(OpenGL渲染与几何内核那点事-项目实践理论补充(一-1-(1):从开发的视角看下CAD画出那些好看的图形们))
OpenGL渲染与几何内核那点事-项目实践理论补充(一-1-(1):从开发的视角看下CAD画出那些好看的图形们
代码仓库入口:
系列文章规划:
巨人的肩膀:
- deepseek
我们生活中见过很多“很专业也很好看”的图
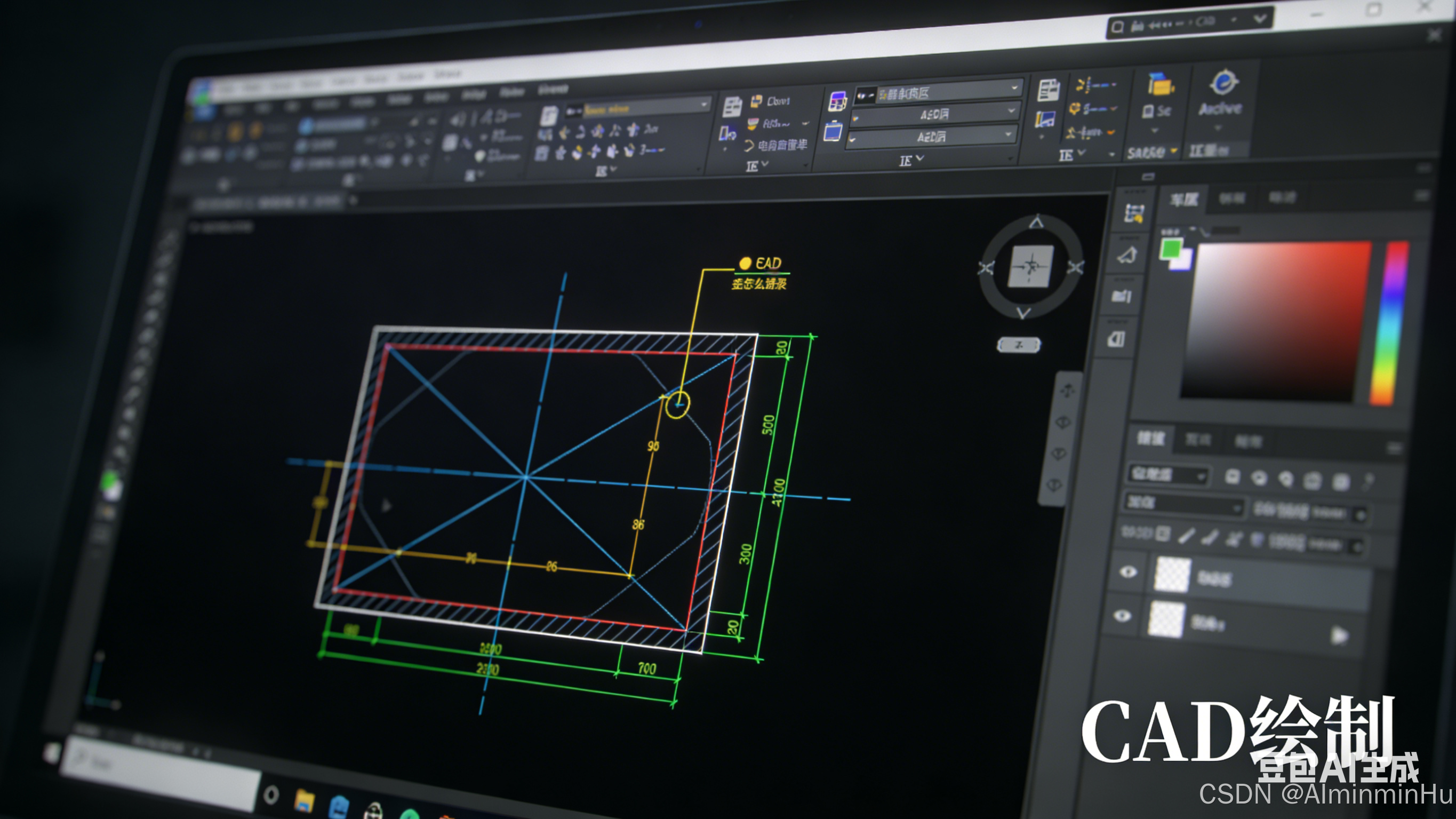
假设我们现在看到的是一张机械装配图,里面有一个复杂的齿轮箱:
- 外壳(粗实线,带剖面线)
- 内部齿轮(细实线,齿形需要精确)
- 尺寸标注(带箭头、文字)
- 标题栏(表格、公司名称、比例)
- 还有几个局部放大图
这张图用铅笔和尺规画在 A0 图纸上要花几天,但现在我们想用电脑来画。
如果你是最早的 CAD 开发者,你会怎么做?
电脑只有 64KB 内存,硬盘还没普及,屏幕还是单色的。
你不能像今天那样随便 new 几万个对象。
你得设计一个极其紧凑的数据结构,还要让用户能轻松修改。
初步思路:用 C++ 的“类”来表示图形元素
你定义一个基类 Entity,派生出 Line、Circle、Arc、Text 等等。
每个实体记录自己的几何参数(起点、终点、圆心、半径、文字内容)和一些样式(颜色、线型)。
你写了一个 Draw() 函数,遍历所有实体,一个个画到屏幕上。
这看起来很不错——至少能画图了。
但是很快,你就遇到了麻烦。
问题一:我想同时控制一整批线
比如,我想把所有剖面线都改成红色,或者把所有尺寸标注都隐藏。
如果按现在的设计,我得遍历全部实体,判断它是不是剖面线的一部分,再改颜色。
这在只有几十个实体时还行,但图纸一复杂(上千个实体),速度慢得无法忍受,而且用户操作极其繁琐。
你灵机一动: 给每个实体加一个“分组标签”不就行了?
这个标签就是一个字符串,比如 "HATCH"、"DIM"、"OUTLINE"。
修改时,我只需要把属于这个标签的所有实体找出来,一次性修改它们的属性。
而且,我还可以给这个标签增加“全局开关”——比如隐藏整个标签组,所有实体瞬间消失。
这个“标签”,就是 层 (Layer)。
在代码里,它其实就是一个 std::map<string, LayerProperties>,每个 Entity 里存一个 layerId 指向它。
这样,改一个层的颜色,所有属于该层的实体自动改变,不需要遍历所有实体。
内存节省: 以前每个实体都存一遍颜色、线型,现在这些信息只存在层表里,实体只需存一个 4 字节的 ID。
换个视角看:
1. 层 —— 数据的分组与“开关”
- 是什么:Layer 就像是 Photoshop 里的图层,或者更像 C++ 里的
namespace(命名空间) +std::vector的索引。 - 为什么存在:
- 在没有层的时候,画图就像在一张纸上乱画,想选中所有红色的线非常困难。
- AutoCAD引入了“层”,它本质上是一个容器。你可以规定“第0层放轮廓线(黑色)”,“第1层放标注(绿色)”。
- 对开发者的意义:层决定了实体的可见性(Visible)、颜色(Color)、线型(Linetype)和是否可以编辑(Locked)。当你开发插件时,不需要去遍历整个数据库找某个特定的圆,只需要去特定的层里找。
问题二:图里有很多重复的零件
你画了一个螺栓,它由六边形头部、圆柱杆、螺纹线组成,一共 20 条线。
在装配图里,这个螺栓要出现 50 次。
按照现在的设计,你得在内存里存 50 × 20 = 1000 条线的数据。
这太浪费了!而且如果要修改螺栓的样式,你得把这 1000 条线全部找到并更新。
你又灵机一动:
我能不能只定义一次“螺栓”的图形组合,然后在图中放置 50 个“引用”,每个引用只记录它放在哪里(位置、旋转角度)?
就像 C++ 里定义一个类,然后创建多个对象。
这就是 块 (Block) 和 块引用 (Block Reference)。
块定义(BlockTableRecord)里存一份几何数据;
块引用(BlockReference)里只存一个指向块定义的指针 + 变换矩阵(位置、旋转、缩放)。
内存从 1000 条线缩减到 1 份几何定义 + 50 个轻量级引用。
而且,修改螺栓形状时,只要改块定义,所有引用自动更新。
这就是享元模式的经典应用。
换个视角看:
2. 块 —— 实例化与复用
- 是什么:Block 是 AutoCAD 中最精华的部分。它相当于 C++ 中的
class(类),而你在图中插入的那个图形叫做 Block Reference(块参照),相当于instance(实例)。 - 前世今生:早期 CAD 画螺丝、门、窗户,如果每次都要复制几百个一模一样的图形,文件会巨大无比。块的出现解决了这个问题:
- 定义(Block Definition):在内存中只存储一份几何图形的“蓝图”。
- 引用(Block Reference):在图纸中放几百个“指针”,它们都指向同一个蓝图。
- 优势:如果你改了蓝图(重定义块),几百个实例会自动更新。这完全就是面向对象编程中的类与对象关系,也是设计模式中 Flyweight(享元模式) 的完美体现。
问题三:每个螺栓还需要不同的“属性”
螺栓有规格、材质、价格、生产厂家。
这些信息放在哪里?
如果放在块引用里,每个螺栓实例都可以不同;
如果放在块定义里,所有螺栓都一样。
显然,我们需要一种“实例数据”附加在块引用上。
这就是 属性 (Attribute)。
你可以把块定义想象成 C++ 的类,属性就是类的成员变量。
每个块引用(实例)都有自己的属性值,比如 M12×50、不锈钢。
这样,你可以轻松提取 BOM 表,把图形和数据无缝连接起来。
换个视角看:
3. 属性 —— 数据的载体
- 是什么:Attribute 是附着在块上的
struct成员变量,或者是数据库中的Field。 - 为什么存在:
- 假设你要画一张建筑图,里面有 100 个“窗户”块。你不仅要看到窗户的形状(几何),还要知道每个窗户的“型号”、“价格”、“生产厂家”。
- 属性就是用来干这个的。当你选中一个块参照,你可以通过属性提取出“C++ 结构体”里存储的具体值。属性是 AutoCAD 连接“图形”和“数据(MIS系统、ERP系统)”的桥梁。
问题四:画倾斜的零件时,输入坐标太痛苦
你想画一个倾斜 30° 的齿条,上面的齿形相对于水平线是斜的。
如果用世界坐标系,每个齿的坐标都要经过旋转矩阵计算,不仅容易算错,代码也复杂。
你想: 我能不能临时把“坐标系”旋转一下,让我以为我还在画水平线?
用户说:“我想在这个斜面上画一条水平线。”
其实这条线在绝对世界里是斜的,但在用户看来就是水平的。
这就是 用户坐标系 (UCS)。
你给用户提供一个命令,让他定义一个新的 UCS(选原点、X 轴方向、Y 轴方向)。
之后用户输入的所有点,都先通过这个 UCS 的变换矩阵转成世界坐标(WCS),然后存储。
画图的人觉得“我在画水平线”,实际上数据存储的是世界坐标系下的倾斜线。
UCS 本质上是一个 变换矩阵,它把用户习惯的局部坐标系映射到绝对存储坐标系。
换个视角看:
4. 坐标系 (WCS/UCS) —— 数学基与变换矩阵
- 是什么:
- WCS (World Coordinate System):世界坐标系。这是绝对的、唯一的。你可以理解为 C++ 数学库中的 全局原点
(0,0,0),是底层数据库存储数据的唯一标准。 - UCS (User Coordinate System):用户坐标系。这是一个
Transform Matrix(变换矩阵)。
- WCS (World Coordinate System):世界坐标系。这是绝对的、唯一的。你可以理解为 C++ 数学库中的 全局原点
- 为什么存在:
- 现实中,你画图不可能都是横平竖直的。比如你要画一个倾斜 30 度的桌子上的零件。
- 如果你用 WCS 算点,要用一大堆三角函数。
- 有了 UCS,你只需要调用
AcGeMatrix3d::setToRotation,告诉 AutoCAD:“把你的纸转 30 度,让我以为我还是在画水平线。” 然后你输入(0,0)就代表在斜面上的那个点。UCS 的本质就是一个从用户习惯到数据库存储的坐标映射。
问题五:出图时,比例和布局怎么弄?
图纸画好了,1:1 的模型空间里,齿轮箱实际尺寸是 2 米 × 1 米。
但打印要用 A3 纸(420mm×297mm),必须缩小 100 倍。
你不想缩小图形本身,因为修改时还是要按实际尺寸来。
你再次灵机一动:
把“绘图”和“打印”分开。
模型空间里永远是 1:1 的真实尺寸。
打印时,我们创建一个“布局”(Layout),它代表一张虚拟的纸。
在布局上,我们开一个“视口”(Viewport),这是一个窗口,可以设置缩放比例(例如 1:100),透过它去看模型空间里的内容。
这样,你可以在同一张图纸上放多个视口:
- 一个视口看整体(1:100)
- 一个视口看局部放大图(1:10)
- 还可以加标题栏、图框,这些也放在布局里,和模型空间无关。
这就是 MVC 模式的直观体现:
- 模型空间 = 数据模型
- 布局 = 视图
- 视口 = 摄像机 + 投影变换
5. 布局 与 视口 —— 模型与视图的分离
- 是什么:这是经典的 MVC 模式 的图形化体现。
- 模型空间 (Model Space):相当于 C++ 中的 数据模型。你在这里 1:1 画图,不管图纸多大(就像数据类本身)。
- 布局 (Layout):相当于 View。它模拟一张真实的物理纸张(A4、A0)。
- 视口 (Viewport):相当于 摄像机。它是一个窗口,透过它去看模型空间里的内容,而且可以设置不同的“缩放比例”。
- 为什么存在:
- 早期 CAD 是在模型空间里画个框框住图形来打印,修改非常麻烦。
- 后来引入了布局。这意味着你可以把“画图”和“出图”完全解耦。在模型空间画一个房子(1:1),在布局里,你可以开一个视口看整体平面图(1:100),开另一个视口看卫生间的大样图(1:20),两者互不干扰。这完美解决了工程制图中“同一数据,多比例呈现”的痛点。
也有人说,AutoCAD本质上是一个拥有40年历史的、极其庞大的图形数据库操作系统
回到你最初的疑惑
这些名词 —— 层、块、属性、UCS、布局/视口 —— 不是凭空冒出来的。
它们都是早期 CAD 开发者面对内存、性能、易用性等实际问题时,一步步做出的优雅设计。
当你用 C++ 去操作 AutoCAD 时,你其实是在和这套经典的数据结构打交道。
理解了它们的前世今生,你就会明白:
- 层 是分组与属性继承的容器
- 块 是复用与享元模式的实现
- 属性 是附着在块上的结构化数据
- UCS 是坐标变换的便捷工具
- 布局/视口 是模型与视图分离的经典实践
这些设计至今仍在几乎所有 CAD 软件中沿用,因为它们确实解决了本质问题。
现在,你可以带着这些“历史原因”去重新打开 AutoCAD,点开“图层特性管理器”,插入一个带属性的块,切换 UCS 试试 —— 你会发现,这些按钮背后,都是一段段为了节省内存、方便修改而设计的精巧代码。
解决了层、块、UCS 和布局这些“看得见”的功能之后,你作为早期 CAD 开发者,终于能画出一张像模像样的图纸了。
用户也渐渐从“能画线”变成“画复杂的装配图、建筑图”。
但很快,你又遇到了新的麻烦——这次不是内存不够,而是数据管理开始失控。
但是问题又来了:一切都要自己存,太蠢了
现在你的程序里,每个 Line、Circle 都存着自己的颜色、线型、所在层名。
比如一条红色的中心线,它存着:
- 几何:起点 (10,20),终点 (100,200)
- 颜色:红色
- 线型:虚线
- 层名:
"CENTER"
图里有一千条中心线,每条都存一遍“红色、虚线、CENTER”。
如果你想把中心线改成蓝色,就得遍历这一千条线,挨个改。
这跟当年手工改图纸有什么区别?
而且,你刚实现了“层”——用户明明已经在图层管理器里把 "CENTER" 层的颜色从红改成蓝了,为什么线还是红的?
你意识到问题:实体自己存属性,就失去了通过“层”统一控制的意义。
把“描述”和“图形”分开
你开始重构数据模型。
实体(Entity) 只保留几何信息(起点、终点、半径等),以及一个指向“描述”的 ID。
所有关于“怎么显示”的信息——颜色、线型、是否可见、是否锁定——全部抽出来,放进一个专门的表里,叫做 符号表 (Symbol Table)。
对于层,你建了一个 Layer Table,它是一个字典(像 std::map<string, LayerRecord>)。
每个 LayerRecord 存储层的名字、颜色、线型、开关状态。
实体里只存一个整数 layerId,指向 Layer Table 中的某个记录。
这样,当用户把 "CENTER" 层的颜色从红改成蓝时,你只需要修改 Layer Table 里那一条记录。
所有 layerId 指向它的实体,下次重绘时自然就变成蓝色了。
你甚至不需要知道哪些实体用了这一层——它们都通过 ID 间接引用。
不光层,块和线型也一样
块定义也类似。
你之前用“块定义 + 块引用”的方式节省了内存,现在你把所有块定义也放进一个 Block Table。
每个块定义是一个 BlockTableRecord,里面装着组成这个块的实体列表(那些线、圆、属性定义)。
块引用只存一个 blockId,以及变换矩阵。
线型(比如虚线、点划线)同样如此。
每个实体的线型不是存字符串 "DASHED",而是存一个 linetypeId,指向 Linetype Table 里的线型定义(包含线型模式、缩放比例等)。
你发现这种模式的好处巨大:
- 统一修改:改一处,处处生效。
- 内存节省:颜色、线型、层状态这些信息只存一份。
- 查询高效:想知道某个层有哪些实体?不用遍历所有实体,只需遍历实体时检查
layerId——虽然还是得遍历,但至少数据不再冗余。
但有些东西既不是实体,也不是符号表
有一天,用户想保存一些额外信息,比如:
- 这张图纸的作者是谁?
- 这个插件上次运行的参数是什么?
- 某个自定义对象的扩展数据。
这些东西不属于图形(不能画出来),也不属于系统预定义的符号表(层、块、线型、文字样式等)。
你怎么办?
你可以在图纸文件末尾偷偷塞一个二进制块,但那样不透明,也不易扩展。
于是你设计了一个 字典 (Dictionary) —— 一个更通用的键值对容器。
它就像 C++ 的 std::unordered_map<std::string, ObjectId>。
你可以把任何“命名对象”放进去,比如 "AUTHOR" 指向一个文字对象,"MyPluginSettings" 指向一个你自己定义的配置对象。
在 AutoCAD 里,这个顶级字典叫 命名对象字典 (Named Objects Dictionary)。
它给所有开发者留了一个“万能口袋”,用来存储任何不属于标准符号表的东西。
回到你的角色
现在,当你写 C++ 代码(用 ObjectARX)时,你脑子里很清楚:
- 实体:看得见、可编辑、有几何的玩意。它们都派生自
AcDbEntity。 - 非实体对象:
- 符号表:系统级的容器,存着层的定义、块的定义、线型的定义等。
- 字典:开发者级的容器,存着各种自定义数据。
每次你操作一个实体,比如修改颜色,你实际上不是直接改实体本身,而是通过它的 layerId 找到 Layer Table 里的记录,再改那个记录的颜色。
你明白了为什么 AutoCAD 里“改层的颜色,所有对象瞬间变” —— 因为本来就是这样设计的。
这对你开发插件意味着什么
当你想统计一张图里所有红色的线时,你不会傻乎乎地遍历每条线判断它的颜色属性。
你会:
- 打开
Layer Table,找到所有颜色为红色的层。 - 记录下这些层的 ID。
- 遍历所有实体,检查它们的
layerId是否在那组 ID 中。
这样效率更高,而且更符合 AutoCAD 的数据哲学。
同样,当你想插入一个块时,你其实是在 Block Table 里查找或创建块定义,然后创建 BlockReference 指向它。
当你想要保存插件配置时,你打开 Named Objects Dictionary,创建一个自定义对象放进去。
这套设计,诞生于内存以 KB 计量的年代,却极其优雅地解决了“数据共享、统一控制、灵活扩展”的问题。
直到今天,它依然是 AutoCAD 的底层骨架。
理解它,你就不再是一个只会“调用 API”的开发者,而是真正理解了 AutoCAD 的“操作系统内核”。
你看着自己设计出的这套“实体+符号表+字典”的数据库结构,长舒一口气。
数据管理终于变得清晰了,图纸不再臃肿,修改也能瞬间生效。
你开始觉得,也许 AutoCAD 真的能成为设计师们的得力助手。
但很快,你又遇到了新的难题——这一次不是数据怎么存,而是用户怎么用。
命令行时代:一次只做一件事
早期的 AutoCAD 只有命令行。
用户敲一个命令,比如 LINE,程序就进入“画线模式”,提示用户输入起点、终点。
在命令执行期间,用户不能干别的——不能画圆,不能改层,更不能打开另一个图纸。
你作为开发者,代码逻辑很简单:一个命令函数从头跑到尾,中间穿插几次用户输入,函数返回后,用户才能敲下一个命令。
这种模式叫做 模态交互 —— 程序的控制流是线性的,一次只做一件事。
对开发者来说,这很舒服。你不需要考虑用户会不会在画线中途跑去修改图层属性,因为根本不允许。
图形界面的诱惑:让工具面板“浮”起来
随着 Windows 普及,用户开始习惯鼠标点一点、右边有个面板随时改属性。
他们问你:“能不能像 Word 一样,我一边画图,右边的属性面板随时显示当前选中对象的信息,我改了颜色,它就立刻变?”
你心动了。
但实现这个,意味着你的程序必须允许 两个东西同时运行:
- 用户在图纸上画线、选对象
- 一个对话框(属性面板)始终显示着,用户可以在上面修改参数
这和你熟悉的命令行模式完全不同。
这种对话框,不会阻塞用户对 AutoCAD 主窗口的操作,它叫 非模态对话框 (Modeless Dialog)。
模态对话框:简单的“弹窗锁”
你首先尝试的是模态对话框。
它就像 C++ 里的 DoModal(),弹出来时,用户只能操作这个对话框,点不了画图区,也输不了命令。
这很简单:你在对话框里收集用户输入(比如“新建文件时选模板”),点击“确定”后关闭,继续执行后续代码。
在这期间,AutoCAD 的图形数据库是安全的,因为用户没法去修改它。
你把这种用于“一次性参数输入”的对话框做得很顺手。
非模态对话框:麻烦开始了
真正让你头疼的是非模态对话框。
你做了一个“快速属性面板”,里面有个下拉框可以选择颜色。
用户选中一条线,面板显示它的颜色,用户改成红色,那条线就应该立即变红。
但你发现,当面板开着的时候,用户可能:
- 切换到另一张打开的图纸
- 新建一张图纸
- 关闭当前图纸
- 在执行某个命令的过程中,点你的面板上的按钮
你的代码必须知道:此时此刻,用户正在操作哪张图纸?
如果面板还在,但用户已经关掉了图纸,你的代码再去修改那个图纸里的对象,程序就会崩溃。
如果用户激活了第二张图纸,你的面板应该显示第二张图纸里当前选中对象的信息,而不是第一张的。
多文档与上下文切换:开发者噩梦
你意识到,AutoCAD 支持同时打开多个图纸(MDI,多文档界面),每个图纸对应一个 文档 (Document),每个文档有自己的图形数据库、自己的当前选中集。
你的非模态对话框,就像一个独立的线程,它必须在正确的时间,操作正确的文档。
在 C++ 开发(ObjectARX)中,你得学会一个概念:文档锁 (Document Lock)。
当你的对话框要操作某个文档时,必须先锁定那个文档,防止用户在操作过程中把它关了,或者防止另一个对话框同时修改它。
你还要监听“文档激活”事件,当用户切换到另一个文档时,你的对话框要立即刷新数据。
这比你预想的复杂得多。
你终于理解了为什么 AutoCAD 早期几乎都是模态交互——非模态需要开发者处理异步、多文档、资源竞争,一不小心就 crash。
模态 vs 非模态:设计的取舍
回过头看,你总结出两者的本质区别:
-
模态对话框:程序执行流被阻塞,用户必须完成当前交互才能继续。适合“一次性参数输入”,例如新建文件、插入块时的参数设置。在这种模式下,AutoCAD 的图形数据库是安全的,你不需要担心用户在对话框开着时乱改图纸。
-
非模态对话框:程序执行流不阻塞,用户可以在画图和对话框操作之间来回切换。适合“实时编辑”和“状态显示”,例如属性面板、工具选项板。但开发者必须处理文档上下文切换、锁定、事件同步等复杂逻辑。
这不仅是 UI 设计问题,更是程序架构问题。
在你的 C++ 代码里,模态就像普通的函数调用,非模态就像多线程编程——你得小心地管理资源,确保对话框在正确的时机访问正确的数据。
转换思维:AutoCAD 是一个数据库服务
经历了这么多,你终于学会用全新的视角看 AutoCAD:
- AutoCAD = 一个运行中的图形数据库服务,它管理着所有图纸(数据库)的读写、事务、并发。
- 一张图纸 (DWG) = 一个数据库文件,里面包含实体表、符号表、字典等。
- 实体 = 数据库中的记录,每一条都有唯一的 ID。
- 层表、块表 = 数据库的系统表(Schema),存储元数据。
- UCS = 一个临时的坐标变换矩阵,方便用户输入,但底层存储永远是 WCS。
- 模态/非模态 = 程序执行流是否阻塞,也决定了你是否需要处理文档上下文切换。
当你开始写插件时,你会发现:
- 想删除所有红色线,你不会傻到遍历所有线判断颜色,而是去 层表 找到红色的层 ID,然后遍历所有指向该层的实体(高效,且符合数据库索引思维)。
- 想统计图纸里所有块的属性,你不会去逐个选择图形,而是去 块表 遍历块定义,再读取每个块引用的属性。
- 想自动出图,你会去操作 布局和视口 来调整比例和位置,而不是去缩放模型空间里的图形。
给新手的建议
你现在明白,这些名词不是 AutoCAD 的“功能”,而是它的核心数据结构和交互模型。
它们不是凭空发明的,而是为了应对早期资源限制和用户需求,一步步演变出来的优雅设计。
作为 C++ 开发者,我建议你:
- 从 面向对象 的角度理解这些概念,把它们对应到 C++ 的类、继承、多态、容器。
- 如果你刚入门,可以先看 AutoCAD 的 .NET API 文档(即使你最后用 C++ 开发 ObjectARX)。.NET 的 API 更现代、逻辑更清晰,能帮你快速建立对
Database、Transaction、ObjectId等核心概念的理解。 - 记住:AutoCAD 的二次开发,本质上是在操作一个图形数据库,而不是简单的绘图 API。一旦你掌握了这个视角,写出的代码才会高效、稳定。
现在,你再打开 AutoCAD,点击“图层特性管理器”,插入一个带属性的块,或者在 UCS 下画条线——你看到的已经不是按钮,而是一段段为了节省内存、方便修改、保证安全而精心设计的代码逻辑。
而这些,正是 CAD 软件四十年来沉淀下来的智慧。
-
如果想了解一些成像系统、图像、人眼、颜色等等的小知识,快去看看视频吧 :
- 抖音:数字图像哪些好玩的事,咱就不照课本念,轻轻松松谝闲传
- 快手:数字图像哪些好玩的事,咱就不照课本念,轻轻松松谝闲传
- B站:数字图像哪些好玩的事,咱就不照课本念,轻轻松松谝闲传
- 认准一个头像,保你不迷路:

- 认准一个头像,保你不迷路:
-
您要是也想站在文章开头的巨人的肩膀啦,可以动动您发财的小指头,然后把您的想要展现的名称和公开信息发我,这些信息会跟随每篇文章,屹立在文章的顶部哦


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 21
21 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)