Redis 常用数据结构以及单线程模型
数据结构和内部编码
type 命令实际返回的就是当前键的数据结构类型,它们分别是:string(字符串)、list(列表)、hash(哈希)、set(集合)、zset(有序集合),但这些只是 Redis 对外的数据结构。
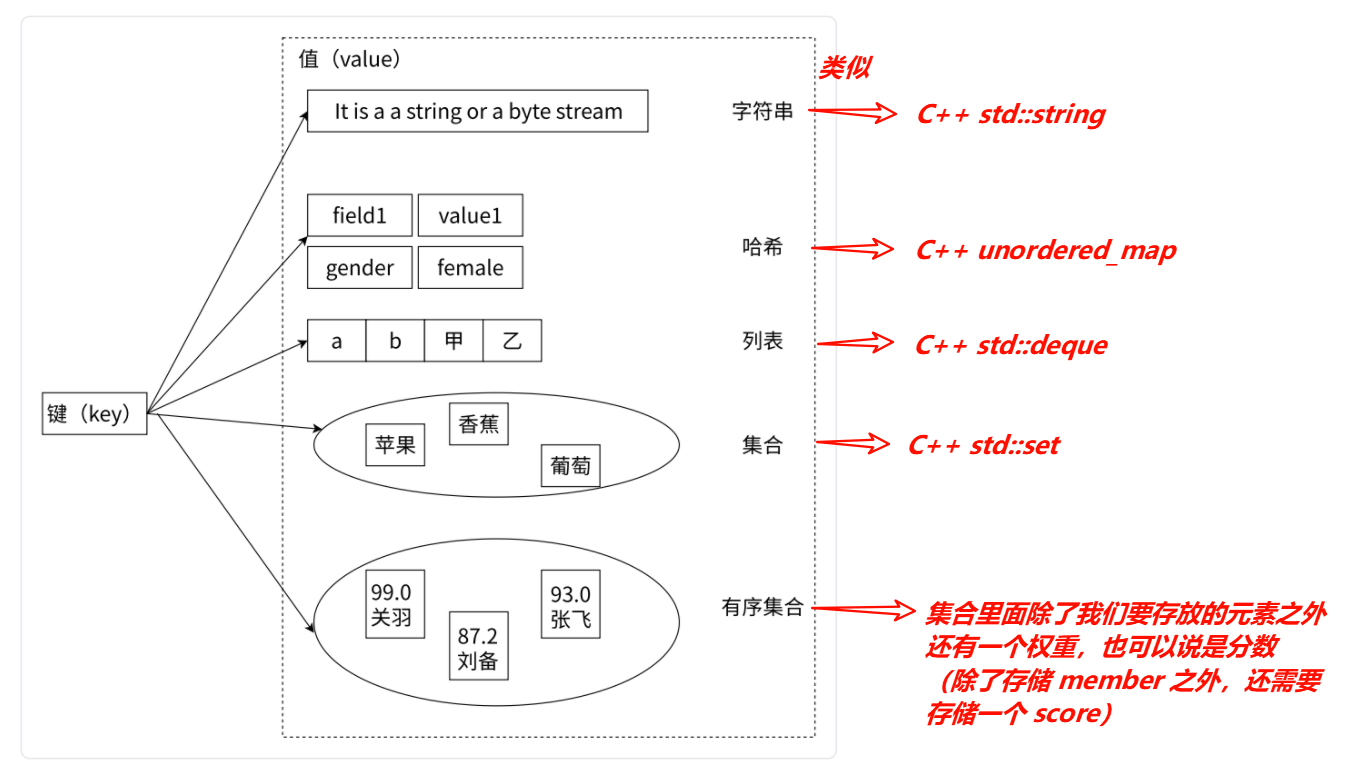
Redis 在底层实现上述数据结构时候,会在源码层面,针对上述的实现进行特定的优化,来达到节省时间/空间的效果,这个优化指的是其在内部的具体实现,编码方式还有变数,也就是说:
实际上 Redis 针对每种数据结构都有自己的底层内部编码实现,而且是多种实现,这样 Redis 会在合适的场景选择合适的内部编码。
Redis 承诺,现在我这有一个 hash 表,你进行查询,插入,删除操作都保证是 O(1),但是背后的实现不一定是一个标准的 hash 表,可能在特定的场景下,使用别的数据结构实现,保证时间复杂度符合承诺!!!
具体例如,list 数据结构包含了 linkedlist 和 ziplist 两种内部编码。同时有些内部编码,例如 ziplist,可以作为多种数据结构的内部实现,可以通过 object encoding 命令查询内部编码:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> lpush mylist a b c
(integer) 3
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> object encoding mylist
"quicklist"可以看到 hello 对应值的内部编码是 embstr,键 mylist 对应值的内部编码是 ziplist。
Redis 这样设计有两个好处:
-
可以改进内部编码,而对外的数据结构和命令没有任何影响,这样一旦开发出更优秀的内部编码,无需改动外部数据结构和命令。
-
多种内部编码实现,也就是 Redis 内部底层实现,可以在不同场景下发挥各自的优势,例如
ziplist较为节省内存,但是在列表元素较多的情况下,性能会下降,这时候 Redis 会根据配置选项将列表类型的内部实现转换为linkedlist,整个过程用户同样无感知。

Redis 会自动适应内部编码!
- raw:底层就是持有一个 char 数组。
- int:Redis 通常也可以用来实现 “计数” 的功能 —— 点赞计数,当 value 就是一个整数的时候,Redis 就会直接使用 int 来保存。
- embstr:针对短字符串进行的特殊优化,这样占据的空间会比较小,大了就转成 raw。
- hashtable:这就是最基本的哈希表。
- ziplist:压缩列表,针对特殊的场景下,就是在哈希表里面元素比较少的时候,可能就优化成了 ziplist 了,可以节省空间。遍历的过程因为量少也是 O (1) 的。
- linkedlist:就是普通的链表。Redis 3.2 开始引入了 quicklist 来代替了 list 的上面这两种内部编码。
- intset:集合中存放的都是整数,就会优化成 intset。
- skiplist:跳表,有一链表面试题,《复杂链表复制:有一个指针乱指》和这题有点相似,每个节点上有多个指针域,巧妙的搭配这些指针域的指向,就可以做到从跳表上查询元素的时间复杂度是 O (logN)。
单线程架构
Redis 使用了单线程架构来实现高性能的内存数据库服务,我们接下来首先通过多个客户端命令调用的例子说明 Redis 单线程命令处理机制,接着分析 Redis 单线程模型为什么性能如此之高,最终给出为什么理解单线程模型是使用和运维 Redis 的关键。
我们需要注意:Redis 只使用一个线程,处理所有的命令请求,不是说一个 Redis 服务器进程内部真的就只有一个线程。其实也有多个线程,但是多个线程是在处理网络 IO 请求 --- 从网卡,或者 socket 上面读到数据之后,就会将数据交给那一个核心的主线程处理!
引出单线程模型:现在开启了三个 redis-cli 客户端同时执行命令。
-
客户端 1 设置一个字符串键值对:
127.0.0.1:6379> set hello world
-
客户端 2 对
counter做自增操作:
127.0.0.1:6379> incr counter
-
客户端 3 对
counter做自增操作:
127.0.0.1:6379> incr counter
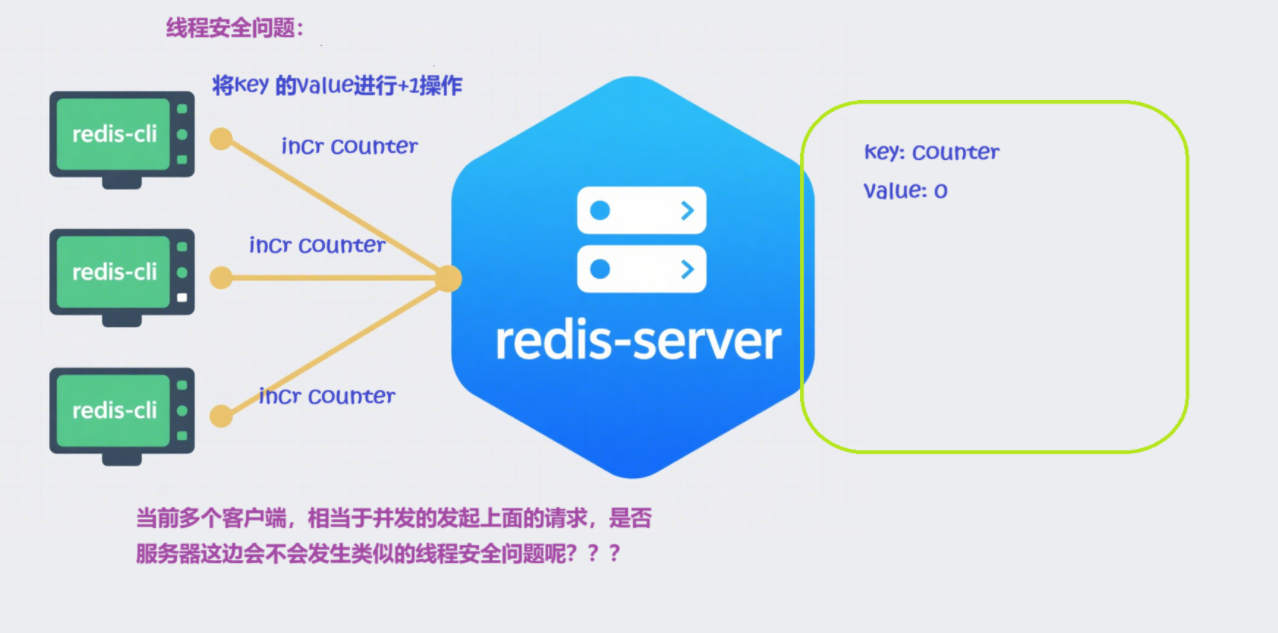
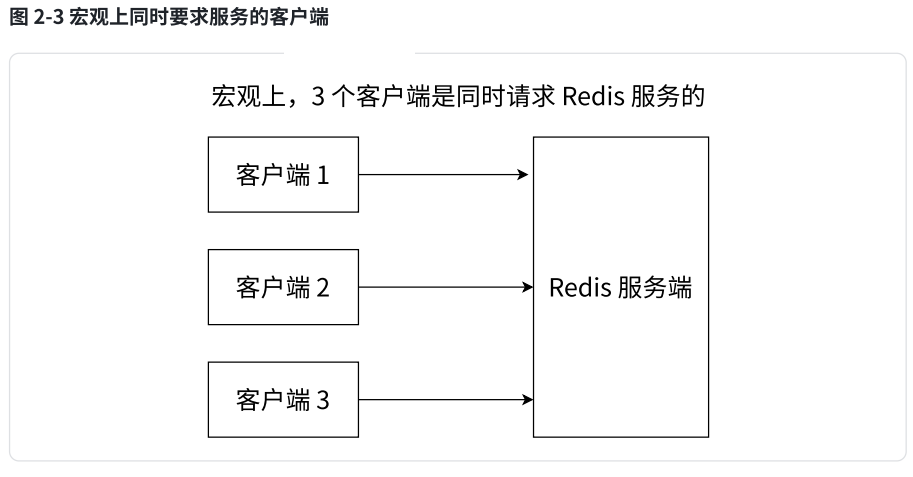
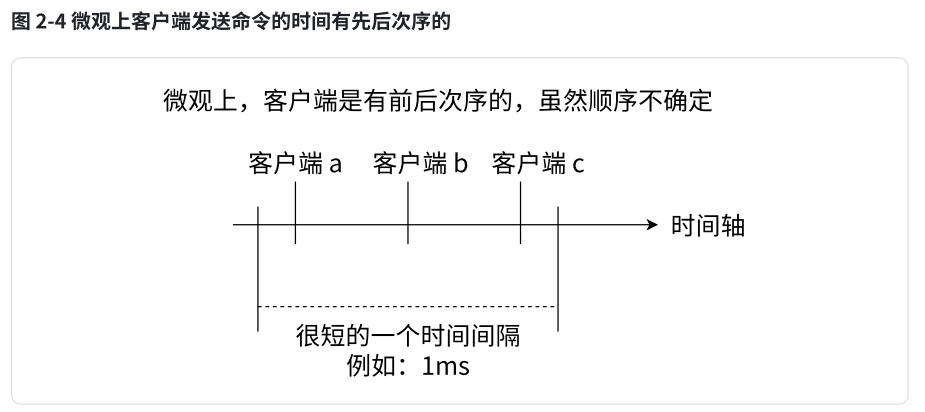
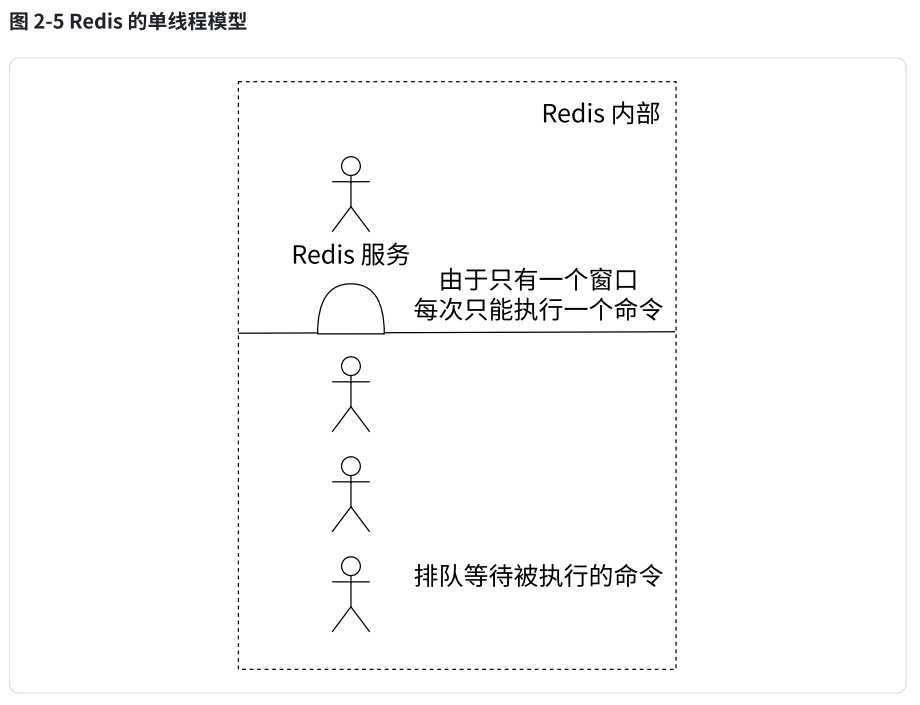
我们已经知道从客户端发送的命令经历了:发送命令、执行命令、返回结果三个阶段,其中我们重点关注第 2 步。我们所谓的 Redis 是采用单线程模型执行命令的是指:虽然三个客户端看起来是同时要求 Redis 去执行命令的,但微观角度,这些命令还是采用线性方式去执行的,只是原则上命令的执行顺序是不确定的,但一定不会有两条命令被同步执行,例如 Redis 内部只有一个服务窗口,多个客户端按照它们达到的先后顺序被排队在窗口前,依次接受 Redis 的服务,所以两条 incr 命令无论执行顺序,结果一定是 2,不会发生并发问题,这个就是 Redis 的单线程执行模型保证收到的多个请求是串行执行的。
为什么单线程还能这么快?--- 经典面试题
通常来讲,单线程处理能力要比多线程差,例如有 10000 公斤货物,每辆车的运载能力是每次 200 公斤,那么要 50 次才能完成;但是如果有 50 辆车,只要安排合理,只需要依次就可以完成任务。那么为什么 Redis 使用单线程模型会达到每秒万级别的处理能力呢?
可以将其归结为三点:
a. 纯内存访问。Redis 将所有数据放在内存中,内存的响应时长约为 100 纳秒,这是 Redis 达到每秒万级别访问的重要基础。
b. 非阻塞 IO。Redis 使用 epoll 作为 I/O 多路复用技术的实现,再加上 Redis 自身的事件处理模型将 epoll 中的连接、读写、关闭都转换为事件,不在网络 I/O 上浪费过多的时间。(一个线程,就可以管理多个 socket,针对 TCP 来说,服务器这边每次要服务一个客户端,都需要给这个客户端安排一个 socket,一个服务端多个客户端,同时就会有很多 socket,这些 socket 上都是无时不刻的在传输数据吗?并不是,同一时刻,只有少数 socket 是活跃的,就可以使用多路复用!)
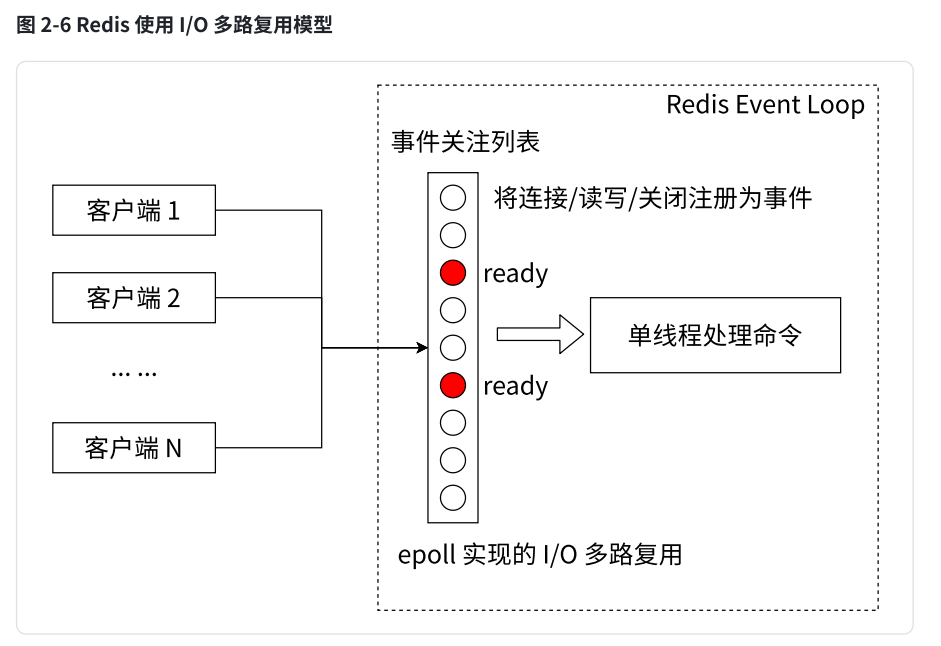
epoll 本身在调用 epoll_wait 等待事件时是阻塞的,但它只阻塞等待有没有任何 socket 就绪,而不是阻塞在某个具体连接的读写上;Redis 是单线程模型,epoll_wait 等待事件、IO 读写以及命令执行都在同一个主线程里,不存在专门的事件线程和工作线程。之所以叫非阻塞 IO,是因为 Redis 把所有 socket 都设置为非阻塞模式,只在 socket 就绪时才去读写,不会因为没数据而卡住线程,epoll 只是负责告诉主线程哪些 socket 已经就绪,主线程再去处理。
c. 单线程避免了线程切换和竞态产生的消耗。单线程可以简化数据结构和算法的实现,让程序模型更简单;其次避免了多线程在线程竞争同一份共享数据时带来的切换和等待消耗。
虽然单线程给 Redis 带来很多好处,但还是有一个致命的问题:对于单个命令的执行时间都是有要求的。如果某个命令执行过长,会导致其他命令全部处于等待队列中,迟迟等不到响应,造成客户端的阻塞,对于 Redis 这种高性能的服务来说是非常严重的,所以 Redis 是面向快速执行场景的数据库。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)