空间中,将全局级特征与三维坐标结合能使网络更好地在不同车辆间共享特征,从而加快模型收敛。表5最后一行和图9f的结果显示,若采用与建筑实例生成器相同的设计(局部编码器结合正余弦位置编码),会增加模型的学习难度,导致生成的车辆形状不完整;同理,在车辆实例生成器中使用生成式哈希网格,会增加网络将纹理特征与三维坐标关联的难度,进而导致生成结果出现结构畸变(图9c、9e,表5第三、五行)。
5.5 应用
城市仿真
CityDreamer4D可作为高性能的城市仿真器,生成包含动态物体和精细化环境的真实感四维城市场景。与CARLA[68]等传统仿真器相比,该方法突破了预定义有界区域的限制,能够生成大规模、无缝衔接的城市场景;同时,该方法可生成街景和无人机视角的场景,为自动驾驶、城市规划、虚拟现实等应用提供更丰富的仿真场景。
局部编辑
依托组合式架构设计,CityDreamer4D支持对建筑和车辆实例进行局部编辑。图10a和10c的结果显示,可独立修改车辆的位置和风格,且不会影响场景中的其他元素;同理,图10b和10d的结果显示,建筑的外观可随高度变化自适应调整,且保持风格的一致性。该能力为场景后期制作中的定制化优化提供了便利。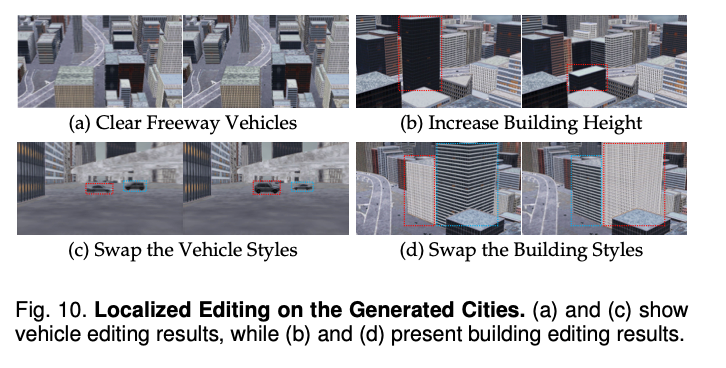
城市风格化
利用控制网络(ControlNet)[116],可对CityDreamer4D生成的城市进行无缝的风格化重构——在由边缘检测(HED)边缘条件生成的图像上,对预训练模型进行微调即可实现风格迁移。图11展示了将城市风格转化为《我的世界》(Minecraft)和赛博朋克(Cyberpunk)风格的结果,依托CityDreamer4D的场景表示和参数化设计,风格化后的城市仍保持良好的多视角一致性。
视觉语言导航
为验证生成的四维城市场景的实用性,本文开展了视觉语言导航实验——具身智能体根据自然语言指令在场景中完成导航任务。具体而言,智能体在基于CityTopia数据集训练的CityDreamer4D所生成的场景中执行导航任务,本文手动标注了100组指令-轨迹对作为测试集,每组数据引导智能体前往生成场景中的特定地标。本文沿用GRUtopia[124]的实验方案,智能体将当前的图像观测和语言提示输入视觉语言模型(VLM),模型从12种离散动作中选择执行:向前/斜向移动(2/4/6米)、向左/向右转(45°)或停止,该过程迭代执行直至模型输出“停止”指令。
本文同时收集了5名志愿者的人工表现作为参考,志愿者按照与视觉语言模型相同的导航方案完成整个测试集。实验采用GRUtopia的零样本评估设置,使用未经过任务特定微调的预训练视觉语言模型,评估的当前最优模型包括开源模型SAIL-VL 1.6[119]、Ovis2[120]、Qwen2.5-VL[121]、Ola[122]、InternVL3[123],以及闭源模型Gemini 2.5 Pro[117]、GPT4o[118]。
采用四项标准指标评估导航性能:成功率(SR)、路径长度(PL)、归一化逆路径长度加权成功率(SPL)、因遮挡导致的重置次数(RT)。表6的结果显示,视觉语言模型在四维城市中的空间推理能力表现不佳,成功率和归一化逆路径长度加权成功率均处于较低水平;其中GPT-4o的表现最优,InternVL3次之。作为对比,人工参考的成功率为100.0%,归一化逆路径长度加权成功率为85.87%,证明人工与模型的性能之间存在显著差距。人工导航的平均路径长度略长于模型,主要原因是模型往往在未到达目的地时便提前停止。上述结果结合近期相关研究发现[124][125]表明,在复杂的城市场景中,将空间指令落地为实际导航行为仍具有较大难度,而生成的四维城市可作为评估视觉语言模型空间推理和导航能力的优质基准。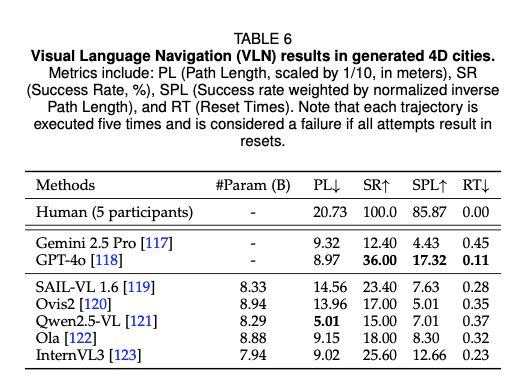
5.6 讨论
视角一致性
为验证CityDreamer4D生成结果的多视角一致性,本文利用COLMAP[113],对基于GoogleEarth和CityTopia数据集训练的模型所生成的环绕式视频,进行运动恢复结构和密集重建。测试视频包含600帧分辨率为960×540的图像,由固定高度的环形相机轨迹拍摄,相机始终对准场景中心;重建过程仅基于图像完成,未指定任何相机参数。图12的结果显示,估计的相机位姿与采样的轨迹高度吻合,且重建得到的点云密集、轮廓清晰。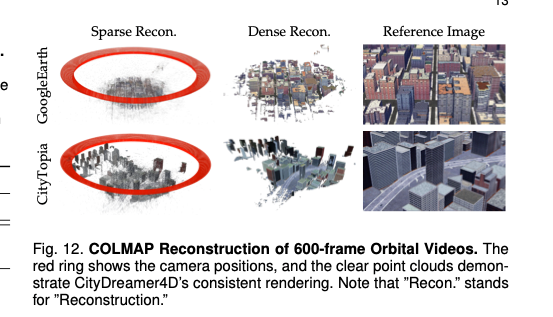
重新打光
在CityDreamer4D中,背景元素与实例的生成分离设计带来两大优势:1)降低建筑实例、车辆实例和背景元素的学习难度;2)支持对建筑和车辆实例进行局部编辑。该设计可视为一种逆渲染过程——CityDreamer4D生成城市场景的反照率、法向量和深度信息,再根据给定的光照条件计算光照和着色效果。
如图13所示,着色效果分为两部分:朗伯着色和阴影映射。朗伯着色结合光照方向和表面法向量,实现全方向的均匀光照(图13a);阴影映射考虑光照的可见性,能够模拟场景中其他物体产生的阴影和遮挡效果(图13b)。图13c展示了相机置于场景左侧时的最终重新打光效果。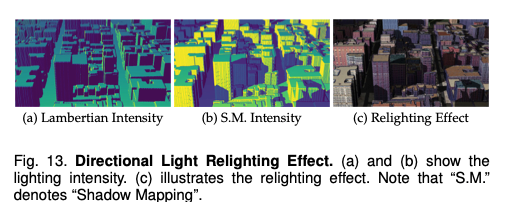
多智能体支持
为探索CityDreamer4D支持更多样化智能体的潜力,本文开展了将行人集成至生成场景的初步实验:利用MoMask[126]合成行人运动轨迹,将其重定向至三维人体虚拟化身,并将动画化的行人渲染至生成的四维城市场景中。图14的结果显示,生成的动画呈现出行人过马路等连贯的行为,证明该框架可扩展至支持车辆之外的、更丰富的多智能体仿真。
局限性
尽管CityDreamer4D能生成具有真实感的四维城市,但其仍存在一些局限性:1)推理过程中,建筑和车辆的生成分别独立进行,导致计算成本略有增加;2)当前的模型实现未考虑全局光照和反射效果,而这两项是实现真实感夜景生成的关键。如图15所示,建筑和车辆发出的光线无法对周围环境形成光照,导致夜景生成的真实感受限。
6 结论
本文提出了专为无界四维城市生成设计的生成模型 CityDreamer4D。该方法将动态物体与静态场景解耦,简化了四维城市的生成过程,依托动态交通场景和静态城市布局,实现了更具灵活性和真实感的四维城市生成。四维城市中的物体通过融合面向背景元素的神经场和面向实例的神经场生成,分别适配背景、建筑和车辆的生成需求。此外,本文构建了一套综合的城市生成数据集,包括 OSM、GoogleEarth 和 CityTopia 数据集,这些数据集提供了真实世界的城市布局,以及带有高质量三维标注的城市场景数据。实验结果表明,CityDreamer4D 在生成大规模、真实感的四维城市方面达到了当前最优的性能,且依托组合式设计实现了实例级编辑,为城市仿真领域的研究和实际应用挖掘了新的可能性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)