CogPlanner: Unveiling the Potential of Agentic MultimodalRetrieval Augmented Generation with Plan
这篇由华为云团队发表于 SIGIR-AP 2025 的论文,针对现有多模态检索增强生成(MRAG)系统检索策略僵化、查询表述不足等核心问题,首次提出 “多模态检索增强生成规划(MRAG Planning)” 任务,并设计了 CogPlanner 框架与 CogBench 基准数据集。该框架借鉴人类认知过程,通过迭代式查询重构与检索策略选择,在提升响应准确性的同时降低计算开销,实现了轻量级部署与现有 MRAG 系统的无缝集成,为智能多模态信息获取与生成提供了新范式。
一、研究背景与核心问题
1. MRAG 技术的发展与局限
检索增强生成(RAG)通过引入外部知识显著提升了大语言模型(LLMs)的生成可靠性,而多模态检索增强生成(MRAG)进一步将应用场景扩展至图像、视频等多模态数据,成为视觉问答(VQA)等任务的关键技术。然而,现有 MRAG 框架存在两大刚性缺陷:
- 盲目信息获取:采用固定单步检索策略(仅文本或仅视觉检索),未评估检索必要性,易引入无关噪声干扰模型判断,甚至忽略多模态大语言模型(MLLMs)自身的推理能力,导致检索冗余;
- 查询表述不足:无法处理视觉信息不完整、文本表述模糊或简洁的查询,且难以应对多跳推理需求,单一检索步骤无法满足复杂查询的信息获取需求。
2. 核心创新任务:MRAG Planning
为解决上述问题,论文提出 MRAG Planning 任务,核心目标是为多模态查询规划优化的信息获取与整合轨迹,具体分解为两个子任务:
- 信息获取:识别 MLLMs 的知识缺口,动态选择文本检索、图像检索或不检索策略;
- 查询重构:将复杂多跳查询分解为原子子查询,或优化模糊查询以提升检索相关性。
该任务的核心价值在于打破传统 MRAG 的固定流程,通过自适应规划实现 “按需检索”,在提升响应准确性的同时降低计算开销。
二、CogPlanner 框架设计
CogPlanner 是一款插件式智能框架,借鉴人类认知过程,通过集中式规划专家与下游 MLLMs 协同,动态执行查询重构与检索策略选择,支持并行建模与顺序建模两种范式,整体架构如图 2 所示。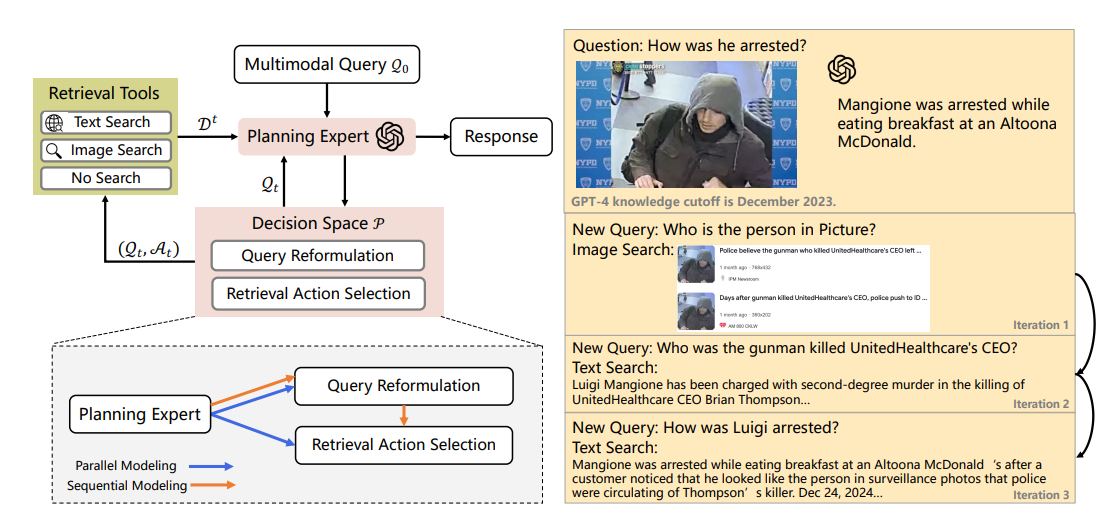
1. 框架核心组件
(1)规划专家(Planning Expert)
作为框架核心,规划专家由 MLLM 担任,负责在每轮迭代中分析当前信息状态,完成两大核心决策:
- 检索动作选择(Information Acquisition):从 “文本检索、图像检索、不检索” 中选择最优动作,决策依据为当前多模态信息质量与外部知识的潜在价值;
- 查询重构(Query Reformulation):分解复杂查询为子查询,或优化模糊查询,确保检索目标明确。
规划专家支持两种建模范式,适配不同场景需求:
表格
| 建模范式 | 决策流程 | 核心优势 | 适用场景 |
|---|---|---|---|
| 并行建模 | 同时执行查询重构与检索动作选择,双线程推理 | 效率高,响应延迟低 | 实时性要求高的场景 |
| 顺序建模 | 先重构查询,再基于优化后的查询选择检索动作 | 检索决策更精准,适配复杂查询 | 多跳推理、模糊查询场景 |
(2)检索与生成模块
- 检索工具:采用 Google Web Search(文本检索)与 Google Image Search(图像检索),文本结果经 Jina API 预处理为结构化数据,图像检索保留 3-6 个高置信度结果及上下文描述,同时引入缓存机制提升效率;
- 生成模块:当规划专家判定信息充分时,整合初始查询、优化后查询及检索文档,由 MLLM 生成最终响应。
(3)兼容性设计
框架与具体模型无关,规划专家可选用任意 MLLM(如 GPT-4o、Qwen-VL 系列、Pixtral 系列),或传统分类模型,可无缝集成至现有 MRAG 系统,灵活性极强。
2. 框架工作流程
以 “查询 Luigi 被捕细节” 为例,CogPlanner 的迭代流程如下:
- 初始状态:输入多模态查询 “How was he arrested?”(含人物图像),规划专家判定需先明确人物身份;
- 迭代 1:重构查询为 “Who is the person in Picture?”,选择图像检索,确认人物为 Luigi Mangione;
- 迭代 2:重构查询为 “Who was the gunman killed UnitedHealthcare's CEO?”,选择文本检索,获取 “Luigi 涉嫌谋杀 CEO” 的背景信息;
- 迭代 3:重构查询为 “How was Luigi arrested?”,选择文本检索,获取 “在麦当劳被捕” 的细节;
- 生成响应:整合三轮检索信息,生成完整回答。
3. 轻量级模型优化
为降低部署成本,基于 CogBench 数据集设计专项微调策略,将 Qwen2-VL-7B-Instruct 微调为轻量级规划专家 Qwen2-7B-VL-Cog:
- 微调数据:CogBench 训练集 + 通用指令数据(1:1 比例),平衡专项能力与通用能力;
- 微调配置:采用 Llama-Factory 框架,学习率 2e-6,训练 2 个 epoch,批次大小 32,暖启动比例 0.1。
三、CogBench 基准数据集
为评估 MRAG Planning 任务与 CogPlanner 框架性能,论文构建了 CogBench 数据集,填补现有基准在多模态规划评估上的空白。
1. 数据集核心特征
- 规模:含 5718 个多模态查询样本,其中训练集 5307 个、测试集 401 个,覆盖 9 个认知领域;
- 复杂性:79.55% 的样本需 MRAG Planning,46.62% 为 3 跳以上推理查询,24.19% 为开放域查询(平均回答长度 40.13 个 token);
- 数据结构:每个样本包含 “多模态查询、迭代规划轨迹、检索文档、黄金答案”,支持完整的规划过程评估。
2. 数据集优势
与现有 MRAG 基准(如 MRAGBench、MMSearch)相比,CogBench 的核心优势在于:
- 聚焦规划过程:不仅提供查询 - 答案对,还记录完整的规划轨迹,支持对查询重构、检索决策的细粒度评估;
- 贴近真实场景:查询基于网页截图生成,经人工优化,避免简单实体替换,更符合实际使用需求;
- 支持轻量级模型训练:通过微调可提升小模型的规划能力,促进框架工业化部署。
四、实验设置与结果
1. 实验配置
- 评估数据集:CogBench 测试集;
- 骨干模型:GPT-4o、Qwen2-VL-72B-Instruct、Pixtral-Large-Instruct、Qwen2-7B-VL-Cog;
- 基线方法:原始 MLLMs、固定文本检索 MRAG、固定图像检索 MRAG、自反思 RAG;
- 评估指标:token 级 F1 分数(响应与黄金答案的 token 重叠度)、claim 级精确率 / 召回率(评估事实准确性)。
2. 核心实验结果
(1)端到端性能对比
CogPlanner 在所有模型配置下均显著超越基线方法,关键结果如下:
- GPT-4o + 并行建模:整体 F1 分数达 23.49,较原始 GPT-4o 提升 10.28,较自反思 RAG 提升 4.02;
- 多跳查询优势显著:3 跳以上查询的 F1 分数达 15.26,较基线提升 2.43-4.53,验证了规划机制对复杂推理的支撑作用;
- 固定检索基线性能退化:固定文本 / 图像检索的 MRAG 性能普遍低于原始 MLLMs,证明盲目检索引入的噪声会损害生成质量。
(2)查询重构性能
采用 BLEU、ROUGE、F1 指标评估查询重构质量,结果显示:
- GPT-4o + 并行建模表现最优,F1 分数达 0.5620,显著优于直接提示工程(0.5375);
- 模型规模影响显著:Qwen2-VL-72B-Instruct 的重构 F1(0.4643)高于 Qwen2-7B-VL-Cog(0.4472),但微调后小模型性能接近大模型,验证了 CogBench 的微调价值。
(3)轻量级模型性能
Qwen2-7B-VL-Cog 作为轻量级规划专家,表现出优异的性能 - 效率权衡:
- 性能接近:与 Qwen2-VL-72B-Instruct 相比,F1 分数仅下降 0.28(21.46 vs 21.74);
- 效率优势显著:token 消耗仅增加 9.8%,延迟降至大模型的 30%(0.484s vs 1.209s),适合工业化部署。
3. 规划过程分析
(1)检索动作分布
- 文本检索占主导:所有模型中,文本检索占比 59.87%-84.28%,表明文本仍是最核心的外部知识来源;
- 轻量级模型更谨慎:Qwen2-7B-VL-Cog 的 “不检索” 占比 5.25%,低于大模型,反映小模型倾向于通过检索增强信心。
(2)迭代步数分析
- 多数任务 2 跳解决:即使是 3 跳以上查询,多数可通过 2 轮检索完成,表明 CogPlanner 的规划机制能高效聚焦关键信息;
- 大模型存在过度检索:Qwen2-VL-72B-Instruct 对 1 跳查询仍执行 2 轮以上检索,验证了 “过度思考” 现象,而 Qwen2-7B-VL-Cog 的检索步数更合理。
五、相关工作对比
1. 与传统 MRAG 的区别
传统 MRAG(如 MuRAG、M2RAG)采用固定检索流程,仅支持单模态或固定组合检索,而 CogPlanner 的核心优势在于 “自适应规划”,通过查询重构与动态检索选择实现 “按需检索”,避免盲目检索带来的噪声与开销。
2. 与查询处理技术的区别
早期信息检索(IR)的查询处理依赖人工启发式规则,而 CogPlanner 通过 MLLM 实现端到端查询重构与检索决策,更适配复杂多模态查询场景;与自反思 RAG 相比,CogPlanner 聚焦多模态场景,规划颗粒度更细,性能提升更显著(平均提升 41.45%)。
六、研究贡献与未来方向
1. 核心贡献
- 任务创新:首次定义 MRAG Planning 任务,填补传统 MRAG 在自适应规划上的空白;
- 框架创新:提出 CogPlanner 插件式框架,支持并行 / 顺序建模,兼容多种 MLLM,可无缝集成至现有系统;
- 数据集创新:构建 CogBench 基准,支持 MRAG Planning 的细粒度评估与轻量级模型微调;
- 性能验证:实验表明,CogPlanner 较基线提升 12.4%-52.5%,轻量级模型仅增加 10% 开销,兼顾性能与效率。
2. 未来方向
- 优化规划决策:减少大模型的 “过度检索” 现象,提升规划步数的合理性;
- 扩展模态支持:纳入视频、音频等更多模态的检索与规划;
- 增强领域适配:针对垂直领域优化查询重构与检索策略,提升专业场景性能。
七、附加资源
- 框架特性:插件式设计,支持并行 / 顺序建模,兼容主流 MLLM,轻量级模型可工业化部署;
- 数据集:CogBench 含 5718 个样本,覆盖 9 个认知领域,支持规划过程评估与模型微调;
- 关键结论:自适应规划是提升 MRAG 性能的核心,CogPlanner 在多跳查询、模糊查询场景中优势显著,轻量级模型 Qwen2-7B-VL-Cog 实现性能与效率的平衡。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)