【RL】MiniMax-M1: CISPO + Lightning Attention
note
- CISPO是2025年6月minimax提出,放到今天还是有价值的。
- CISPO强化学习:
- 传统 PPO / GRPO 这类方法,在做 token 级 clipping 时,会把一些“低概率但很关键”的 token(这类token一般是反思、转折、纠错、重新检查等字符,类似思维拐点) 更新给压掉,如果都被clip掉,模型就不容易学会真正的长链反思。
- 通过裁剪重要性采样权重而不是更新令牌来稳定训练,从而避免了传统PPO/GRPO算法中的令牌裁剪问题。
- 模型架构优化:它不是纯标准 softmax attention,也不是全线性 attention,
而是一个 hybrid attention:- 大部分层用 lightning attention:线性/闪电注意力负责把长序列成本压低
- 每隔几层再插一个普通 softmax attention(每 7 个 transnormer/lightning attention block 后接 1 个 softmax attention block):少量 softmax attention 负责保住全局建模能力
- 训练态和推理态概率不一致,他们发现 hybrid architecture 下:training-mode 的 token probability、inference-mode 的 token probability,本来理论上应该一致,结果实际不一致,直接影响 RL reward 增长。最后他们查到主要问题在 LM output head 的精度,把输出头提到 FP32 后,这个问题才缓解。
- MiniMax-M1模型在多个复杂场景中表现出色,特别是在软件工程、长上下文和工具使用方面。
- 软件工程:在SWE-bench验证任务上,MiniMax-M1取得了56.0%的准确率,显著优于其他开源模型。
- 长上下文理解:在OpenAI-MRCR(1M)任务上,MiniMax-M1取得了58.6%的准确率,排名全球第二,仅次于最新的DeepSeek-R1-0528模型。
- 工具使用:在TAU-bench(retail)任务上,MiniMax-M1取得了67.8%的准确率,超过了所有其他开源模型,甚至超过了Gemini-2.5 Pro。
文章目录
一、研究背景
- 研究问题:这篇文章要解决的问题是如何有效地扩展测试时计算能力,以便在大规模推理任务中提高模型的性能。具体来说,作者提出了MiniMax-M1,这是世界上第一个开源的大规模混合注意力推理模型,结合了闪电注意力机制。
- 研究难点:该问题的研究难点包括:传统Transformer架构中softmax注意力的二次计算复杂度限制了推理长度的扩展;现有的优化技术(如稀疏注意力、线性注意力等)在大规模推理模型中尚未得到充分验证。
- 相关工作:该问题的研究相关工作包括OpenAI的o1和DeepSeek-R1等模型,这些模型通过大规模强化学习在复杂任务中取得了显著进展。然而,这些模型仍然依赖于传统的注意力设计,且扩展推理过程具有挑战性。
二、MiniMax-M1模型
1、模型架构变化
- 混合专家(MoE)架构:MiniMax-M1采用了混合MoE架构,结合了多个专家网络来处理不同的输入子集。每个Transformer块后跟随一个闪电注意力模块,理论上可以实现对数百个千token长度的推理。
- 闪电注意力机制:闪电注意力是一种I/O感知的线性注意力变体,通过减少计算复杂度来实现高效的扩展。其核心思想是将长序列的注意力映射到一个低频的傅里叶域上,从而降低计算复杂度。
MiniMax-M1模型采用了闪电注意力机制,这是一种I/O感知的线性注意力变体。其核心思想是将长序列的注意力映射到一个低频的傅里叶域上,从而降低计算复杂度。具体来说,闪电注意力通过以下步骤实现高效扩展:
- 傅里叶注意力映射:将长序列的注意力映射到傅里叶域上,减少了计算复杂度。
- 动态采样和长度惩罚:采用动态采样和长度惩罚技术,进一步降低计算开销。
- I/O感知设计:闪电注意力机制特别适用于I/O密集型任务,能够在保持高效计算的同时,处理长序列输入。
这些创新使得MiniMax-M1模型能够在大规模推理任务中显著提高计算效率,特别是处理长输入和复杂推理任务时表现出色。
2、CISPO强化学习算法
- 新算法CISPO:为了进一步提高RL训练效率,作者提出了一种新的RL算法CISPO。CISPO通过裁剪重要性采样权重而不是更新令牌来稳定训练,从而避免了传统PPO/GRPO算法中的令牌裁剪问题。具体公式如下: J CISPO ( θ ) = E ( q , a ) ∼ D , { o i } i = 1 G ∼ π θ old [ 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ r ^ i , t ( θ ) A ^ i , t ] \mathcal{J}_{\text{CISPO}}(\theta) = \mathbb{E}_{(q, a) \sim \mathcal{D}, \{o_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|o_i|} \sum_{t=1}^{|o_i|} \hat{r}_{i,t}(\theta) \hat{A}_{i,t} \right] JCISPO(θ)=E(q,a)∼D,{oi}i=1G∼πθold G1i=1∑G∣oi∣1t=1∑∣oi∣r^i,t(θ)A^i,t
其中, r ^ i , t ( θ ) \hat{r}_{i,t}(\theta) r^i,t(θ) 是裁剪后的重要性采样权重:
r ^ i , t ( θ ) = clip ( r i , t ( θ ) , 1 − ϵ low , 1 + ϵ high ) \hat{r}_{i,t}(\theta) = \text{clip}\left(r_{i,t}(\theta), 1 - \epsilon_{\text{low}}, 1 + \epsilon_{\text{high}}\right) r^i,t(θ)=clip(ri,t(θ),1−ϵlow,1+ϵhigh)

你直觉上看到:
- GRPO: min ( r A , clip ( r ) A ) \min(rA, \text{clip}(r)A) min(rA,clip(r)A)
- CISPO: clip ( r ) A log π θ \text{clip}(r) A \log \pi_\theta clip(r)Alogπθ
会觉得都用了 clip,好像差不多。
但真正差别是:
1) GRPO 被 clip 后,很多 token 会“没梯度”
GRPO的loss是 L G R P O = − min ( r t A t , clip ( r t ) A t ) L_{\mathrm{GRPO}}=-\min \left(r_t A_t, \operatorname{clip}\left(r_t\right) A_t\right) LGRPO=−min(rtAt,clip(rt)At)
当 A > 0 A > 0 A>0 且 r > 1 + ϵ r > 1 + \epsilon r>1+ϵ 时,GRPO 里:
min ( r A , ( 1 + ϵ ) A ) = ( 1 + ϵ ) A \min(rA, (1 + \epsilon)A) = (1 + \epsilon)A min(rA,(1+ϵ)A)=(1+ϵ)A
这项对 θ \theta θ 来说就是个常数,因为 clip 后那个边界值不再随 θ \theta θ 变。所以这部分 token 的梯度没了,等价于:这个 token 被 mask 掉了,不再继续学。论文后面其实把它写成了一个显式 mask 形式:
如果 A > 0 A > 0 A>0 且 r > 1 + ϵ high r > 1 + \epsilon_{\text{high}} r>1+ϵhigh,或者 A < 0 A < 0 A<0 且 r < 1 − ϵ low r < 1 - \epsilon_{\text{low}} r<1−ϵlow,那 M i , t = 0 M_{i,t} = 0 Mi,t=0。也就是这个 token 的更新直接被关掉。
比如 ϵ \epsilon ϵ为0.2,对应的min结果为:
min ( r A , clip ( r ) A ) = { r A , r < 0.8 r A , 0.8 ≤ r ≤ 1.2 1.2 A , r > 1.2 \min (r A, \operatorname{clip}(r) A)= \begin{cases}r A, & r<0.8 \\ r A, & 0.8 \leq r \leq 1.2 \\ 1.2 A, & r>1.2\end{cases} min(rA,clip(r)A)=⎩
⎨
⎧rA,rA,1.2A,r<0.80.8≤r≤1.2r>1.2
而被clip的低概率token的梯度就为0了。
2) CISPO 被 clip 后,token 还有梯度
CISPO 是:
r ^ A log π θ \hat{r} A \log \pi_\theta r^Alogπθ
其中 r ^ = clip ( r ) \hat{r} = \text{clip}(r) r^=clip(r)。论文明确说它是“clip importance sampling weight”,而不是像 PPO/GRPO 那样 clip token updates。
具体看:
图中的sg是detach函数,参考如下:
如果写成
L = detach ( x ) ⋅ y L=\operatorname{detach}(x) \cdot y L=detach(x)⋅y
那求导时,detach ( x ) (x) (x) 被当常数,所以:
∂ L ∂ θ = 0 ⋅ y + detach ( x ) ∂ y ∂ θ \frac{\partial L}{\partial \theta}=0 \cdot y+\operatorname{detach}(x) \frac{\partial y}{\partial \theta} ∂θ∂L=0⋅y+detach(x)∂θ∂y
也就是第一项没了,变成:
∂ L ∂ θ = detach ( x ) ∂ y ∂ θ \frac{\partial L}{\partial \theta}=\operatorname{detach}(x) \frac{\partial y}{\partial \theta} ∂θ∂L=detach(x)∂θ∂y
所以 detach 的本质就是:保留 x x x 的数值,但令 ∂ x ∂ θ = 0 \frac{\partial x}{\partial \theta}=0 ∂θ∂x=0
三、模型训练
第一步:继续预训练
他们在 base model 上又继续训了 7.5T tokens,
而且特别提高了:STEM、code、books、reasoning 相关数据,这些数据占比提高到 70%。
第二步:SFT 冷启动
再做一轮 SFT,给模型灌入想要的 CoT pattern,
尤其是 long CoT、reflection 风格的回答。
第三步:大规模 RL
然后才是核心的 RL scaling。
而且 RL 数据不只做数学和代码,还做了很杂的任务:
数学推理
逻辑推理
竞赛编程
软件工程 sandbox
问答
创意写作
instruction following 等
它不是只把模型训成奥数/代码刷题机,而是想把它训成更 agentic 的 reasoning model。
三、实验设计
- 数据收集:实验数据包括数学推理、逻辑推理、编程竞赛、软件工程和一般领域任务。数据来源包括公开数学竞赛、GitHub仓库、合成数据框架SynLogic等。
- 实验设置:MiniMax-M1模型在7.5T令牌的数据上进行预训练,然后在监督微调阶段注入特定的链式思维(CoT)模式。RL训练在多种环境中进行,包括数学推理、逻辑推理、编程竞赛和软件工程任务。
- 参数配置:模型使用AdamW优化器,初始学习率为8e-5,训练过程中逐步衰减。为了应对计算精度不匹配问题,将LM输出头的精度提高到FP32。
四、实验结果
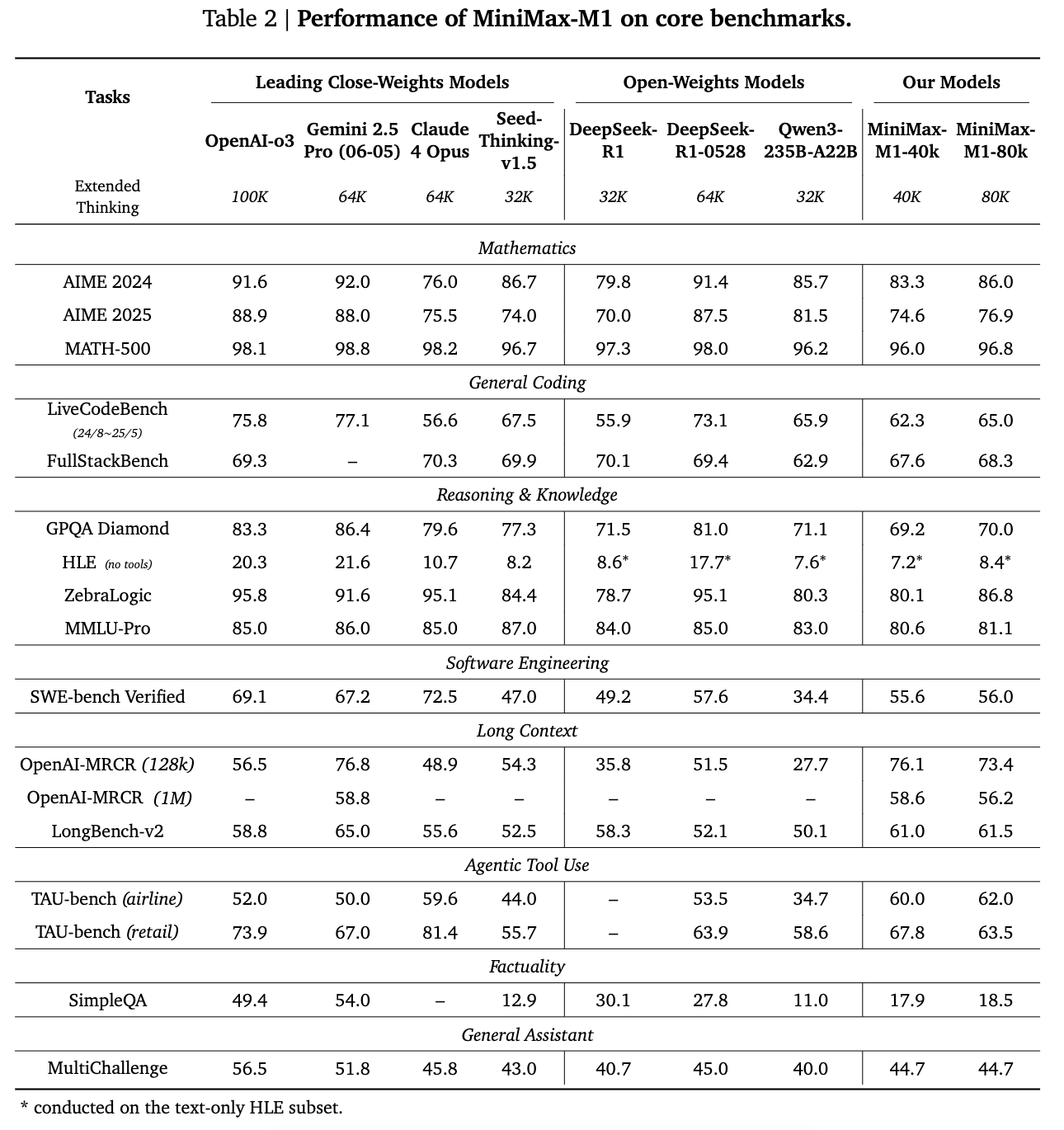
- 基准测试:在数学推理任务中,MiniMax-M1在AIME 2024和AIME 2025基准上分别取得了86.0%和88.9%的准确率,接近DeepSeek-R1的性能。在编程任务中,MiniMax-M1在LiveCodeBench和FullStackBench上分别取得了65.0%和68.3%的准确率,与Qwen3-235B相当。当在2025这个节点,和当时闭源强模型还是有不少距离。
- 复杂场景:在软件工程任务中,MiniMax-M1在SWE-bench验证任务上取得了56.0%的准确率,显著优于其他开源模型。在长期上下文理解任务中,MiniMax-M1在OpenAI-MRCR(1M)上取得了58.6%的准确率,排名全球第二。
- 工具使用:在代理工具使用任务中,MiniMax-M1在TAU-bench(retail)上取得了67.8%的准确率,超过了所有其他开源模型。
Reference
[1] CISPO 目标函数怎么从DAPO变过来的
[2] 从 PPO 到 SAPO:大模型强化学习算法的演进与对比 (PPO, GRPO, DAPO, CISPO, GSPO, SAPO)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)