【大模型应用】一篇弄懂MCP-模型上下文协议
MCP-模型上下文协议
为什么要有?
官网:https://modelcontextprotocol.io/docs/getting-started/intro
为什么Anthropic要搞这个协议?
以前让大模型访问外部数据,主流做法有两种:
- 一是把数据灌进prompt里,受token 限制很容易爆;
- 二是用Function Calling,但每个模型厂商的实现不一样,OpenAI和Anthropic 的接口就不兼容。
这导致一个很头疼的问题:
- 开发者想做一个能访问本地文件的AI助手,得为每个模型分别适配,代码复用率极低。
- MCP的出发点就是解决这个碎片化问题,把模型和外部世界的交互标准化。
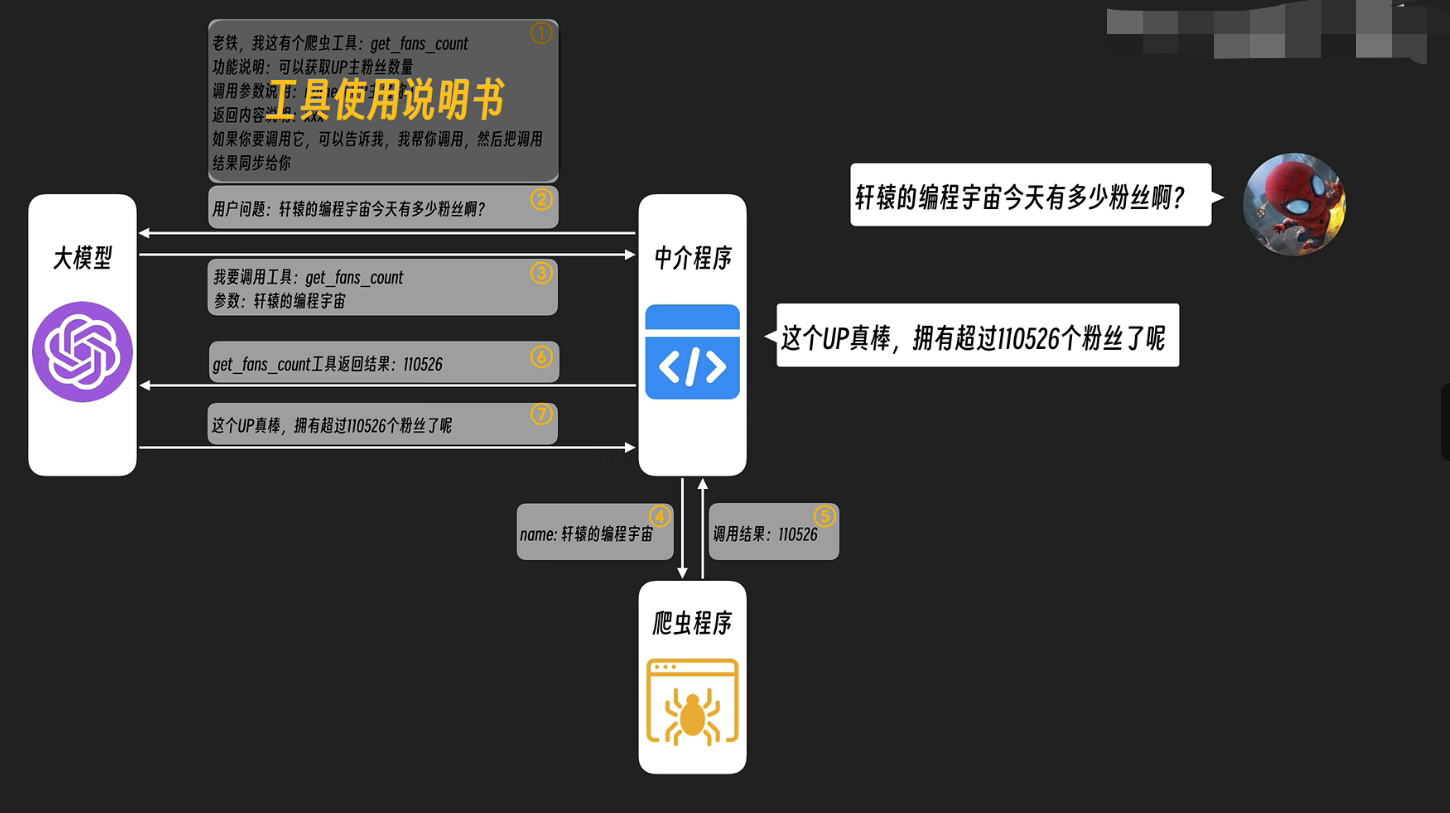
MCP 全称 Model Context Protocol,模型上下文协议,是Anthropic 在2024年11月发布的开放标准,核心目标是让大模型能够标准化地连接外部数据源和工具。
在MCP出现之前,想让大模型访问数据库、调用API、读取本地文件,每个场景都要单独写一套对接代码,维护成本高得吓人。
MCP的思路很简单:定义一套通用协议,所有外部资源只要实现这个协议,大模型就能直接调用,不用关心底层是MySQL还是MongoDB,是本地文件还是云存储。
用USB接口来类比最直观。以前各种设备的充电线、数据线五花八门**,现在有了USB-C,一根线搞定所有设备**。MCP 就是AI 领域的USB-C,让模型和外部世界的连接变得即插即用。
作用
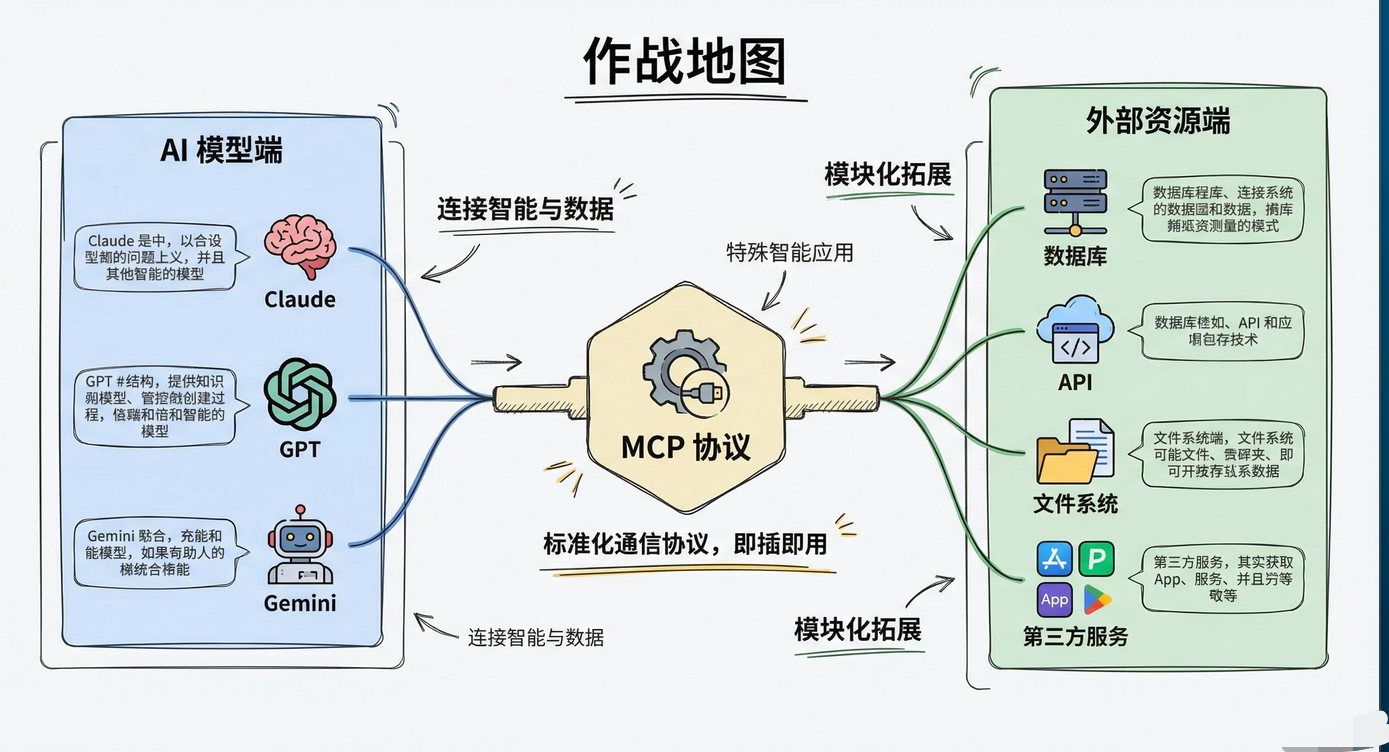
MCP的作用主要体现在三个层面:
1)**标准化数据接入:**一次实现MCP Server,所有支持MCP的模型都能用,不用为GPT、Claude、Gemini各写一套适配代码
**2)增强模型实时能力:**模型可以动态获取最新数据,比如实时查GitHub仓库状态、读取本地日志文件、调用内部API拿业务数据,不再被训练数据的时间截止线卡住
**3)降低集成复杂度:**系统架构变得模块化,加一个新数据源只要部署一个MCPServer,不用动模型侧的代码
5个核心组件
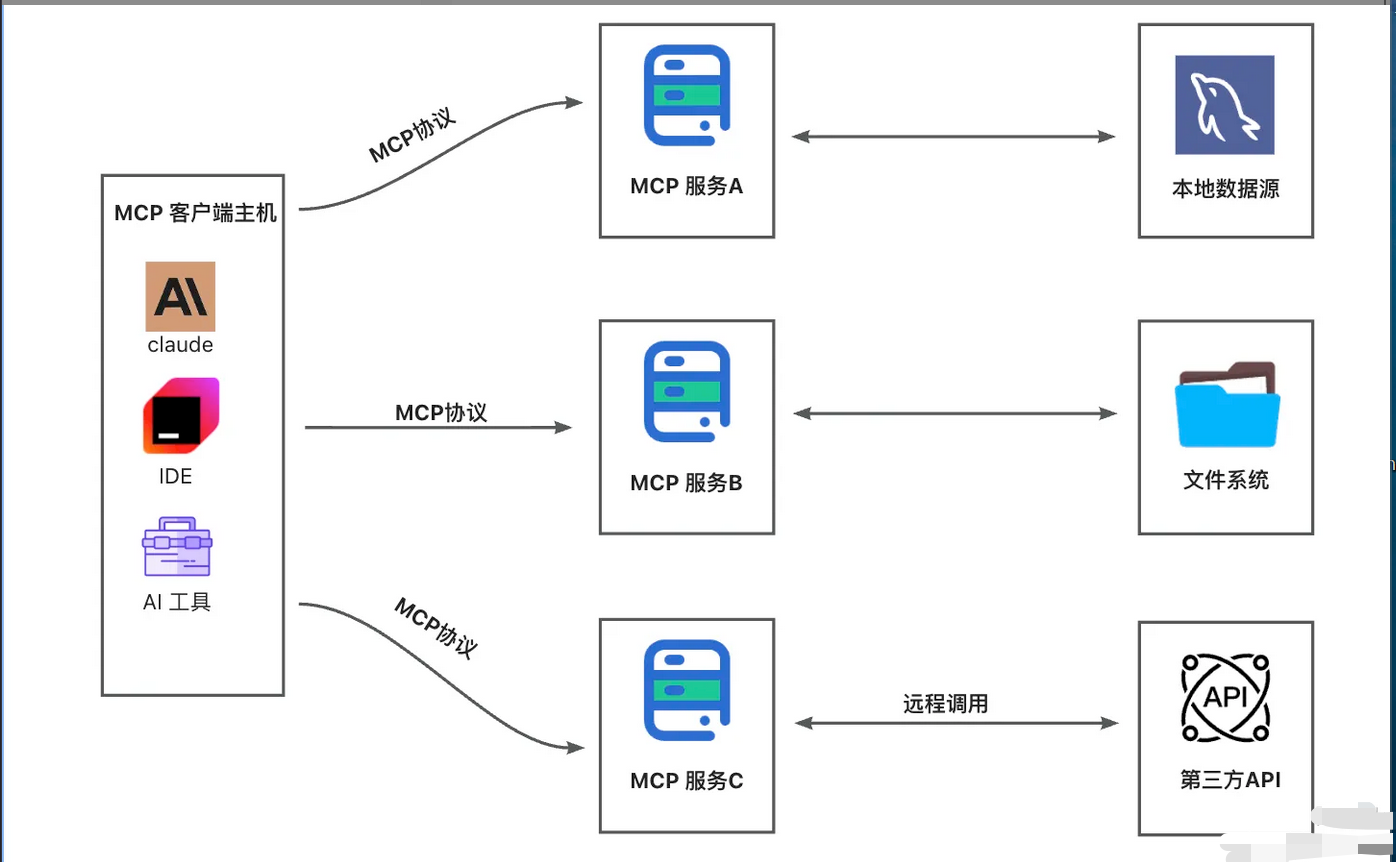
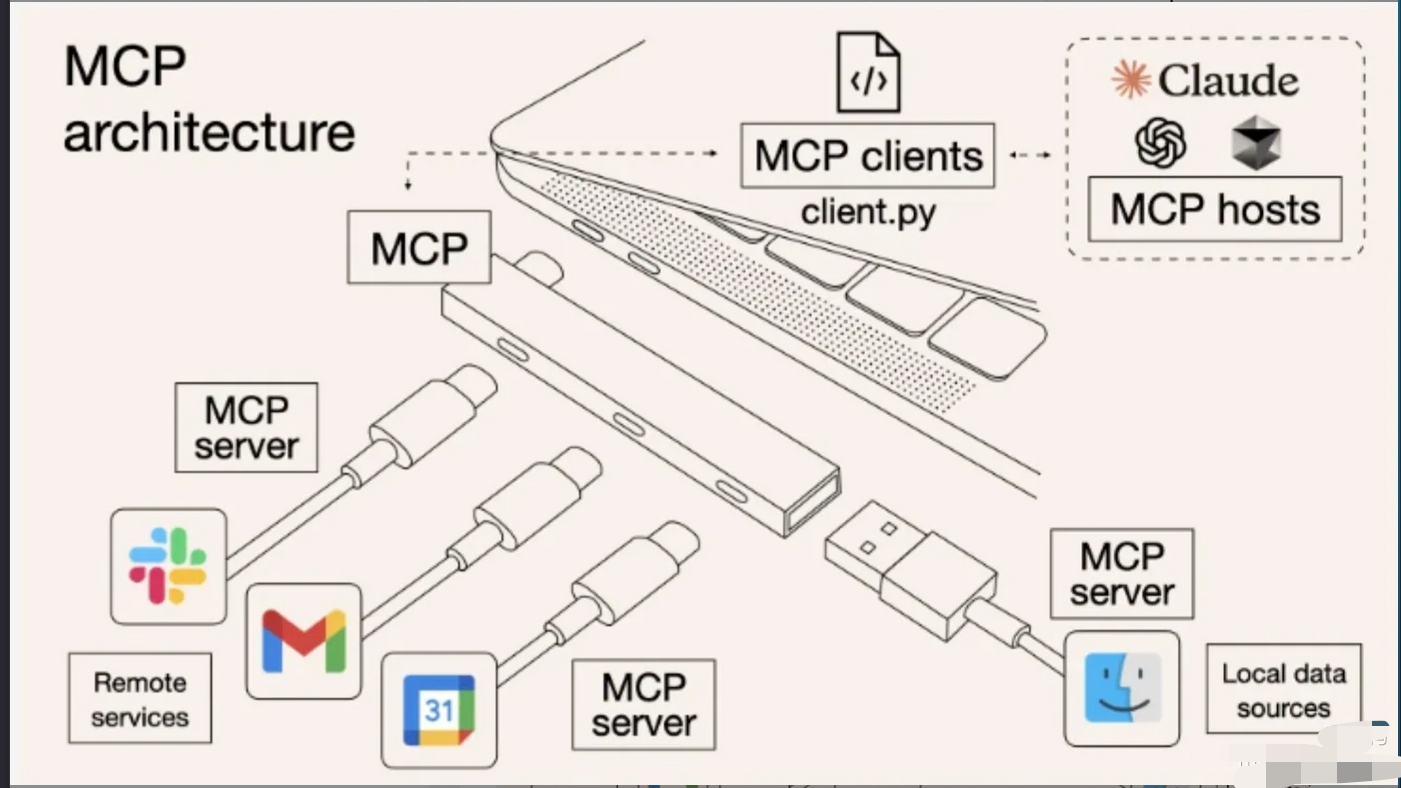
MCP的核心是客户端-服务器架构(C/S),一个主机可以同时连接多个服务器。
整体由5个核心组件构成:

- 1)**MCP主机:**想通过MCP访问外部数据的程序,比如Claude Desktop、Cursor、各种 AI工具都属于这一类。
- 2)**MCP客户端:**与服务器保持1:1连接的协议客户端,负责和服务器通信。
- 3)MCP服务器:轻量级程序,通过标准化的MCP协议向客户端暴露特定功能,包括数据源、工具、API接口等。
- 4)**本地数据源:**MCP服务器可以安全访问的本机资源,比如文件系统、本地数据库、系统服务。
- 5)**远程服务:**MCP服务器通过互联网连接的外部系统,比如第三方API、云服务。
Server的三种基础操作
MCPServer(MCP服务器)是整个架构的核心,负责向大模型提供结构化上下文和可调用的操作能
力。它定义了三大类基础功能:
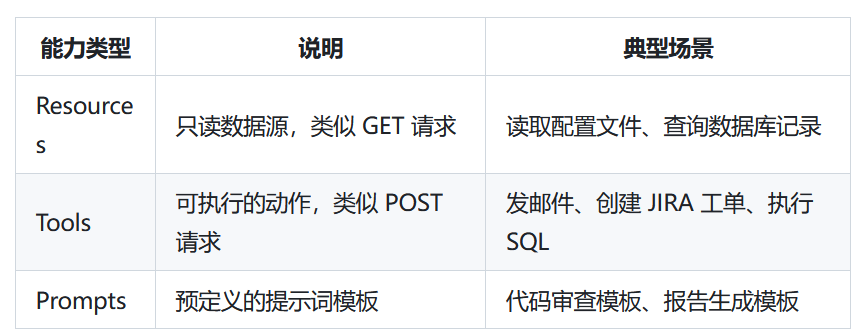
- 1)Resources:类似静态或动态的数据文档,比如API返回的JSON、配置文件、项目结构,供模型查询参考。
- 2)Tools:模型可调用的函数接口,比如发请求、创建文档、执行命令,执行前通常需要用户授权来保证安全。
- 3)Prompts:预定义的提示模板,用来引导模型完成特定任务,比如代码审查、生成commit message、总结会议内容,能提高交互效率。
通过这三类能力,MCPServer让模型不仅能"看懂"信息,还能"动手"完成任务。模型在运行的时候会拿到所有可用的Resources、Tools、Prompts列表,然后根据用户意图决定调用哪个
社区维护的 MCP Servers Repository 和 Awesome MCP Servers 里有大量开的MCP Server 实现。
TypeScript写的MCP Server 通常用 npx命令运行。
Python写的用uvx 命令启动,部署起来很方便。
MCP Server 的Tools 和 Resources 有什么本质区别?
回答:
- Resources是只读的数据,模型拿来参考用,不会产生副作用;
- Tools是可行的动作,会真正改变外部状态。
- 打个比方,Resources像是给模型看的文档,Tools像是给模型用的遥控器。Resources模型可以随时读,Tools执行前通常要尸户确认授权,因为可能会发邮件、删文件这种不可逆操作。
两种通信模式
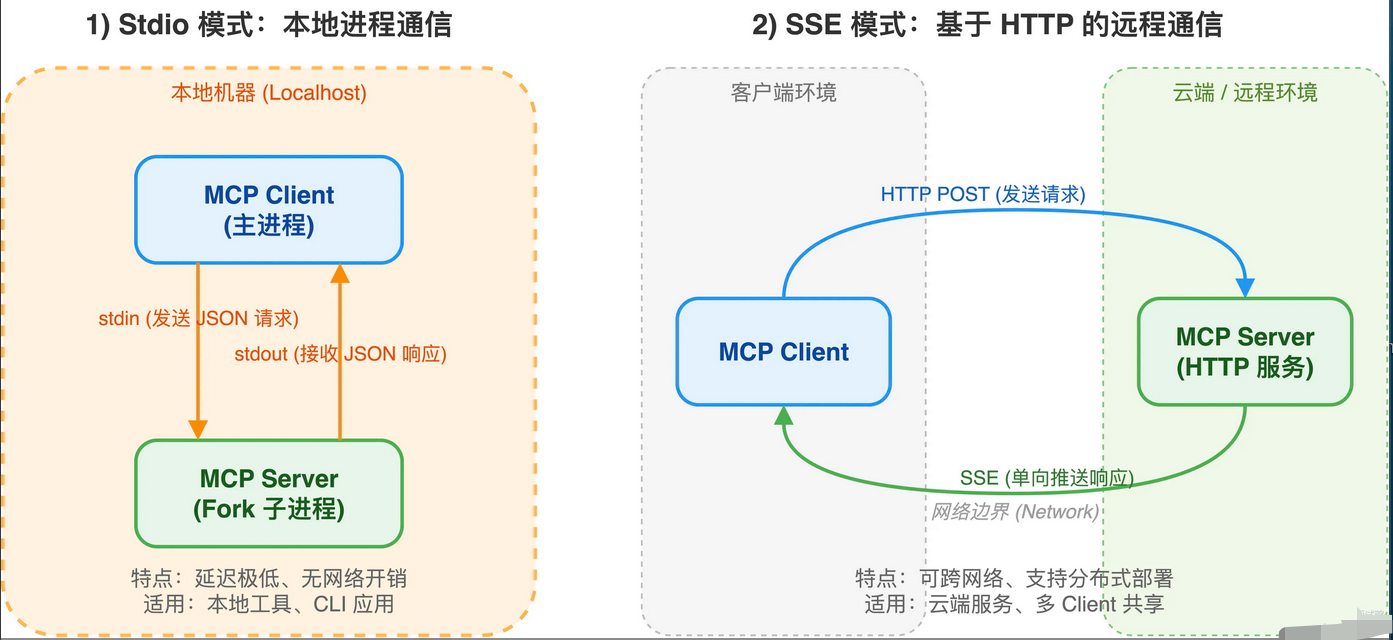
MCP协议支持两种通信模式:Stdio和 SSE。
**1)Stdio模式:**通过标准输入输出流和MCP服务器通信。Client直接fork一个Server 进程,用stdin/stdout 交换JSON消息,不走网络,延迟低、实现简单。适合本地部署的MCP服务器,Client和Server 跑在同一台机器上,直接进程间通信就搞定。
**2) SSE 模式:**基于 HTTP + Server-Sent Events 实现。 **Client 用HTTP POST 发请求,Server用SSE单向推送响应。**适合远程部署的场景,比如Server跑在云端、分布式系统、或者需要网络实时推送的情况。一个SSE模式的MCP Server 可以同时被多个Client远程调用。
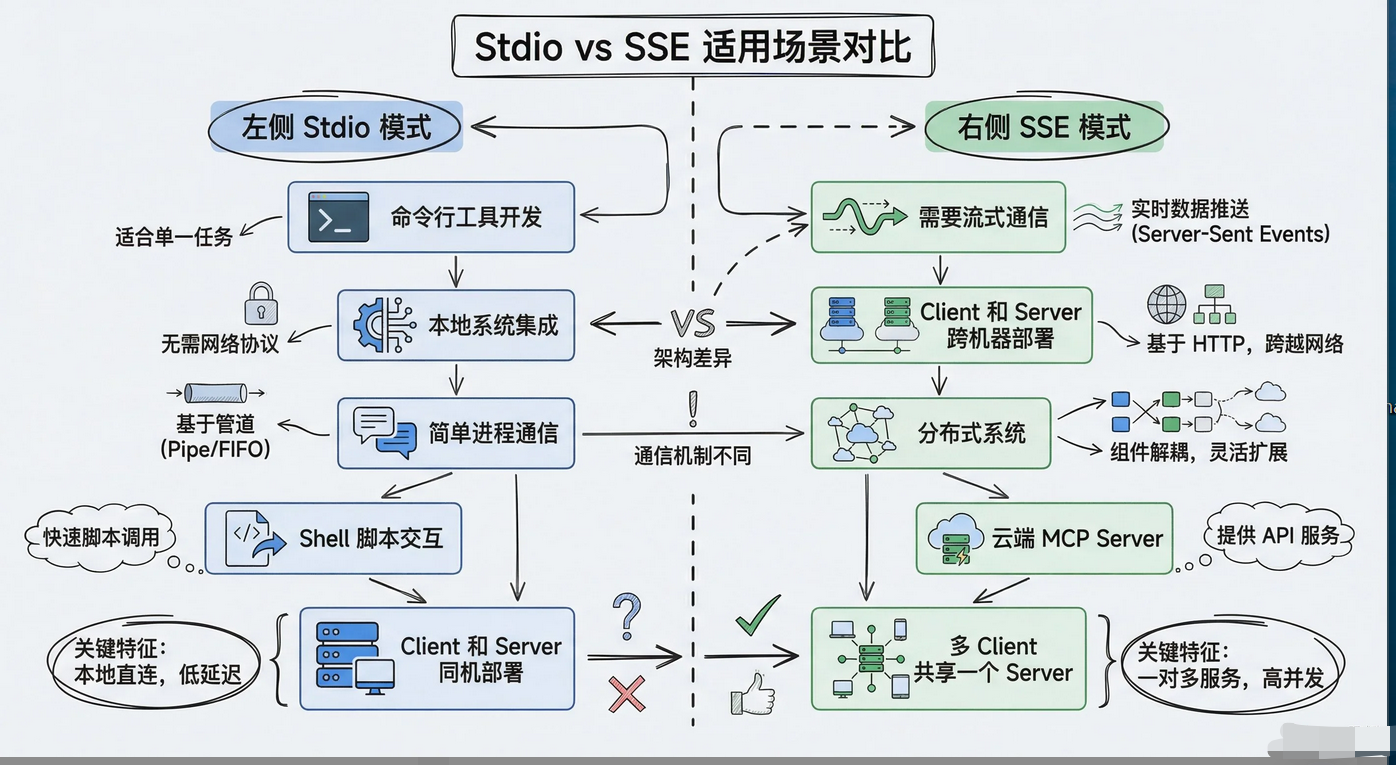
提问:MCPClient 和 MCP Server 之间是怎么通信的?用的什么协议?
回答:MCP底层用的是JSON-RPC2.0协议,传输层支持两种方式:
- 一种是stdio,适合本地进程间通信;
- 另一种是HTTP+SSE,适合远程服务调用。
- stdio方式下Client直接fork一个Server 进程,通过标准输入输出交换JSON消息,延迟低、实现简单。HTTP+SSE方式下Client用HTTP POST发请求,Server 用Server-SentEvents 推送响应,适合跨网络场景。
工作流程
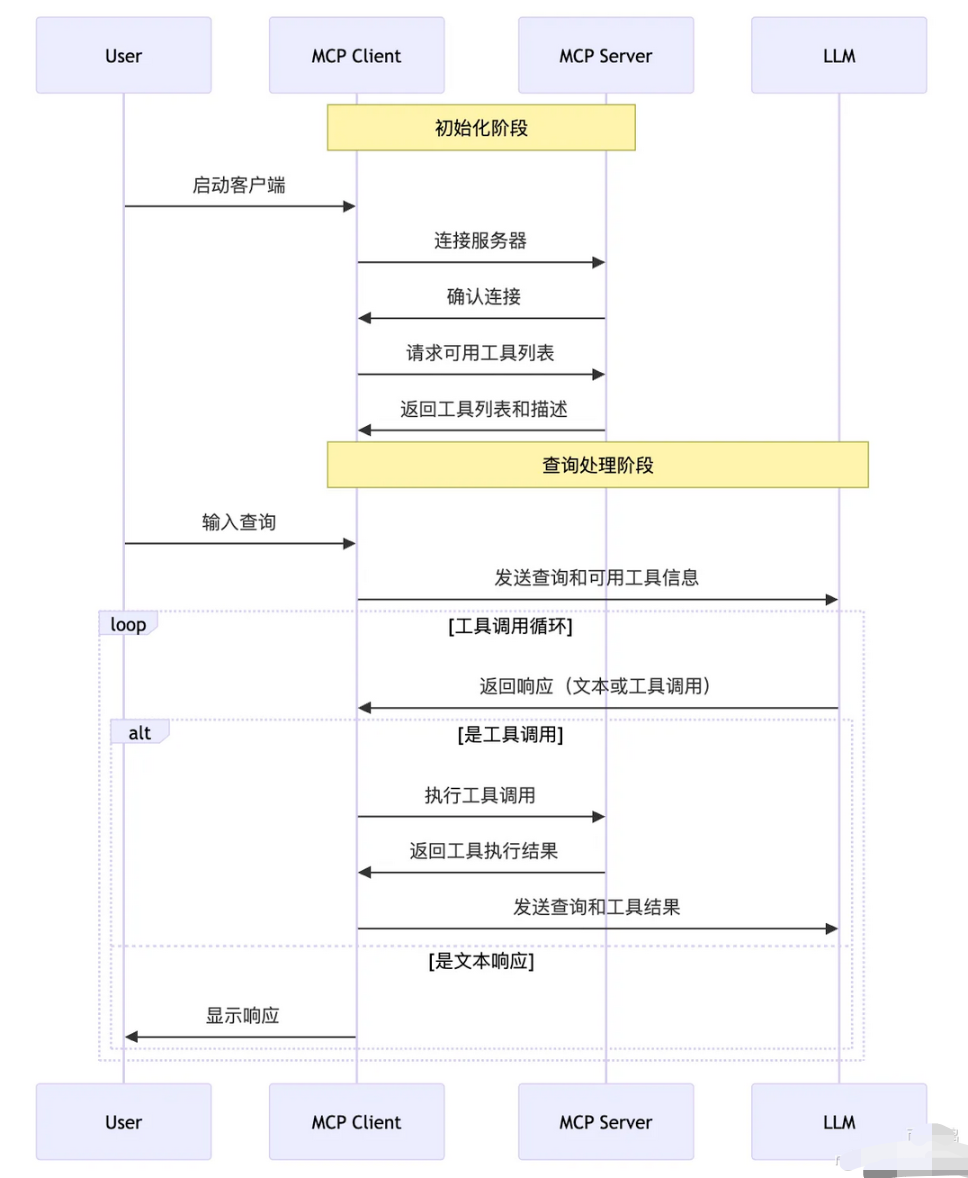
MCP的核心工作流程是一个客户端-服务器协作的闭环,整体分为7个阶段:
1)**初始化连接:**主机应用启动后,MCP Client与MCP Server建立连接。一个主机可以同时连多个Server,每个Server负责不同的工具和资源。
2)获取工具列表:Client 从Server拉取可用的工具清单,包括每个工具的名称、参数、用途描述。这一步相当于"能力注册",让模型知道手里有哪些牌可以打。
3)**构造 Function Calling请求:**用户输入问题后,Client把工具描述和用户问题一起打包发给LLM。传输格式是结构化的Function Calling,告诉模型"你现在能调用这些函数"。
**4)模型智能决策:**LLM根据上下文和工具信息,判断是否需要调用外部工具、调用哪个、传什么参数。比如用户问天气,模型就会选择 getWeather工具并填入城市参数。
5)工具调用执行:如果模型决定调用工具,Client 把调用请求转发给Server,Server负责实际执行跑脚本、查数据库、调API,然后把结果返回。
**6)结果整合:**工具执行结果传回LLM,模型把这个结果和原始问题、对话上下文糅在一起,生成最终的自然语言回答。
**7)用户响应输出:**Client把模型生成的回答展示给用户,完成一次完整的人机协作。
提问:一个MCP Client 能同时连多个MCP Server 吗?这种多连接场景下怎么管理?
回答:可以,MCP设计上就支持一个Client同时连多个Server。每个Server 提供不同能力,Client会维护一个Server 列表,每次请求前先聚合所有Server 的工具列表给模型。模型选择调用哪个工具时,Client根据工具归属把请求路由到对应的Server。Cursor 里配置多个MCP Server 就是这个原理。
SpringAI集成MCP
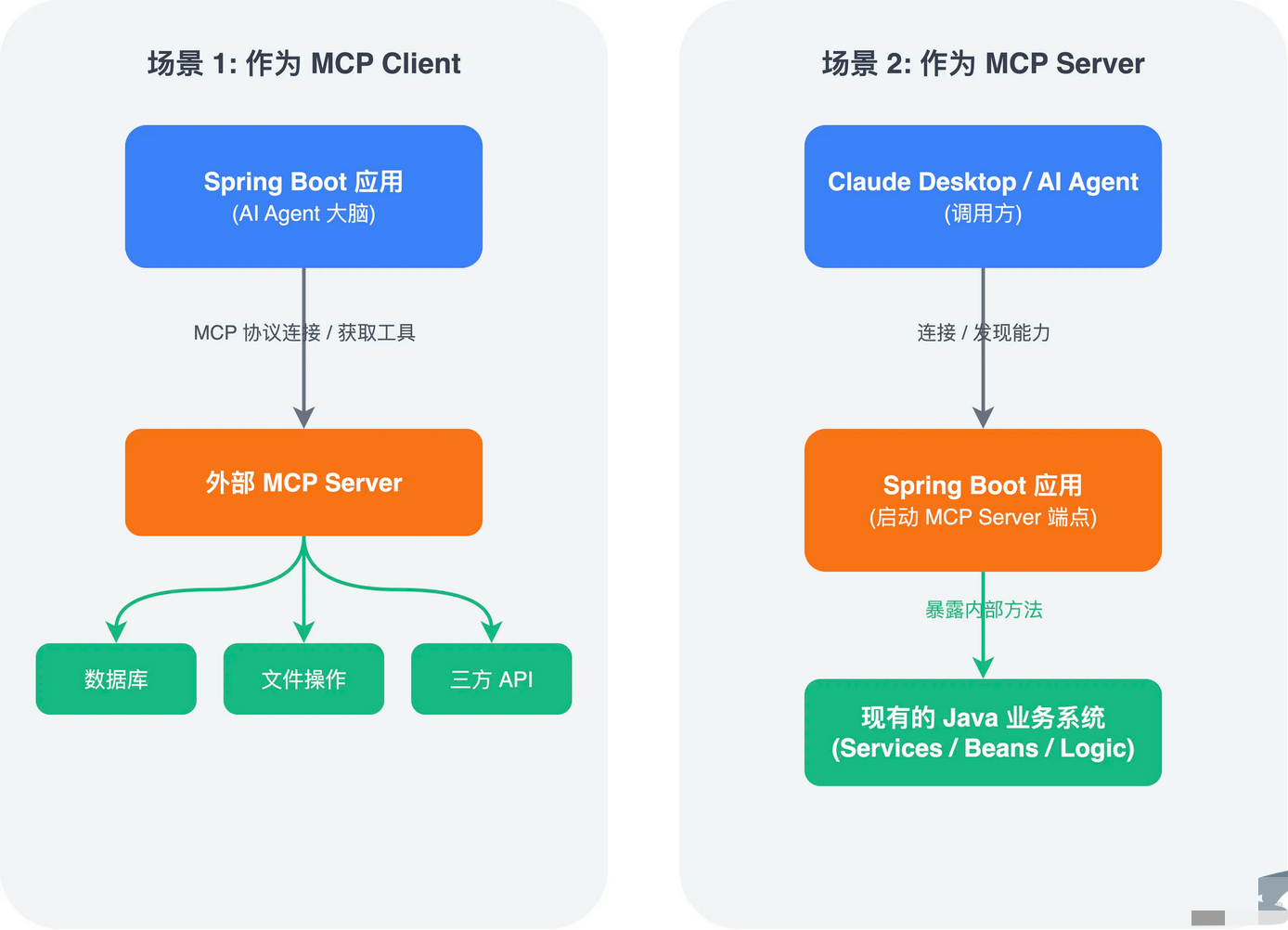
Spring AI集成 MCP有两种角色,方向完全不同:
- 1)作为MCP Client:你的Spring Boot应用是AI Agent 的大脑,通过MCP协议连接外部的MCP Server 来获取工具能力。比如让AI助手能查数据库、操作文件、调用第三方API。
- 2)作为MCP Server:你有现成的Java业务系统,想把里面的能力暴露给ClaudeDesktop或其他AI Agent 调用。Spring Boot应用**启动一个MCP Server 端点,**等着别人来连。
将已有程序转为MCP服务
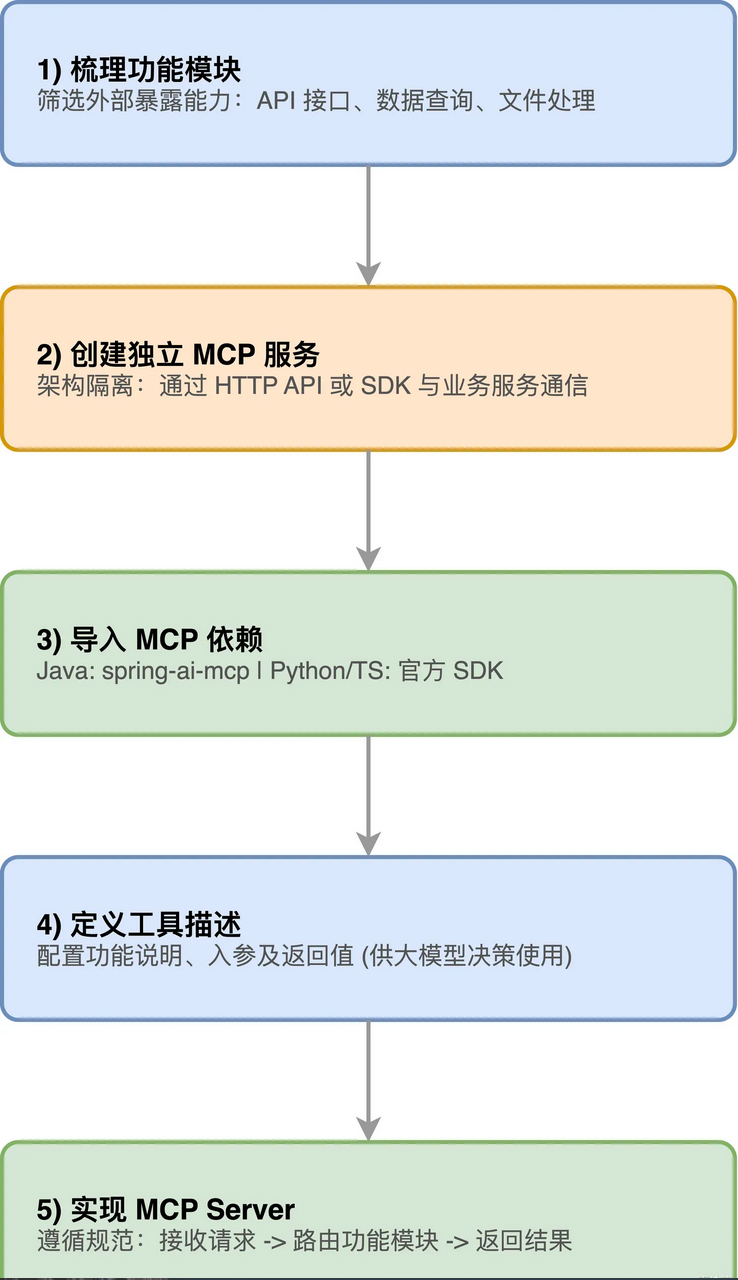
把现有应用转成MCP服务,核心就是把应用里的功能封装成标准化的MCP工具,再通过 MCP Server暴露出去让大模型能调用。
整个转换流程分这几步:
1)梳理功能模块,把应用里需要暴露给外部的能力挑出来,比如API接口、数据查询、文件处理这些
2)创建独立的MCP服务,跟原有业务服务隔离开,通过HTTP API或者SDK跟业务服务通信
3)导入 MCP依赖,Java 用 spring-ai-mcp,**Python、TypeScript 等语言参考官方SDK
4)定义工具描述,包括功能说明、入参字段及描述、返回值字段及描述,这些信息会被大模型用来理解什么时候该调用这个工具
5)实现MCP Server,按照MCP协议规范构建服务端,负责接收MCP客户端请求、路由到对应功能模块、返回结果
安全机制
MCP在设计上考虑了安全边界:
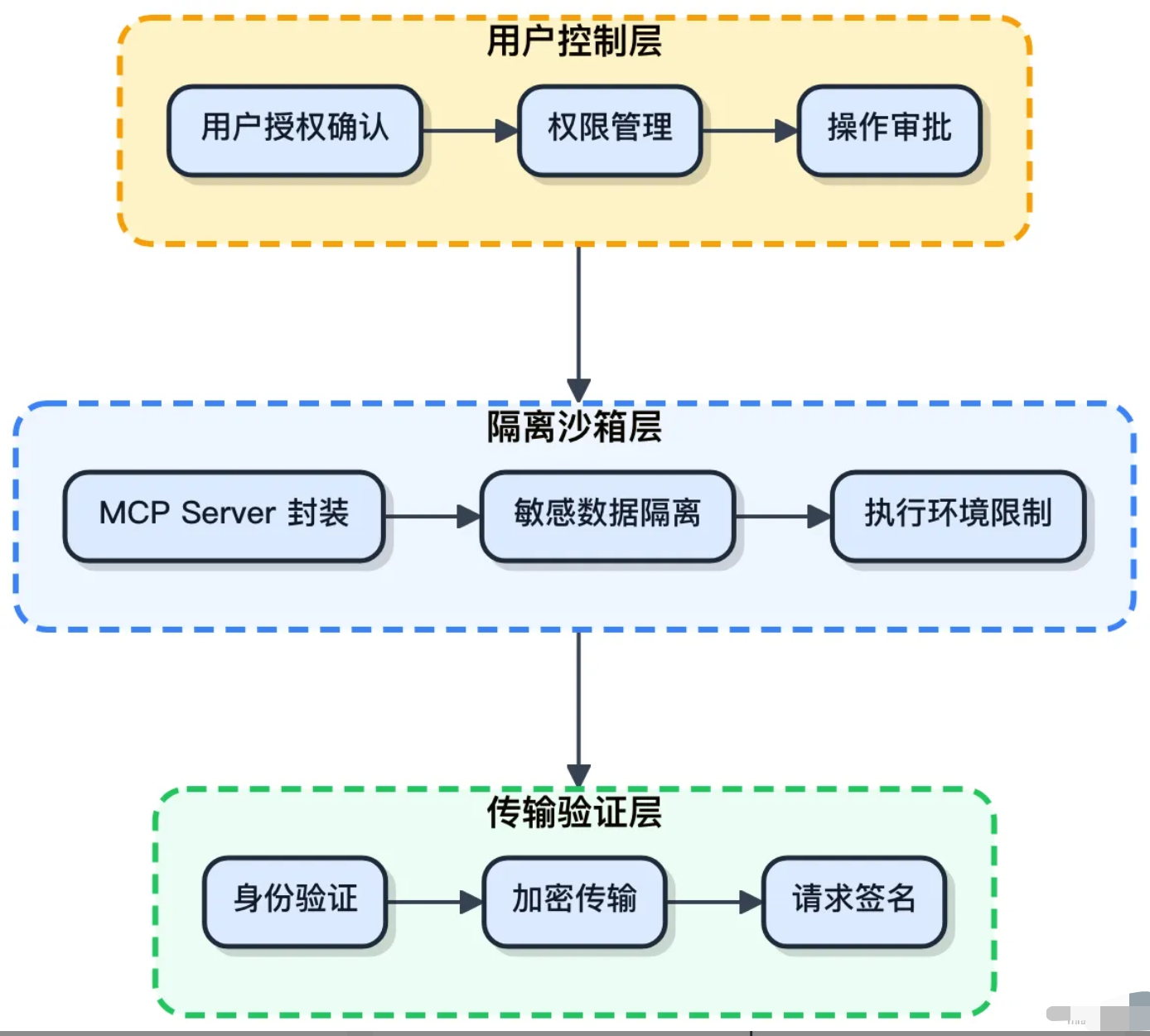
MCP协议的安全性设计围绕三层防护展开:用户控制层、隔离沙箱层、传输验证层。
1)用户同意和控制
**所有工具、资源、提示的访问都必须经过用户授权。**Host应用负责权限管理,在调用敏感操作前弹窗让用户确认。用户得清楚知道哪些数据会交给模型、每个工具能干什么,授权前心里有数。
2)隔离与沙箱机制
工具调用被封装在MCP Server 内部,模型压根碰不到原始敏感数据。Server 充当中间层,即使模型被prompt注入攻击,攻击者也拿不到数据库密码、APIKey这些凭证。沙箱机制还能限制工具的执行环境,防止恶意代码跑飞。
每个Server 只能访问自己管辖的资源,一个连数据库的Server没法读本地文件
3)加密传输与来源验证
MCP内置请求验证机制,只有通过身份校验的请求才能访问资源。SSE模式走HTTPS,数据全程加密;Stdio模式虽然是本地通信,但进程间也有隔离保护。防止中间人攻击
现有生态
目前支持 MCP 的Host 端有Claude Desktop、Cursor、Windsurf 等。Server 端社区已经有不少现成实现:
1)数据库类:PostgreSQL、SQLite、MongoDB
2)开发工具类:GitHub、GitLab、Linear
\3) 生产力类:Slack、 Notion、Google Drive
4)浏览器类:Puppeteer、Playwright
Anthropic 官方维护了一批 Reference Server,开发者可以直接拿来用或者参考写自己的。
MCP和Function Calling的区别?
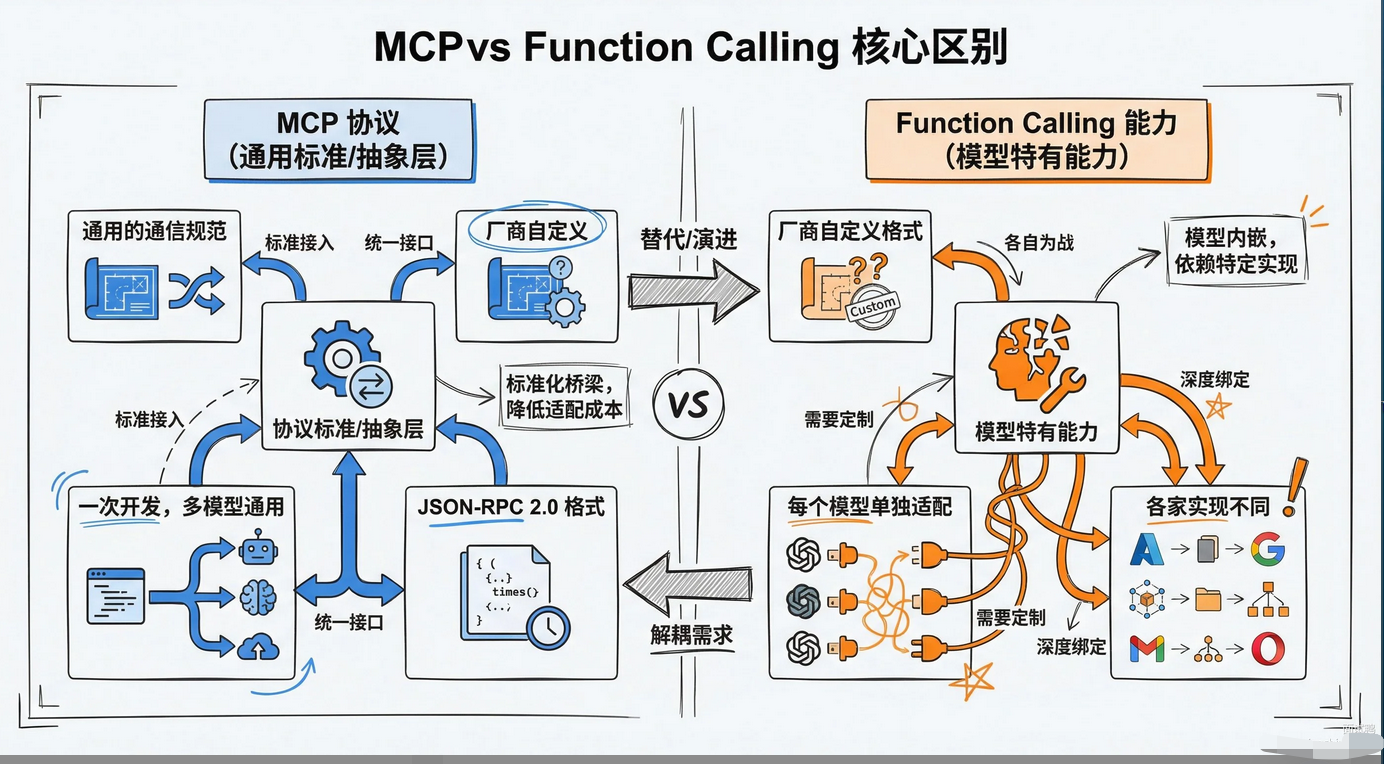
回答:最大的区别是抽象层级不一样。
- Function Calling是模型层面的能力,每个模型厂商自己定义接口格式,开发者要针对不同模型写不同的适配代码。
- MCP是应用层协议,和模型实现解耦,只要模型支持调用外部工具的能力,不管是Function Calling 还是 Tool Use,都能接入MCP。
- 打个比方**,Function Calling像是各厂商自己的私有充电口,MCP像是行业通用的USB-C标准**。
- 再用支付系统来比喻:Function Calling像是直接对接微信、支付宝、银联,每个系统都要单独开发;MCP像是对接一个支付网关,只需要开发一次,网关帮你搞定和各家的对接

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 22
22 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)