动手学深度学习——PyTorch 神经网络基础:模型构造详解
一、前言
在前面学习深度学习基础时,我们已经接触过很多核心概念,比如:
-
线性回归
-
多层感知机
-
模型初始化
-
激活函数
-
数值稳定性
-
房价预测实战
但如果要真正开始写神经网络代码,光理解这些概念还不够,我们还必须掌握一项非常基础、非常核心的能力:
如何在 PyTorch 中构造模型。
也就是说,前面我们更多是在理解“神经网络是什么”,而从这一节开始,我们要逐渐进入:
神经网络在代码里到底怎么定义、怎么组织、怎么调用。
“模型构造”这一节非常重要,因为后面无论是:
-
多层感知机
-
卷积神经网络
-
循环神经网络
-
Transformer
本质上都离不开“如何构造模型”这个基础。
如果这一节学扎实了,后面你看到再复杂的网络结构,也不会觉得神秘,因为你会明白:
再复杂的模型,本质上也只是各种层和运算模块按一定方式组合起来而已。
二、什么叫模型构造
所谓模型构造,本质上就是:
用代码把神经网络的结构描述出来。
比如一个最简单的神经网络:
-
输入层
-
一个全连接层
-
一个 ReLU 激活函数
-
再接一个输出层
我们就需要用 PyTorch 代码把它写出来。
也就是说,模型构造解决的问题是:
-
这一层是什么
-
下一层接什么
-
数据怎么从前往后流动
-
每一层的参数由谁管理
-
最终整个网络怎样表示
简单说:
模型构造,就是把“网络结构图”翻译成 PyTorch 代码。
三、为什么模型构造很重要
这一节看上去像是在学 API,但其实它远不只是“会不会调函数”这么简单。
1. 它决定你能不能把想法写成网络
很多时候我们脑子里能想出一个结构,但如果不会模型构造,就写不出来。
2. 它是后面所有神经网络的基础
后面学卷积层、循环层、自定义层时,本质上都建立在模型构造能力之上。
3. 它能帮助你真正理解“网络是怎么组成的”
会搭模型之后,你会慢慢发现:
-
网络不是一个黑箱
-
模型不是“系统自动出来的”
-
所有复杂结构都可以拆成一个个模块
这对后续深入学习非常重要。
四、PyTorch 中模型构造的核心思想
PyTorch 在设计神经网络时,有一个很重要的思想:
把网络中的每一层,都看成一个模块(Module)。
比如:
-
全连接层是一个模块
-
卷积层是一个模块
-
激活函数也可以是一个模块
-
整个神经网络本身也可以是一个更大的模块
也就是说,在 PyTorch 里:
大模型 = 小模块的组合
这正符合深度学习的结构特点。
五、PyTorch 中最核心的类:nn.Module
在 PyTorch 里,几乎所有模型构造都离不开一个核心类:
nn.Module
它可以理解成:
所有神经网络模块的“基类”。
也就是说:
-
一个线性层是
nn.Module -
一个卷积层是
nn.Module -
一个完整网络也是
nn.Module
如果你要自己定义一个神经网络,通常都要:
继承
nn.Module
例如:
import torch
from torch import nn
class MyModel(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
这个写法虽然简单,但它已经体现了 PyTorch 模型构造最基本的框架。
六、构造模型时最常见的两个部分
一个自定义神经网络,通常包含两个关键部分。
1. __init__()
这个函数主要负责:
定义网络中要用到的层和参数。
比如:
-
nn.Linear -
nn.Conv2d -
nn.ReLU
这些通常都写在 __init__() 里。
2. forward()
这个函数主要负责:
定义数据前向传播的计算过程。
也就是说,输入 x 进来之后:
-
先经过哪一层
-
再经过哪一层
-
最后输出什么
这些逻辑都写在 forward() 中。
所以可以简单理解成:
-
__init__():先把零件准备好 -
forward():再规定这些零件怎么拼起来用
七、先看一个最简单的模型构造例子
下面先看一个非常基础的两层全连接网络:
import torch
from torch import nn
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
x = self.hidden(x)
x = torch.relu(x)
x = self.out(x)
return x
这个模型表示:
-
输入维度是 20
-
第一层映射到 256 维
-
再经过 ReLU
-
最后输出 10 维
如果实例化:
net = MLP()
print(net)
你就得到了一个完整可用的网络。
八、这段代码应该怎么理解
这一段代码非常典型,几乎是以后写各种网络的模板。
1. class MLP(nn.Module)
表示我们定义了一个新的神经网络类,它继承自 nn.Module。
2. super().__init__()
调用父类初始化函数。
这是必须写的,否则 nn.Module 的很多功能无法正常使用。
3. self.hidden = nn.Linear(20, 256)
定义一个全连接层,从 20 维输入变成 256 维输出。
4. self.out = nn.Linear(256, 10)
定义输出层,从 256 维映射到 10 维。
5. forward(self, x)
规定数据前向传播时的路径。
即:
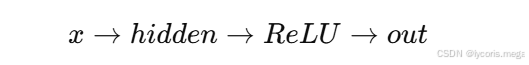
所以这就是一个标准的前馈神经网络。
九、为什么 forward 很重要
很多初学者会把注意力只放在“定义了哪些层”,但其实:
真正决定模型计算逻辑的,是
forward()。
因为层只是摆在那里,而数据到底按什么顺序流动,是由 forward() 决定的。
例如你完全可以在 forward() 里写出不同的逻辑:
-
顺序执行
-
分支结构
-
残差连接
-
拼接操作
-
跳跃连接
所以:
__init__()更像是“备好组件”,forward()才是真正“搭建计算图”。
这也是 PyTorch 非常灵活的原因之一。
十、Sequential:更简单的模型构造方式
如果一个模型只是单纯按顺序一层接一层,没有复杂分支,那么 PyTorch 提供了更简单的写法:
nn.Sequential
例如:
import torch
from torch import nn
net = nn.Sequential(
nn.Linear(20, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
print(net)
这段代码和前面手写的 MLP 本质上差不多,表示的仍然是:
-
线性层
-
ReLU
-
线性层
十一、Sequential 的优点和局限
1. 优点
nn.Sequential 的优点很明显:
-
写法简洁
-
结构直观
-
很适合简单顺序模型
-
初学时特别好理解
2. 局限
但它也有明显限制:
-
不适合复杂分支结构
-
不适合需要中间变量反复使用的模型
-
不适合残差连接等非顺序结构
所以一般来说:
-
简单网络:
nn.Sequential -
复杂网络:继承
nn.Module自定义
十二、模型中的参数是怎么管理的
PyTorch 一个特别方便的地方在于:
只要你把层定义成
self.xxx = 某层,它的参数就会被自动注册和管理。
例如:
self.hidden = nn.Linear(20, 256)
这时候 hidden 里的权重和偏置都会自动成为模型参数。
你可以直接查看:
net = MLP()
print(net.state_dict())
或者:
for name, param in net.named_parameters():
print(name, param.shape)
这说明在 PyTorch 里,我们不用手动一个个管理参数,框架已经帮我们组织好了。
十三、为什么层一定要写成 self.xxx
这一点很重要。
如果你只是写:
hidden = nn.Linear(20, 256)
而不是:
self.hidden = nn.Linear(20, 256)
那么这个层不会被当成模型的一部分正式注册。
后果就是:
-
参数可能不会被优化器看到
-
state_dict()里不会完整记录 -
模型保存和加载会出问题
所以在 __init__() 中定义层时,通常必须写成:
self.层名 = 某个层
十四、调用模型时发生了什么
当我们写:
y = net(x)
表面上看是在“调用对象”,但本质上 PyTorch 内部会自动去执行:
net.forward(x)
也就是说,模型对象本身像一个函数一样可以被调用。
例如:
X = torch.rand(2, 20)
net = MLP()
Y = net(X)
print(Y.shape)
如果输出层是 10 维,那么结果形状通常就是:
torch.Size([2, 10])
表示:
-
输入有 2 个样本
-
每个样本输出 10 维结果
十五、模型构造不只是“搭层”,还是“搭计算过程”
很多人学到这里,会觉得模型构造就是:
-
定义几个层
-
顺序调用一下
但实际上更深入一点看:
神经网络模型构造,本质上是在定义一个输入到输出的计算过程。
这个过程不一定是简单直线型的,它可能包含:
-
条件判断
-
循环
-
跳跃连接
-
多输入多输出
所以 PyTorch 非常强调 forward() 的灵活性。
因为真实神经网络结构,往往没有那么规整。
十六、一个稍微完整一点的例子
下面给你一个更适合 CSDN 展示的完整例子:
import torch
from torch import nn
from torch.nn import functional as F
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(20, 64)
self.hidden2 = nn.Linear(64, 32)
self.output = nn.Linear(32, 10)
def forward(self, x):
x = F.relu(self.hidden1(x))
x = F.relu(self.hidden2(x))
x = self.output(x)
return x
net = MLP()
X = torch.rand(4, 20)
Y = net(X)
print(net)
print(Y.shape)
这个模型表示:
-
输入 20 维
-
第一隐藏层 64 维
-
第二隐藏层 32 维
-
输出 10 维
输入 4×20 的张量后,输出会是 4×10。
十七、ReLU 为什么有时写成函数,有时写成层
你可能会发现,ReLU 有两种常见写法。
写法一:函数式写法
x = torch.relu(x)
或者:
from torch.nn import functional as F
x = F.relu(x)
写法二:模块式写法
self.relu = nn.ReLU()
x = self.relu(x)
这两种写法都可以。
一般来说:
-
简单情况下,函数式写法更方便
-
如果想让整体结构更统一、更模块化,可以用
nn.ReLU()
十八、模型打印出来的东西说明了什么
当你执行:
print(net)
通常会看到类似:
MLP(
(hidden1): Linear(in_features=20, out_features=64, bias=True)
(hidden2): Linear(in_features=64, out_features=32, bias=True)
(output): Linear(in_features=32, out_features=10, bias=True)
)
这说明:
-
模型中有哪些层
-
每层输入输出维度是多少
-
是否带偏置项
这对检查模型结构很有帮助。
平时写完模型后,最好都先 print(net) 看一眼。
十九、这一节最核心的学习目标
如果要把“模型构造”这一节浓缩成几个核心点,我觉得应该掌握下面这些。
1. 知道 nn.Module 是所有模型的基础
以后自定义模型基本都离不开它。
2. 明白 __init__() 和 forward() 的分工
-
__init__()定义层 -
forward()定义计算流程
3. 会写简单的 nn.Sequential
适合快速搭建顺序模型。
4. 会继承 nn.Module 自定义网络
这是更通用、更重要的能力。
5. 理解模型调用本质上是在执行前向传播
写 net(x) 时,本质上就是在跑 forward()。
二十、初学者最容易犯的几个错误
这一节虽然不难,但特别容易出一些低级错误。
1. 忘记写 super().__init__()
这会导致父类没有正确初始化。
2. 在 __init__() 里定义层时没写 self.
这样层不会被模型注册。
3. forward() 里数据流顺序写错
比如输入输出维度接不上。
4. 只会写 Sequential,不会写自定义类
一旦遇到复杂模型就容易卡住。
5. 搞不清“定义层”和“真正执行计算”的区别
层只是放在那,真正的运算是在 forward() 里发生的。
二十一、我对这一节的理解
学这一节之前,我对神经网络的理解更多还停留在“图示层面”:
-
一层接一层
-
输入到输出
-
中间加激活函数
但真正写了 PyTorch 模型构造之后,我才慢慢意识到:
神经网络其实不是一个抽象黑箱,而是一个可以被清晰拆解、清晰组织的程序结构。
也就是说,我们在写模型时,实际上是在用代码描述一个计算图。
每一层是什么、怎么连、怎么前向传播,都是由我们自己明确写出来的。
这一点很重要,因为后面网络一复杂,如果没有这种“模块化理解”,很容易被结构吓到。
二十二、结语
“PyTorch 神经网络基础:模型构造” 是后续所有深度学习代码学习的起点。
这一节看起来只是学几个写法,但实际上它帮我们完成了一个非常重要的转变:
从“会看懂神经网络概念”,走向“会亲手把神经网络写出来”。
只要把这一节掌握好,后面无论是参数管理、自定义层、卷积层,还是更复杂的模型结构,都会更容易上手。
所以这一节一定不要只是“看懂”,最好亲手多敲几遍代码,真正熟悉:
-
nn.Module -
__init__() -
forward() -
nn.Sequential
这些最基础的模型构造方法。
二十三、重点速记版
1. 什么是模型构造
就是用代码把神经网络结构写出来。
2. PyTorch 中模型构造的核心基类是什么
nn.Module
3. __init__() 做什么
定义层和参数。
4. forward() 做什么
定义前向传播过程。
5. nn.Sequential 适合什么
适合简单顺序模型。
6. 为什么定义层要写 self.xxx
这样参数才能被自动注册和管理。
7. 调用 net(x) 本质是什么
本质是在执行 forward(x)。
以上就是我对《动手学深度学习》中 PyTorch 神经网络基础——模型构造 这一节的学习整理。
这一节虽然是代码入门部分,但非常关键,因为它决定了后面我们能不能真正把网络结构写出来。
对刚开始学 PyTorch 的同学来说,建议一定要自己多写几遍 nn.Sequential 和继承 nn.Module 的两种写法,把“定义层”和“定义前向传播”这两个概念彻底弄清楚。这样后面学习卷积神经网络、自定义层、参数管理时才会更加顺畅。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)