GraphRAG:构建AI知识库的两大核心阶段,离线构建+在线查询,解锁知识关联新玩法!
本文详细介绍了GraphRAG技术构建AI知识库的两大核心阶段:离线索引构建和在线查询生成。离线阶段通过文本分块、实体关系抽取、知识图谱构建、层级社区检测和社区摘要生成,将非结构化文本转化为结构化知识库;在线阶段根据查询类型选择局部或全局搜索策略,利用构建的索引生成答案,实现多跳推理和宏观感知,提升答案质量和效率。GraphRAG适合金融、医疗等复杂知识管理场景,但构建维护成本高,依赖领域本体设计。
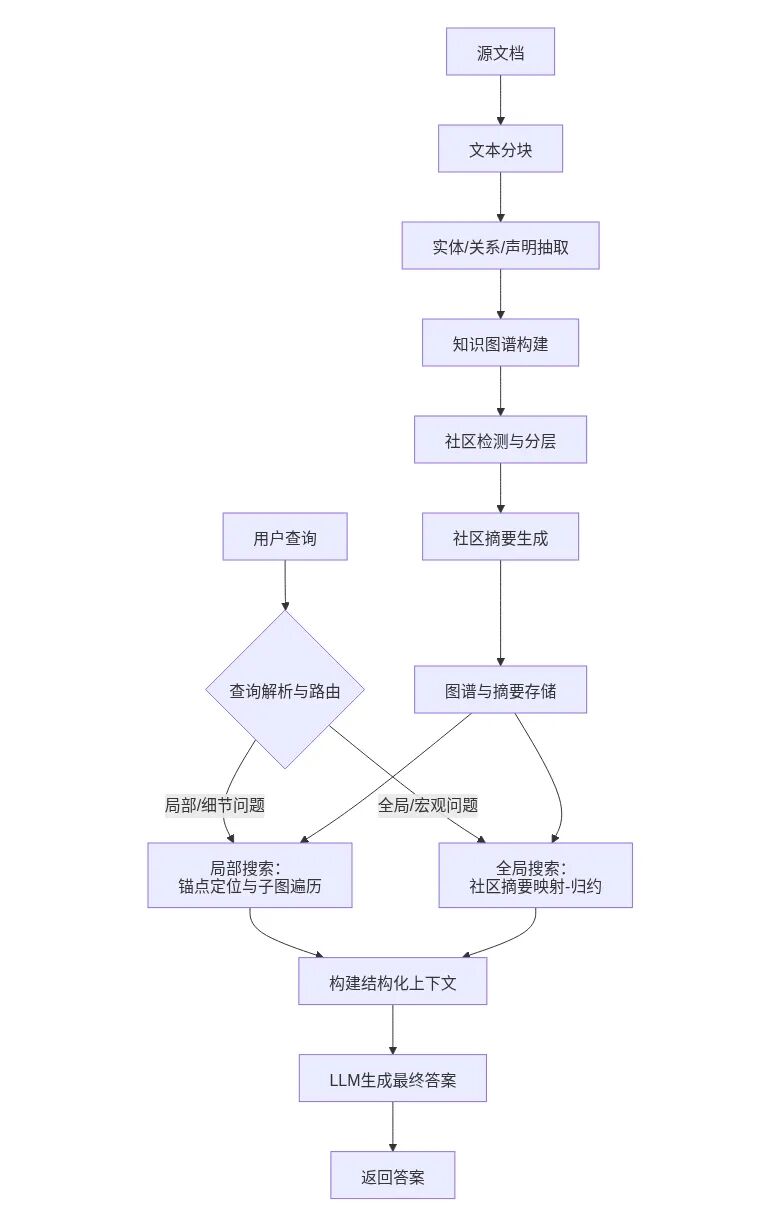
整个流程可分为两大阶段:离线索引构建 和 在线查询生成。
下图概括了其核心数据流:
01
离线索引构建(从文档到结构化知识库)
此阶段的目标是将非结构化文本转化为一个富含语义关系的、层次化的知识库。
步骤 1:源文档 → 文本分块
• 目的:将长文档处理成适合LLM处理的单元。
• 方法:
-
文档被拆分为固定大小(如600 tokens)的文本块,块间保留少量重叠(如100 tokens)以防止信息割裂。
-
平衡LLM调用成本与信息召回率。
- 输出:文本块列表。
步骤 2:文本块 → 实体、关系与声明抽取
• 目的:从文本块中提取结构化信息。
• 方法:
- 使用大语言模型(LLM),配合精心设计的提示词,从每个文本块中提取:
- 实体:如人物、组织、地点、概念、技术术语等。
- 关系:实体之间的语义联系(如“投资了”、“是…的创始人”、“位于”),并为关系赋予强度评分。
- 声明:可验证的事实性陈述(Claims)。
- 通过 “自反思(Self-reflection)” 机制,让LLM检查并减少遗漏。
- 输出:每个文本块对应的实体列表、关系列表和声明列表。
步骤 3:构建知识图谱
• 目的:将抽取的离散信息整合为一张全局图。
• 方法:
- 实体融合:将不同文本块中提到的同一实体进行合并(初期常用精确字符串匹配,高级方案需实体消歧)。实体成为图谱的节点。
- 关系聚合:将描述同一对实体间相同关系的所有实例进行合并,其出现次数可作为边的权重。关系成为图谱的边。
- 声明关联:将声明与相关的实体和关系关联起来,作为图谱的协变量。
• 输出:一个包含节点(实体)、边(关系)和协变量(声明)的知识图谱。
步骤 4:知识图谱 → 层级化社区检测
• 目的:发现图谱中自然形成的主题群落,实现信息的“分而治之”。
• 方法:
- 采用Leiden算法等社区检测算法,对图谱进行分层聚类。
- 流程:
- 在原始图上检测叶社区(C3),社区内连接紧密,数量最多。
- 将每个社区视为一个“超节点”,构建上一层级的图,再次检测,得到父社区(C2)。
- 递归此过程,形成社区层级树,直至根社区(C0),数量最少,代表最宏观的主题。
- 每个层级的社区都完全覆盖所有节点且互不重叠。
- 输出:层级化社区结构(C0, C1, C2, C3)
步骤 5:图社区 → 社区摘要
• 目的:为每个社区生成人类可读的、概括性的描述,作为后续检索的“宏观索引”。
• 方法:自底向上、递归摘要。
- 叶社区(C3)摘要:
- 收集社区内所有实体、关系和声明。
- 按重要性(如节点度)排序,优先将高重要性元素加入LLM上下文。
- 提示LLM生成该社区的标题和摘要。
- 高层社区(如C0)摘要:
- 收集其所有子社区的摘要。
- 如果子社区摘要总长度超出LLM上下文限制,则用更抽象的子社区摘要替换详细内容,或进行截断。
- 提示LLM基于子社区摘要,生成更高层、更概括的标题和摘要。
- 输出:每个社区对应的社区摘要报告。
步骤 6:存储与索引
• 目的:将构建的所有结构化数据持久化,供查询阶段使用。
- 存储内容:
- 图数据库:存储完整的知识图谱(节点、边)和社区成员关系。
- 向量数据库:将社区摘要、实体描述、原始文本块分别向量化存储,以支持相似性检索。
- 元数据存储:记录社区层级、摘要、重要性排名等。
02
在线查询生成(从问题到答案)
此阶段根据用户查询的类型,选择不同的检索策略,利用离线构建的索引生成答案。
步骤 1:查询解析与路由
• 目的:理解用户意图,并选择最合适的检索模式。
• 模式:
- 局部搜索:适用于具体、细节、事实型问题(如“DarwinAI的创始人现在在收购它的公司里担任什么职位?”)。
- 全局搜索:适用于宏观、总结、分析型问题(如“这份文档集主要讨论了哪些技术领域?”)。
- 混合/探索式搜索:适用于模糊、探索性问题,结合多种策略
步骤 2a:局部搜索流程(基于子图遍历)
• 映射(Map):
-
实体识别:用LLM从查询中提取关键实体作为“锚点”。
-
子图检索:在图数据库中,从锚点实体出发,沿关系边进行多跳遍历(如2-3跳),提取出相关的子图。
-
上下文组装:将子图中的实体、关系、以及关联的原始文本片段,组装成结构化的上下文
- 归约(Reduce):
- 将组装好的上下文输入LLM。
- LLM生成针对该查询的局部答案。
步骤 2b:全局搜索流程(基于社区摘要的Map-Reduce)
• 映射(Map):
-
社区相关性评分:将用户查询与所有社区的摘要进行比对(通过向量相似度或LLM判断),筛选出相关社区。
-
并行生成部分答案:为每一个相关社区,将其摘要作为上下文,让LLM独立生成一个针对查询的部分答案,并附上一个相关性评分(0-100
- 归约(Reduce):
- 过滤与排序:过滤掉低分(如0分)的部分答案,并按评分降序排列。
- 迭代合成:将高分部分答案依次加入LLM的上下文窗口,直至达到token限制。
- 最终生成:提示LLM基于所有这些部分答案,合成一个全面、连贯的全局答案。
步骤 3:答案生成与返回
- 最终生成:无论哪种模式,最终都由LLM基于检索到的结构化上下文(来自子图或社区摘要)生成自然语言答案。
- 优势体现:答案不仅包含事实,还能体现实体间的关联,具备更强的逻辑性、全面性和可解释性。
- 返回结果:将最终答案返回给用户。高级系统还可提供答案溯源,展示支撑答案的实体和关系路径。
核心价值
通过上述完整流程,GraphRAG实现了对传统向量RAG的升维打击:
- 解决“信息孤岛”:通过知识图谱连接跨文档的实体,实现多跳推理。
- 实现“宏观感知”:通过社区检测和摘要,获得数据集的全局主题视图,能回答总结性问题。
- 提升答案质量:基于精确的结构化关系网络生成答案,更准确、更全面、幻觉更少。
- 提高Token效率:用高度凝练的社区摘要替代大量原始文本,在回答宏观问题时成本更低。
代价
这一强大能力的背后,是极高的图谱构建与维护成本,以及对领域本体设计和高质量信息抽取的重度依赖。
因此,它最适合应用于金融、医疗、法律、复杂知识管理等对深度关联推理有刚性需求的场景
01
什么是AI大模型应用开发工程师?
如果说AI大模型是蕴藏着巨大能量的“后台超级能力”,那么AI大模型应用开发工程师就是将这种能量转化为实用工具的执行者。
AI大模型应用开发工程师是基于AI大模型,设计开发落地业务的应用工程师。
这个职业的核心价值,在于打破技术与用户之间的壁垒,把普通人难以理解的算法逻辑、模型参数,转化为人人都能轻松操作的产品形态。
无论是日常写作时用到的AI文案生成器、修图软件里的智能美化功能,还是办公场景中的自动记账工具、会议记录用的语音转文字APP,这些看似简单的应用背后,都是应用开发工程师在默默搭建技术与需求之间的桥梁。
他们不追求创造全新的大模型,而是专注于让已有的大模型“听懂”业务需求,“学会”解决具体问题,最终形成可落地、可使用的产品。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

02
AI大模型应用开发工程师的核心职责
需求分析与拆解是工作的起点,也是确保开发不偏离方向的关键。
应用开发工程师需要直接对接业务方,深入理解其核心诉求——不仅要明确“要做什么”,更要厘清“为什么要做”以及“做到什么程度算合格”。
在此基础上,他们会将模糊的业务需求拆解为具体的技术任务,明确每个环节的执行标准,并评估技术实现的可行性,同时定义清晰的核心指标,为后续开发、测试提供依据。
这一步就像建筑前的图纸设计,若出现偏差,后续所有工作都可能白费。
技术选型与适配是衔接需求与开发的核心环节。
工程师需要根据业务场景的特点,选择合适的基础大模型、开发框架和工具——不同的业务对模型的响应速度、精度、成本要求不同,选型的合理性直接影响最终产品的表现。
同时,他们还要对行业相关数据进行预处理,通过提示词工程优化模型输出,或在必要时进行轻量化微调,让基础模型更好地适配具体业务。
此外,设计合理的上下文管理规则确保模型理解连贯需求,建立敏感信息过滤机制保障数据安全,也是这一环节的重要内容。
应用开发与对接则是将方案转化为产品的实操阶段。
工程师会利用选定的开发框架构建应用的核心功能,同时联动各类外部系统——比如将AI模型与企业现有的客户管理系统、数据存储系统打通,确保数据流转顺畅。
在这一过程中,他们还需要配合设计团队打磨前端交互界面,让技术功能以简洁易懂的方式呈现给用户,实现从技术方案到产品形态的转化。
测试与优化是保障产品质量的关键步骤。
工程师会开展全面的功能测试,找出并修复开发过程中出现的漏洞,同时针对模型的响应速度、稳定性等性能指标进行优化。
安全合规性也是测试的重点,需要确保应用符合数据保护、隐私安全等相关规定。
此外,他们还会收集用户反馈,通过调整模型参数、优化提示词等方式持续提升产品体验,让应用更贴合用户实际使用需求。
部署运维与迭代则贯穿产品的整个生命周期。
工程师会通过云服务器或私有服务器将应用部署上线,并实时监控运行状态,及时处理突发故障,确保应用稳定运行。
随着业务需求的变化,他们还需要对应用功能进行迭代更新,同时编写完善的开发文档和使用手册,为后续的维护和交接提供支持。
03
薪资情况与职业价值
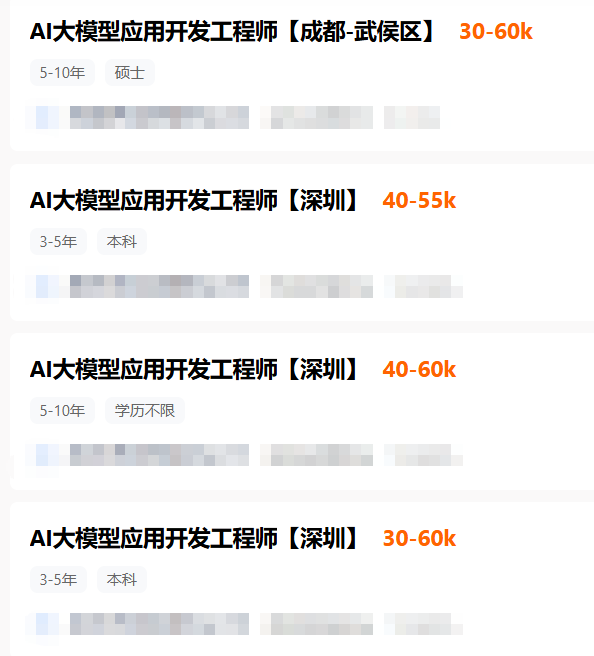
市场对这一职业的高度认可,直接体现在薪资待遇上。
据猎聘最新在招岗位数据显示,AI大模型应用开发工程师的月薪最高可达60k。
在AI技术加速落地的当下,这种“技术+业务”的复合型能力尤为稀缺,让该职业成为当下极具吸引力的就业选择。
AI大模型应用开发工程师是AI技术落地的关键桥梁。
他们用专业能力将抽象的技术转化为具体的产品,让大模型的价值真正渗透到各行各业。
随着AI场景化应用的不断深化,这一职业的重要性将更加凸显,也必将吸引更多人才投身其中,推动AI技术更好地服务于社会发展。
CSDN粉丝独家福利
给大家整理了一份AI大模型全套学习资料,这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献158条内容
已为社区贡献158条内容

所有评论(0)