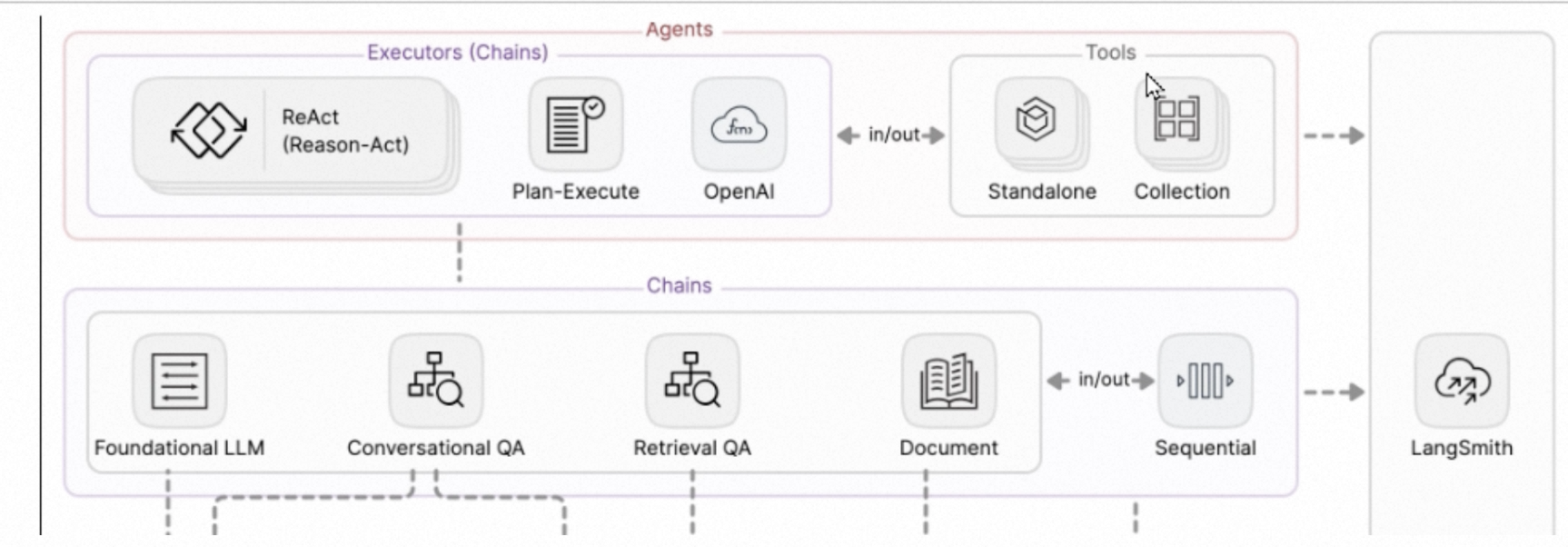
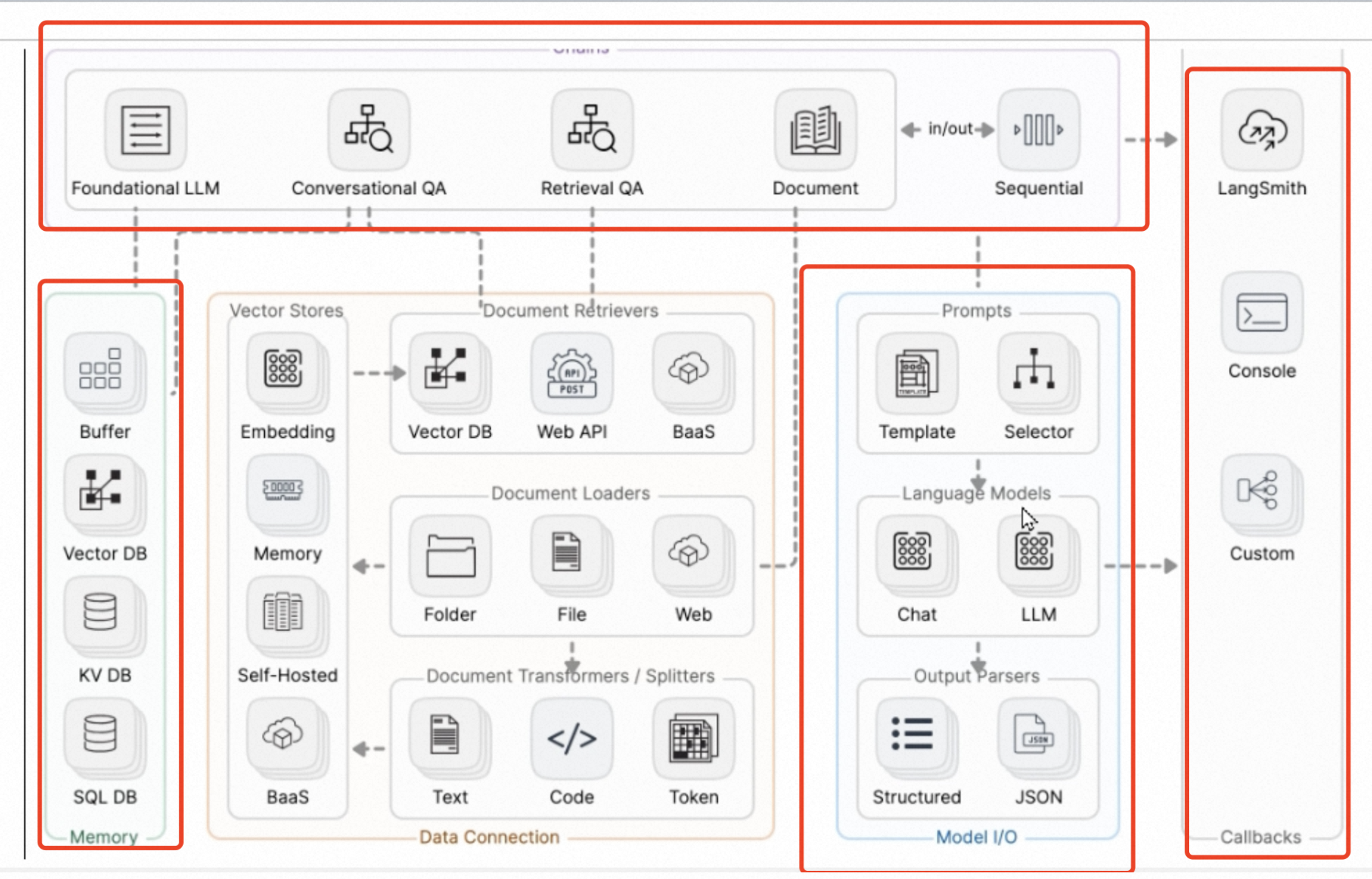
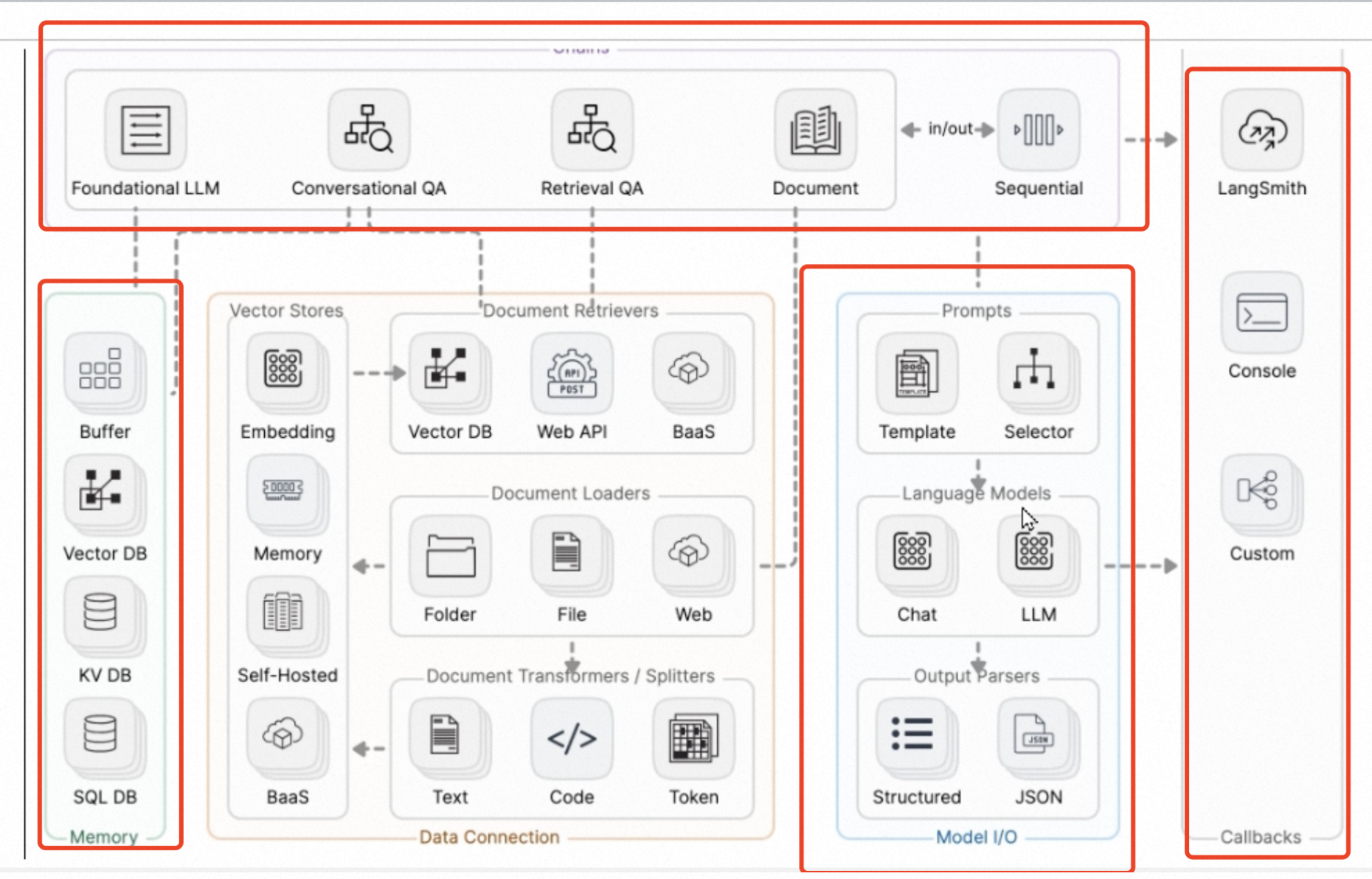
langchain 基础
LangChain 六大组件
- 1 Model 模型
- 2 Memory 记忆
- 3 Retrieval 检索
- 4 Chains 链
- 5 Agents 智能体
- 6 Callback 回调
可以自由组合上述六大组件
@override
def invoke(
self,
input: LanguageModelInput,
config: RunnableConfig | None = None,
*,
stop: list[str] | None = None,
**kwargs: Any,
) -> AIMessage:
config = ensure_config(config)
*表示强制关键字参数 (Keyword-Only Arguments),后面的参数必须通过名字指定,不能通过位置指定,比如要传stop的时候,一定要stop=xxx去传递参数
**k wargs表示收集多余的关键字参数,类似于js的…args。
chat model写法不同
// 0.3
# llm_glm= ChatOpenAI(
# model="glm-4.5-air",
# temperature=1.0,
# api_key=api_key,
# base_url="https://open.bigmodel.cn/api/paas/v4"
# )
// 1.0
llm_glm1 = init_chat_model(
model="glm-4.5-air",
model_provider="openai",
api_key=api_key,
base_url="https://open.bigmodel.cn/api/paas/v4"
)
可以看到,1.0收缩了入口,不用什么模型统一用init_chat_model,0.3x版本不同的模型还是有不同的入口的
def init_chat_model(
model: str | None = None,
*,
model_provider: str | None = None,
configurable_fields: Literal["any"] | list[str] | tuple[str, ...] | None = None,
config_prefix: str | None = None,
**kwargs: Any,
) -> BaseChatModel | _ConfigurableModel:
Model I/O大模型接口
Langchain的Model I/O模块,是与大模型进行交互的核心组件。
Model I/O:标准化各个大模块的输入,输出,包含输入模版,模型本身和格式化输出。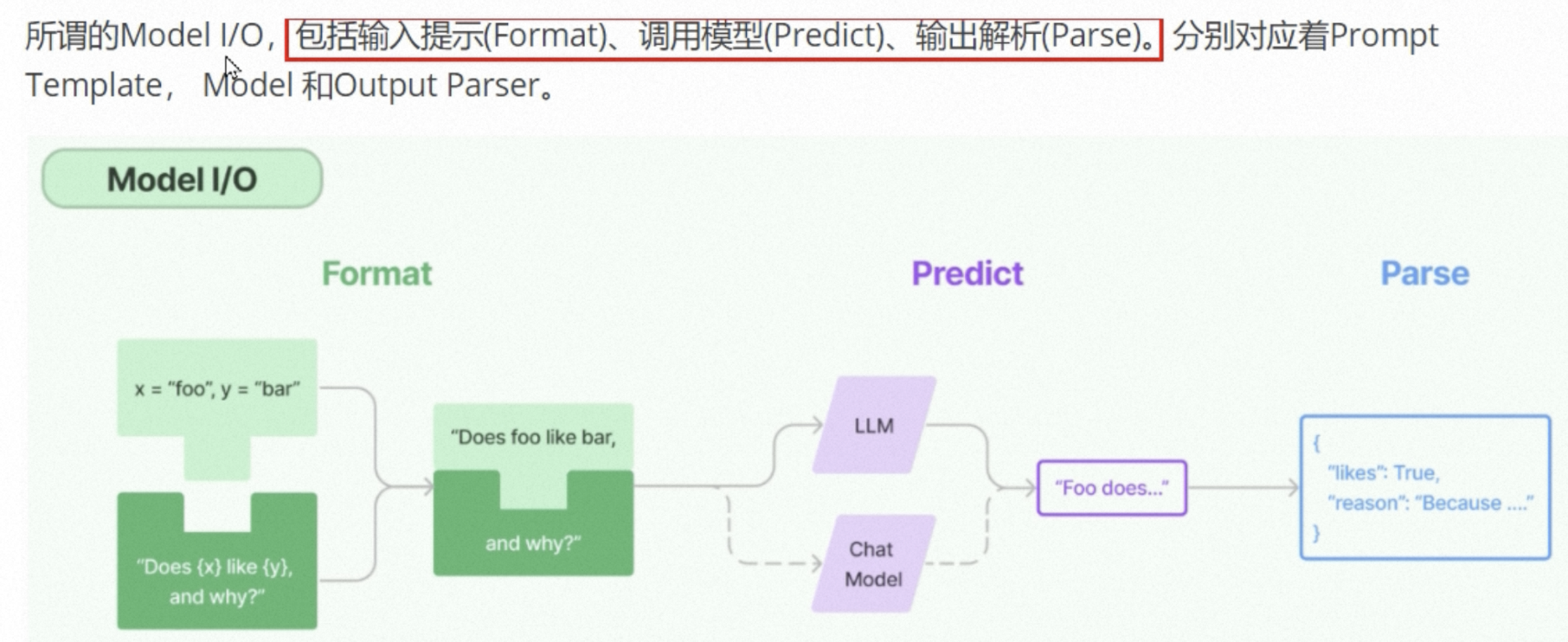
三大部分:输入提示(Prompt Template),调用模型(Predict也就是Model),以及输出解析(Output Parser)
一 Prompt Templat 文本提示词模版
四大角色:SystemMessage HumanMessage AIMessage ToolMessage
0.3版本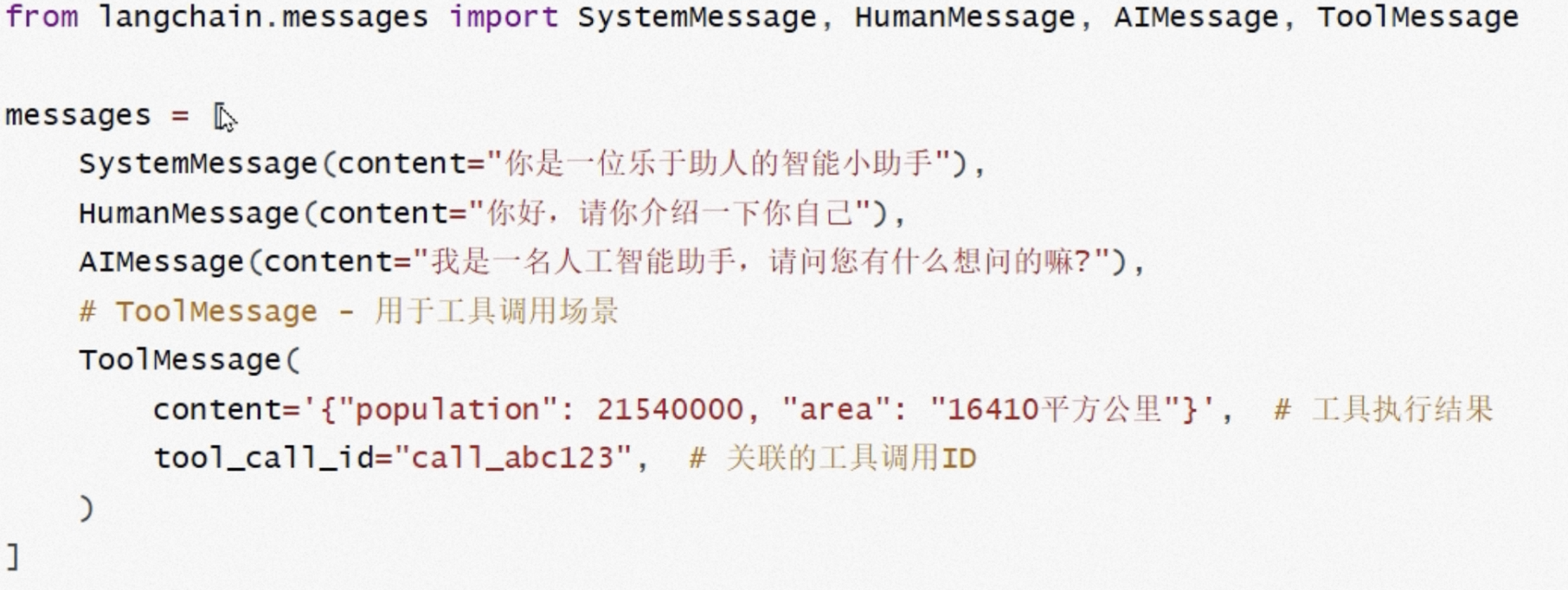
1.0版本
message = [('system', 'xxx'), ('human', 'xxx'), ('ai', 'xxx')]
实例化模版
template = PromptTemplate(tempalte="你是一个{a},请回答我的问题: {b}", input_variables = ['a', 'b'])
# 同等写法
template1 = PromptTemplate.from_template("你是一个{a},请回答我的问题: {b}")
prompt = template.format("前端工程师", "js是同步还是异步的")
response = llm.invoke(prompt)
部分提示词模版:简单地说就是允许先填一部分变量,后面要用到再填一部分变量
template1 = PromptTemplate.form_template("现在是{a},天气:{b}", partial_variables={"a": datetime.now()})
# 同等写法
template2 = tempalte1.partial(time="xxx")
prompt = tempalte.fromt(question="天气晴朗")
提示词组合
template3 = template1 + template2 // 支持这样的组合去用
template3.format("xxxxxx")
模版调用
- format
- invoke
template.invoke({a:"1", b: "2"}),支持.to_string, .to_message() - partial 支持先传入变量
ChatPromptTemplate 对话提示词模版
// 创建不同角色的消息
const translateInstructionTemplate = SystemMessagePromptTemplate.fromTemplate(`你是一个专
业的翻译员,你的任务是将文本从{source_lang}翻译成{target_lang}。`);
const userQuestionTemplate = HumanMessagePromptTemplate.fromTemplate("请翻译这句话:{text}")
// chatPrompt支持组合,主要是传入给llm
// 实例化有三种可以用
// 1 Message 类构成的数组
const chatPrompt = ChatPromptTemplate.fromMessages([
translateInstructionTemplate,
userQuestionTemplate,
]);
// 元祖
const chatPrompt = ChatPromptTemplate([
("system", "你是一个xx,你的名字是{a}"),
("human", "我向提问: {b}"),
("ai", "我可以开发很多{thing}"),
("human", "{user_input}")
])
// 也可以 dict构成的列表
const chatPrompt = ChatPromptTemplate.fromMessages([
{role: "system", content: "你是xx"},
{role: "user", content: "xxxx"},
]);
占位符模版
const chatPrompt = ChatPromptTemplate([
("system", "你是一个xx,你的名字是{a}"),
MessagesPlaceholder("memory"),
// 插入memory占位符,调用的时候只需要传入memory: [HumanMessage("xxx"), AIMessage("xxx")],memory可以是多个Message数组
("placeholder", "{memory}") // 同等写法
("human", "我向提问: {b}"),
("ai", "我可以开发很多{thing}"),
("human", "{user_input}")
])
chatPrompt.invoke({
memory: [],
user_input: "xxx"
})
外部加载prompt
可以将prompt保存为json/yaml,需要的时候再加载,也可以放到MCP服务器上,方便管理和维护
二 模型调用
/**
* 初始化LLM客户端
*/
function initLlmClient(): ChatOpenAI {
if (!apiKey) {
// 相当于 python 的 raise ValueError
throw new Error("环境变量 ZHIPUAPIKEY 不存在");
}
const llm = new ChatOpenAI({
model: "glm-4.5-air",
temperature: 1.0,
apiKey: apiKey,
configuration: {
baseURL: "https://open.bigmodel.cn/api/paas/v4",
},
});
return llm;
}
invoke ainvoke
stream astream
batch batch
async def main():
try:
llm_glm1 = init_llm_client()
print("LLM客户端初始化成功")
question = "你是谁"
response = llm_glm1.ainvoke (question)
print("第一个问题已经提问")
responseStream = llm_glm1.ainvoke("介绍一下langChain,300字以内")
print("第二个问题已经提问")
print(f"答案: {response.__await__(), responseStream.__await__()}")
except ValueError as e:
print(f"配置出错, {str(e)}")
except LangChainException as e:
print(f"模型调用失败: {str(e)}")
except Exception as e:
print(f"未知错误: {str(e)}")
async def async_batch_call():
llm_glm1 = init_llm_client()
questions = ["你是谁", "今天是周几"]
response = await llm_glm1.abatch(questions)
print(f"响应类型 {type(response)}")
for q, r in zip(questions, response):
print(f"问题 {q} \n 回答: {r.content}\n")
if __name__ == "__main__":
asyncio.run(async_batch_call())
a开头的是异步,除了astream之外,其他都要用await修饰,然后通过asyncio.run去执行异步函数
三 输出解析器 OutputParser
指定格式输出,数据校验(确保输出内容符合预期的格式和类型),错误处理(当解析失败,进行错误修复和重试),输出格式提示词
class Test(BaseModel): # 强校验
time: str = Field(description="时间")
person: str = Field(description="人物")
event: str = Field(description="事件")
def test_output():
llm_glm1 = init_llm_client()
jsonOutput = JsonOutputParser(pydantic_object=Test)
prompt = ChatPromptTemplate([
("system", "你是一个车企助手,尽可能回答用户的问题\n\n{format_instructions}"),
("human", "2025年车企的一些事情")
])
template2 = prompt.format_messages(format_instructions=jsonOutput.get_format_instructions())
# 等价于
template = prompt.invoke({"format_instructions": jsonOutput.get_format_instructions()})
llm_glm1.invoke(template)
if __name__ == "__main__":
# asyncio.run(async_batch_call())
test_output()
node写法
// 使用 Zod 代替 Pydantic 做结构校验(对应 Python 的 BaseModel)
const TestSchema = z.object({
time: z.string().describe("时间"),
person: z.string().describe("人物"),
event: z.string().describe("事件"),
});
type TestType = z.infer<typeof TestSchema>;
async function testOutput() {
const llm = initLlmClient();
// 这里使用
const jsonOutputParser = new JsonOutputParser<TestType>();
const prompt = ChatPromptTemplate.fromMessages([
[
"system",
"你是一个车企助手,尽可能回答用户的问题\n\n{format_instructions}",
],
["human", "2025年车企的一些事情"],
]);
const formatInstructions = `请以 JSON 格式回复,包含以下字段:time(时间)、person(人物)、event(事件)`;
const messages = await prompt.formatMessages({
format_instructions: formatInstructions,
});
console.log(messages);
const chain = prompt.pipe(llm).pipe(jsonOutputParser);
const result = await chain.invoke({
format_instructions: formatInstructions,
});
console.log(result);
}
进阶用法
TypedDict, Annotated,这两个校验,类似于nest的classvaide,但是不会报错,直接静态提示。
Annotated给变量的基础类型附加元数据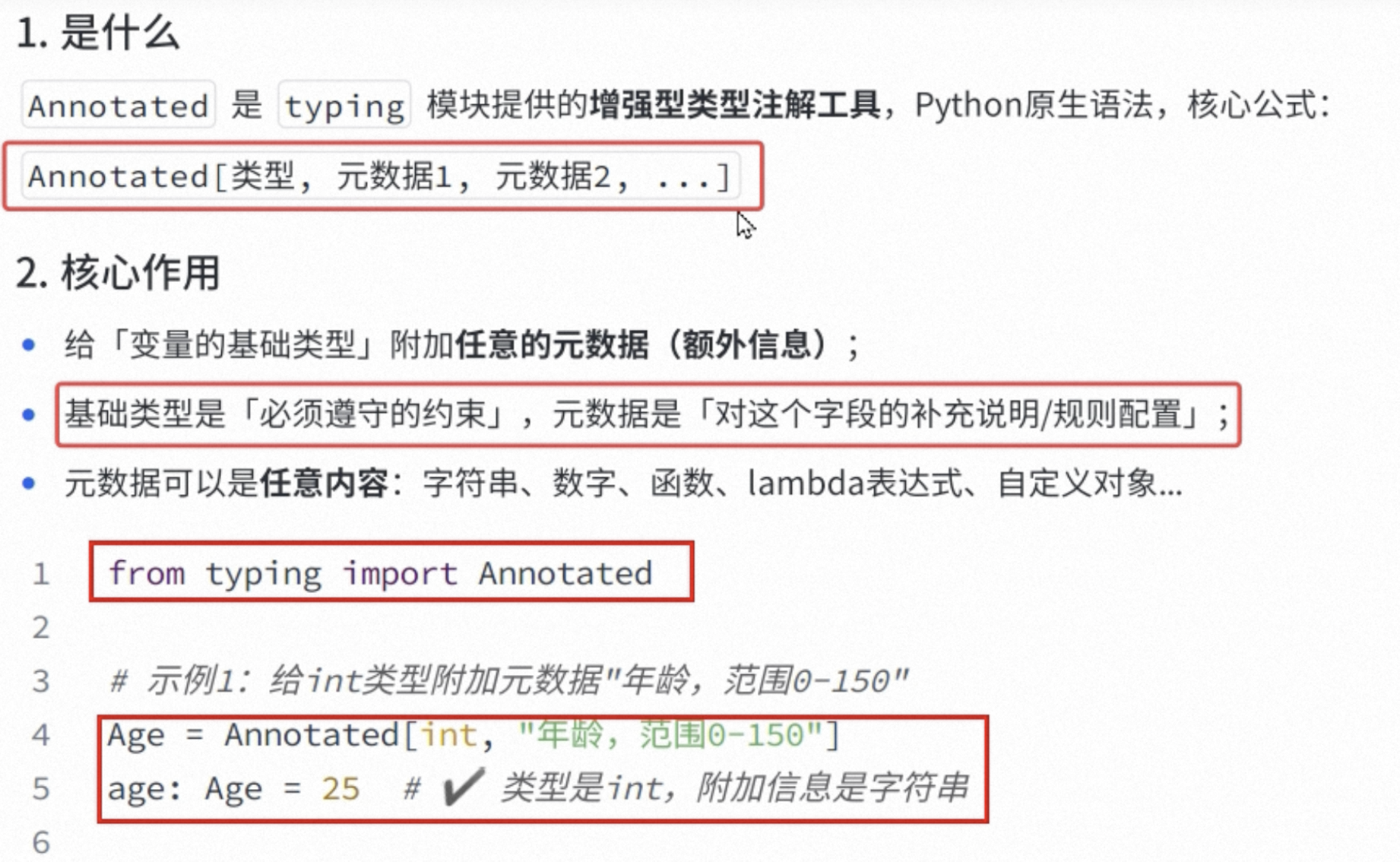
Pedantic: 强校验,类似于nest的classvaide,如果类型不符合会报错。
Pedantic.BaseModel + Annotated
from pydantic import Field, BaseModel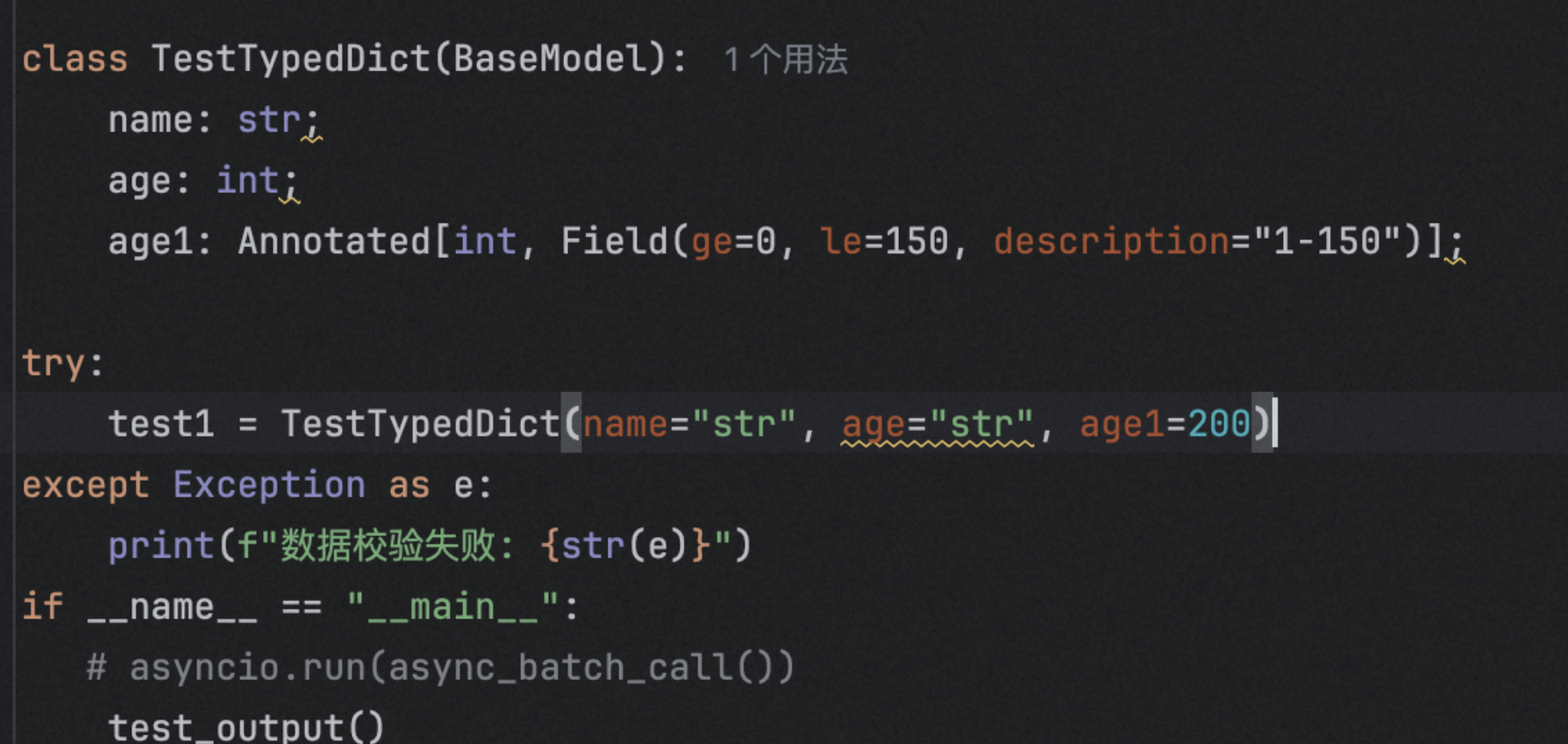
LCEL 链式调用
Runnable
Runnable是langchain的抽象基类(abstract base class),统一组件调用方式,支持LCEL组合,适配同步/异步/批量等场景,他是构建工作流的基础。
像invoke,ainvoke,stream,astream,batch,abatch
LCEL等价于linux的管道符 | ,等价于nest的管道pipe
上一个执行的输出可以给到下一个函数的输入。
可以发现:不管是提示词模版prompt,还是模型llm,还是解析器parser,又或者是chain,他们都有invoke方法,这就是为了统一组件的调用方法,他们都继承Runnable.
只要实现了Runnabke,不管是什么组件,都可以调用invoke方法或者使用管道符
LCEL
langchain的表达式语言,专门用于组合Runnable组件的声明式语法。核心操作符:|
典型:
链:
chain = prompt | model | output_parser
链本身也是Runnable组件:
chain.invoke({"a": "xx"})
chain = prompt | model | output_parser
chain.invoke({})
# 等价于下述操作
prompt = template.invoke()
response = llm.invoke(prompt)
res = output_parser.invoke(response)
链的分类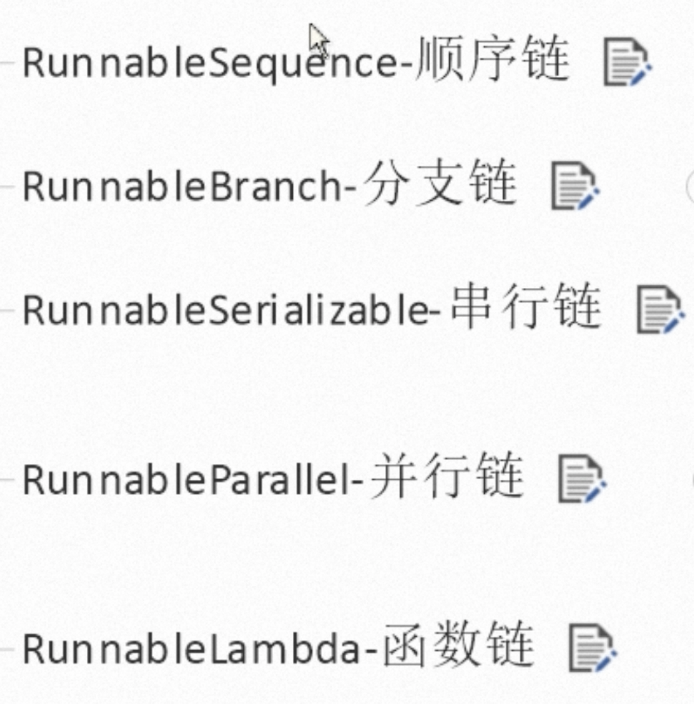
**顺序链 RunnableSequence **
简单的prompt | model | output_parser,按照顺序来
def runnableSequence():
llm1 = init_llm_client()
prompt = ChatPromptTemplate([
("system", "你是一个情感助手"),
("human", "今天我心情不太好")
])
parser = StrOutputParser()
chain = prompt | llm1 | parser
res = chain.invoke({})
print(f"类型: {type(res)}")
if __name__ == "__main__":
# asyncio.run(async_batch_call())
runnableSequence()
分支链RunnableBranch
def runnableBarhh():
llm1 = init_llm_client()
parser = StrOutputParser()
riben_prompt = ChatPromptTemplate([("system", "你是一个翻译专家,专门翻译日语"), ("human", "{input}")])
hanyu_prompt = ChatPromptTemplate([("system", "你是一个翻译专家,专门翻译韩语"), ("human", "{input}")])
english_prmpt = ChatPromptTemplate([("system", "你是一个翻译专家,专门翻译英语"), ("human", "{input}")])
chain = RunnableBranch(
(lambda x: select_language(x["input"]) == "riben", riben_prompt | llm1 | parser),
(lambda x: select_language(x["input"]) == "hanyu", hanyu_prompt | llm1 | parser),
english_prmpt | llm1 | parser # 默认分支
)
print(chain.invoke({
"input": "请你用英文翻译这句话,见到你很开心",
}))
if __name__ == "__main__":
# asyncio.run(async_batch_call())
runnableBarhh()
顺序链的基础上,加上RunnableBranch,每一个分支流向一条链。前面的lambda表达式是判断条件。
node写法
function selectLanguage(x: string): string {
if (x.includes("日语")) return "riben";
if (x.includes("韩语")) return "hanyu";
return "english";
}
async function runnableBranch() {
const llm = initLlmClient();
const parser = new StringOutputParser();
const ribenPrompt = ChatPromptTemplate.fromMessages([
["system", "你是一个翻译专家,专门翻译日语"],
["human", "{input}"],
]);
const hanyuPrompt = ChatPromptTemplate.fromMessages([
["system", "你是一个翻译专家,专门翻译韩语"],
["human", "{input}"],
]);
const englishPrompt = ChatPromptTemplate.fromMessages([
["system", "你是一个翻译专家,专门翻译英语"],
["human", "{input}"],
]);
const chain = RunnableBranch.from([
[
(x: { input: string }) => selectLanguage(x.input) === "riben",
ribenPrompt.pipe(llm).pipe(parser),
],
[
(x: { input: string }) => selectLanguage(x.input) === "hanyu",
hanyuPrompt.pipe(llm).pipe(parser),
],
englishPrompt.pipe(llm).pipe(parser), // 默认分支
]);
const result = await chain.invoke({
input: "请你用英文翻译这句话,见到你很开心",
});
console.log(result);
}
串行链 RunnableSerializable
跟顺序链有点像,但他是串行多条子链。
def runnableSerializable():
# 第一条链
llm1 = init_llm_client()
prompt1 = ChatPromptTemplate([
("system", "你是一个天气专家"),
("human", "今天天气如何")
])
parser1 = StrOutputParser()
chain1 = prompt1 | llm1 | parser1
# 第二条链
llm2 = init_llm_client()
prompt2 = ChatPromptTemplate([
("system", "你是一个翻译助手,将用户输入内容翻译成英文"),
("human", "{input}")
])
parser2 = StrOutputParser()
chain2 = prompt2 | llm2 | parser2
# lambda将返回的字符串,包装成{input: xx}返回
chain3 = chain1 | (lambda content: {"input": content}) | chain2
print(chain3.invoke({}))
if __name__ == "__main__":
# asyncio.run(async_batch_call())
runnableSerializable()
如上,多条子链相加所得,也就是说,链的一部分可以是Runnable组件,也可以是一个链
async function runnableSerializable() {
// 第一条链
const llm1 = initLlmClient();
const prompt1 = ChatPromptTemplate.fromMessages([
["system", "你是一个天气专家"],
["human", "今天天气如何"],
]);
const parser1 = new StringOutputParser();
const chain1 = prompt1.pipe(llm1).pipe(parser1);
// 第二条链
const llm2 = initLlmClient();
const prompt2 = ChatPromptTemplate.fromMessages([
["system", "你是一个翻译助手,将用户输入内容翻译成英文"],
["human", "{input}"],
]);
const parser2 = new StringOutputParser();
const chain2 = prompt2.pipe(llm2).pipe(parser2);
// 将第一条链的输出包装成 {input: content} 传入第二条链(对应 Python 的 lambda)
const chain3 = chain1
.pipe((content: string) => ({ input: content }))
.pipe(chain2);
const result = await chain3.invoke({});
console.log(result);
}
RunnableParallel 并行链
同时运行多条子链,在他们完成后汇总结果
def runnableParallel():
# 第一条链
llm1 = init_llm_client()
prompt1 = ChatPromptTemplate([
("system", "你是一个天气专家"),
("human", "{input}")
])
parser1 = StrOutputParser()
chain1 = prompt1 | llm1 | parser1
# 第二条链
llm2 = init_llm_client()
prompt2 = ChatPromptTemplate([
("system", "你是一个翻译助手,将用户输入内容翻译成英文"),
("human", "{input}")
])
parser2 = StrOutputParser()
chain2 = prompt2 | llm2 | parser2
chain3 = RunnableParallel({
"weather": chain1,
"english": chain2,
})
print(chain3.invoke({"input": "今天深圳天气如何"}))
node写法
async function runnableParallelDemo() {
// 第一条链
const llm1 = initLlmClient();
const prompt1 = ChatPromptTemplate.fromMessages([
["system", "你是一个天气专家"],
["human", "{input}"],
]);
const parser1 = new StringOutputParser();
const chain1 = prompt1.pipe(llm1).pipe(parser1);
// 第二条链
const llm2 = initLlmClient();
const prompt2 = ChatPromptTemplate.fromMessages([
["system", "你是一个翻译助手,将用户输入内容翻译成英文"],
["human", "{input}"],
]);
const parser2 = new StringOutputParser();
const chain2 = prompt2.pipe(llm2).pipe(parser2);
const chain3 = RunnableParallel.from({
weather: chain1,
english: chain2,
});
const result = await chain3.invoke({ input: "今天天气怎么样" });
console.log(result);
}
通过RunnableParallel创建一个并行链,此时返回结果就是
{
"weather": "xxx",
"english": "xxxxx"
}
多个同时执行,执行完后一起返回
函数链 RunnableLambda
将普通的python函数,作为中间节点,融入函数链
def debug_print(x):
print(f"中间结果: {x}")
return {"input": x}
def runnableLambda():
llm1 = init_llm_client()
prompt1 = ChatPromptTemplate([
("system", "你是一个AI助手"),
("human", "{input}")
])
parser1 = StrOutputParser()
chain1 = prompt1 | llm1 | parser1
# 第二条链
llm2 = init_llm_client()
prompt2 = ChatPromptTemplate([
("system", "你是一个翻译助手,将用户输入内容翻译成英文"),
("human", "{input}")
])
parser2 = StrOutputParser()
chain2 = prompt2 | llm2 | parser2
# 创建一个可运行的调试节点,用于中间打印结果 !!!,将函数作为中间节点
debug_node = RunnableLambda(debug_print)
full_chain = chain1 | debug_node | chain2
result = full_chain.invoke({"input": "你能做什么"})
print(result)
之前串行链的lambda函数也算是函数链,但是没抱过RunnableLambda函数,langchain默认会包上
如上,将打印函数用RunnableLambda包装成一个节点(记得返回对应数据),然后作为chain的一个节点去运行。这个中间节点就可以拿到中间数据进行打印了。
sync function runnableLambda(){
// 第一条链
const llm1 = initLlmClient();
const prompt1 = ChatPromptTemplate.fromMessages([
["system", "你是一个AI助手"],
["human", "{input}"],
]);
const parser1 = new StringOutputParser();
const chain1 = prompt1.pipe(llm1).pipe(parser1);
// 第二条链
const llm2 = initLlmClient();
const prompt2 = ChatPromptTemplate.fromMessages([
["system", "你是一个翻译助手,将用户输入内容翻译成英文"],
["human", "{input}"],
]);
const parser2 = new StringOutputParser();
const chain2 = prompt2.pipe(llm2).pipe(parser2);
const debugNode = RunnableLambda.from(debug_print)
const chain3 = chain1.pipe(debugNode).pipe(chain2)
const res = await chain3.invoke({"input": "你能做些什么"})
console.log(res)
}

五 记忆缓存 Memory模块
一个记忆组件要实现:
1 读取记忆组件保存的历史对话信息
2 写入历史对话信息到历史组件
3 存储历史对话信息
给大模型添加记忆功能一般如下:
- 在链执行前,将历史消息从记忆组件读取出来,和用户输入一起添加到提示词中,传递给大语言模型。
- 在链执行完毕后,将用户的输入和大模型输出,一起写到记忆组件中。
- 下一次调用大语言模型的时候,重复这个过程。
版本介绍
ConverstaionChain是lang chain早起简化对话管理的类,但是灵活性不足,且与新的api不兼容,所以0.3之后。开始推荐RunnableWithMessageHistory,它的优势有
- 模块化:允许自由组合提示模版,模型和内存管理逻辑。
- 灵活性:支持自定义对话历史存储和复杂对话流程
- 兼容性:与LCEL和现代聊天模型无缝集成。
- 长期支持,在0.3版本中稳定,且1.0也不会移除。
简单对话
使用BaseChatMessageHistory和RunnableWithMessageHistory结合。
BaseChatMessageHistory是抽象基类
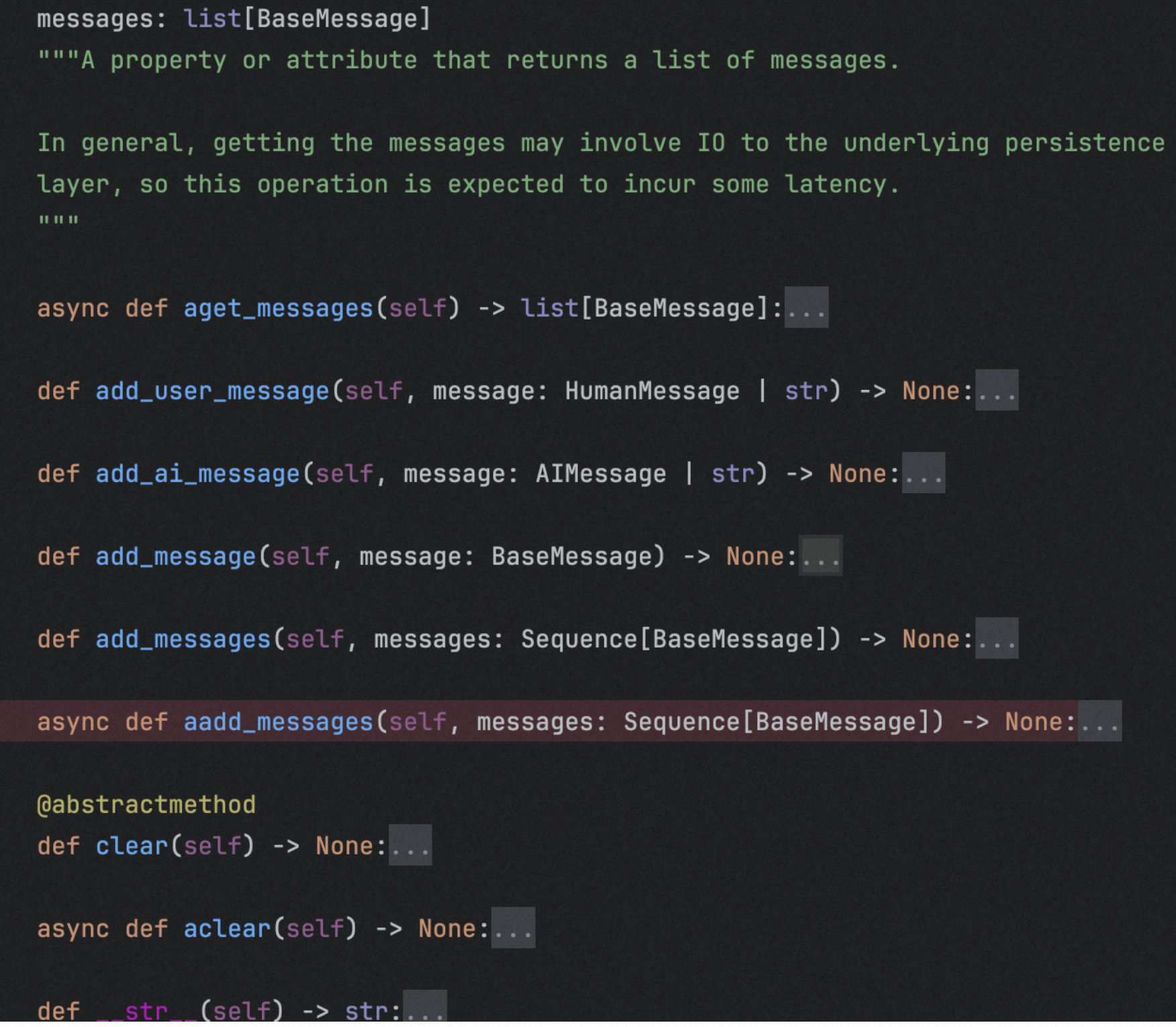
看其属性和方法
List[BaseMessage]: 用来接收和读取历史消息的只读属性
add_messages: 批量添加
add_message: 单独添加
Clear: 清空所有
这个只是抽象类,还有实现类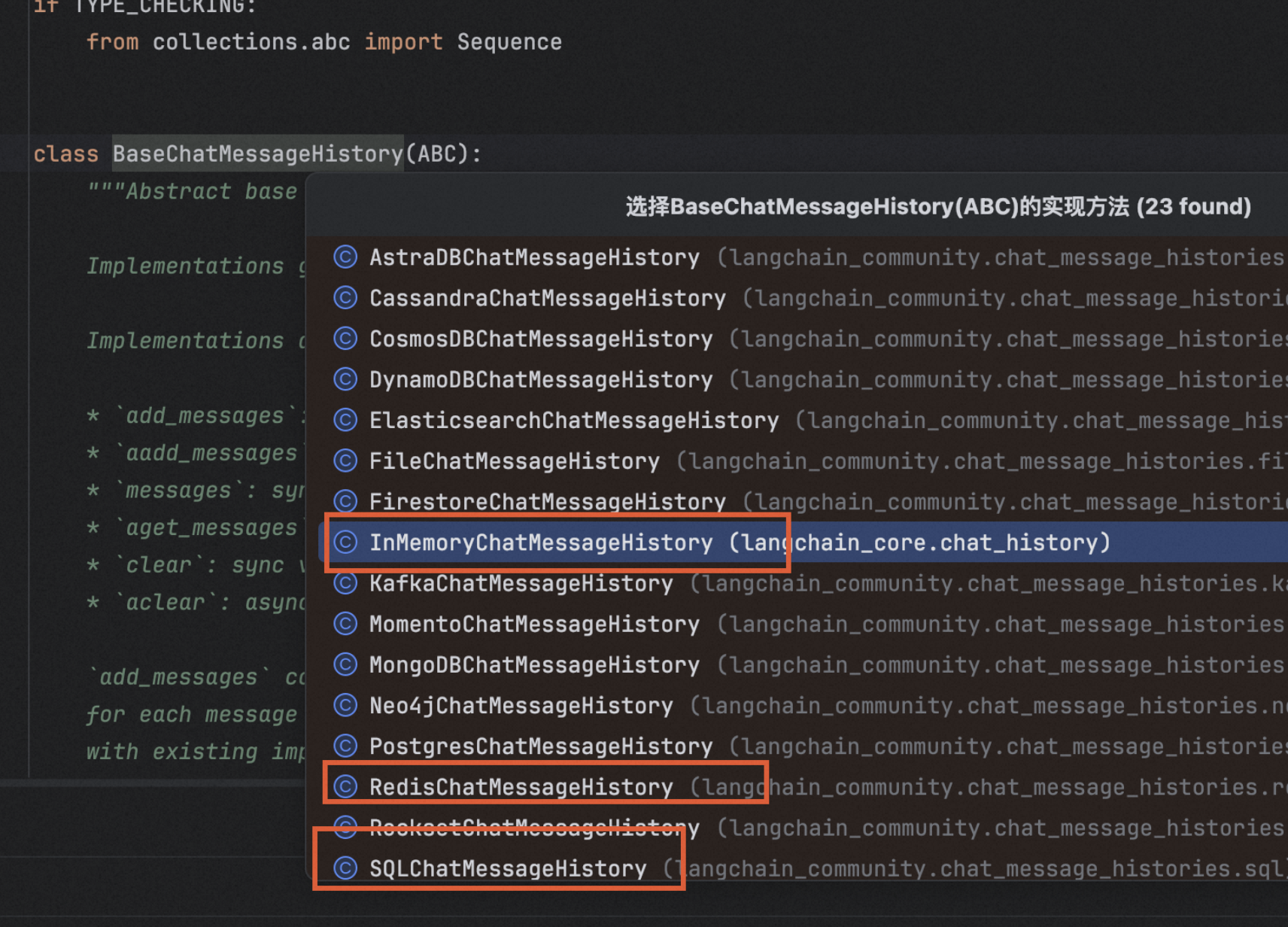
常见的消息历史组件
- InMemoryChatMessageHisotry 基于
内存存储的聊天消息历史组件 - FileChatMessageHisotry 基于
文件存储的聊天消息历史组件 - RedisChatMessageHistory 基于
Redis存储的聊天消息历史组件 - ElasticearchChatMesasageHistory 基于
ES存储
复杂场景
langGraph persistence(Checkpointer + COntent Blocks + 记忆中间件)
记忆 内存版
#模拟全局缓存,后续可以换成redis等
store = {}
def get_message_history(session_id: str):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory();
return store[session_id]
def memoryHistory():
llm = init_llm_client();
prompt1 = ChatPromptTemplate([
("system", "你是一个AI助手"),
MessagesPlaceholder("history"), # 历史数据占位符
("human", "{input}")
])
parser = StrOutputParser()
chain = prompt1 | llm | parser
# 创建内存聊天实例,用于存储会话历史
# 创建带消息历史的可运行对象,用于处理带历史记录的会话
runnbale = RunnableWithMessageHistory(chain,
# 通过id指定历史对象,多个对象历史对象可能不同,每次调用invoke都会自动加对话存到history里面
get_session_history=lambda session_id: get_message_history(session_id),
input_messages_key="input", # 指定输入键
history_messages_key="history", # 消息历史插槽键
)
# 通过RunnableConfig配置运行时参数
config = RunnableConfig(configurable={"session_id": "1"})
print(runnbale.invoke({"input": "我叫小明"}, config))
print(runnbale.invoke({"input": "我是谁"}, config))
if __name__ == "__main__":
# asyncio.run(async_batch_call())
memoryHistory()
需要一个配置config,通过RunnableConfig包裹,指定session_id,根据这个id获取history历史对象。
然后p rompt需要包含历史记忆插槽, MessagesPlaceholder("history"),,这样才能在prompt中插入对应的历史信息。
最后使用RunnableWithMessageHistory对象包裹chain,被包裹的chain就拥有了历史功能,会自动将对话加入到history,并且每次都会从history读取历史信息,注入到prompt里面。只不过需要指定history_messages_key和input_messages_key,其次需要指定get_session_history,让其能知道是用哪个history对象,这样一个带有记忆功能的chain就诞生了。
RedisChatMessageHistory:基于Redis存储聊天历史
用法跟InMemoryChatMessageHistory一样
可以创建History对象,配合RunnableWithMessageHistory使用,可以创建一个有记忆的chain
Tools (Function Callings 0.3版本叫法) 工具调用
当大模型识别问题超出自身能力范围时自动触发
执行流程:
- 模型返回工具调用请求(非纯文本)
- 应用程序解析并执行对应工具(由你的应用去调用方法,大模型本身并不执行,他只是指示调用哪个函数)
- 将执行结果整合成Prompt返回给模型。
1.0版本叫做ToolMessage(以前是:FunctionMesssage)
自定义Tool
使用@tool装饰器,可以将普通函数转换为langchain函数
from langchain_core.tools import tool
@tool
def add_number(a:int, b: int) -> int:
"""两个整数相加"""
return a + b
def test_tool():
print(add_number.invoke({"a": 1, "b": 2}))
print(add_number.name, add_number.description, add_number.args)
3
add_number 两个整数相加 {'a': {'title': 'A', 'type': 'integer'}, 'b': {'title': 'B', 'type': 'integer'}}
可以通过函数.name等获取函数的信息,将其交给大模型。
通过@tool装饰器的函数,也是一个Runnable对象
Pydantic有点像ts,给类加上pydantic.BaseModel后,实例化的那一刻,就会按类型注解
- 类型检查, int必须是int
- 自动转换,“123” -> 123(但是不能int -> str)
- 字段缺失,超范围的,格式不对都会报错
Pydantic = "类型注解 + 自动校验 + 转换"神器,让Python在运行时也能享受“静态类型”的安全感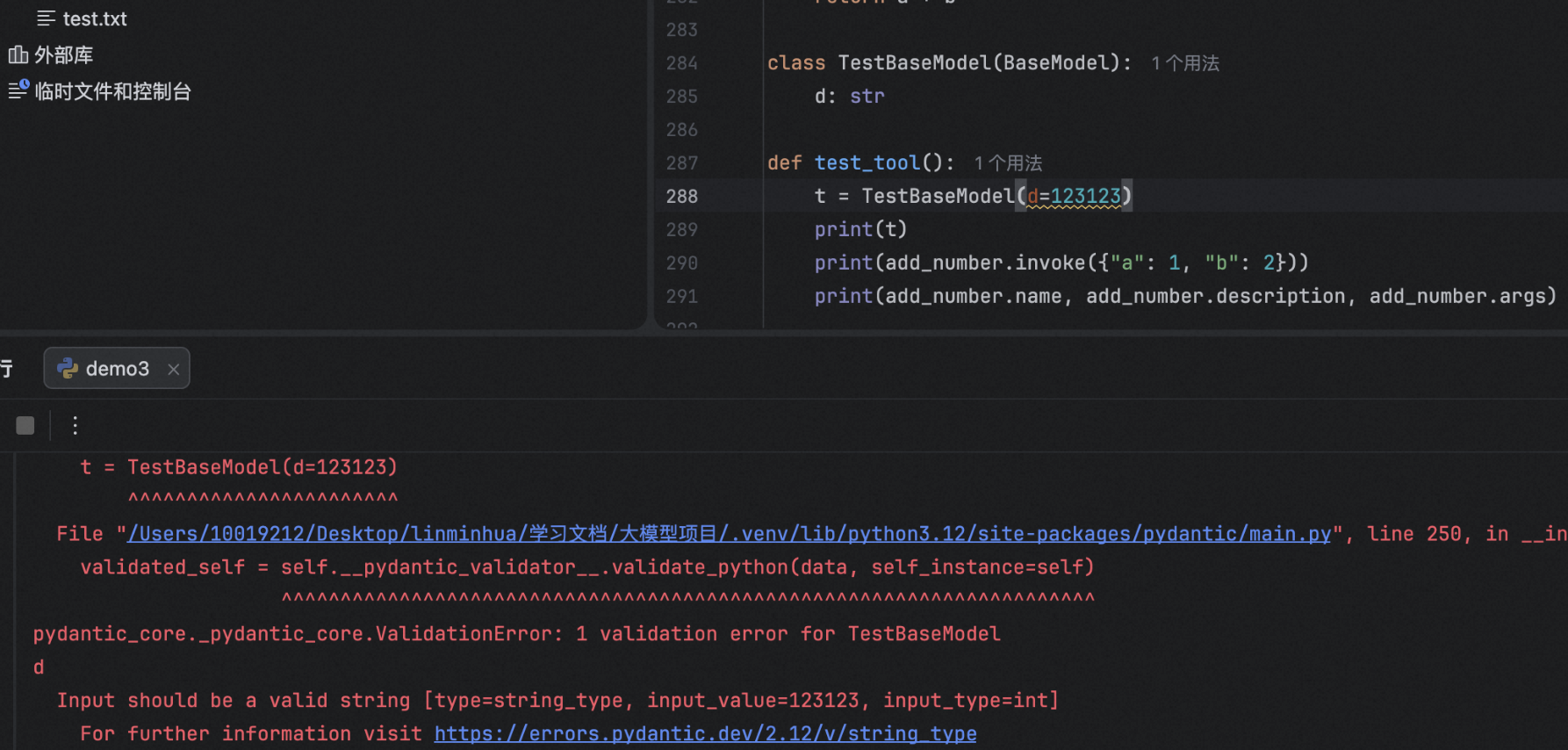
调用
def test_tool2():
llm = init_llm_client();
# 绑定工具,调用后,他会返回需要使用的工具的信息
llm_with_tools = llm.bind_tools([get_weather])
print(llm_with_tools.invoke("北京天气如何"))
当我们有一个工具给llm绑定后,再去调用的时候,
内容是
content='我来为您查询北京的天气情况。\n'
additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 81, 'prompt_tokens': 255, 'total_tokens': 336, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 43}},
'model_provider': 'openai', 'model_name': 'glm-4.5-air',
'system_fingerprint': None, 'id': '20260313093822c0f62886300841e7',
'finish_reason': 'tool_calls', 'logprobs': None}
id='lc_run--019ce4d8-3d00-7210-8333-5498e28e468b-0'
tool_calls=[{'name': 'get_weather', 'args': {'loc': 'beijing'}, 'id': 'call_-7807238821631751323', 'type': 'tool_call'}] invalid_tool_calls=[] usage_metadata={'input_tokens': 255, 'output_tokens': 81, 'total_tokens': 336, 'input_token_details': {'cache_read': 43}, 'output_token_details': {}}
如下,他会有一个tool_calls,里面就是调用工具的信息描述。
然后需要一个解析器,解析大模型返回的这串内容
def test_tool2():
llm = init_llm_client();
# 绑定工具,调用后,他会返回需要使用的工具的信息
llm_with_tools = llm.bind_tools([get_weather])
print(llm_with_tools.invoke("北京天气如何"))
# 解析器,解析llm返回的调用工具的描述
parser = JsonOutputKeyToolsParser(key_name=get_weather.name, first_tool_only=True)
# 天气链,问绑定过大模型工具的天气如何,返回tool_calls给parser,parser处理数据执行get_weather获取结果
get_weather_chain = llm_with_tools | parser | get_weather
print(get_weather_chain.invoke("北京天气如何"))
最后解析器就会拿到上面那一串进行处理,得到{'loc': 'beijing'}
再通过管道,给get_weather去invoke调用,最终返回
{'code': 200, 'contet': '北京的天气凉爽'}
然后我们需要一个调用链
output_prompt = ChatPromptTemplate.from_messages([
("system", """
你将收到一段json格式的天气数据,请用简洁自然的方式将其转述给用户
"""),
("human", "{weather_json}")
])
parser1 = StrOutputParser()
debug_node = RunnableLambda(debug_print)
outputChain = output_prompt | llm | debug_node | parser1
# 将两条链组合
chain2 = get_weather_chain | (lambda json:{"weather_json": json})| debug_node | outputChain
res = chain2.invoke("北京天气如何")
return res
调用链就是正常的解析get_weather返回的结果,解析成自然语言返回给用户。
然后将两条链组合,中间使用lambda函数转换数据格式。最终结果
北京今天阴天,气温20度,多云。
向量化模型
文本,音频,视频都可以通过embedding model将其向量化,专程一组数组,有1024唯,也有512唯的,维度越高,匹配度越高。
阿里的
def embeding():
# 支持传入图片,音频,但是一般都使用文本
input_texts = "衣服的质量杠杠的,很漂亮,不枉我等了这么久啊,喜欢,以后还来这里买"
resp = dashscope.MultiModalEmbedding.call(
model="tongyi-embedding-vision-flash",
input=[{"text": input_texts}],
api_key=tongyi_api_key
)
print(resp)
其他的使用openAI通用
def otherEmbedding():
client = OpenAI(
api_key=api_key,
base_url=zhipu_url
)
completion = client.embeddings.create(
model="embedding-3",
input="你好啊"
)
print(completion.model_dump_json())
模版
def embeddingTemplate():
embedding = OpenAIEmbeddings(
model="embedding-3",
api_key=api_key,
base_url=zhipu_url
)
text = "test"
query_result = embedding.embed_query(text)
doc_results = embedding.embed_documents([
"你好",
"我是谁",
"哈哈哈"
])
print(len(doc_results), len(query_result))
OpenAIEmbeddings是专门做Embedding的,通用的就用OpenAIEmbeddings,如果用通义专用的,可以用其专用的api
向量数据库

用法基本一样。
def test_redis():
# 初始化embedding模型
embedding = OpenAIEmbeddings(
model="embedding-3",
api_key=api_key,
base_url=zhipu_url
)
# 向量化的文本/文件
texts = ["你好啊", "Redis是个高性能的存储系统", "langchain可以轻松集成各大模型和向量数据库"]
# 不管是什么类型的数据,都得转成Docuemnts
documents = [Document(page_content=text, metadata={"source": "manual"}) for text in texts]
vecotr_store = Redis.from_documents(
documents=documents, # 向量话文档
embedding=embedding, # Embedding 模型
redis_url="redis://redis:6379", # redis地址
index_name= "my_index11" # 向量索引名称
)
# 创建检索器
retriver = vecotr_store.as_retriever(search_kwargs={"k": 2}) # 返回前2
results = retriver.invoke("Langchain和Redis怎么结合")
存入向量数据库后得到一个检索器,可以通过向量相似度获取前几条相似度最高的数据。
RAG
外挂知识库+大模型
- 将数据进行分割,转成向量存入向量数据库
- 检索阶段,根据向量相似度排序,将排序较高的几条数据返回。
- 重排序:返回后的数据继续进行一个重排序。
- 将返回的数据+提问一起作为prompt发给大模型,大模型进行回答。
Langchain组件
LangChain提供了很多组件,方便我们搭建RAG。
- 文档加载器,比如TextLoader,PDFLoader等可以加载各种各样的资源。
- 文档分割器,将加载的文档分割成文档片段,比如RecursiveCHaracterTextSpliter
- 文本嵌入模型:比如OpenAIEmbedding,将文本信息向量化
- 向量数据库组件:VectorStore,向量数据库,将向量和元数据信息保存到向量数据库。
- 文本检索器:VectorStoreRetriver检索器,可以根据用户提问在向量数据库中进行检索。
文档加载器
文档加载器可以讲不同种类的资源,加载成langchain的Documents类,这样不管什么资源都能统一对待。
所有文档加载器都继承自BaseLoader基类,这样使得他们都有一个共同的方法,load,除此之外还有他们各自方法。
Documents类有两个重要属性:
- page_content,表示文档的内容
- Metadata,与文档无关的元数据,比如作者的姓名,id等任意信息。
loader =TextLoader("./test.txt")
documents = loader.load()
分割器
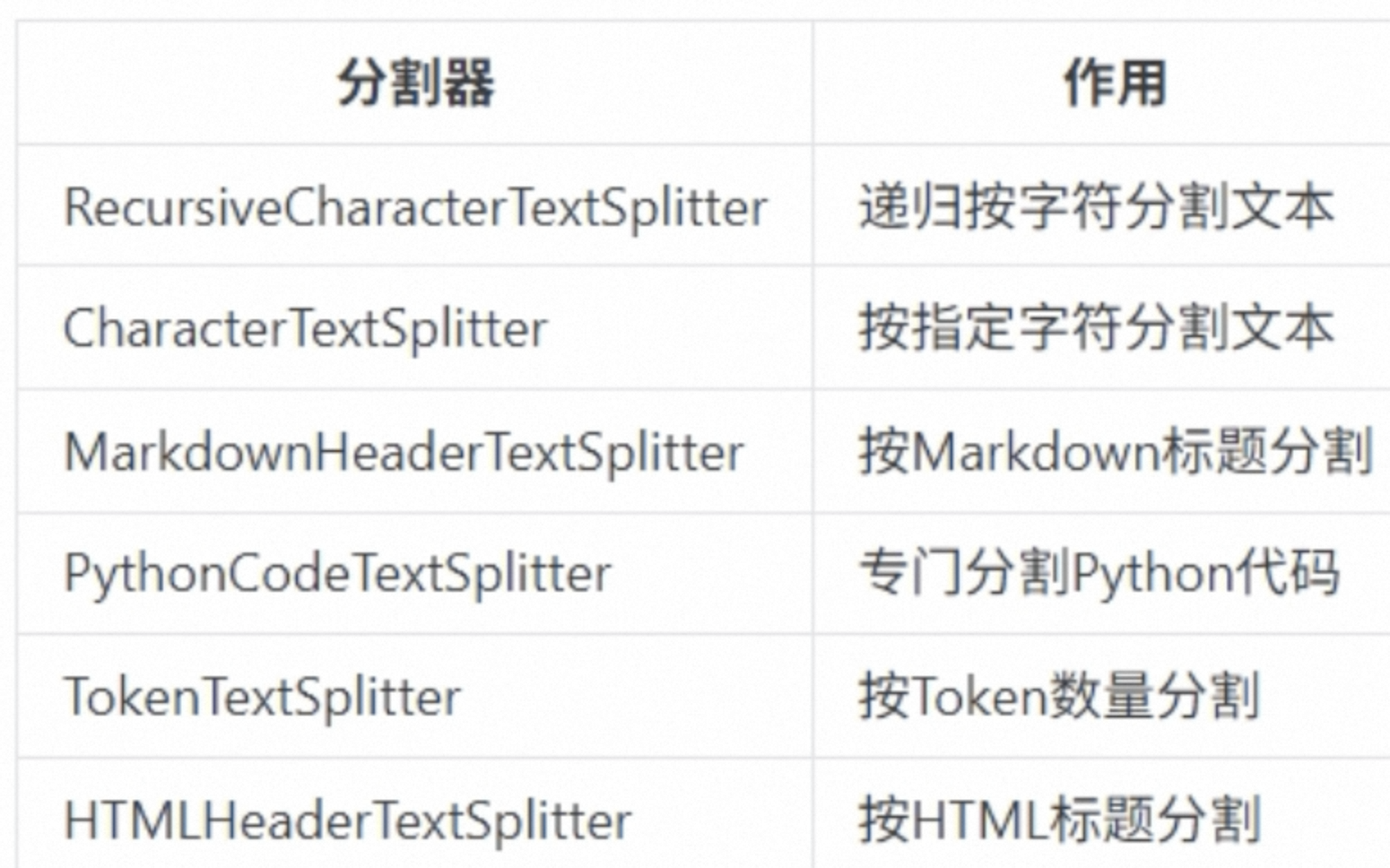
大部分文本分割器都继承了TextSplitter 基类,有一些共同方法
Split_text(): 将文本字符分割成字符串列表
Split_documents(): 将Document对象列表分割成更小文本片段的Document对象列表
Create_documents(): 通过字符串列表创建Document对象
常用的就是RecursiveCharacterTectSpliter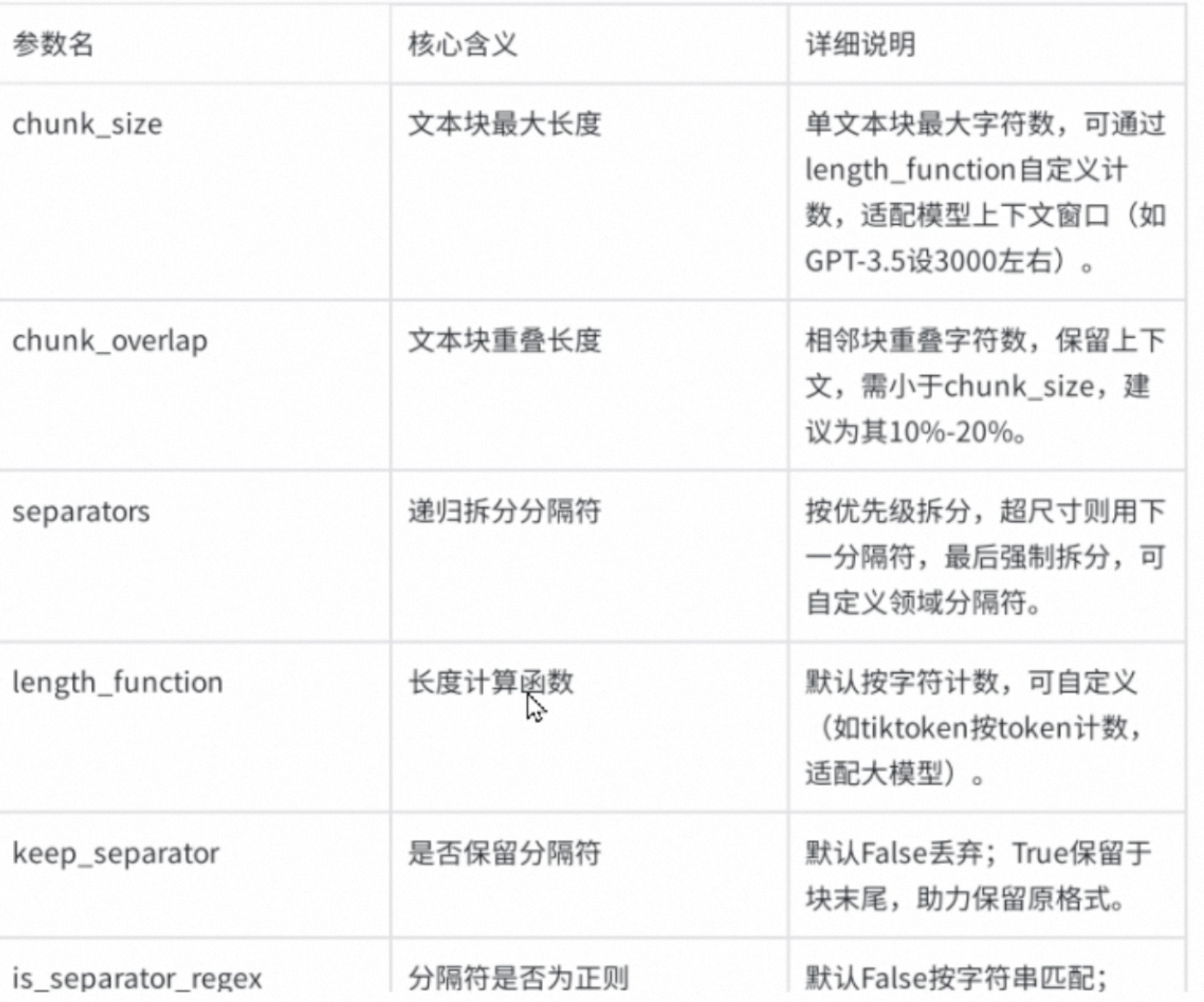
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50, length_function=len);
split_documents = text_splitter.split_documents(documents)
Chunk_overlap建议设置为chunk_size的10%-20%左右,
RecursiveCharacterTextSplitter可以使用split_text分割纯文本,也可以使用split_documents分割documents对象
MCP
MCP是一套标准协议,大模型之间的通信。
AI只需要通过MCP,就可以跟不同的服务进行交流。
类似于Type-c,只要将不同来源的数据,工具,服务统一起来通过MCP协议,就能给各个大模型调用,不管你用什么语言写的。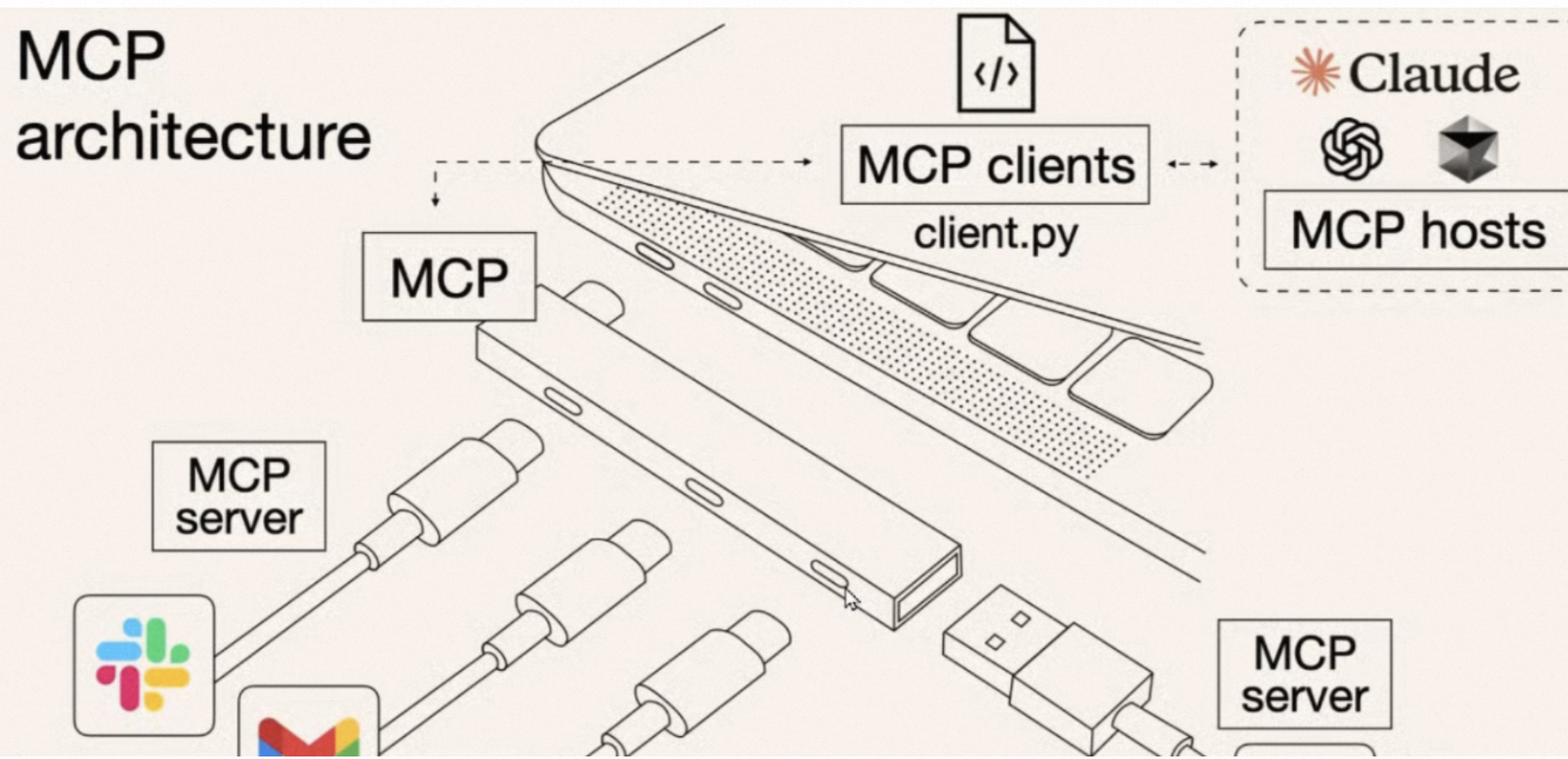
h这个图就很抽象了,MCP就是中间的转换器,很多能力直接通过MCP,成为MCP Server,然后需要使用这些能力的就是MCP Client,他们通过MCP协议,调用MCP Server的能力。
https://mcp.so/zh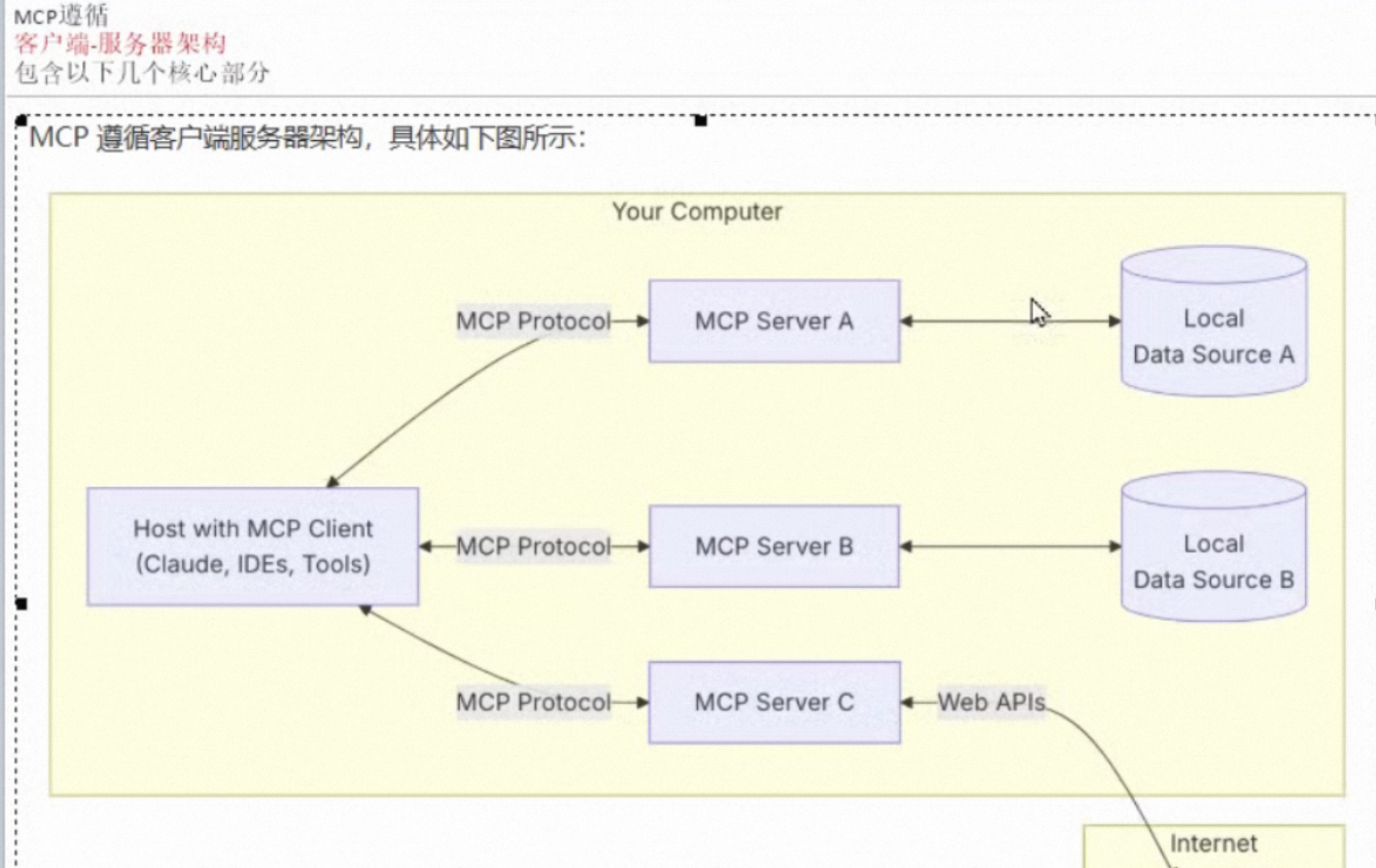
以高德地图的MCP为例子,当我们通过MCP 调用高德的MCP Server后,就会调用高德自己的内部服务去处理数据,在返回。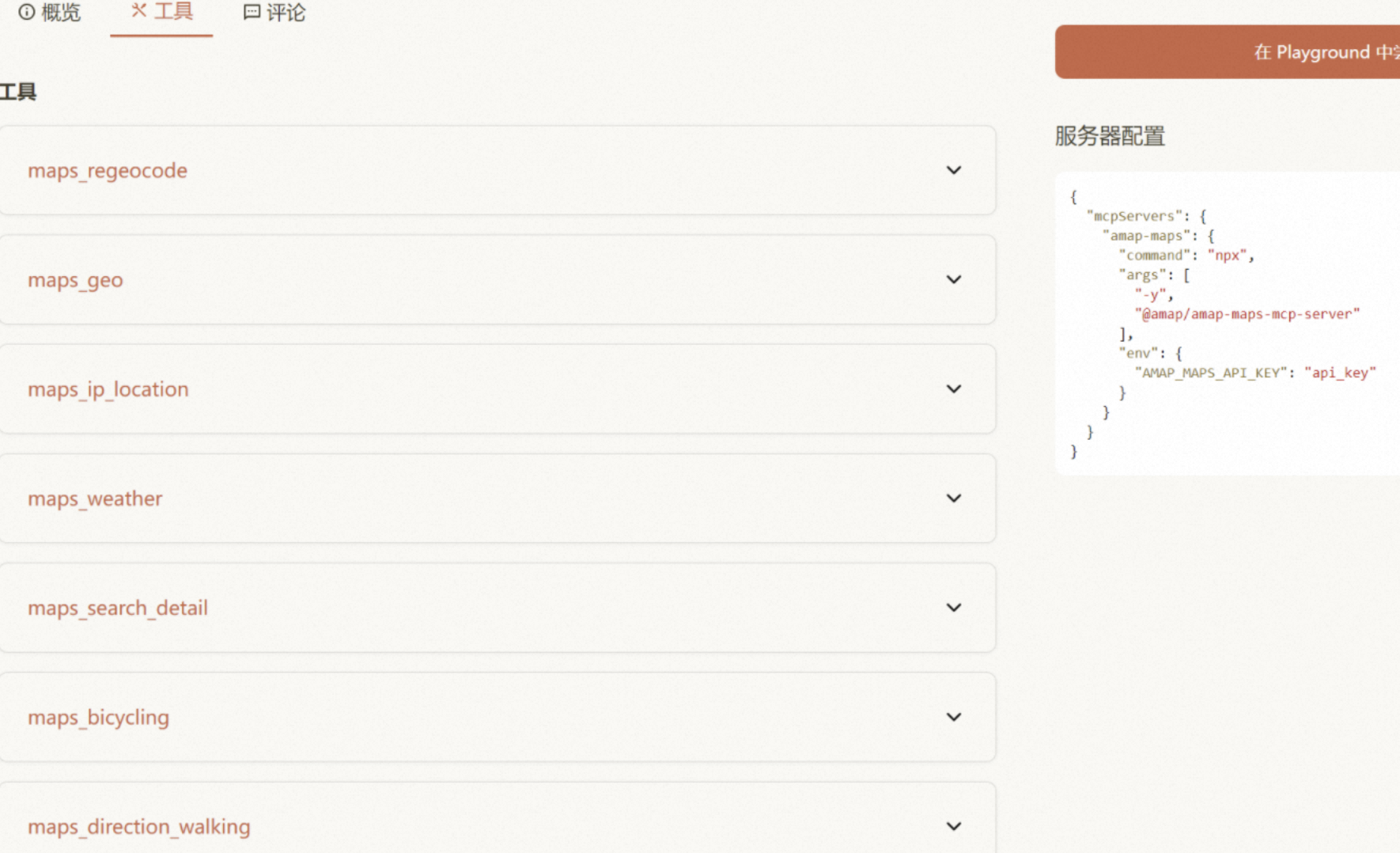
高德的MCP Server提供了一系列的工具调用。
自己封装的tool自己用,单机。通过MCP别人也可以用,联机游戏。
MCP支持两种模式,STDIO(标准输入,输出),支持标准输入和输出流进行通信,主要用于本地集成,命令行工具等场景,SSE(Server-Sent Events)支持使用HTTP Post,请求进行到服务器到客户端流式处理,以实现客户端和服务器端通信。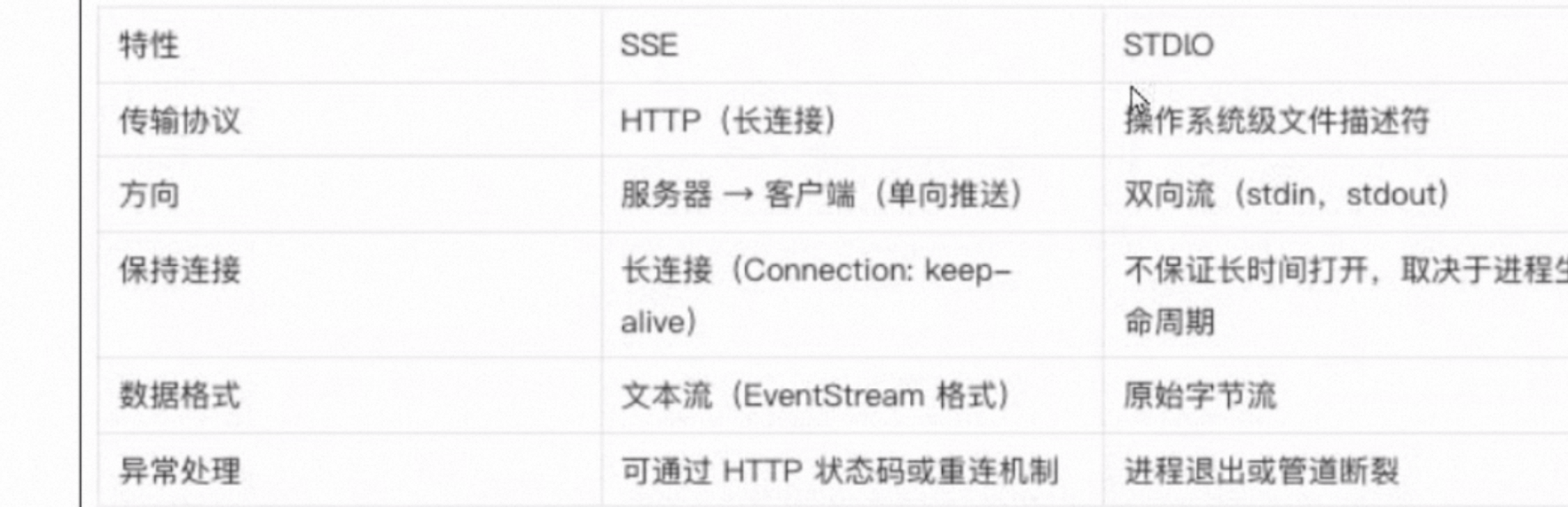
一般都是SSE,单向推送,比如百度提供服务给我们使用,没有百度反过来调用我们,STDIO一般是单机,本地的,命令集成。
demo
构建一个mcp server
from venv import logger
from fastmcp.contrib.mcp_mixin import mcp_tool
from mcp.server.fastmcp import FastMCP
mcp = FastMCP(name="weatherServerSSE", host="0.0.0.0", port=8000)
@mcp_tool()
def get_weather(city: str)->str:
return f"{city}的天气今天晴朗,多云"
if __name__ == "__main__":
logger.info("启动MCP SSE天气服务,监听在8000/sse")
mcp.run(transport="sse")
这样我们就启动过了一个mcp服务,通过mcp_tool包装,提供了一个weather工具。
mcp.json
{
"mcpServers": {
"weatcher": {
"url": "http://localhost:8000/sse",
"transport": "sse"
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"],
"transport": "stdio"
}
}
}
配置了一个weather,以及一个fetch工具,他由mcp-server-fetch提供,用于搜索网页内容,uvx相当于npx,这个是langchain自带的
使用:
mcp.client
def load_servers(file_path: str = "mcp.json") -> Dict[str, Any]:
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
return data.get("mcpServers", {})
async def test_mcp_client():
server_cfg = load_servers()
mcp_client = MultiServerMCPClient(server_cfg)
print(server_cfg)
tools = await mcp_client.get_tools();
print(f"tools: {[t.name for t in tools]}")
llm = init_llm_client();
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有用的工具,请在需要的时候调用工具"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# 0.3版本通用写法
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors="解析用户请求失败,请重新输入清晰的指令"
)
print(await agent_executor.ainvoke({"input": "纽约今天天气如何"}))
if __name__ == "__main__":
asyncio.run(test_mcp_client())
通过MultiServerMCPClient得到server提供的工具,给大模型
执行结果:
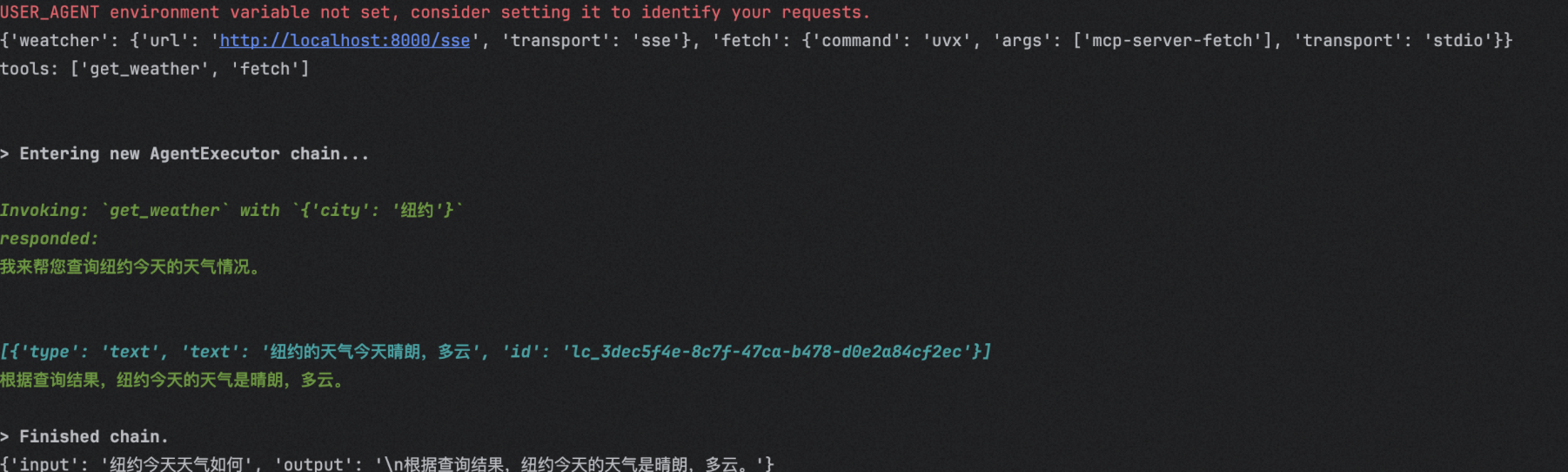
Agent
Agent = LLM + Memory + Tools + PLanging + Action
ReACt模式,reason + act (思考 + 行动)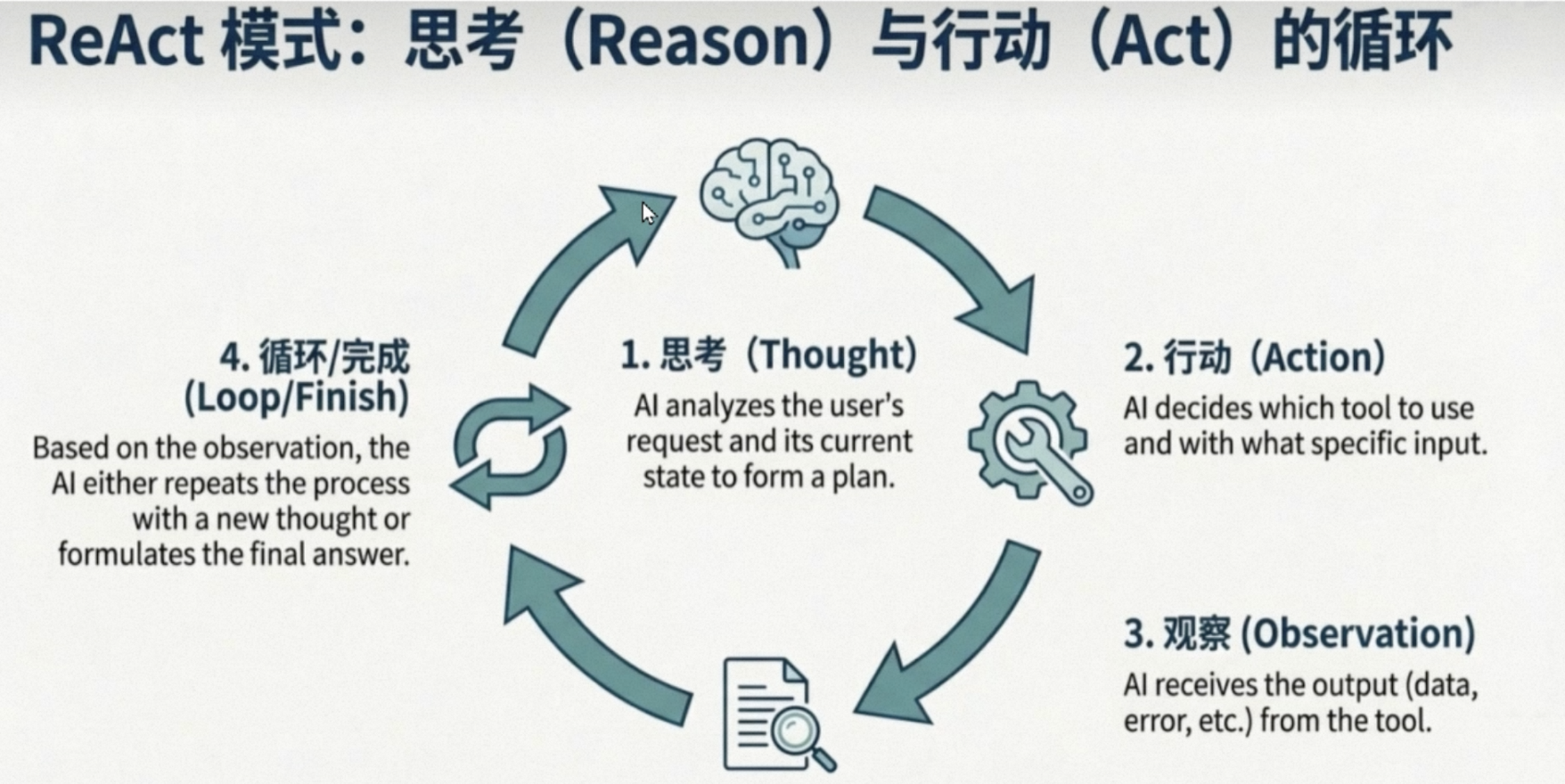
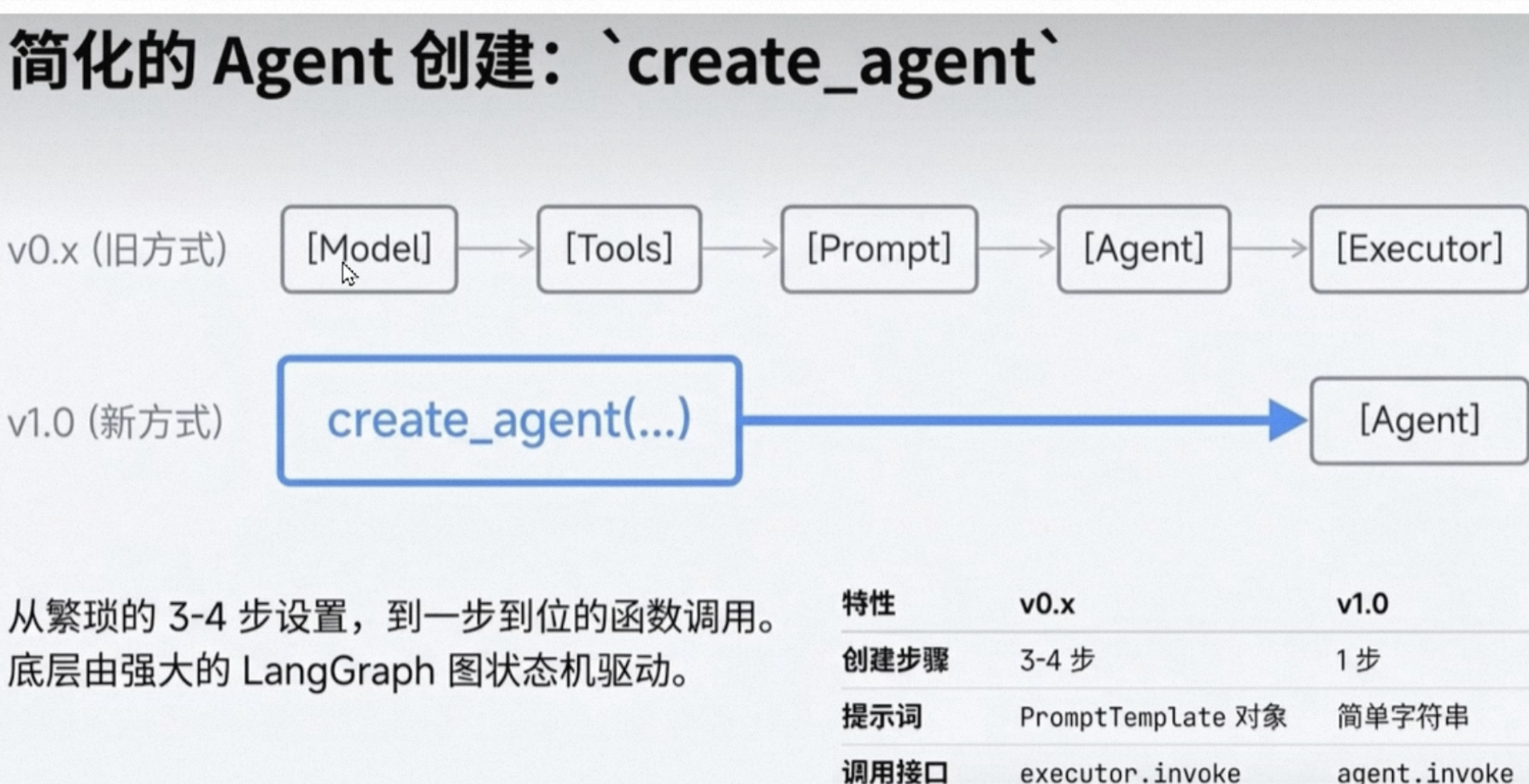
版本迭代,1.0的时候,创建agent只需要调用一个函数了。0.3多了一个Executor执行期,Agent只需要决策,真正执行是通过Executor。
1.0之后
ReAct demo
@tool()
def get_weather1(v1: str):
"""获取天气的工具"""
return f"${v1}的天气是38度,稍微热"
@tool()
def get_today():
"""获取今天的日期"""
return datetime.today().strftime("%Y-%m-%d")
from langchain.agents import create_agent
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
def print_agent_steps(result: dict):
messages = result.get("messages", [])
print(f"\n{'='*50} Agent 执行步骤 {'='*50}")
for i, msg in enumerate(messages):
if isinstance(msg, HumanMessage):
print(f"\n[步骤 {i+1}] 用户输入")
print(f" {msg.content}")
elif isinstance(msg, AIMessage):
if msg.tool_calls:
print(f"\n[步骤 {i+1}] AI 决策 → 调用工具")
for tc in msg.tool_calls:
print(f" 工具名: {tc['name']}")
print(f" 参数: {tc['args']}")
else:
print(f"\n[步骤 {i+1}] AI 最终回答")
print(f" {msg.content}")
elif isinstance(msg, ToolMessage):
print(f"\n[步骤 {i+1}] 工具返回结果")
print(f" 工具名: {msg.name}")
print(f" 结果: {msg.content}")
print(f"\n{'='*115}\n")
def agent01():
llm1 = init_llm_client();
tools = [get_weather1, get_today]
agent1 = create_agent(tools=tools, model=llm1, system_prompt="""你是一个优秀的个人数助手,根据ReAct的模式完成用户的需求
1.先推理用户需求
2.选择合适的工具执行操作
3.基于工具结果进行下一次推理
4.重复直到完成整体任务
你必须保持推理步骤尽量简单
""")
result = agent1.invoke({"messages": [{"role": "user", "content": "今天是多少号,北京今天的天气如何"}]})
print_agent_steps(result)
print(result)
if __name__ == "__main__":
# asyncio.run(test_mcp_client())
agent01()
返回的result包含所有的内容,打印结果
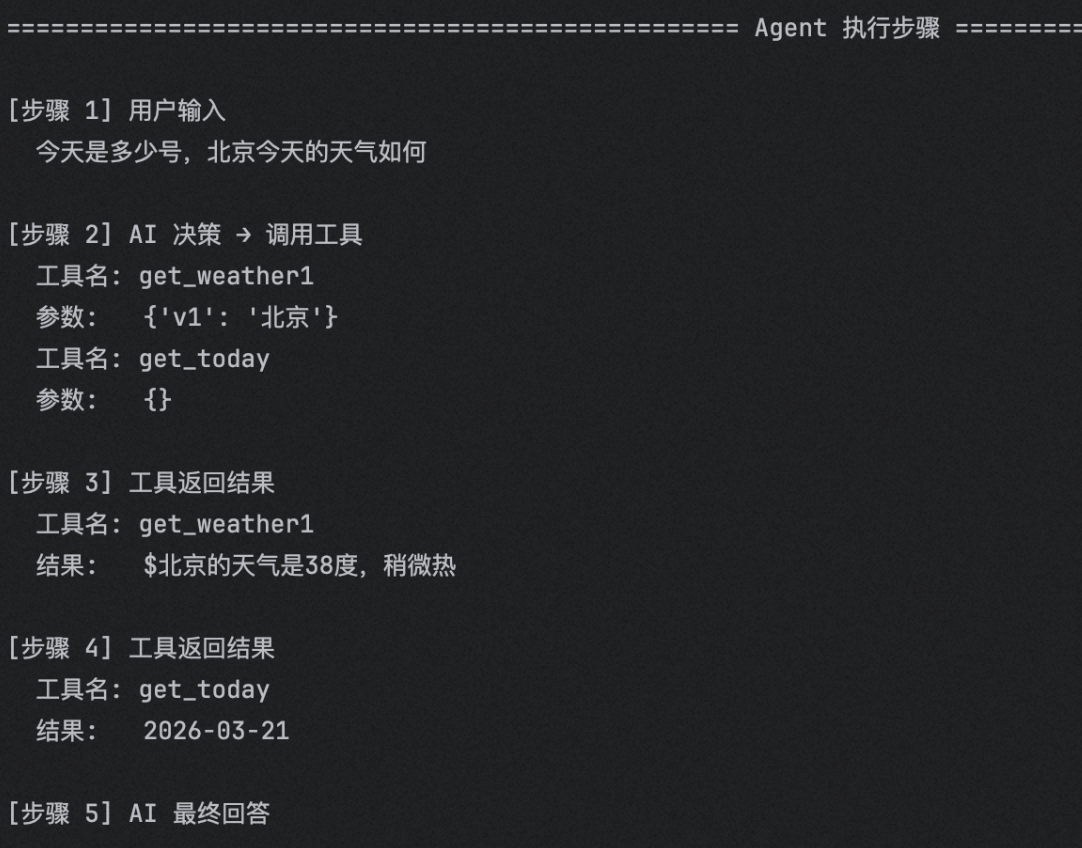
如图,会自主决策调用工具。
A2A
Agent to Agent(智能体调用智能体)
模拟用户 从北京飞上海,在浦东机场附近订酒店,从机场打车到酒店的 需求
核心设计思路:
- 拆分专属Agent,按业务领域拆分机票Agent,酒店Agent,打车Agent,每个Agent仅负责自身领域的任务,保证专业性。
- 主协调Agent:新增出行总协调Agent,作为入口接收用户需求,调度各专属Agent,整合协作效果,反馈最终结论。
- 简单说: A2A调度 = 多个功能单一的Runnable 子Agent链 + 一个控制调用逻辑的总协调器。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)