Cross-Modal Retrieval from Coarse-Grained to Fine-Grained Perspectives: A Survey
这篇由北京大学王选计算机技术研究所彭宇新教授团队发表于《Journal of Computer Science and Technology》的综述论文,针对现有跨模态检索(CMR)研究中分类体系过时、细粒度任务覆盖不足、新兴模型影响未充分体现等问题,提出了以 “检索粒度” 为核心的统一分类框架,系统梳理了粗粒度(CCMR)与细粒度(FCMR)跨模态检索的最新进展,涵盖主流方法、数据集、性能对比及应用场景,为该领域提供了全面且前沿的学术参考。
一、研究背景与核心问题
1. 跨模态检索的定义与价值
跨模态检索(CMR)是多媒体理解与推荐系统的核心技术,旨在跨越图像、视频、文本等异质模态的语义鸿沟,根据查询需求检索目标模态信息(如文本查图像、文本查视频)。其核心目标是解决 “异质模态语义对齐” 问题 —— 早期依赖统计相关性分析,现有方法多通过深度学习将不同模态映射到共享特征空间,但仍面临 “难负样本区分” 的关键挑战(即区分视觉相似但语义不同的样本)。
2. 现有研究的局限
传统综述存在三大短板:
- 分类体系僵化:多以 “方法类型” 为分类依据,忽略检索目标的粒度差异,且聚焦粗粒度任务,忽视细粒度需求;
- 新兴模型覆盖不足:未充分纳入视觉 - 语言预训练(VLP)模型(如 CLIP)和多模态大语言模型(MLLMs)的突破性影响;
- 任务关联性割裂:将图像文本检索、图像接地、视频时序接地等任务孤立分析,未揭示其内在联系。
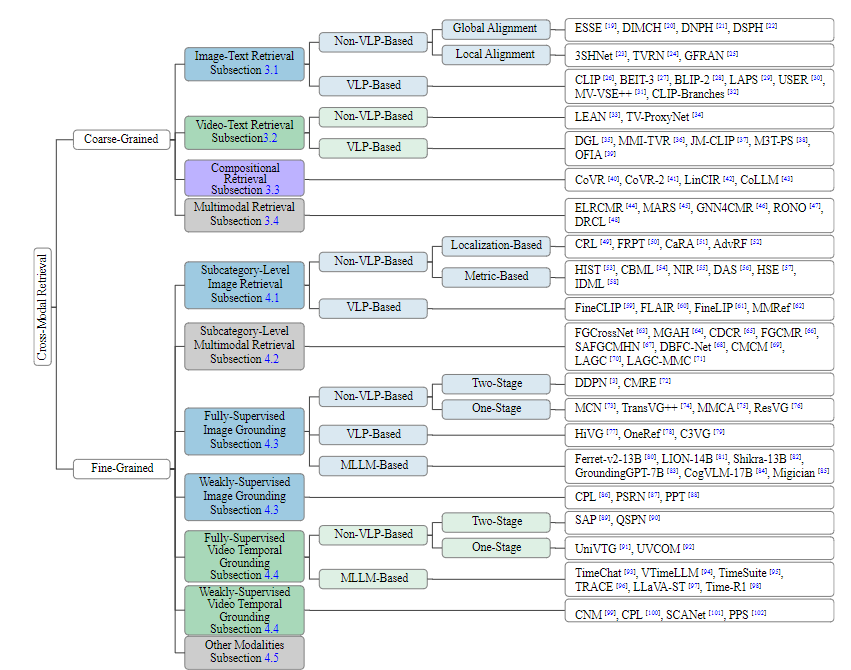
3. 核心创新点
论文提出以 “检索粒度” 为核心的统一分类框架,首次将 CMR 明确划分为粗粒度(CCMR) 和细粒度(FCMR) 两大分支,整合检索与接地类任务,系统分析 VLP 和 MLLMs 的应用价值,填补了现有综述的空白。
二、分类框架:粗粒度与细粒度跨模态检索
1. 分类逻辑与核心区别
分类的核心依据是 “检索目标的语义 / 空间粒度”,两者在任务目标、挑战、模型选择上存在本质差异:
表格
| 维度 | 粗粒度跨模态检索(CCMR) | 细粒度跨模态检索(FCMR) |
|---|---|---|
| 核心目标 | 检索完整实例(如整张图像、完整视频) | 检索子类别或实例局部(如特定鸟类、图像区域、视频片段) |
| 典型任务 | 图像 - 文本检索(ITR)、视频 - 文本检索(VTR) | 子类别检索、图像接地(IG)、视频时序接地(VTG) |
| 关键挑战 | 全局语义匹配,区分不同实例的整体差异 | 局部语义对齐,处理高内类方差、低类间方差的细粒度差异 |
| 模型偏好 | 注重效率,常用哈希编码、双编码器架构 | 注重精度,常用 MLLMs、局部对齐机制 |
| 数据标注需求 | 实例级配对标注(如图文对) | 细粒度标注(如边界框、子类别标签)或弱监督标注 |
2. 任务细分与示例
(1)粗粒度跨模态检索(CCMR)
聚焦完整实例的全局匹配,主要包括 4 类任务:
- 图像 - 文本检索(ITR):文本描述检索对应图像(如 “雪地里玩耍的女孩” 检索相关图像);
- 视频 - 文本检索(VTR):文本查询检索对应视频(如 “大象行走” 检索相关视频);
- 组合检索:参考视觉输入 + 文本修改指令检索目标(如 “参考这张红色裙子图像,检索蓝色版本”);
- 多模态检索:扩展至音频、3D 点云等模态(如音频 - 文本检索、文本 - 3D 模型检索)。
(2)细粒度跨模态检索(FCMR)
聚焦更精细的语义或空间目标,分为 2 类核心任务:
- 子类别级检索:检索特定细分子类别实例(如同属 “鸟类” 的 “加州鸥”,同属 “汽车” 的 “沃尔沃 850 轿车”),需区分视觉相似的不同子类别;
- 实例局部检索:检索实例的空间 / 时序局部(图像接地定位图像区域,如 “中间最小的大象”;视频时序接地定位片段,如 “黄棕色狗吃雪的片段”)。
3. 任务内在关联
- 统一性:均以 “跨模态语义对齐” 为核心,依赖 VLP 模型提供基础表征,本质是 “从候选集中检索最相关目标”;
- 互补性:CCMR 通过局部对齐增强全局匹配精度,FCMR 通过 CCMR 过滤无关实例(如子类别检索先筛选超级类)或转化任务(如两阶段图像接地将局部定位转化为候选区域的粗粒度匹配)。
三、主流方法体系
论文按 “检索粒度 + 技术范式” 梳理了 CCMR 和 FCMR 的核心方法,重点分析非 VLP、VLP、MLLM 三大技术路线的特点与代表性模型。
1. 粗粒度跨模态检索(CCMR)方法
(1)图像 - 文本检索(ITR)
- 非 VLP 方法:分为全局对齐(如 ESSE 通过扇形嵌入捕捉一对多语义对应)和局部对齐(如 3SHNet 通过视觉语义 - 空间自高亮实现细粒度交互),部分结合哈希编码提升效率(如 DIMCH 的多对多对齐哈希框架);
- VLP 方法:采用 “预训练 - 微调” 范式,CLIP 为基础模型,通过多视图学习(MV-VSE++)、知识蒸馏(USER)等优化,兼顾泛化性与任务适配性,是当前主流范式。
(2)视频 - 文本检索(VTR)
- 非 VLP 方法:聚焦视频时序特征提取与跨模态融合(如 LEAN 构建多模态超图建模语义块关系);
- VLP 方法:以 CLIP 为基础,通过提示调优(DGL)、多粒度特征融合(JM-CLIP)、语义标签预筛选(M3T-PS)提升效率与精度,平衡计算成本与性能。
(3)组合检索与多模态检索
- 组合检索:通过语言仅训练(LinCIR)、LLM 辅助查询理解(CoLLM)实现参考输入 + 文本修改的灵活检索;
- 多模态检索:针对音频、3D 等模态,采用对比学习(ELRCMR)、图神经网络(GNN4CMR)、模态质量自适应加权(DRCL)解决异质特征对齐与噪声鲁棒性问题。
2. 细粒度跨模态检索(FCMR)方法
(1)子类别级检索
- 非 VLP 方法:分为定位型(如 CRL 通过弱监督显著性提示提取判别区域)和度量学习型(如 HIST 通过超图语义三元组损失优化嵌入空间);
- VLP 方法:增强 CLIP 的细粒度对齐能力(如 FineCLIP 通过区域对比学习与自蒸馏,FineLIP 扩展长文本建模),或构建多模态参考(MMRef)弥补文本描述不足。
(2)实例局部检索
- 图像接地(IG):
- 非 VLP 方法:两阶段(DDPN 生成多样化候选区域)、一阶段(MCN 联合理解与分割)、Transformer-based(TransVG++ 纯 Transformer 架构);
- VLP 方法:通过低秩适配(HiVG)、掩码参考建模(OneRef)优化预训练模型的接地适配性;
- MLLM 方法:利用大模型推理能力(如 Shikra 将坐标作为词汇,CogVLM 插入视觉专家模块),支持开放词汇与复杂指令理解;
- 视频时序接地(VTG):
- 非 VLP 方法:两阶段(SAP 基于视觉 - 语义相关性生成候选片段)、一阶段(UniVTG 统一标签格式实现大规模预训练);
- MLLM 方法:分为预训练型(TimeChat 构建时序标注数据集)和无训练型(ChatVTG 通过对话生成片段描述匹配查询),零样本性能突出。
(3)弱监督方法
针对细粒度标注成本高的问题,通过粗粒度标注训练细粒度能力:如图像接地的 CPL 利用预训练模型生成区域描述,视频时序接地的 CNM 通过高斯掩码生成候选片段。
四、数据集与评估体系
1. 核心数据集统计
论文汇总了 15 + 主流数据集,覆盖不同任务与模态,关键信息如下:
表格
| 任务类型 | 代表性数据集 | 规模(实例数) | 模态组合 | 核心特点 |
|---|---|---|---|---|
| 图像 - 文本检索 | MS COCO | 12.3 万 | 图像 + 文本 | 80 个类别,5 句 / 图标注 |
| Flickr30k | 3.18 万 | 图像 + 文本 | 场景丰富,支持接地任务扩展 | |
| 视频 - 文本检索 | MSR-VTT | 1 万 | 视频 + 文本 | 20 万句标注,1K 测试集常用 |
| ActivityNet Captions | 2 万 | 视频 + 文本 | 长视频,平均片段 36.2 秒 | |
| 图像接地 | RefCOCO 系列 | 5 万(物体数) | 图像 + 参考文本 | 支持人机、物体接地细分场景 |
| 视频时序接地 | Charades-STA | 6.6 万(视频数) | 视频 + 文本 | 短片段为主,平均 8.1 秒 |
| 细粒度子类别检索 | CUB-200-2011 | 1.18 万 | 图像 + 文本 | 200 种鸟类,细粒度差异显著 |
| PKU FG-XMedia | 5.01 万 | 多模态(4 种) | 200 个细粒度类别,跨模态检索 |
2. 评估指标
- CCMR 核心指标:Recall@K(前 K 结果中正确实例占比)、mAP(平均精度,评估排序质量)、MdR/MnR(中位 / 平均排名,越低越好);
- FCMR 核心指标:IoU@m(交并比,图像 / 视频接地任务,m 取 0.3/0.5/0.7)、Recall@K(子类别检索)。
四、性能对比与关键发现
1. CCMR 性能对比
- 图像 - 文本检索:VLP 方法全面超越非 VLP,BLIP-2 在 Flickr30k 的文本查图像 Recall@1 达 89.7%,哈希方法(如 DIMCH)在 16 位编码下 mAP 达 77.51%,适合大规模场景;
- 视频 - 文本检索:CLIP 衍生模型表现突出,JM-CLIP 在 MSR-VTT 的文本查视频 Recall@1 达 62.5%,MdR 仅 1.0,平衡精度与效率;
- 多模态检索:DRCL 通过模态质量自适应加权,在 PKU XMedia 的平均 mAP 达 0.662,显著优于传统方法。
2. FCMR 性能对比
- 子类别检索:AdvRF 在 CUB-200-2011 的 Recall@1 达 88.0%,LAGC-MMC 在 PKU FG-XMedia 的多模态检索平均 mAP 达 0.622;
- 图像接地:MLLM 方法领先,Ferret-v2-13B 在 RefCOCO 的 IoU@0.5 达 92.64%,OneRef(VLP)达 92.87%,弱监督方法 CPL 接近部分全监督性能;
- 视频时序接地:Time-R1(MLLM)在 Charades-STA 的 IoU@0.5 达 72.2%,弱监督方法 PPS 的 IoU@0.3 达 69.06%,接近早期全监督水平。
3. 关键发现
- VLP 模型是基础:CLIP 等模型为两类检索提供统一表征,其泛化性降低任务适配成本;
- MLLM 优势在 FCMR:因计算成本高,MLLM 仅适用于实例级局部检索(如单图像 / 视频),但开放词汇与推理能力显著提升零样本性能;
- 细粒度方法依赖局部对齐:子类别检索与局部检索均需强化模态内局部特征交互,单纯全局对齐无法区分细微差异。
五、应用场景与未来方向
1. 核心应用
- 数字电商:支持文本 / 语音查询商品图像 / 视频,提升搜索直观性;
- 身份检索:通过外貌、行为描述从监控视频中定位特定人物;
- 智能内容创作:通过自然语言描述检索素材(如 “山巅日落暖光” 的图片 / 视频片段),优化创作流程。
2. 未来研究方向
- 开放域细粒度检索:突破封闭数据集限制,减少对细粒度标注的依赖,实现任意子类别的跨模态检索;
- 统一多模态基础模型:构建支持任意模态、任意粒度检索的通用框架,整合理解、检索、生成能力;
- 数据驱动革命:优化数据集筛选与合成(如 LLM 生成高质量标注),设计衡量 “概念丰富度”“难负样本分布” 的数据集评估指标;
- 用户中心检索:引入交互反馈机制,动态优化查询意图与检索结果,提升用户适配性;
- 新兴模态拓展:将检索扩展至机器人视觉 - 动作、自动驾驶多传感器(相机 + 激光雷达)、医疗多模态(EEG+MRI)等场景。
六、总结
该综述以 “检索粒度” 为核心重构了跨模态检索的分类体系,首次系统整合粗粒度与细粒度任务,全面覆盖非 VLP、VLP、MLLM 三大技术路线,通过数据集统计、性能对比揭示了领域发展规律。其核心贡献在于:明确了任务内在关联,凸显了新兴模型的应用价值,为研究者提供了清晰的学术地图,同时指出的开放域检索、统一基础模型等方向,为该领域的未来发展提供了关键指引。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)