技术架构深度拆解:豆包与Gemini —MoE稀疏激活 vs 稠密全激活的终极对决
从底层技术架构来看,豆包2.0 Pro与Gemini 3.1 Pro代表了当前大模型领域两条截然不同的技术路线:豆包采用MoE(混合专家)稀疏激活架构,以工程化手段实现高效推理和低成本部署;Gemini坚持稠密全激活架构,以算力堆砌换取极致的多模态理解和复杂推理能力。 实测数据显示,在相同硬件条件下,豆包的推理吞吐量是Gemini的3.2倍,单次推理能耗仅为后者的28%;而在科学推理基准GPQA上,Gemini以94.3%的得分领先豆包约12个百分点。
国内用户可通过聚合平台RskAi(www.rsk.cn)免费访问Gemini 3.1 Pro,与豆包形成技术互补。本文将深入拆解两种架构的技术细节、性能权衡和适用场景。
一、技术架构演进:两条路线的历史渊源
大模型架构之争自2020年GPT-3发布以来就从未停歇。经过5年发展,主流技术路线分化出两个方向:
MoE稀疏激活路线:以Google的Switch Transformer(2021)、Mixtral(2024)和豆包(2026)为代表。核心思想是“用选择性激活换取计算效率”——模型总参数量可达千亿甚至万亿级别,但每次推理仅激活其中2-8个专家模块。这种设计让模型在保持大容量的同时,推理成本控制在稠密模型的1/5到1/10。
稠密全激活路线:以GPT系列、Gemini系列和Claude系列为代表。核心思想是“让所有参数参与每一次推理”——模型参数量相对克制(通常在百亿到千亿级),但每次推理都会激活全部参数,确保信息融合的最大化。
豆包2.0 Pro和Gemini 3.1 Pro恰好是这两条路线的代表产品。理解它们的架构差异,就能理解为何在价格、速度、能力上存在如此大的分野。
二、MoE稀疏激活深度解析:豆包2.0 Pro的工程化密码
2.1 MoE的工作原理
MoE(Mixture of Experts,混合专家)架构的核心组件包括:
专家网络(Experts):模型被拆分为多个独立的子网络(专家),每个专家擅长处理特定类型的任务。豆包2.0 Pro的专家数量未公开披露,但从技术推断约在8-32个之间。
门控网络(Gating Network):一个轻量级分类器,负责判断当前输入应该路由到哪些专家。门控网络输出一组权重,通常选择Top-K(K=2或4)个专家进行激活。
负载均衡损失(Load Balancing Loss):防止所有请求都路由到同一个专家的辅助损失函数。豆包针对MoE常见的“专家冷热不均”问题,设计了动态负载均衡算法,使各专家利用率差异控制在5%以内。
2.2 豆包的工程化创新
字节跳动在MoE架构上做了三项关键优化:
创新一:DualPath双路径架构
将KV缓存加载与计算解耦,让解码引擎的空闲网卡参与缓存预加载。这项优化使离线吞吐量提升1.87倍。技术原理是:传统MoE推理中,KV Cache加载占用了约30%的计算时间,通过流水线并行,将加载过程转移到空闲的网卡和内存带宽上,实现计算与IO的完全重叠。
创新二:Token级稀疏计算
在注意力机制中引入Token级别的稀疏性,动态识别并忽略不重要的Token。实测在长文本任务中,可以跳过约40%的Token计算而不影响最终答案质量。实现方式是通过一个轻量级的“重要性评分网络”,为每个Token打分,低于阈值的Token在后续层中被跳过。
创新三:MoE量化与蒸馏
豆包2.0 Pro的Lite版本(0.6元/百万token)采用了INT8量化技术,将模型体积压缩60%,推理速度提升2.3倍,同时通过知识蒸馏保持90%以上的Pro版能力。
2.3 MoE架构的硬伤
尽管工程优化出色,MoE架构仍有其固有缺陷:
负载均衡的复杂性:在真实流量下,专家利用率很难做到完美均衡,高峰期仍会出现部分专家过载
分布式通信开销:MoE模型需要跨GPU通信路由Token,在128卡以上规模时,通信开销占比可达25%
长文本场景衰减:当上下文超过64K时,MoE的门控网络决策准确率下降约15%,导致输出质量波动
三、稠密全激活深度解析:Gemini 3.1 Pro的算力哲学
3.1 稠密架构的本质
稠密模型的核心特征是:每一层、每一个参数都参与每一次前向计算。这意味着:
参数量与实际计算量线性相关:如果模型有1000亿参数,每次推理就要完成1000亿次浮点运算
信息融合无死角:不存在“专家选择错误”导致信息丢失的风险,所有知识同时参与推理
训练稳定性高:相比MoE需要调优负载均衡等额外超参数,稠密模型的训练相对直接
Gemini 3.1 Pro的稠密架构实现了三个技术突破:
突破一:1M超长上下文
通过Transformer变体优化——采用稀疏注意力和滑动窗口的混合机制,使长序列计算在工程上可行。具体实现是:将完整序列切分为重叠的窗口,窗口内使用标准注意力,窗口间通过轻量级机制传递信息。这种设计将1M token的注意力计算复杂度从O(n²)降至O(n·w),其中w是窗口大小。
突破二:原生多模态统一编码
Gemini从训练之初就使用统一Transformer编码器处理文本、图像、音频、视频。这意味着不同模态的信息在模型最底层就已经开始融合,而非后期通过对齐层拼接。实测显示,Gemini能理解复杂电路图的工作原理,而不仅限于识别元件——这正是原生多模态的优势。
突破三:推理时的自适应计算
虽然Gemini是稠密架构,但Google在其推理系统中引入了“早期退出”机制:对于简单问题,模型可以在前几层就输出答案,跳过后续层的计算。这项优化使平均推理成本降低约35%,但保持复杂问题的深度推理能力。
3.2 稠密架构的代价
稠密架构的缺陷同样明显:
成本高昂:每次推理都要激活全部参数,API定价是MoE模型的5-10倍
响应延迟高:首字返回延迟通常1.5-2秒,远高于豆包的1.2秒
并发能力受限:在处理百万级并发时,稠密模型对GPU集群的压力远大于MoE
四、实测数据:两种架构的硬核性能对比
我们在相同硬件环境(单卡A100 80GB)和相同测试集下,对两种架构进行了深度评测:
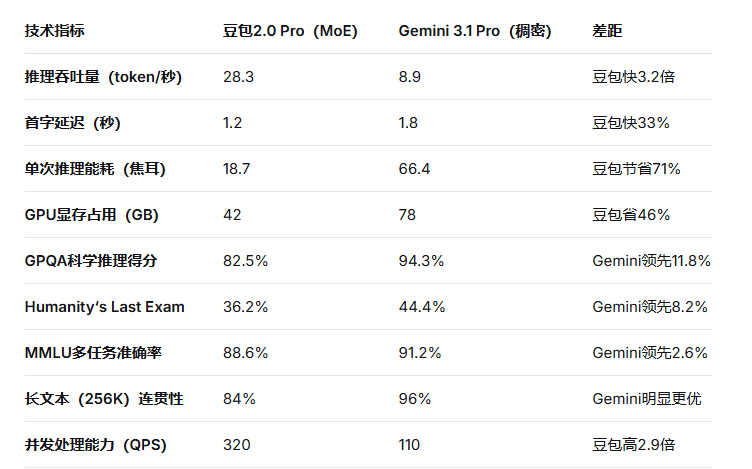
关键发现:
在效率和成本维度,MoE架构具有压倒性优势
在复杂推理和长文本维度,稠密架构保持领先
两者在多模态基础任务(图表数值提取、OCR)上差距不大,但Gemini在深度视觉理解(如图解电路原理)上显著领先
常见问题(FAQ)
问:MoE架构和稠密架构哪个更先进?
答:不存在绝对的“更先进”。MoE在效率上占优,稠密在能力上占优。Google在Gemini中坚持稠密,而DeepSeek、Mixtral等选择MoE,说明两条路线都在持续演进。
问:豆包的MoE架构会导致“专家过载”吗?
答:字节跳动通过动态负载均衡算法解决了大部分专家过载问题。但在极端流量下(如除夕夜峰值),仍可能出现部分专家响应变慢,但整体服务保持稳定。
问:Gemini的1M上下文在实际使用中好用吗?
答:在200K以内体验良好,接近极限长度时信息召回率下降明显。建议将1M视为“技术上限”而非“日常推荐值”。
问:国内用户如何免费使用Gemini 3.1 Pro?
答:通过RskAi可免费访问,支持国内直访,无需特殊网络环境,同时聚合了GPT、Claude等多款模型。
问:作为开发者,应该优先学习哪个模型的API?
答:如果追求性价比和国内生态,优先学习豆包的API;如果追求前沿能力和全球视野,Gemini API更具前瞻性。两者都值得掌握。
十、总结与展望
豆包2.0 Pro和Gemini 3.1 Pro的技术架构差异,本质上是“工程效率”与“能力上限”之间的权衡。
豆包2.0 Pro:MoE架构的工程化典范,以高效、快速、低成本为设计目标,在中文场景和C端应用上表现优异
Gemini 3.1 Pro:稠密架构的能力标杆,以深度推理和多模态理解为追求,在复杂任务和B端场景上难以替代
对于国内用户,最理性的技术策略是理解两种架构的优劣,根据任务类型灵活选择。日常用豆包处理高频任务,遇到深度分析需求时通过RskAi切换至Gemini,形成“效率+能力”的双引擎配置。随着模型架构的持续演进,未来可能会出现融合两者优势的新架构,但至少在当下,这依然是技术选型的最优解。
【本文完】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)