大模型记不住时间?MemoTime 时序知识图谱全解析(非常详细),解决动态推理难题必看!

1
研究背景
当大语言模型面对“谁在某个时间之前担任某职位”“某事件发生后又发生了什么”“多个实体是否在同一时间窗口内存在关联”这类问题时,其表现往往并不像看上去那样可靠。
原因在于,大模型虽然擅长理解语义信息,但对时间顺序、事件演化以及多实体之间时序关系的把握仍然有限。一旦问题涉及动态变化的知识,模型就容易出现事实混淆、时间错位,甚至生成看似合理却实际上并不成立的答案。
围绕“大语言模型如何更准确地处理复杂时间问题”这一挑战,近日,新南威尔士大学(UNSW)联合CSIRO’s Data61提出了新的时序推理框架MemoTime,相关工作已被WWW 2026接收。该框架结合时序知识图谱、层次化推理与经验记忆机制,为时间敏感型问答和动态知识推理提供了新的解决思路。
1
为什么大语言模型在时间问题上容易出错?
近年来,大语言模型在开放问答、代码生成、信息抽取和复杂推理等任务上都展现出很强能力。但这类模型本质上仍依赖静态参数来存储知识,这意味着它们并不会天然跟随现实世界持续更新。一旦问题涉及不断变化的实体关系,例如人员任职变动、组织合并重组、事件前后顺序、跨阶段状态变化等,模型就可能出现以下问题:
- 一是知识过时。模型记住的是训练时见过的事实,而不是当前最新的事实。
- 二是时间混淆。模型可能知道多个相关事实,但不能保证它们在同一个时间条件下同时成立。
- 三是推理幻觉。模型会把语义上相关、但时间上不兼容的证据拼接到一起,形成错误推理链。
2
传统RAG为什么还不够?
检索增强生成(RAG)已经成为缓解大模型静态知识问题的一种常见方式。它的核心思想是:在模型生成答案前,先从外部知识库中检索相关信息,再把这些信息提供给模型做推理。但对于复杂时间问题来说,传统RAG仍然存在明显限制。大多数文本型RAG主要依赖向量检索寻找“语义最相似”的文本片段。这种方式对于普通事实问答很有效,但对于涉及时间顺序的问题则不够稳妥。因为在时间推理中,真正关键的不只是“说的是不是同一个主题”,而是“这些事实是否发生在正确的时间关系中”。 因此, 如果没有对时间顺序和结构化关系的建模,因此很容易把“语义相关但时间上不成立”的事实混在一起。
例如,“Obama是美国总统(2009–2017)”与“Biden是美国总统(2021–)”这两条事实都和“美国总统”高度相关,但显然不能在同一时间段内同时成立。如果系统只是按语义相似性去找答案,就可能把它们错误地混用。
相比普通文本,**时序知识图谱(Temporal Knowledge Graph, TKG)**提供了一种更适合时间推理的知识表示方式。它用带时间戳的四元组来表示事实:(主体, 关系, 客体, 时间)。来显式表示事实及其发生时间,因此为时间推理提供了更可靠的基础。但即便引入TKG,现有很多方法仍然没有很好解决复杂时间推理中的几个关键难点。
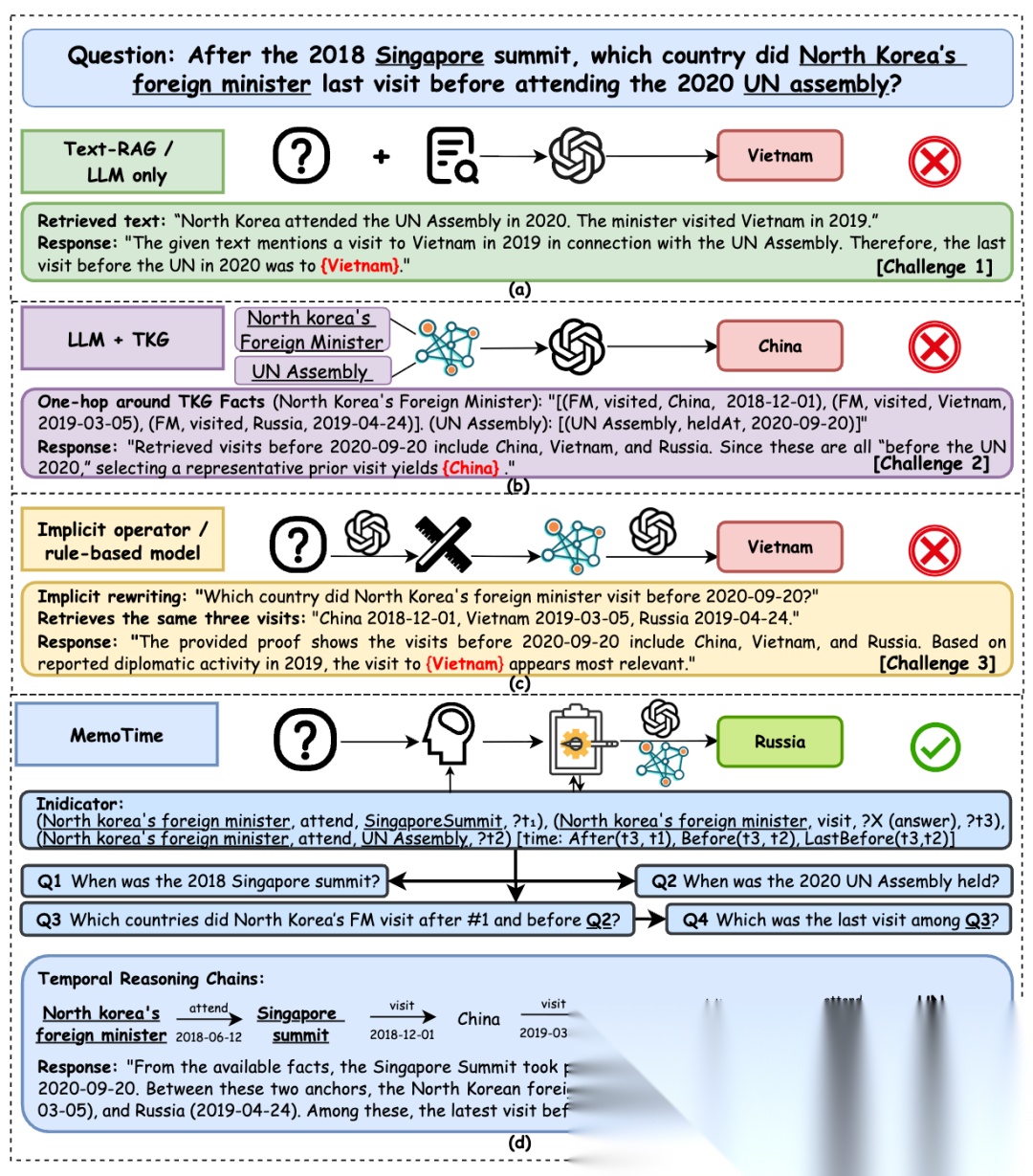
图1: workflow对比图及MemoTime示例
3
现有方法的关键问题?
现有TKG推理框架大多采用“plan-retrieve-answer”的流程,也就是先拆问题,再检索相关事实,最后生成答案。这个流程虽然有一定可解释性,但仍有四个关键短板。
-
Gap 1:多跳推理中的时间一致性不足
**很多方法在扩展推理路径时更关注语义相关性,而不是整条路径是否满足全局时间约束。**结果就是,单独看每一步都似乎合理,但组合起来却在时间上不成立。例如,问题中要求“某事件发生之后”或“某人最后一次访问之前”的关系时,系统如果只根据表面语义选择证据,就可能选到错误的时间节点。
-
Gap 2:多实体问题缺少统一时间同步
当问题中同时包含多个实体时,很多方法会分别探索每个实体,再在后面拼接证据。这样虽然每一部分都可能各自正确,但它们未必能落在同一条时间一致的推理链上。
-
Gap 3:不同时间算子需要不同检索策略,但现有方法适应性弱
时间问题并不只有“before/after”这么简单,还会涉及first、last、duration、set relation等不同算子。现有方法大多采用较固定的改写或检索方式,难以根据不同时间算子自适应调整。一些方法采用RL进行不同的检索工具调用,但训练消耗极****大。
-
Gap 4:缺少可积累的推理经验记忆
很多系统是“无记忆”的。一次问题做完后,成功的推理路径、子问题拆解方式、工具使用经验都被丢弃。结果就是模型不断重复解决相似问题,既影响效率,也限制了稳定性。
为了解决上述时间推理难题,论文提出了MemoTime,一个面向时序知识图谱的记忆增强大模型推理框架。它将时间约束建模、层次化推理、算子自适应检索、以及经验记忆更新统一到同一个框架中,从而让LLM能够在面对复杂时间问题时进行更可靠、更可解释、也更高效的推理。
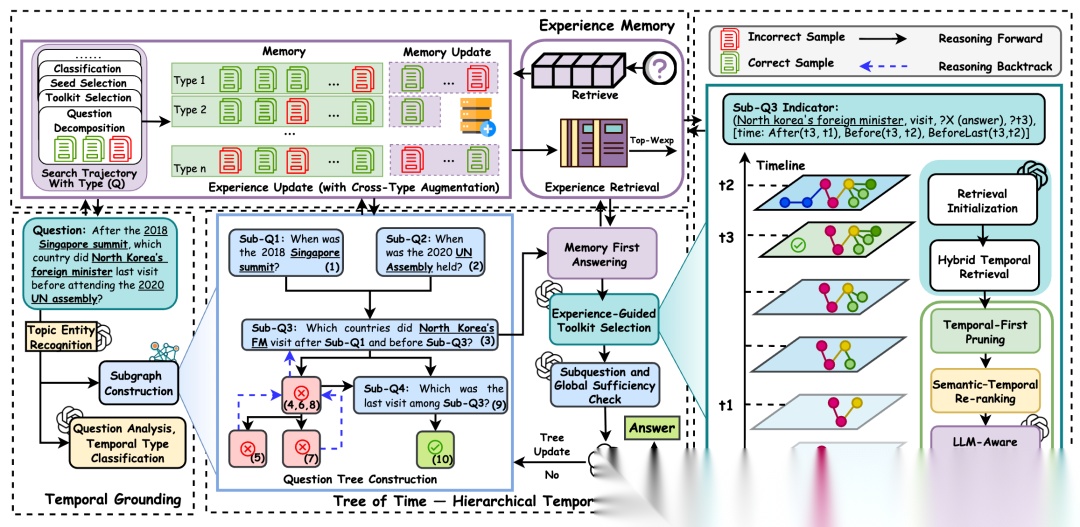
图2: MemoTime框架示意图
如图二所示,MemoTime主要由四部分组成:1.Temporal Grounding, 2.Tree of Time Hierarchical Reasoning, 3.Temporal Evidence Retrieval and Pruning, 4.Experience Memory
2
研究方法
1.Temporal Grounding:先把问题“落到时间事实”上
MemoTime首先会从问题中识别主题实体和时间相关信息,并在时序知识图谱中构建一个与问题相关的局部子图,作为后续推理的事实基础。然后系统还会对问题进行temporal type classification,识别该问题属于哪一类时间推理任务。与使用静态模板不同,MemoTime会从经验记忆中检索相似的历史样例,辅助当前问题的时间类型判断。这一阶段的作用,是把自然语言问题转化为一个更加结构化、带有明确时间约束的推理起点。
2.Tree of Time:让复杂问题按层次展开
MemoTime创新性的设计了Tree of Time的层次化推理控制器。 与传统的线性拆问题方式不同,Tree of Time会把复杂问题组织成一棵子问题树。每个子问题都继承主问题中的时间约束,并且在全局控制下保持时间顺序一致。
这样做有两个直接好处:
- 可以避免子问题之间各自为战,导致最后拼起来出现时间矛盾;
- 可以让整个推理过程更清楚,因为每一步都能对应到更明确的子任务。
换句话说,MemoTime不只是“找证据”,而是在“按时间规则组织证据”。当某个子问题到来时,系统会先检查经验池里是否已有相似推理轨迹可以复用;如果没有,再动态选择合适的temporal toolkit去做检索和推理。最后再做sufficiency check,判断当前子问题是否已经被充分解决,如果没有则继续细化或扩展。
3.Temporal Evidence Retrieval and Pruning:面向时间约束的混合检索与剪枝
论文强调,想要回答复杂时间问题,关键在于找到既满足语义相关性、又满足时间约束的推理路径。为此,MemoTime设计了一套hybrid temporal retrieval机制,同时结合图结构时间路径扩展和embedding检索。
与很多方法先看语义不同,MemoTime采用temporal-first pruning,先过滤掉违反时间约束和时间单调性**的路径,再做语义与时间的联合重排序,最后再交给LLM做最终选择**。这样做可以显著减少“语义像但时间不对”的噪声路径。
4.Experience Memory:把成功推理经验真正存下来
MemoTime的一个很重要的特点是,它不是一次性推理框架,而是一个可持续积累经验的系统。每次成功的推理结束后,系统都会把子问题、所选工具、时间路径、推理结果及其embedding一起写回经验池。之后遇到相似问题时,就可以按问题类型和语义相似度检索这些经验,用来辅助类型判断、问题拆解、种子选择和工具选择。
同时,MemoTime还支持一定程度的cross-type augmentation,即把某些结构相近的不同类型时间问题建立联系,提高经验复用能力。
3
研究结果
为了验证MemoTime的有效性,团队在两个具有代表性的时序问答基准上进行了系统实验,包括MultiTQ和TimeQuestions。其中,MultiTQ是目前公开可用规模最大的时序知识图谱问答数据集,覆盖多跳推理、多实体协同和多种时间算子;TimeQuestions则更加关注显式与隐式时间表达、时间型与序数型答案等更细粒度的时间理解能力。
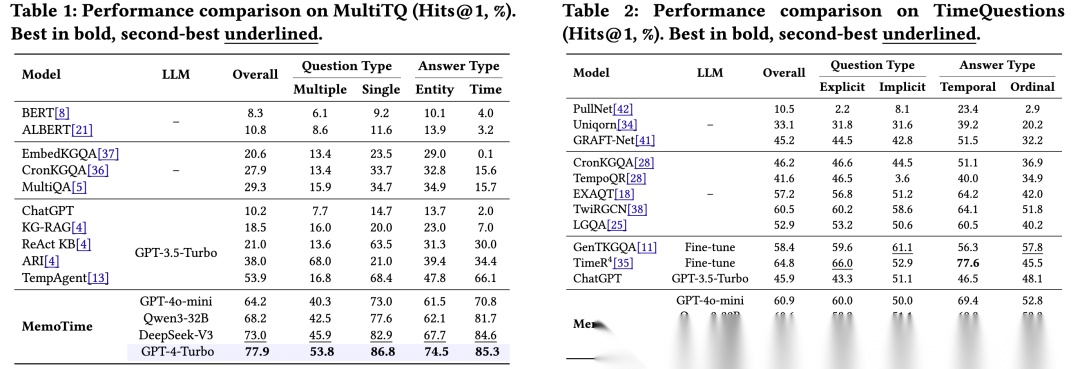
实验结果显示,MemoTime在两个数据集、不同问题类型和不同主干模型上都取得了当前最优结果。在MultiTQ上,搭载GPT-4-Turbo的MemoTime比此前表现最好的提升24.0%;即便使用更小的骨干模型,如Qwen3-32B,MemoTime仍可达到68.2%,已经超过最好的GPT-3.5系列基线方法。在TimeQuestions上,MemoTime同样取得最佳整体表现,超过了经过专门训练的GenTKGQA和TimeR4,而MemoTime本身仍然是training-free的框架。
这些结果说明,MemoTime并不是简单地把TKG接到LLM前面,而是通过temporal grounding、层次化Tree of Time推理、面向算子的动态检索,以及经验记忆复用,显著增强了模型在复杂时间问题上的时间一致性、推理稳定性与泛化能力。尤其是在多跳、多实体和隐式时间约束并存的场景下,MemoTime的优势更加明显。
赋能小模型,媲美大模型性能

**MemoTime的记忆增强与时序推理能力,让小参数模型在复杂时间问答任务上实现了“质的跃升”****。**在接入MemoTime之后,原本时序推理能力较弱的小模型,也能够更好地理解多跳时间关系、多实体同步约束以及隐式时间条件,其整体表现明显逼近更强模型。
这表明,MemoTime有效缓解了小模型在时间知识获取、时间关系对齐和复杂推理组织上的瓶颈。对于较弱模型而言,MemoTime不只是带来了性能提升,更像是补上了它们原本欠缺的时序推理能力,使其在复杂时间问题上不再仅仅依赖有限的参数记忆,而能够结合外部时序知识进行更完整、更有条理的推理。
**同时,较强模型同样能够从MemoTime中持续受益。**虽然它们本身已经具备较强的理解与推理能力,但在涉及严格时间约束的任务上,MemoTime仍然能够进一步提升其推理稳定性和答案可靠性。总体上,MemoTime使不同能力层次的大模型都能进行更深层、更准确的时序知识检索与整合,而不是只依赖模型内部已有的静态知识。
4
研究结论
随着大语言模型逐步走向真实应用场景,如何处理不断变化的知识、如何保证时间敏感任务中的事实一致性,已经成为一个越来越重要的问题。无论是在事件分析、时序问答、动态知识管理,还是在更广泛的智能决策场景中,模型都需要具备对“时间”的理解能力,而不仅仅是对“文本语义”的匹配能力。
MemoTime的提出,为这一方向提供了一种较为完整的解决方案。它不仅关注如何检索到相关知识,更进一步关注这些知识在时间维度上是否一致、是否能够组成完整推理链,以及系统能否从以往推理中积累经验并持续改进。这样的设计使得大语言模型在面对动态世界时,不再只是被动地调用外部知识,大模型不仅“能回答”,更“会按照时间去推理”。

WWW(ACM The Web Conference)是互联网、人工智能和交叉综合领域最具影响力的学术会议之一,同时也是中国计算机学会(CCF)推荐A类国际学术会议,至2026年已成功举办35届。该会议每年汇聚互联网、人工智能、数据挖掘和信息检索等领域全球顶尖学者与业界专家,围绕前沿理论与前瞻技术展开深入交流与思想碰撞。今年Research Track共计投稿3370篇,其中676篇论文被录用,录用率约为20.1%。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献221条内容
已为社区贡献221条内容

所有评论(0)