Cursor滑跪开源技术报告:Kimi基模这样微调能干翻Claude
Cursor滑跪开源技术报告:Kimi基模这样微调能干翻Claude
导读:当"套壳"成为一门技术活,Cursor用一份技术报告告诉我们:基于中国开源模型Kimi K2.5,通过持续预训练+异步强化学习,完全可以在代码Agent领域干翻Claude Opus 4.6。这不是简单的"拿来主义",而是一场关于"开源基模+垂直微调"的工程范式革命。
文章目录
一、事件回顾:从"套壳疑云"到"滑跪认错"
3月19日:Composer 2的"自研"宣言
Cursor发布了Composer 2,官方博客宣称这是"首个自研模型",采用"首次对基座模型进行持续预训练,结合强化学习"的技术路径 。基准测试数据相当亮眼:
- CursorBench:61.3分(超越Claude Opus 4.6的58.2分)
- SWE-bench Multilingual:73.7分(较上一代65.9分大幅提升)
博客用了一个精心措辞的说法:“我们的第一次继续预训练”——给人的感觉是,Cursor从头训练了一个编程模型。
3月20-21日:社区"破案"与马斯克实锤
不到24小时,开发者Fynn通过调试API截获模型ID:kimi-k2p5-rl-0317-s515-fast 。月之暗面预训练负责人杜宇伦确认该模型与Kimi K2.5使用完全一致的tokenizer。埃隆·马斯克在X上转发并实锤:“Yeah, it’s Kimi 2.5” 。
更尴尬的是,这是Cursor第二次被发现使用中国开源基座模型。2025年11月发布的Composer 1已被社区识别出tokenizer与DeepSeek一致,且推理中偶现中文输出,Cursor当时未作回应 。

3月21日:Cursor的"滑跪"与和解
面对舆论压力,Cursor联合创始人Aman Sanger公开认错:“一开始没在博客里提到Kimi的底座,是我们的疏忽。下一个模型我们会改正” 。随后,Cursor与月之暗面确认存在商业授权合作,双方达成和解 。
3月27日:技术报告发布——“有技术地套”
最新消息,Cursor放出Composer 2技术报告,力证自己不是"纯套",而是"有技术地套、循序渐进地套" 。报告开篇第一件事:老老实实署名Kimi K2.5,并盛赞:
“训练前,我们评估了多款潜在的开源基础模型,包括GLM5、Kimi K2.5和DeepSeek V3.2,但Kimi K2.5是最棒的!”
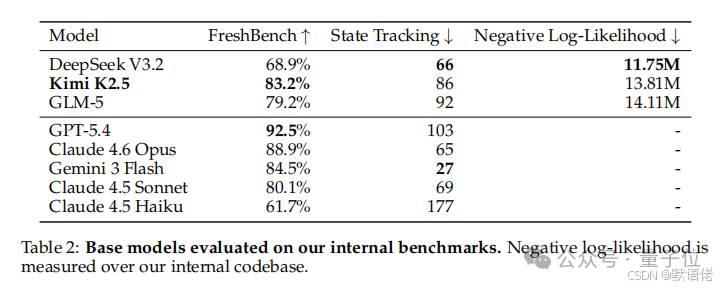
滑跪速度之快,态度之诚恳……但网友们似乎并不买账。毕竟,这份报告更像是一份"危机公关+技术找补"的混合体。
二、技术深扒:Cursor如何把Kimi 2.5"炼"成Composer 2?
抛开争议,这份技术报告确实揭示了一套完整的开源基模垂直优化范式。对于想基于开源模型做垂直领域落地的开发者来说,极具参考价值。
2.1 整体架构:站在巨人肩膀上的"二次创作"
┌─────────────────────────────────────────┐
│ Composer 2 架构 │
├─────────────────────────────────────────┤
│ 应用层:Cursor IDE Agent 交互逻辑 │
├─────────────────────────────────────────┤
│ 训练层:持续预训练(32k→256k) + 异步RL │
├─────────────────────────────────────────┤
│ 基座层:Kimi K2.5 (约25%预训练权重) │
└─────────────────────────────────────────┘
Cursor员工Lee Robinson透露,Composer 2约25%的预训练来自K2.5的基座模型,其余75%通过继续预训练和强化学习完成 。推理部署由Fireworks提供商业授权支持。
2.2 阶段一:持续预训练(Continual Pre-training)
这是Composer 2的"地基工程",目的是提升模型在编码领域的基础知识和潜在编码能力,分为三个子阶段 :
| 阶段 | 序列长度 | 目标 | 关键技术 |
|---|---|---|---|
| 基础训练 | 32k tokens | 掌握代码语法、结构、常见模式 | 大部分计算资源投入 |
| 长上下文扩展 | 256k tokens | 支持大型代码库理解 | 短期训练快速扩展 |
| 指令微调(SFT) | - | 适配特定代码任务 | 小样本指令调优 |
工程亮点:
- 多token预测(MTP):新增MTP层,结合投机解码技术和自蒸馏策略,显著提升线上推理速度
- 数据质量验证:模型在自研代码库上的损失值呈对数线性下降,且代码库困惑度与下游RL性能正相关,证明预训练有效性
2.3 阶段二:异步强化学习(Async RL)
这是Composer 2的"灵魂注入"环节。Cursor没有采用简单的SFT,而是构建了一套高度模拟真实Cursor对话场景的RL训练环境 。
训练框架设计
# 伪代码示意 Composer 2 RL 训练流程
class Composer2RL:
def __init__(self):
self.base_model = "kimi-k2.5"
self.optimizer = "Adam" # 全参数更新
self.algorithm = "Optimized_GRPO"
def train_step(self, instruction):
# 单指令多样本策略
samples = self.generate_multiple(instruction, k=K)
# 同一指令仅参与一次训练(避免过拟合)
if instruction in self.seen_instructions:
return
# 移除长度标准化,避免长度偏差
rewards = self.compute_rewards(samples, normalize=False)
# KL散度正则化 (k1=-log r)
kl_penalty = self.kl_divergence(samples, self.base_model)
# 更新策略
loss = self.grpo_loss(rewards, kl_penalty)
self.model.update(loss)
关键技术创新
-
稳定性优化:
- 采用单指令多样本的策略梯度算法
- 设置固定的样本组大小,避免训练震荡
- 同一指令仅参与一次训练,防止记忆化
-
GRPO算法改进:
- 移除长度标准化项,避免模型"拖长答案"的投机行为
- 引入KL散度(k1=-log r)实现正则化,保持与基座模型的偏离可控
-
辅助奖励机制:
- 正向奖励:代码风格、交互表达质量
- 负向惩罚:不当工具调用、危险操作
- 动态调整:根据训练中涌现的行为实时调整奖励规则
训练效果验证
研究发现,最终模型的平均性能和best-of-K性能同步提升,证明RL不仅重新加权推理路径,还扩展了正确解的覆盖范围 。这意味着模型不是死记硬背,而是真正学会了"举一反三"。
2.4 评测体系:自建CursorBench的"降维打击"
Cursor没有依赖SWE-bench等公开基准,而是自建了CursorBench——一套更贴近真实编程场景的评估体系 :
| 维度 | CursorBench | SWE-bench |
|---|---|---|
| 代码修改量 | 中位数181行 | 7-10行 |
| 指令长度 | 中位数390字符 | 1185-3055字符 |
| 评估维度 | 功能正确性+代码质量+执行效率+智能体交互 | 仅功能正确性 |
| 任务来源 | 真实Cursor Agent使用场景 | 开源仓库Issue |
这种"自己出题自己考"看似不公平,但恰恰反映了垂直领域评测的本质:公开基准测试的是"解题能力",而CursorBench测试的是"工程交付能力"。
结果显示,Composer 2在CursorBench-3中准确率达61.3%,较1.5版本相对提升37%、较1版相对提升61% 。
2.5 成本与效率:帕累托最优的工程实践
Composer 2实现了帕累托最优 :
- 推理成本:与更小的模型相当
- 精度表现:媲美大尺寸前沿模型(Claude Opus 4.6)
- Token效率:与其它SOTA模型持平,无额外资源消耗
这意味着,通过精细的垂直优化,中等规模的基座模型+高质量领域数据+高效RL训练,完全可以挑战千亿级闭源模型的性能。
三、行业冲击:开源基模时代的"套壳哲学"
Cursor事件不是孤立的"翻车现场",而是AI行业范式转移的缩影。
3.1 从"造轮子"到"改引擎":AI应用层的新分工
传统认知中,"自研模型"意味着从0开始预训练。但Cursor的实践揭示了新范式:
| 模式 | 代表 | 投入 | 风险 | 适用场景 |
|---|---|---|---|---|
| 全栈自研 | OpenAI, Anthropic | 数十亿美元 | 极高 | 通用AGI |
| 开源基模+垂直优化 | Cursor, 多数AI应用 | 数百万-千万美元 | 中等 | 垂直领域 |
| 纯API调用 | 早期Cursor, 多数初创公司 | 低 | 依赖性强 | 快速验证 |
Cursor的选择是理性的:作为代码编辑器公司,其核心能力不是预训练大模型,而是理解开发者需求、构建Agent交互、积累代码数据。基于Kimi 2.5这样的开源SOTA模型做垂直优化,是性价比最高的路径 。
3.2 开源基模的"权力反转"
这场争议的最大赢家是中国开源模型生态。
- Kimi K2.5成为Cursor评估后认定的"最强基模",超越GLM5、DeepSeek V3.2
- Modified MIT许可证虽然要求商业产品标注,但提供了合法合规的使用路径
- 性能背书:Composer 2在代码任务上超越Claude Opus 4.6,证明了开源模型的商业落地潜力
正如杨植麟在中关村论坛所言:“开源模型正在逐渐成为新的标准。而以Kimi K2.5为代表的开源模型,已经成为全世界所有芯片厂商测试硬件性能的基准” 。
3.3 争议背后的"估值叙事"冲突
Cursor正处于约500亿美元估值的融资关键期,ARR在90天内由10亿美元增至20亿美元 。承认基于开源模型,意味着其技术护城河不如"全栈自研"叙事中那么深。
但讽刺的是,Cursor此前高度依赖Anthropic的Claude模型,年付推理费用约6.5亿美元,导致毛利率为负 。转向"自研"(即使是基于开源的优化)实为降低依赖、改善利润结构的生存性举措。
这场"套壳"争议的本质,是资本市场对AI公司估值逻辑的重估:当开源模型足够强,“拥有模型” vs "善用模型"哪个更有价值?
四、开发者启示:如何"有技术地套"?
Cursor的技术报告为基于开源模型做垂直优化的开发者提供了可复用的方法论。
4.1 基座选择:不要重复造轮子
选型 checklist:
- 许可证兼容性:Modified MIT、Apache 2.0等商业友好型
- Tokenizer一致性:避免后续训练数据格式冲突(Cursor与Kimi使用相同tokenizer是关键)
- 基础设施匹配:考虑推理部署成本、硬件兼容性
- 社区活跃度:模型更新频率、bug修复速度、生态工具丰富度
Cursor评估了GLM5、Kimi K2.5、DeepSeek V3.2后选择Kimi,理由是"综合能力突出+自研基础设施中的执行效率" 。
4.2 数据工程:垂直领域的"护城河"
Cursor的核心资产不是模型权重,而是自研代码库和真实Agent交互数据。
数据策略:
- 领域数据积累:构建高质量、专有的领域语料库(Cursor的自研代码库)
- 真实场景模拟:训练环境高度模拟实际产品交互(Cursor的RL环境模拟真实对话场景)
- 数据-指标相关性:验证预训练指标(如困惑度)与下游任务性能的相关性
4.3 训练策略:预训练+RL的"组合拳"
技术路线:
开源基模
→ 持续预训练(领域数据+长上下文扩展+SFT)
→ 异步强化学习(真实场景模拟+多维度奖励+动态调整)
→ 垂直领域SOTA模型
关键技巧:
- 分阶段训练:先扩展能力(预训练),再对齐场景(RL)
- 全参数更新:使用Adam优化器更新全部参数,而非LoRA等轻量微调(保证充分适配)
- 避免过拟合:同一指令仅参与一次训练,使用KL散度约束与基座模型的偏离
4.4 评测体系:建立"内部标准"
不要迷信公开基准。CursorBench的设计哲学值得借鉴:
- 任务真实性:来自真实产品场景,而非构造的测试集
- 多维度评估:功能正确性只是底线,代码质量、执行效率、交互体验同样重要
- 难度匹配:指令更简洁(390字符 vs 1000+),修改量更大(181行 vs 7-10行),更接近工程师实际工作流
五、未来展望:开源生态的"中国时刻"
Cursor事件标志着中国开源模型从"跟随者"向"标准制定者"的转变。
5.1 Kimi的"Scaling Law"新解
杨植麟在技术报告中分享了Kimi团队的最新思考,提出大模型训练的第三阶段 :
| 阶段 | 时间 | 核心特征 |
|---|---|---|
| 第一阶段 | 2023-2024 | 天然数据为主,少量人工标注 |
| 第二阶段 | 2025 | 人工筛选高质量任务,大规模强化学习 |
| 第三阶段 | 2026+ | Agent集群协作,规模化输入/输出/执行/编排 |
Kimi的Scaling策略聚焦于三点 :
- Token效率:用同样有限的数据学到更多智能
- 长上下文:新架构Kimi Linear从根本上提升长程能力
- Agent集群:不再死磕单模型极致,而是通过多Agent协作解决复杂问题
5.2 开源 vs 闭源:效率之争
Cursor的实践证明了开源基模+垂直优化路线的可行性:
- 成本效率:避免数十亿美元的预训练投入
- 迭代速度:基于成熟基座快速验证场景
- 合规可控:Modified MIT等许可证提供了明确的商业使用路径
这对闭源模型厂商构成了根本性挑战:当开源模型通过垂直优化能在特定领域超越闭源模型,通用模型的溢价空间在哪里?
5.3 给开发者的建议
- 拥抱开源:Kimi、DeepSeek、GLM等中国开源模型已具备商业落地能力,且许可证日益完善
- 专注场景:与其追求"通用大模型",不如在垂直场景做深做透(如Cursor专注代码Agent)
- 数据为王:模型权重会同质化,但高质量领域数据和RL训练环境是护城河
- 合规先行:使用开源模型务必遵守许可证要求(标注义务、商用限制等),避免Cursor式的"滑跪"
结语:从"Copy to China"到"Copy from China"
十年前,中国互联网公司被诟病"Copy to China"。如今,硅谷明星公司Cursor基于中国开源模型构建核心产品,甚至在被发现后"滑跪"道歉——这何尝不是一种**“Copy from China”**?
但Cursor的技术报告也证明,"套壳"不是原罪,"无脑套"才是。通过持续预训练、异步强化学习、自建评测体系,Cursor确实把Kimi 2.5"炼"成了在代码Agent领域超越Claude的存在。
这场争议的最大启示是:开源基模时代,"拥有模型"不再是壁垒,"用好模型"才是核心竞争力。 对于广大开发者来说,这是一个比"训练千亿参数模型"更务实、更可行的创业路径。
正如杨植麟所言:“我们希望通过开源,让所有人都能以非常低的门槛获取智能。最终,大家能够去形成一个开源生态系统,共同推动AI领域的发展” 。
Cursor的"滑跪",或许正是这个开源生态系统走向成熟的标志。
参考链接:
- Cursor Composer 2技术报告解读(36氪):https://www.36kr.com/p/3740414075011328
- Cursor套壳Kimi事件回顾(DoNews):https://www.donews.com/news/detail/4/6478296.html
- 杨植麟中关村论坛演讲(智源社区):https://hub.baai.ac.cn/view/53368

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)