动手学深度学习——PyTorch 神经网络基础:参数管理详解
一、前言
在上一节“模型构造”中,我们已经知道了如何用 PyTorch 定义一个神经网络,比如:
-
用
nn.Sequential搭建顺序模型 -
继承
nn.Module自定义网络 -
在
__init__()中定义层 -
在
forward()中定义前向传播过程
但当我们真正开始训练模型时,很快就会遇到一个更具体的问题:
模型里的参数到底存在哪里?
我们该怎么查看、访问、初始化、共享和修改这些参数?
这就是“参数管理”要解决的核心问题。
因为神经网络训练的本质,说到底就是:
不断更新模型参数,使模型输出越来越接近真实目标。
所以如果不会管理参数,那么:
-
你看不懂模型内部到底学了什么
-
你不会初始化参数
-
你不会冻结某些层
-
你不会做参数共享
-
你也很难真正理解训练过程
因此,这一节虽然表面看起来像是在学 PyTorch 的接口,但实际上它非常关键。
它会帮助我们真正走近神经网络内部。
二、什么是参数管理
所谓参数管理,本质上就是:
对模型中的可学习参数进行查看、访问、修改和组织。
在神经网络中,最常见的参数包括:
-
权重
weight -
偏置
bias
例如一个全连接层:
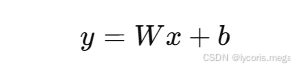
这里的:
-
(W) 就是权重参数
-
(b) 就是偏置参数
训练时优化器不断更新的,就是这些东西。
所以参数管理关注的是:
-
怎么拿到这些参数
-
怎么看它们的形状
-
怎么单独访问某一层的参数
-
怎么对参数做初始化
-
怎么让不同层共享同一组参数
三、为什么参数管理很重要
1. 训练本质上是在更新参数
你如果不知道参数在哪里、长什么样,就等于不知道模型真正学的是什么。
2. 很多高级操作都依赖参数管理
例如:
-
自定义初始化
-
冻结某些层
-
迁移学习
-
参数共享
-
模型保存与加载
这些都离不开参数管理。
3. 它能帮助你理解模型内部结构
一个模型表面看是很多层,往里看其实就是很多参数张量。
学会参数管理之后,你对网络的理解会更“落地”。
四、先看一个简单模型
下面先定义一个最基础的多层感知机:
import torch
from torch import nn
net = nn.Sequential(
nn.Linear(4, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
print(net)
这个模型里有两层线性层:
-
第一层:
Linear(4, 8) -
第二层:
Linear(8, 1)
而真正有参数的是这两层 Linear,中间的 ReLU 没有可学习参数。
五、如何查看某一层的参数
例如我们想查看第二个线性层,也就是:
net[2]
可以直接打印它的参数:
print(net[2].state_dict())
输出通常会类似于:
OrderedDict([
('weight', tensor(...)),
('bias', tensor(...))
])
这说明这个层中包含:
-
weight -
bias
也就是说,state_dict() 可以把该层当前保存的参数状态展示出来。
六、state_dict() 到底是什么
state_dict() 是 PyTorch 里非常重要的一个方法。
它的作用可以理解为:
返回模型当前所有参数和缓冲区的状态字典。
对初学阶段来说,你可以简单把它理解成:
模型参数的“总账本”
比如:
print(net.state_dict())
你会看到整个模型中所有层的参数都被组织在一个字典中,例如:
-
0.weight -
0.bias -
2.weight -
2.bias
这里的 0 和 2 表示 Sequential 中对应层的编号。
七、如何直接访问权重和偏置
如果你只想访问某一层的权重,可以这样写:
print(net[0].weight)
print(net[0].bias)
例如第一层 Linear(4, 8):
-
权重形状通常是
[8, 4] -
偏置形状通常是
[8]
因为这层表示:
[
y = Wx + b
]
输入 4 维,输出 8 维,所以权重矩阵大小就是 8 × 4。
八、param.data 和 param 本身有什么区别
当你访问参数时,比如:
print(net[0].weight)
你拿到的是一个 Parameter 对象,它本质上是特殊的张量。
如果你只想看里面实际的数据值,可以写:
print(net[0].weight.data)
简单理解:
-
weight:是参数对象,包含梯度等训练信息 -
weight.data:更偏向于参数内部的纯数值张量
平时查看数值时,经常会看到 .data。
九、named_parameters():更系统地查看参数
如果你想遍历一个层或整个模型中的参数,可以使用:
for name, param in net.named_parameters():
print(name, param.shape)
输出一般类似:
0.weight torch.Size([8, 4])
0.bias torch.Size([8])
2.weight torch.Size([1, 8])
2.bias torch.Size([1])
这个方法非常实用,因为它可以同时告诉你:
-
参数名字
-
参数形状
这对于调试模型特别方便。
十、parameters() 和 named_parameters() 的区别
这两个方法很像,但有一点差别。
1. parameters()
只返回参数本身:
for param in net.parameters():
print(param.shape)
2. named_parameters()
同时返回参数名称和参数本身:
for name, param in net.named_parameters():
print(name, param.shape)
所以一般来说:
-
只想把参数交给优化器,用
parameters() -
想调试、查看名字,用
named_parameters()
十一、为什么优化器只更新参数层
例如:
optimizer = torch.optim.SGD(net.parameters(), lr=0.1)
这里传进去的是 net.parameters()。
这意味着优化器会自动找到模型中所有可学习参数。
而像 ReLU 这种没有参数的层,不会出现在里面。
所以你会发现:
不是所有层都有参数,只有可学习层才有参数。
比如:
-
Linear有参数 -
Conv2d有参数 -
BatchNorm有参数 -
ReLU没有参数 -
Sigmoid没有参数
十二、如何从嵌套块中访问参数
很多模型不是简单一层层平铺,而是嵌套结构。
例如:
def block1():
return nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
nn.Linear(8, 4), nn.ReLU())
def block2():
net = nn.Sequential()
for i in range(4):
net.add_module(f'block {i}', block1())
return net
rgnet = nn.Sequential(block2(), nn.Linear(4, 1))
print(rgnet)
这个模型会比较复杂,里面套了很多 Sequential。
如果你想访问某个深层参数,可以一层层索引:
print(rgnet[0][1][0].bias.data)
也就是说:
-
rgnet[0]:第一个大块 -
[1]:里面第二个子块 -
[0]:这个子块里的第一层线性层
虽然写起来有点长,但这说明:
PyTorch 的模型结构本质上是可以层层访问的。
十三、如何一次性初始化所有参数
参数管理中最常见的需求之一就是:
自定义初始化。
例如我们想把所有线性层的权重初始化为均值 0、标准差 0.01 的正态分布:
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
net.apply(init_normal)
print(net[0].weight.data[0], net[0].bias.data[0])
这里的核心是:
net.apply(init_normal)
它会把 init_normal 函数递归地应用到模型中的每个子模块。
十四、常见初始化方式有哪些
1. 正态分布初始化
nn.init.normal_(m.weight, mean=0, std=0.01)
2. 常数初始化
nn.init.constant_(m.weight, 1)
nn.init.zeros_(m.bias)
3. Xavier 初始化
nn.init.xavier_uniform_(m.weight)
4. He 初始化
nn.init.kaiming_uniform_(m.weight, nonlinearity='relu')
这些初始化方式你在前面的“模型初始化”博客里已经接触过了。
现在到了参数管理这一节,你会发现它们终于能真正和代码对上了。
十五、如何只初始化某些参数
有时候我们不想把所有层都一样初始化,而是只改某一层。
比如只初始化第一层:
nn.init.normal_(net[0].weight, mean=0, std=0.01)
nn.init.zeros_(net[0].bias)
或者只对名字里包含 weight 的参数做处理:
for name, param in net.named_parameters():
if "weight" in name:
nn.init.normal_(param, mean=0, std=0.01)
这样就更灵活。
十六、可以直接修改参数值吗
可以。
比如:
net[0].weight.data[:] = 42
net[0].bias.data[:] = 0
这表示:
-
第一层所有权重全改成 42
-
第一层所有偏置全改成 0
当然,实际训练中一般不会这么干,但这个例子能说明:
参数本质上就是张量,所以是可以直接操作的。
也正因为如此,PyTorch 在调试和实验时非常灵活。
十七、参数共享是什么意思
参数共享是这一节非常有代表性的内容。
所谓参数共享,就是:
多个地方使用同一组参数,而不是各自拥有独立参数。
例如我们先定义一个共享层:
shared = nn.Linear(8, 8)
然后把它放进网络中多次使用:
net = nn.Sequential(
nn.Linear(4, 8), nn.ReLU(),
shared, nn.ReLU(),
shared, nn.ReLU(),
nn.Linear(8, 1)
)
这里 shared 被用了两次。
十八、为什么说这是“共享”而不是“复制”
因为这里不是重新创建了两个 Linear(8,8),而是:
把同一个层对象用了两次。
所以这两个位置实际指向的是同一组参数。
你可以验证:
print(net[2].weight.data[0] == net[4].weight.data[0])
一般会发现它们完全一样。
进一步,如果你修改其中一个:
net[2].weight.data[0, 0] = 100
print(net[4].weight.data[0, 0])
另一个对应位置也会变化。
这就说明它们确实共享同一份参数。
十九、参数共享有什么用
参数共享在深度学习中非常重要,不只是一个“技巧”。
1. 减少参数量
共享参数后,模型参数更少,内存占用更低。
2. 强制不同位置学习相同模式
例如卷积神经网络本质上就带有参数共享思想。
同一个卷积核在不同位置滑动,其实就是在共享参数。
3. 在某些结构设计中很自然
比如:
-
Siamese Network
-
某些递归结构
-
特定残差或重复模块
所以理解参数共享,对后面学习 CNN 等结构很有帮助。
二十、如何判断参数是不是同一个
有时我们想确认两层参数到底是不是共享的,可以直接比较对象标识:
print(net[2].weight is net[4].weight)
如果结果是 True,就说明它们真的是同一个参数对象,而不是值恰好相等。
这一点比只比较数值更本质。
二十一、这一节的核心思想到底是什么
如果把“参数管理”这一节压缩成一句话,我觉得就是:
模型不是神秘黑箱,本质上就是一组可以被组织、访问、修改和共享的参数。
前面“模型构造”让我们知道了网络怎么搭;
这一节“参数管理”则让我们开始真正接触网络内部。
从这时候开始,你对神经网络的理解就不只是“层和层”,而是:
-
每层里有什么参数
-
参数长什么样
-
参数如何初始化
-
参数如何被优化器更新
-
参数如何被共享和复用
这会让你对模型的认识更深入一层。
二十二、初学者最容易混淆的几个点
1. 不是所有层都有参数
例如 ReLU 没有参数,Linear 才有。
2. state_dict() 看到的是参数状态,不只是权重
它是整个模型参数的总表。
3. parameters() 和 named_parameters() 不一样
前者只有参数,后者还有名字。
4. self.xxx = 某层 才会注册参数
临时变量不会被模型自动管理。
5. 参数共享不是“数值一样”,而是“对象本身就是同一个”
这一点很关键。
二十三、一个适合 CSDN 的完整示例
下面给你一份适合放博客里的完整演示代码:
import torch
from torch import nn
# 1. 定义模型
net = nn.Sequential(
nn.Linear(4, 8),
nn.ReLU(),
nn.Linear(8, 1)
)
# 2. 查看整个模型参数
print("=== state_dict ===")
print(net.state_dict())
# 3. 查看每个参数名字和形状
print("\n=== named_parameters ===")
for name, param in net.named_parameters():
print(name, param.shape)
# 4. 自定义初始化
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
net.apply(init_normal)
print("\n=== 初始化后的第一层权重 ===")
print(net[0].weight.data)
# 5. 参数共享
shared = nn.Linear(8, 8)
net2 = nn.Sequential(
nn.Linear(4, 8), nn.ReLU(),
shared, nn.ReLU(),
shared, nn.ReLU(),
nn.Linear(8, 1)
)
print("\n=== 参数共享验证 ===")
print(net2[2].weight is net2[4].weight)
这段代码基本把本节最核心的内容都串起来了。
二十四、我对这一节的理解
学完“参数管理”之后,我最大的感受是:
以前写神经网络时,更多只是把层堆起来,感觉模型像个整体黑箱;
但这一节让我第一次开始真正把模型拆开来看。
我发现:
-
每一层其实就是若干参数张量
-
参数是可以查看的
-
参数是可以单独初始化的
-
参数甚至还可以共享
这让我对神经网络的理解更具体了。
原来训练模型,不是某种神秘过程,而是在不断调整这些权重和偏置。
所以这一节虽然不像卷积层那样“看起来很炫”,但它非常基础,也非常关键。
二十五、结语
“参数管理”是 PyTorch 神经网络基础中非常重要的一节。
如果说“模型构造”解决的是“怎么搭网络”,那么“参数管理”解决的就是:
怎么真正看懂网络里面的参数,并对它们进行控制。
这一节学扎实之后,后面你再去学:
-
自定义层
-
模型初始化
-
参数冻结
-
卷积网络
-
模型保存与加载
都会轻松很多。
所以建议这一节一定不要只停留在“看懂”,最好自己亲手试一下:
-
state_dict() -
named_parameters() -
apply() -
参数共享
这些操作。
二十六、重点速记版
1. 什么是参数管理
对模型中的权重和偏置进行查看、访问、修改和组织。
2. 查看某层参数用什么
state_dict()
3. 遍历模型参数用什么
parameters() 或 named_parameters()
4. 初始化整个模型常用什么
net.apply(初始化函数)
5. 参数能不能直接改
可以,本质上它们是张量。
6. 什么是参数共享
多个位置使用同一组参数对象。
7. 为什么参数共享重要
可以减少参数量,并让不同位置学习相同模式。
以上就是我对《动手学深度学习》中 PyTorch 神经网络基础——参数管理 这一节的学习整理。
这一节让我对神经网络的理解进一步从“搭结构”深入到了“看参数”。也让我真正明白,模型训练的本质其实就是对这些参数不断进行更新和优化。
对于刚开始学 PyTorch 的同学来说,这一节非常值得自己动手敲一遍。因为只有真正看过参数、改过参数、初始化过参数,后面学习更复杂的网络结构时,才不会一直停留在“黑箱使用”的阶段。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)