多模态文档解析新思路:MinerU-Diffusion通过扩散解码进行文档OCR
继续跟进【文档智能】解析进展。在前期介绍了非常多的多模态视觉语言模型在OCR场景的方法思路,在模型架构上,基本都是vit+MLP+LLM的框架,以自回归(AR)【即文本以从左到右、逐个词元的方式生成。】的方式进行OCR解码,存在顺序延迟问题,其延迟与文档长度呈线性关系。AR的因果生成导致错误传播,即初始错误会在输出中逐级放大。

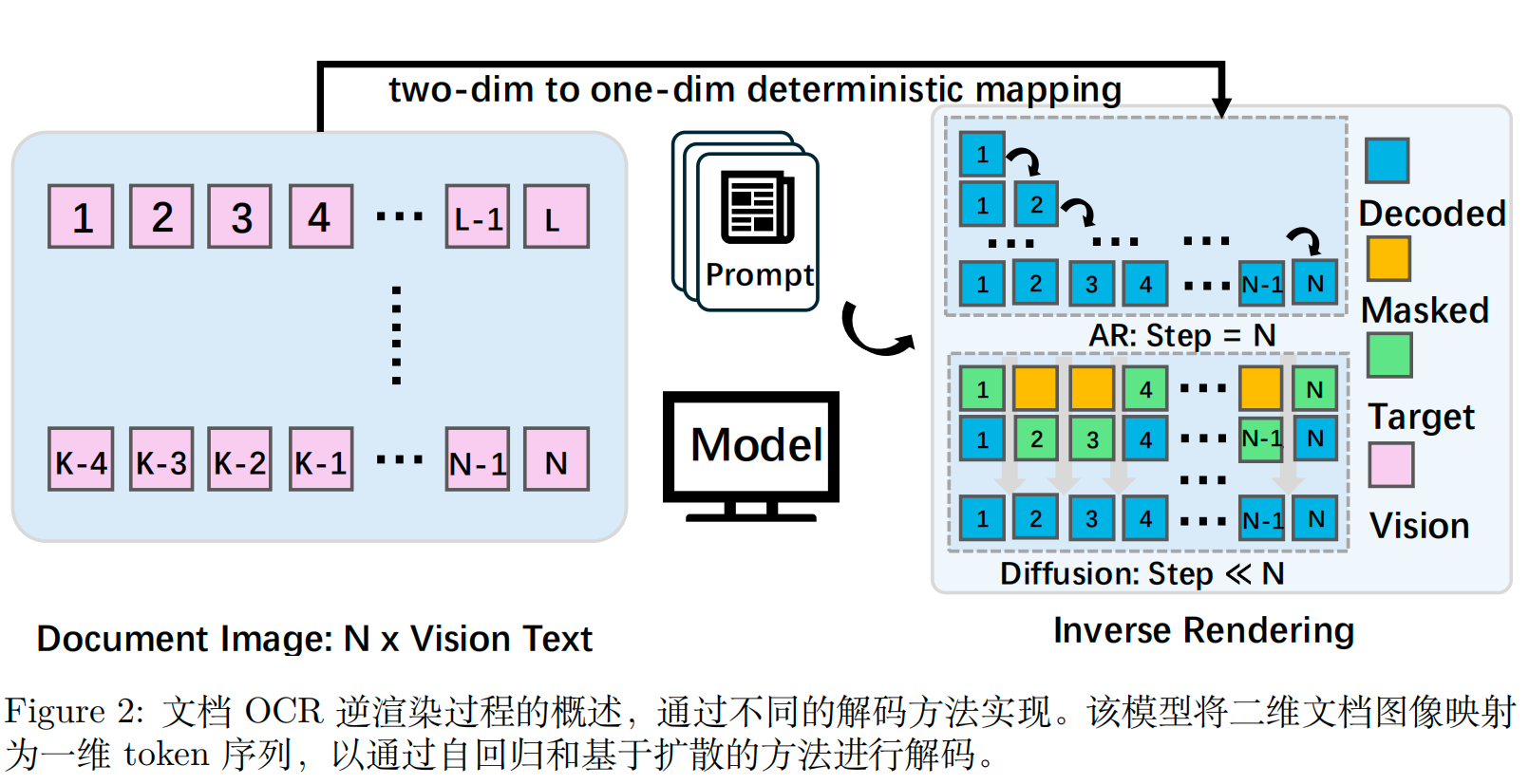
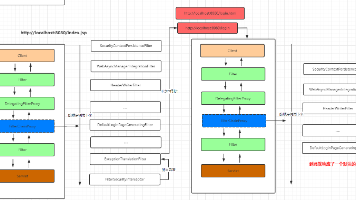
如上图,MinerU-Diffusion引入了一种不同的范式,将文档OCR重构为一个逆向渲染问题。该框架不一次预测一个序列,而是使用一个并行的基于扩散的解码器。通过将文档视为一个空间耦合的离散随机场,MinerU-Diffusion旨在直接从视觉特征重建结构化文本,从而确保高效率并以视觉输入为基础。
建模
把文档OCR建模为从2D文档图像到1D结构化token序列的逆渲染过程:
y = ( y ( 1 ) , . . . , y ( L ) ) ∈ V L y=\left( y^{(1)},... ,y^{(L)}\right) \in \mathcal {V}^{L} y=(y(1),...,y(L))∈VL
- y y y:统一结构化token,包含文本、布局标记、表格分隔符、数学符号;
- 核心逻辑:token间的依赖来自文档空间布局/格式,而非固定的生成因果顺序;
- OCR本质:基于视觉证据的后验推断 p ( y ∣ x ) p(y|x) p(y∣x),而非语言驱动的序列生成。
模型结构
这一块直接从代码看,整体架构分为三大核心组件:视觉编码器、视觉 - 语言投影器、SDAR 语言模型:
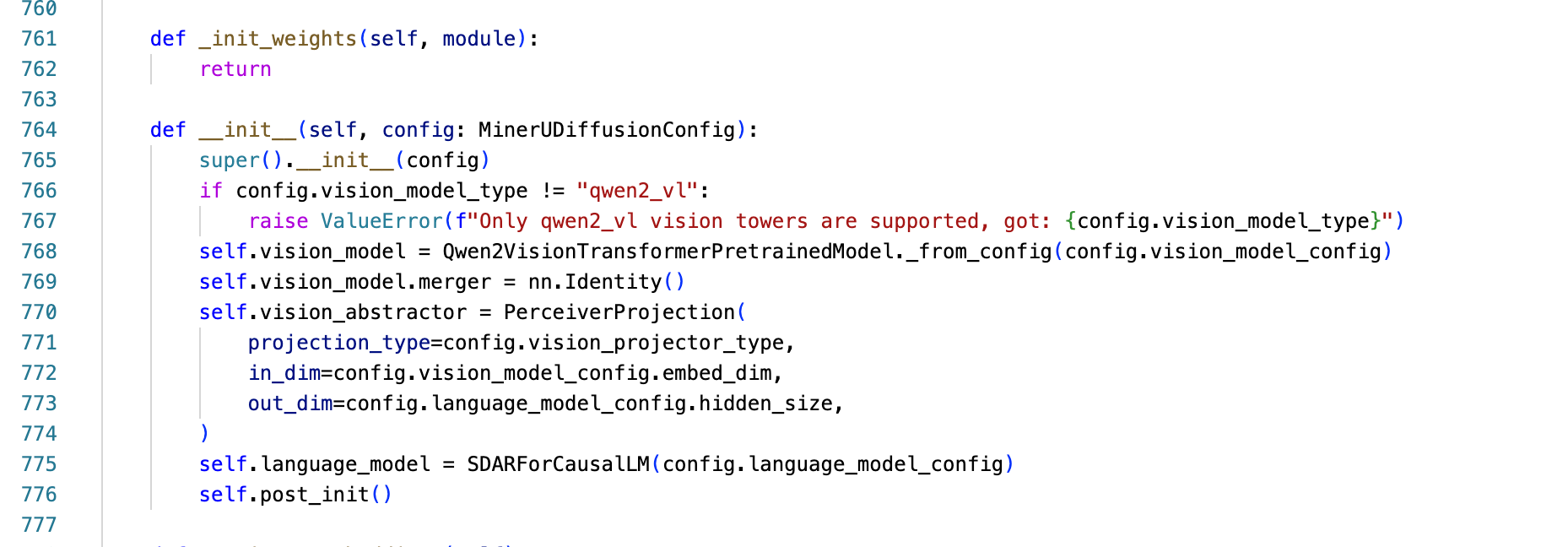
SDAR 语言模型基于扩散(Diffusion)机制生成文本,这个区别传统的多模态视觉语言模型自回归的方式,重点看一下。

SDARModel
├── Token嵌入层 (Embedding):将文本token转为向量
├── N × SDARDecoderLayer:解码器层(核心计算单元)
├── SDARRMSNorm:归一化层(稳定训练)
└── SDARRotaryEmbedding:旋转位置编码(RoPE,支持长文本)
SDARForCausalLM:基座模型 + 语言模型头(LM Head)
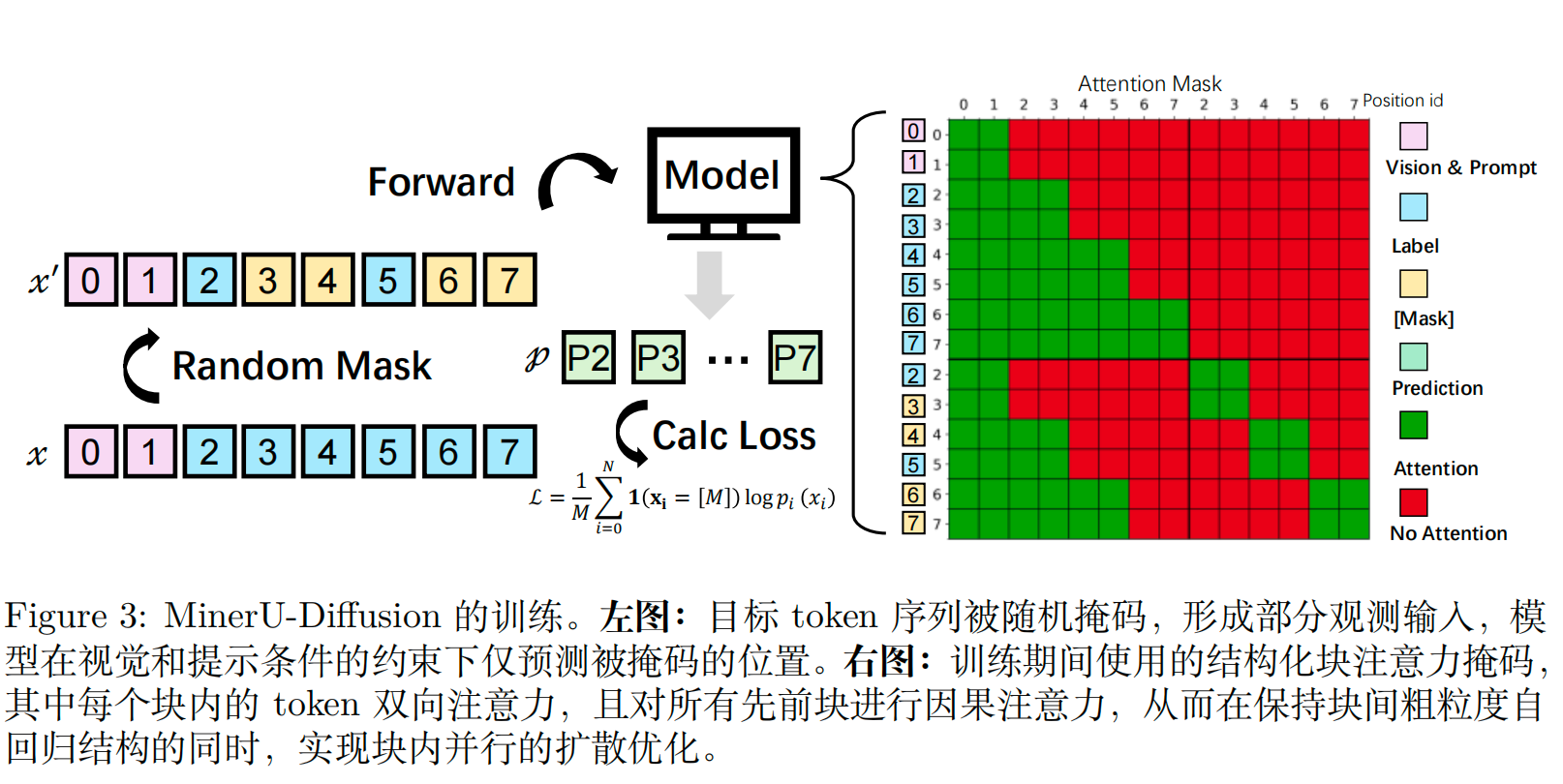
核心创新:generate_with_embeds 方法 → 块级去噪扩散生成
- 用掩码 token(MASK)占位待生成的文本
- 分块、分步去噪,逐步把掩码 token 替换为生成 token
- 比传统自回归生成速度更快、长文本效果更稳
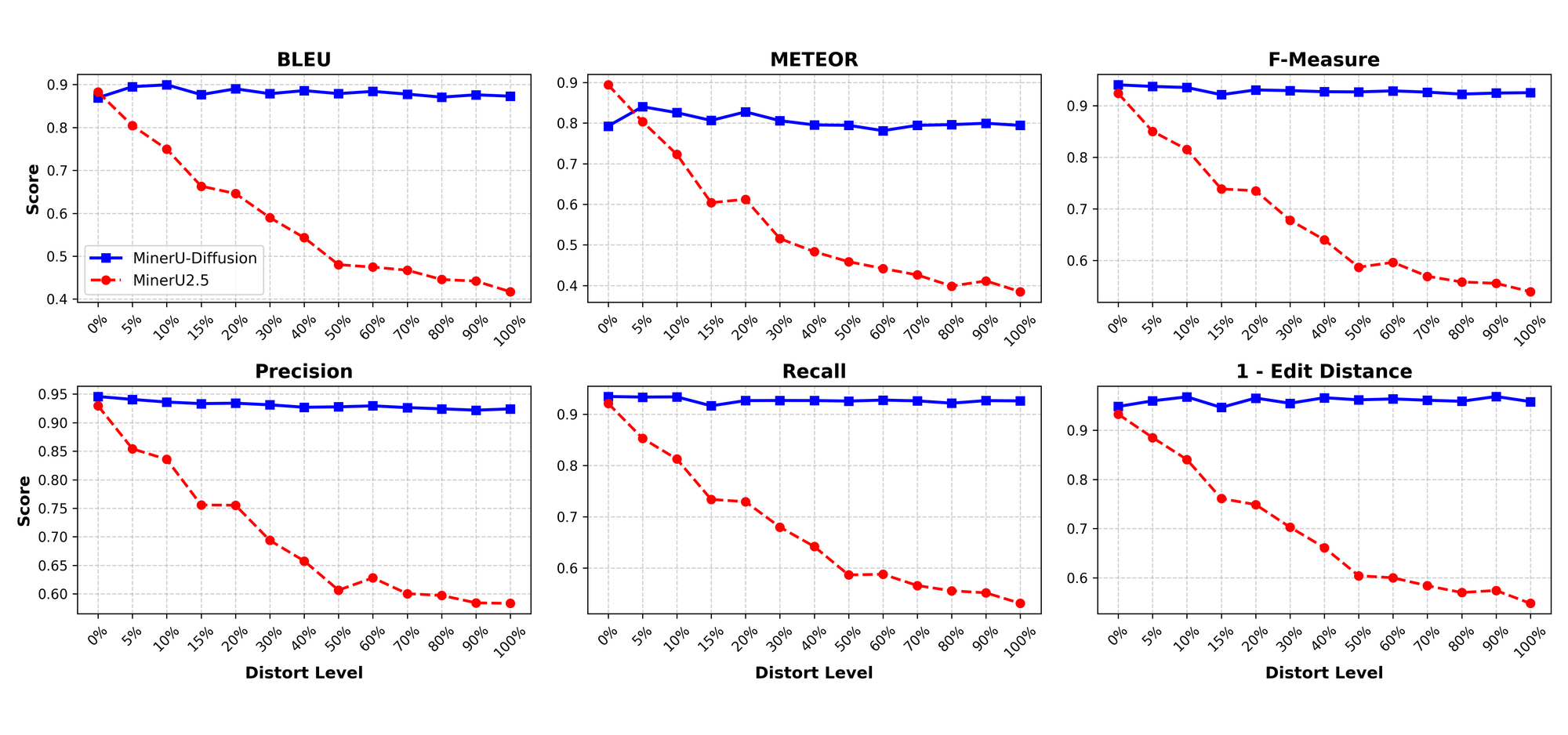
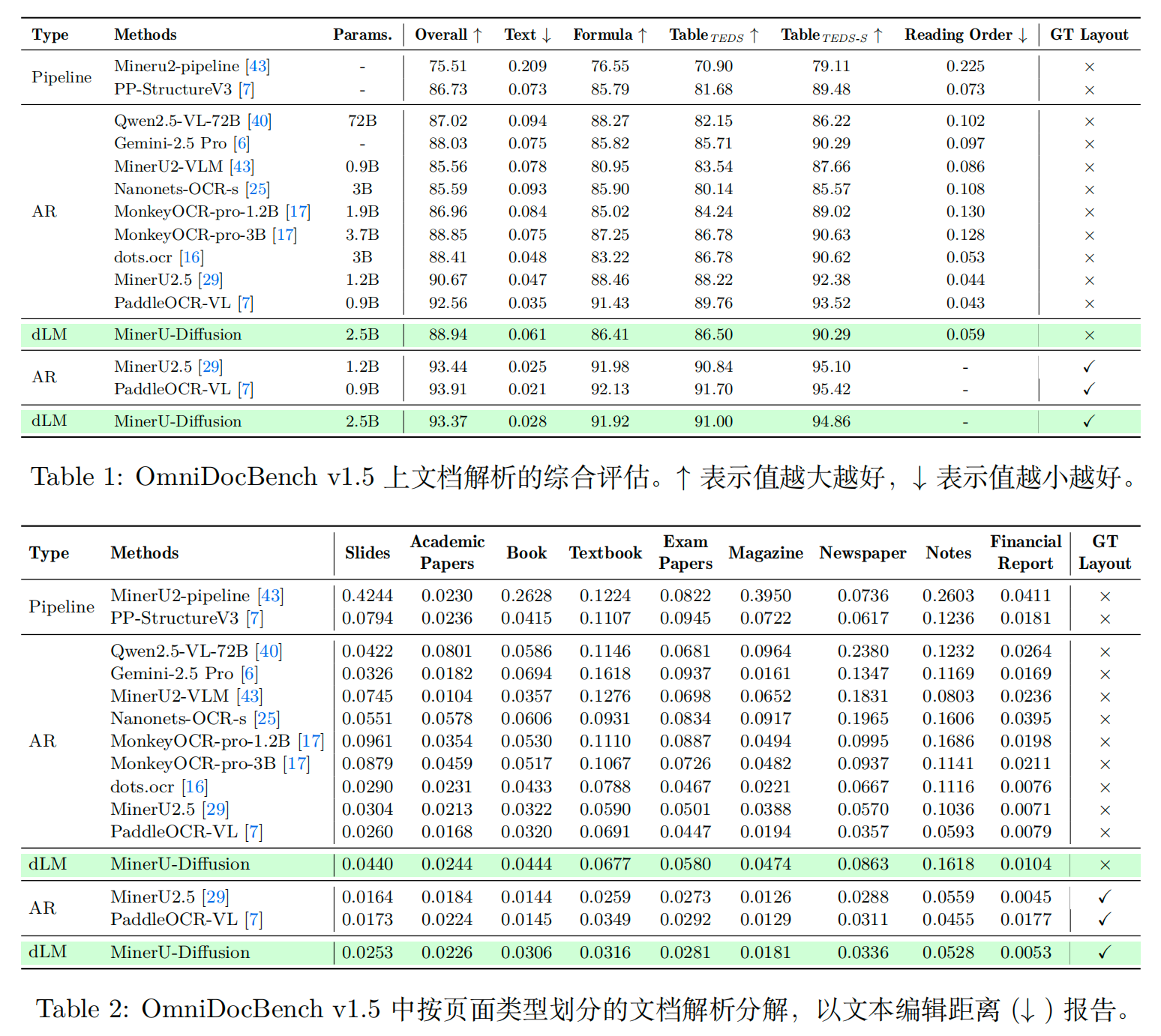
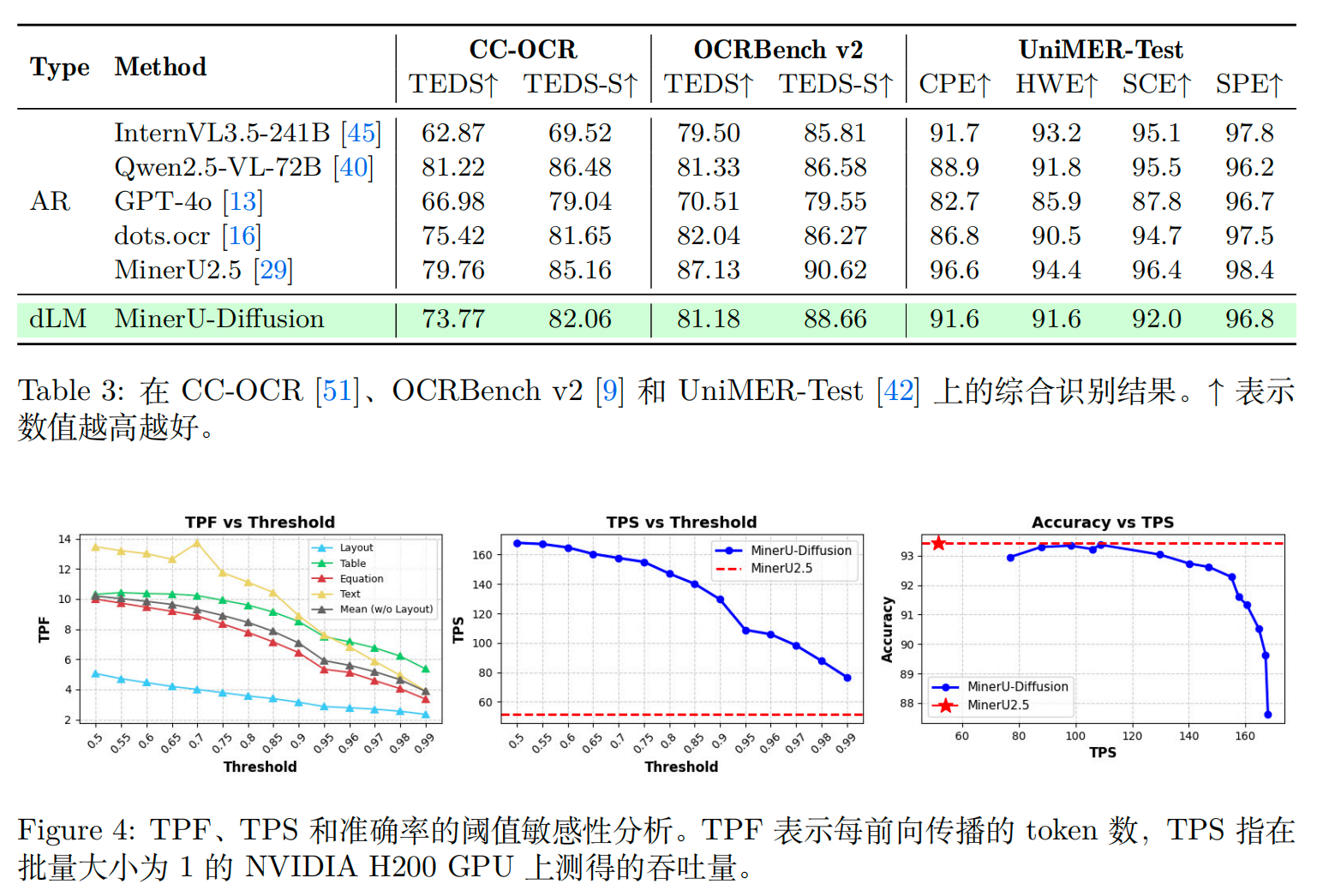
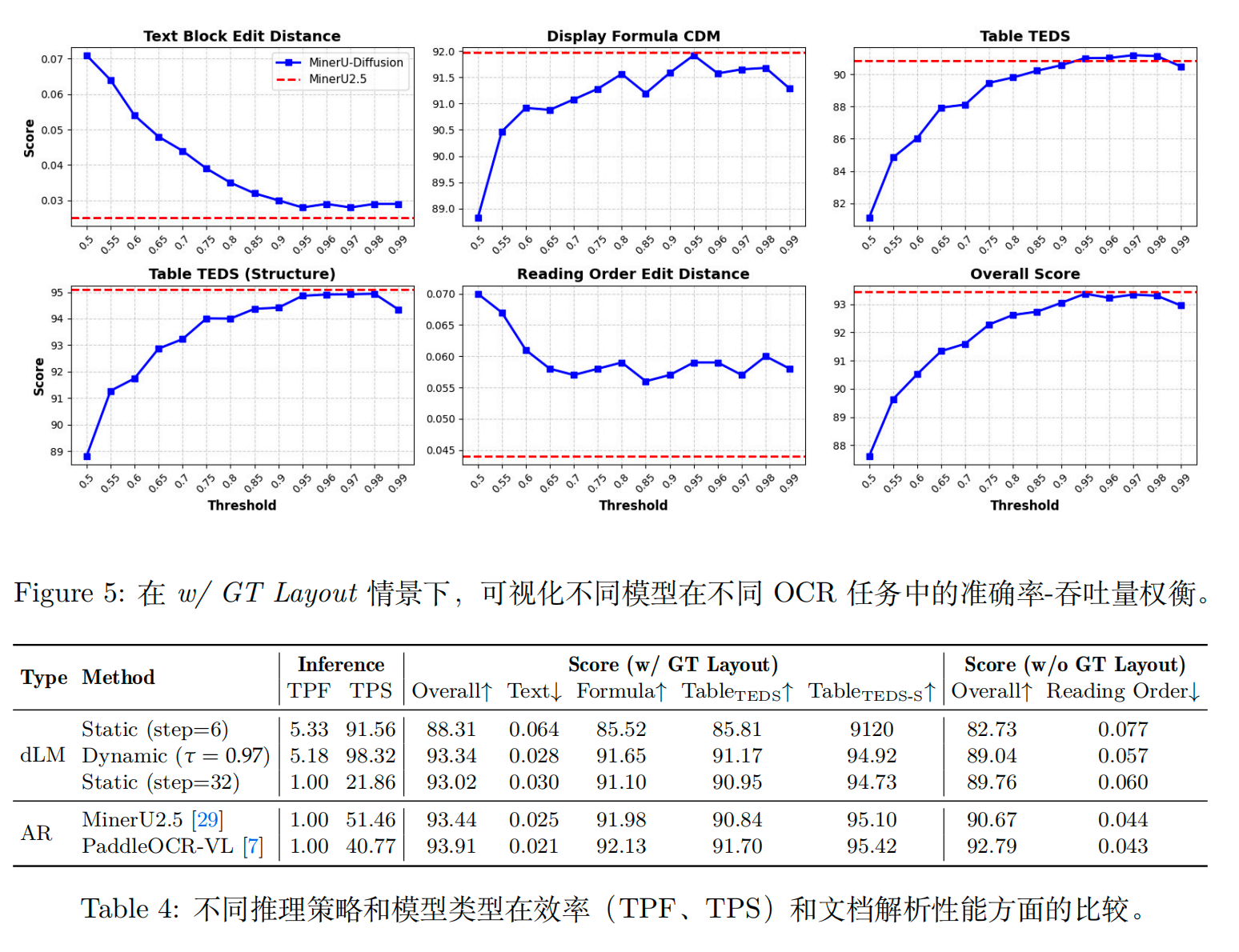
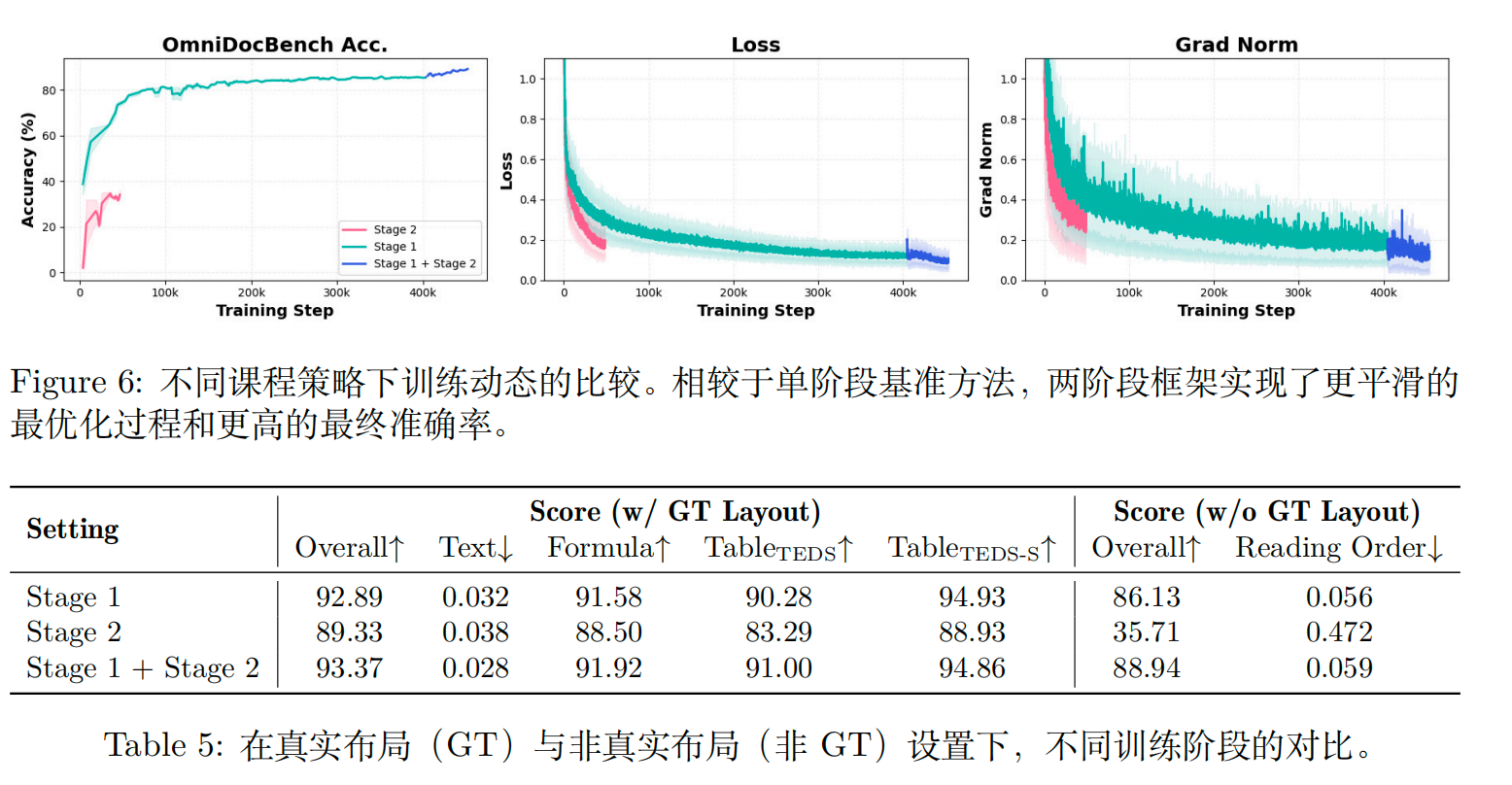
实验
参考文献
MinerU-Diffusion: Rethinking Document OCR as Inverse
Rendering via Diffusion Decoding,https://arxiv.org/pdf/2603.22458
往期相关
多模态文档解析的开源项目模型技术方案都在《文档智能专栏》,如:
…

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)