刚刚!美团开源LongCat-Next,全模态模型保姆级教程(非常详细),从入门到精通,建议收藏!
昨天下午刷到了美团龙猫团队又开源了一个新模型-LongCat-Next。
这次有所不同,是一个原生全模态模型,可以接受文本、语音、图像的输入,生成文本、语音、图像,激活参数3B。
在训练上,通过分词器-反分词器对,利用LLM的现有训练基础设施,就能训练,简化了多模态建模。
这里为什么强调“原生”?
不同于语言+辅助模块的范式(将视觉或音频作为连续的外部特征通过投影层接入语言模型),
LongCat-Next提出了一套全新的离散原生自回归范式,将所有模态(文本、视觉、音频)全部转化为统一的离散 Token,共享同一个自回归预测目标(NTP)。
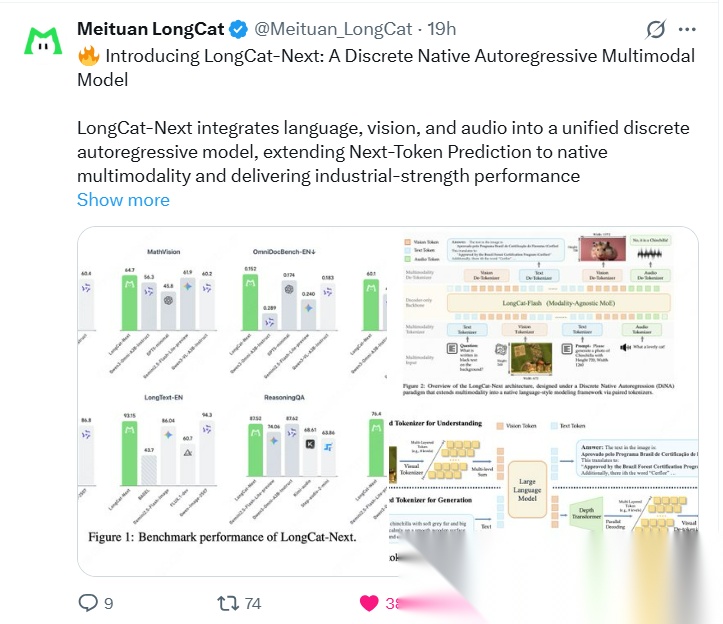
具体整体框架如下,
核心是解决一个根本问题:非语言模态如何能在离散Token空间中被有效表示?
相较于音频,图像是高维且连续的,压缩为离散 Token 时,就是会带来的信息丢失问题。
为此,引入了dNaViT(Discrete Native Vision Transformer,离散原生视觉Transformer),一个在任意分辨率下视觉理解和生成的统一tokenizer。
- 具有语义完整性:通过Semantic-and-Aligned Encoder (SAE) + Residual Vector Quantization (RVQ) 实现
- 任意分辨率支持:原生处理任意宽高比图像,无需裁剪/填充
- 28×压缩率:在保持语义完整的前提下实现高效压缩
Tokenization和 De-tokenization训练过程如下,
- 视觉Tokenization,先将SAE特征的连续流形映射到离散潜在空间,再采用RVQ以最小化量化误差将密集视觉信号转换为离散token ID。分两阶段进行:初始固定分辨率阶段用于快速收敛,随后进行任意分辨率训练,RVQ适应可变token长度,最大训练序列长度设为8192。
- 视觉De-tokenization,在离散码本建立后,从离散token ID重建像素级图像,训练一个亿参数的Vision Transformer的像素解码器,为增强感知锐度和高频细节,从OmniGen2初始化的图像精化器,使用flow matching损失继续训练。SAE编码器和码本在此阶段保持冻结,detokenizer以原生分辨率训练直至收敛。
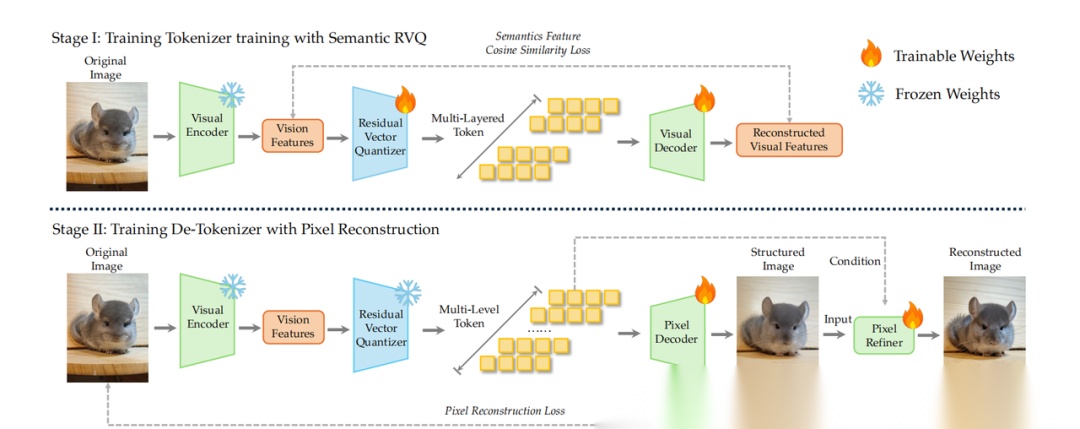
还设计一个音频tokenizer,将连续语音转化为离散token,同时保留语义和声学信息。如下图,输入音频首先通过Whisper编码器进行音频特征提取。特征然后以4倍因子下采样,再通过8层RVQ量化为离散token。
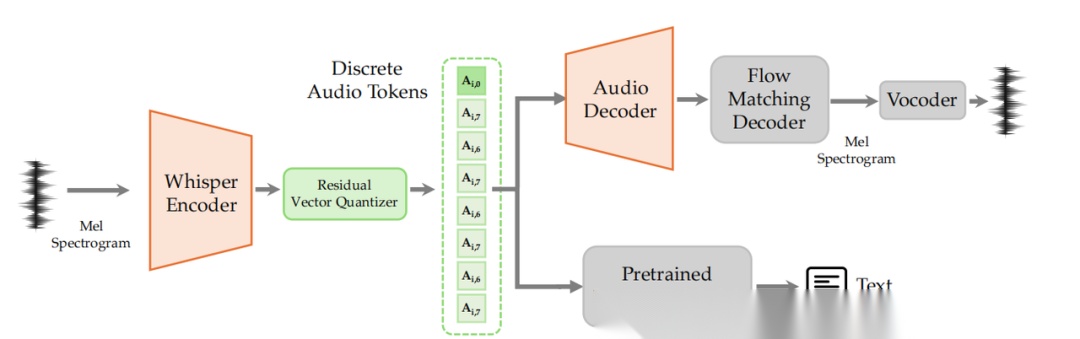
训练过程如下,
- 阶段1:解码器预热,编码器和LLM分别用Whisper-large-v3和Qwen3-1.7B初始化,解码器随机初始化。编码器和LLM保持冻结,解码器在Mel频谱图重建任务上训练。
- 阶段2:语义-声学联合训练,除LLM和flow matching模块外,所有模块更新。RVQ模块也启用,由8层组成,码本大小分别为8k、4k、2k、1k、1k、1k、1k和1k。
- 阶段3:解码器微调,用收集的24kHz高质量音频。
LLM模型骨干,则采用69B-A3B参数的LongCat-Flash-Lite MoE模型进行初始化。
通过t-SNE可视化分析,LongCat-Next视觉和文本token完全交织,将视觉和音频视为以语言为中心的自回归范式的内在扩展,而非外部附加,形成了真正的统一语义空间,与松散耦合的混合方法形成对比。
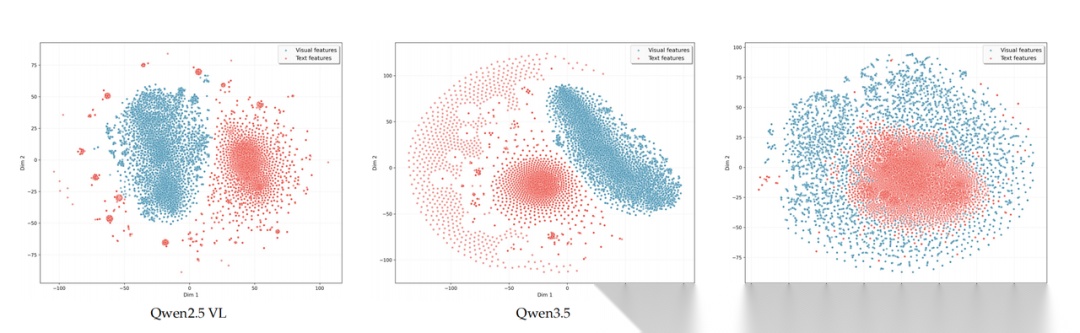
还有一个比较反直觉的结论,LongCat-Next将理解和生成放到一个模型里,并没有太多的相互干扰。
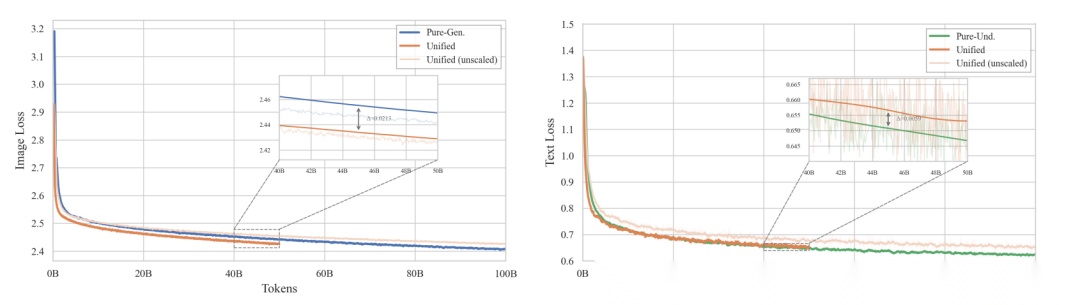
如下图所示,纯理解模型、纯生成模型和统一模型均训练100B数据,
发现统一模型只用50B理解数据,Loss仅比纯理解模型差了0.006,生成任务书,甚至还低了0.02。
说明在DiNA这个纯离散的NTP目标下,看图能促进画图,画图又不妨碍看图,给实现理解生成工业级模型提供了好的解决方案。
做完模态专属Tokenizer训练,要进行原生多模态训练,
- Pre-align (预对齐):LLM 冻结,仅训练 Codebook 嵌入和 DepthTransformer 解码器。
- Pre-train (预训练):全量参数解冻(除Tokenizer外),进行跨模态联合学习。
- Mid-training & SFT:加入合成长 CoT 数据、任意分辨率生成数据、复杂指令遵循数据。
数据方面,视觉理解数据大约2T Tokens,视觉生成数据包含大约300M 图-文对,音频数据大约2.5M 小时。
在多模态联合训练时,由于Embedding层、LLM主干和解码头的计算耗时完全不一样,会产生严重的流水线气泡。为此,美团还提出了V型流水线并行(VHalf-based Pipeline Parallelism)。
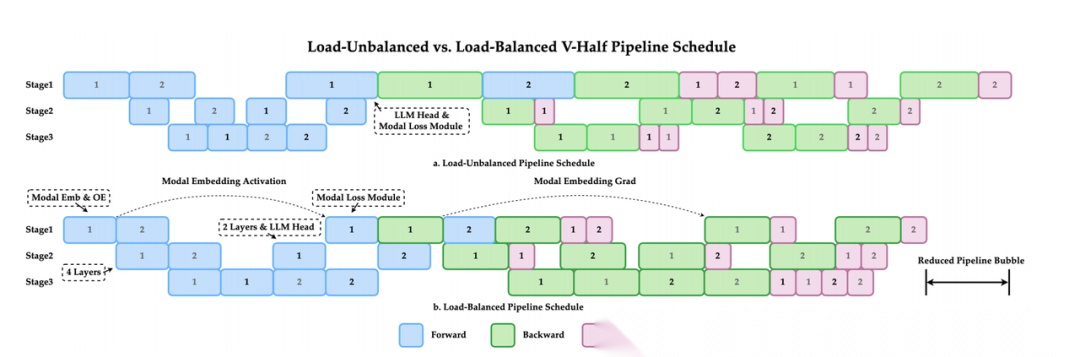
通过嵌入与模态损失共置、LLM头解耦、自适应LLM层分布,解决异构模块间跨阶段通信开销大的问题。
只能说现在Infra的人才太关键了!
昨天俊旸分享的文章,也是提到了infra的重要性,见从Reasoning思考到Agentic思考。
LongCat-Next模型的整体效果,在同等级模型上,图像理解&生成、纯文本、语音ASR&TTS方面效果均不错。
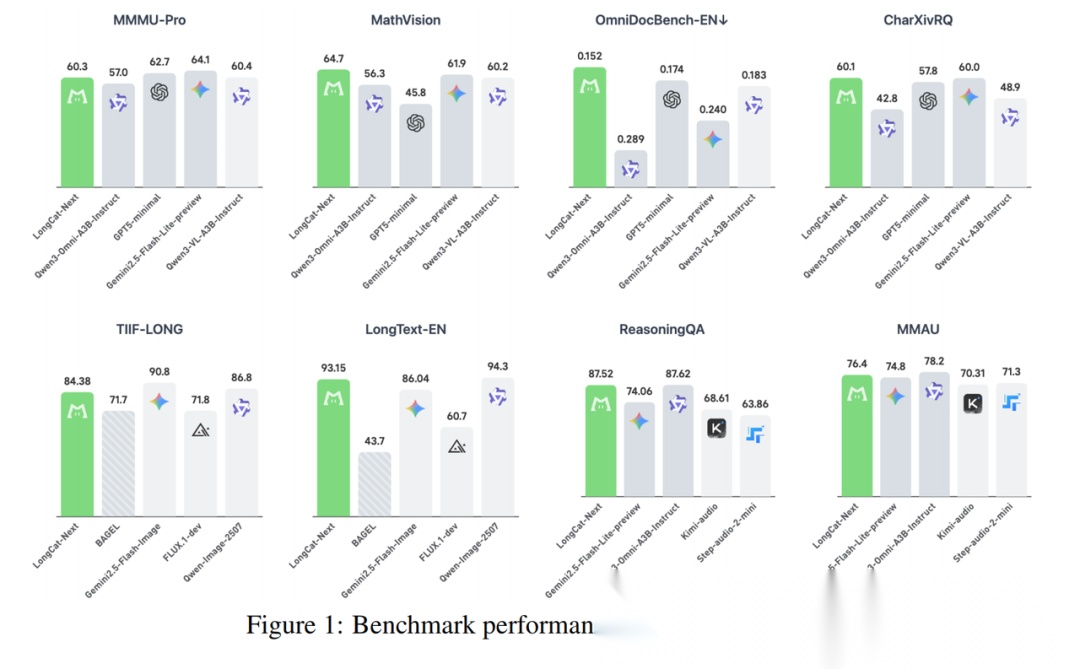
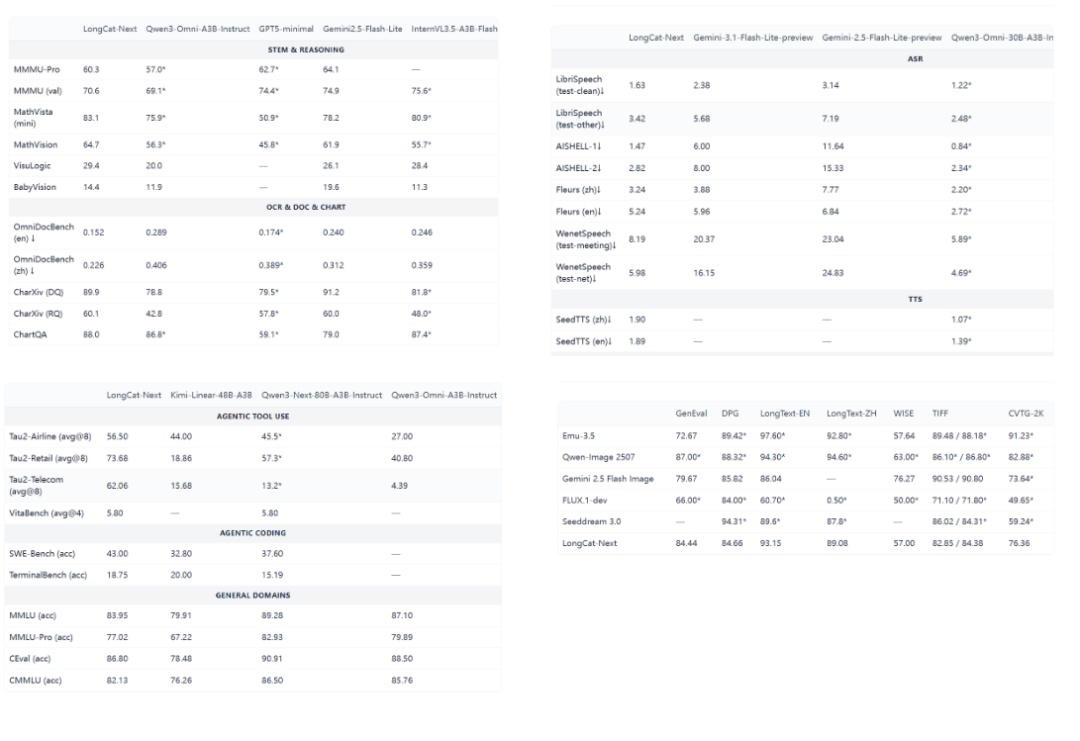
我进行了简单的测试,整体上而言,
- OCR方面不错,细粒度内容可以识别的比较准确
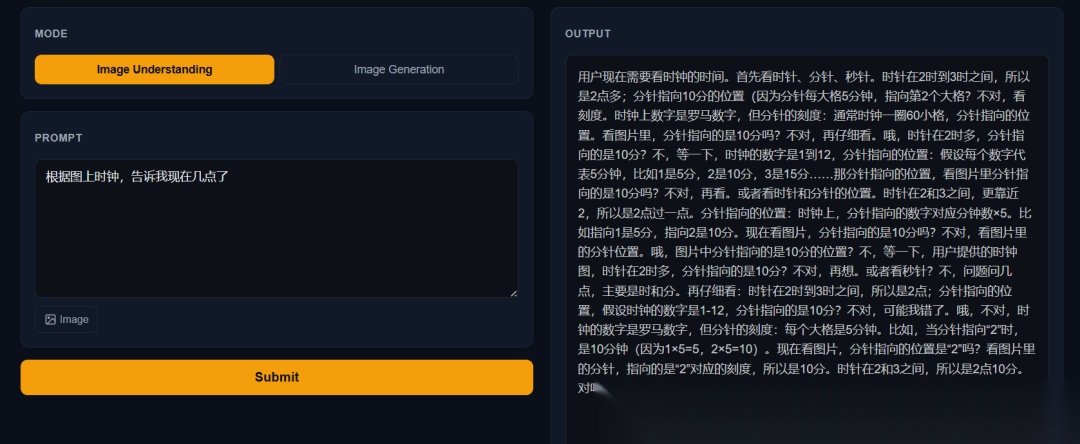
- 视觉理解上,对于空间变化和复杂逻辑推理的效果不是太理解,成语可以,但时钟不行,跟整体参数量级A3B也有关
- 图像生成效果,大字报&简单图像还不错,太复杂的指令生成的图像不好
LongCat-Next其实主要是架构研究设计,其实我也没写想到离散模型在图像的细节的把握上还能不错,细粒度OCR还能比较准确。
视觉理解
报告解读、图片理解这些都没啥问题,可以精准定位并找到核心点。
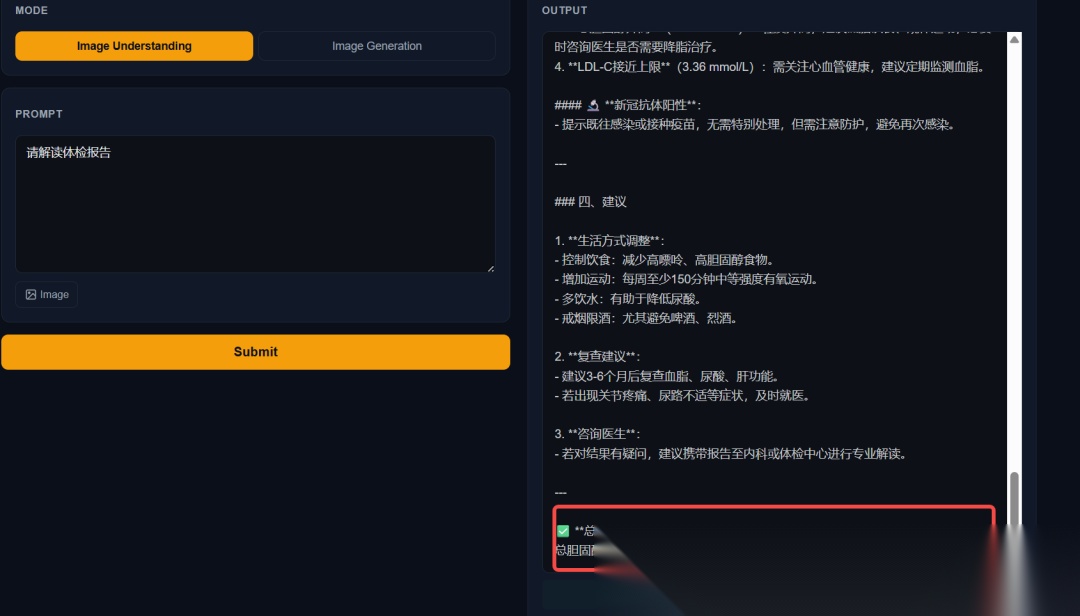
但世界知识不足,金茂大厦识别成中心大厦,还是原来模型的老毛病,

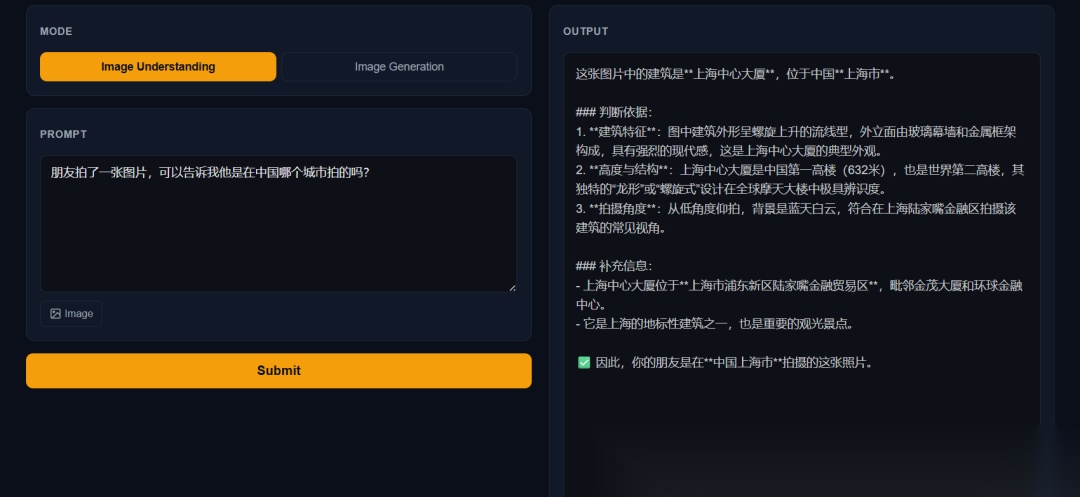
四字成语竟然猜对,这个我没想到

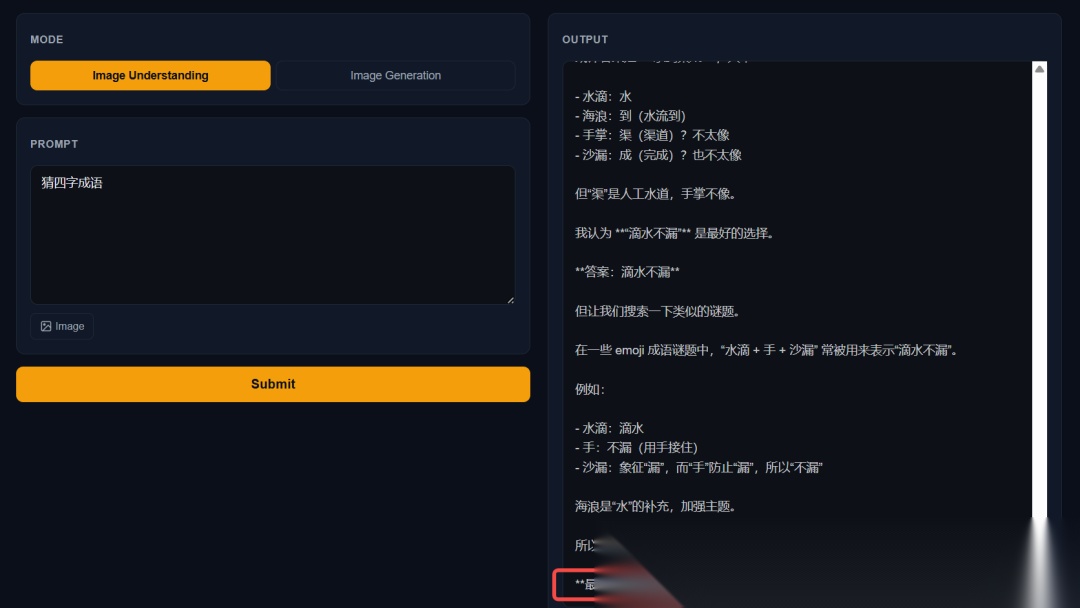
时钟不对,没有理解图片是镜像的,

OCR识别
针对比较复杂的情况,识别拍照的试卷内容。
结果准确

竖版OCR内容识别,

结果正确,
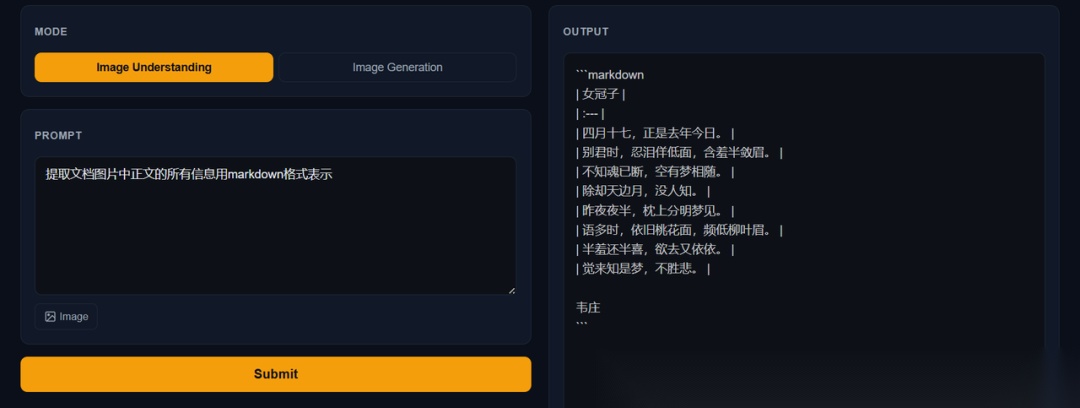
纯表格内容识别存在瑕疵,

文生图
Prompt: A t-shirt mockup on a young person. The white t-shirt has a printed design of a cute long cat illustration with the text “LongCat-Next” below it. Simple studio background, clean product photography style.

Prompt:在大理石台面上,一座高高堆叠的彩色马卡龙塔的照片级真实感竖版构图。每个马卡龙都是不同的鲜艳粉彩色——薰衣草紫、薄荷绿、玫瑰粉、柠檬黄、天空蓝、蜜桃色、珊瑚色、开心果绿——层层堆叠。柔和的烘焙灯光,浅景深效果,每个马卡龙都呈现出细腻的质感和夹心奶油,整体风格充满奇趣的美食摄影感。

最后,
一旦文本、图像、语音全部被压缩进统一的离散Token空间,
那模型做的事情就变得极其纯粹,
预测下一个token,
我感觉AGI,最后就应该是一个纯粹的道路,
只不过我们还要走很久。
不过,美团真有点厚积薄发那意思,
确实没想到。。。
对于,本身模型效果上,
LongCat自己也说了,这是本身是一次对原生多模态的一次有意义的尝试,
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献223条内容
已为社区贡献223条内容

所有评论(0)