动手学深度学习——PyTorch 神经网络基础:自定义层详解
一、前言
在前面的学习中,我们已经接触了 PyTorch 中很多现成的层,比如:
-
nn.Linear -
nn.ReLU -
nn.Sequential
这些层已经足够我们搭建很多基础神经网络。
但随着学习深入,我们很快会发现一个问题:
现实中的网络结构,不一定总能完全靠现成层直接拼出来。
比如有时候我们可能想实现:
-
一个带特殊计算规则的层
-
一个没有可学习参数、只做固定变换的层
-
一个带自定义权重逻辑的层
-
一个按照自己想法组织前向传播的模块
这时候,就需要掌握一个非常重要的能力:
自定义层。
如果说前面的“模型构造”是在学怎么用现成零件搭模型,
那么“自定义层”就是在学:
如何自己造零件。
这一节非常关键,因为它会让我们真正明白:
-
层到底是什么
-
自定义层本质上怎么实现
-
没有参数的层怎么写
-
带参数的层怎么写
-
为什么 PyTorch 的灵活性这么强
二、什么是自定义层
所谓自定义层,本质上就是:
我们不再只使用 PyTorch 已经提供好的层,而是自己定义一个新的模块,用来完成特定计算。
比如 nn.Linear 本质上就是一个层,作用是:
[
y = Wx + b
]
如果我们想定义一个自己的层,比如:
-
把输入减去均值后再输出
-
把输入限制在某个范围内
-
手动定义一个可学习权重矩阵参与计算
那么都可以通过继承 nn.Module 来完成。
也就是说:
自定义层的本质,仍然是自定义一个
nn.Module。
三、为什么要学自定义层
1. 现成层不可能覆盖所有需求
虽然 PyTorch 提供了很多常见层,但真实研究和项目里,总会遇到一些特殊需求。
2. 它能帮助我们真正理解“层”的本质
很多人会把层理解成一个神秘黑箱,但学了自定义层之后就会明白:
层本质上就是一个按照某种规则处理输入的模块。
3. 后面很多高级结构都离不开这个能力
例如:
-
注意力机制
-
自定义归一化模块
-
特殊损失前处理模块
-
某些论文复现中的特殊块
本质上都依赖自定义层能力。
四、自定义层的核心思路
前面我们已经学过,PyTorch 中所有模型和层的基础都是:
nn.Module
因此,自定义层最核心的思路就是:
-
继承
nn.Module -
在
__init__()中定义需要的参数或子层 -
在
forward()中定义计算逻辑
这和我们之前自定义整个网络是一样的。
也就是说:
从 PyTorch 的角度看,“层”和“模型”没有绝对边界。
小模块可以当层,大模块也可以当层。
五、先看一个没有参数的自定义层
最容易理解的,是先写一个不带参数的自定义层。
例如,我们定义这样一个层:
输入一个张量,把张量中所有元素做 ReLU 操作,也就是把负数变成 0。
代码如下:
import torch
from torch import nn
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()
这里这个层的作用是:
把输入整体减去均值,使输出的均值变成 0。
六、这个没有参数的层该怎么理解
我们来逐行看。
1. class CenteredLayer(nn.Module)
表示我们定义了一个新的层,并继承 nn.Module。
2. __init__()
这里没有定义任何参数,所以除了 super().__init__(),什么都不用写。
3. forward(self, X)
定义这个层的前向传播规则:
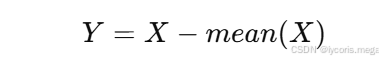
也就是把输入中每个元素都减去整体均值。
这个层没有权重、没有偏置,但它仍然是一个合法的层。
这说明:
层不一定非得有参数,只要它能对输入做某种变换,它就可以是一个层。
七、如何使用这个自定义层
和使用普通层没有区别:
layer = CenteredLayer()
X = torch.tensor([1.0, 2.0, 3.0, 4.0])
Y = layer(X)
print(Y)
print(Y.mean())
输出会发现:
-
Y的均值接近 0
也就是说,这个层成功实现了“中心化”操作。
八、为什么说这已经说明了层的本质
这个例子非常重要,因为它让我们看清楚:
层的本质,不一定是“带参数的神经元计算”,而是“一个输入到输出的变换模块”。
只不过很多常见层,例如 Linear、Conv2d,恰好还带有可学习参数。
但本质上,层首先是一个计算规则。
这对后面理解各种复杂模块很有帮助。
九、带参数的自定义层怎么写
接下来再看更重要的一类:带参数的自定义层。
例如,我们自己实现一个简化版线性层。
线性层的公式是:
[
Y = XW + b
]
那么代码可以这样写:
import torch
from torch import nn
from torch.nn import functional as F
class MyLinear(nn.Module):
def __init__(self, in_units, out_units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, out_units))
self.bias = nn.Parameter(torch.randn(out_units))
def forward(self, X):
linear = torch.matmul(X, self.weight) + self.bias
return F.relu(linear)
这个层做的事情是:
-
先做线性变换
-
再做 ReLU 激活
十、nn.Parameter 是什么
这一点非常关键。
在自定义层中,如果我们想定义“可学习参数”,不能只是普通张量:
self.weight = torch.randn(in_units, out_units)
而应该写成:
self.weight = nn.Parameter(torch.randn(in_units, out_units))
原因是:
nn.Parameter会告诉 PyTorch:
这个张量是模型参数,需要被自动注册,并在训练时被优化器更新。
如果你只是普通张量,那么:
-
model.parameters()看不到它 -
优化器不会更新它
-
它不会被当成真正的可学习参数
所以可以理解为:
nn.Parameter就是“带可学习身份标记的张量”。
十一、这个自定义线性层怎么理解
1. 权重
self.weight = nn.Parameter(torch.randn(in_units, out_units))
定义一个形状为 [输入维度, 输出维度] 的权重矩阵。
2. 偏置
self.bias = nn.Parameter(torch.randn(out_units))
定义偏置向量。
3. 前向传播
linear = torch.matmul(X, self.weight) + self.bias
实现矩阵乘法和偏置相加。
4. 加激活函数
return F.relu(linear)
最后做 ReLU。
这说明:
其实很多现成层,本质上也是这么实现的,只不过官方封装得更完善。
十二、如何使用带参数的自定义层
例如:
linear = MyLinear(5, 3)
X = torch.rand(2, 5)
Y = linear(X)
print(Y)
这里:
-
输入是
2 × 5 -
输出是
2 × 3
因为:
-
每个样本输入维度为 5
-
输出维度设为 3
十三、自定义层可以直接放进模型里吗
当然可以。
这也是 PyTorch 最强大的地方之一。
只要你定义的类继承了 nn.Module,它就可以像普通层一样参与模型搭建。
例如:
net = nn.Sequential(
MyLinear(64, 32),
MyLinear(32, 16),
MyLinear(16, 8)
)
X = torch.rand(4, 64)
Y = net(X)
print(Y.shape)
这说明:
自定义层和官方层在使用方式上几乎没有区别。
十四、自定义层和自定义模型的关系
很多初学者会有点混淆:
-
自定义层
-
自定义模型
到底有什么区别?
其实从 PyTorch 的角度看,二者本质是一回事:
它们都是
nn.Module
区别只是规模不同:
-
自定义层:通常功能更小、更局部
-
自定义模型:通常是多个层组合起来的整体结构
所以可以这样理解:
一个模型可以由多个层组成;
而一个层,本质上也可以看成一个小模型。
十五、再看一个更有代表性的自定义层例子
我们可以定义一个“把输入裁剪到某个范围内”的层。
例如:
class MyClipLayer(nn.Module):
def __init__(self, min_val, max_val):
super().__init__()
self.min_val = min_val
self.max_val = max_val
def forward(self, X):
return torch.clamp(X, self.min_val, self.max_val)
这个层的作用是:
-
小于最小值的,变成最小值
-
大于最大值的,变成最大值
-
中间的保持不变
使用方法:
layer = MyClipLayer(-1.0, 1.0)
X = torch.tensor([-2.0, -0.5, 0.3, 2.5])
print(layer(X))
输出会被限制在 [-1, 1] 之间。
十六、自定义层中可以保存普通常量吗
可以。
例如刚才这个例子中的:
self.min_val = min_val
self.max_val = max_val
它们不是可学习参数,只是普通属性。
但因为它们是这个层工作所需要的信息,所以也可以保存在类中。
因此在自定义层里,通常会出现两种东西:
1. 可学习参数
用 nn.Parameter 定义
2. 普通配置属性
直接保存为 self.xxx
这两类东西都可以写在 __init__() 中。
十七、自定义层的优势到底是什么
1. 表达能力强
你可以按自己的想法设计任意计算规则。
2. 与 PyTorch 框架无缝衔接
只要继承 nn.Module,就能继续使用:
-
parameters() -
state_dict() -
优化器
-
Sequential -
GPU 加速
3. 有利于模块化组织代码
复杂模型可以拆成多个自定义层,使代码更清晰。
4. 是复现论文和做研究的基础能力
很多论文结构根本没有现成 API,必须自己定义模块。
十八、自定义层时最容易犯的错误
1. 忘记继承 nn.Module
如果不继承,就无法享受 PyTorch 的模块管理机制。
2. 忘记写 super().__init__()
这样父类不会正确初始化。
3. 可学习参数没写成 nn.Parameter
这样优化器不会更新它们。
4. 在 forward() 中写错维度
例如矩阵乘法维度对不上。
5. 把“普通属性”和“可学习参数”混淆
不是所有 self.xxx 都是参数,只有 nn.Parameter 才是可学习参数。
十九、自定义层和官方层相比有什么区别
从使用者角度看,几乎没有本质区别。
例如你写:
layer = MyLinear(4, 3)
它和:
layer = nn.Linear(4, 3)
在“调用方式”上是一样的,都是:
Y = layer(X)
区别主要在于:
-
官方层是 PyTorch 已经封装好的
-
自定义层是你自己定义规则
所以学习自定义层后,你就会对官方层理解更深:
原来这些现成层,本质上也是别人提前帮我们写好的
nn.Module。
二十、一个适合 CSDN 的完整示例
下面给你一份更完整、适合博客展示的示例代码。
import torch
from torch import nn
from torch.nn import functional as F
# 1. 无参数自定义层
class CenteredLayer(nn.Module):
def __init__(self):
super().__init__()
def forward(self, X):
return X - X.mean()
# 2. 有参数自定义层
class MyLinear(nn.Module):
def __init__(self, in_units, out_units):
super().__init__()
self.weight = nn.Parameter(torch.randn(in_units, out_units))
self.bias = nn.Parameter(torch.randn(out_units))
def forward(self, X):
linear = torch.matmul(X, self.weight) + self.bias
return F.relu(linear)
# 3. 测试无参数层
layer1 = CenteredLayer()
X1 = torch.tensor([1.0, 2.0, 3.0, 4.0])
Y1 = layer1(X1)
print("CenteredLayer 输出:", Y1)
print("输出均值:", Y1.mean())
# 4. 测试有参数层
layer2 = MyLinear(5, 3)
X2 = torch.rand(2, 5)
Y2 = layer2(X2)
print("MyLinear 输出:", Y2)
# 5. 放入顺序模型中
net = nn.Sequential(
MyLinear(5, 8),
CenteredLayer(),
MyLinear(8, 1)
)
X3 = torch.rand(4, 5)
Y3 = net(X3)
print("组合模型输出:", Y3)
这段代码已经很好地展示了:
-
无参数自定义层
-
有参数自定义层
-
自定义层组合成模型
二十一、这一节最核心的收获
如果把这一节压缩成几个关键点,我觉得最重要的是:
1. 层本质上就是一个模块
只要能定义输入到输出的变换,它就可以是层。
2. 自定义层本质上就是自定义 nn.Module
没有神秘之处。
3. 有参数的层要用 nn.Parameter
这样参数才能被自动管理和更新。
4. 自定义层可以和官方层无缝组合
这也是 PyTorch 灵活性的根本来源。
5. 自定义层能力是后续进阶的基础
以后学复杂模型时会反复用到。
二十二、我对这一节的理解
学完“自定义层”之后,我最大的感受是:
以前总觉得神经网络中的“层”是某种固定的、由框架提前规定好的东西,
但这一节让我明白了:
层并不是死的,层本质上只是一个按某种规则处理输入的模块。
只要我们会写 nn.Module,其实就可以自己设计层。
这让人对深度学习框架的理解一下子更深了。
也就是说,PyTorch 并不是在强迫我们“只能用现成模块”,而是在提供一个非常灵活的框架,让我们自己去组合、去扩展、去创造新的结构。
这一点对后面学习更复杂网络特别重要。
二十三、结语
“自定义层”是 PyTorch 神经网络基础中非常值得认真掌握的一节。
如果说前面的“模型构造”让我们学会了怎么搭网络,“参数管理”让我们学会了怎么看参数,那么这一节则进一步让我们明白:
网络中的层,本质上也是可以自己定义的。
掌握这一点之后,后面你再学习卷积网络、注意力机制、论文复现时,思路会顺很多。
因为你已经不再只是“调用别人写好的模块”,而是开始具备自己设计模块的能力了。
二十四、重点速记版
1. 什么是自定义层
自己定义一个新的 nn.Module 来完成特定计算。
2. 没有参数的层能不能算层
可以,只要它能实现某种输入到输出的变换。
3. 有参数的层怎么定义参数
用 nn.Parameter。
4. 为什么不能直接用普通张量代替参数
因为普通张量不会被优化器自动更新。
5. 自定义层能不能放进 nn.Sequential
可以,只要它继承了 nn.Module。
6. 自定义层和自定义模型的本质区别是什么
以上就是我对《动手学深度学习》中 PyTorch 神经网络基础——自定义层 这一节的学习整理。
这一节让我真正理解了“层”的本质,也让我意识到,PyTorch 的强大并不只是因为它提供了很多现成 API,更因为它允许我们自己去扩展和定义新的模块。
对于刚开始学 PyTorch 的同学来说,这一节建议一定要亲手敲一遍。尤其要把“无参数层”和“有参数层”的写法都自己实现一次,这样后面学习更复杂模型时,理解会更扎实。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)