Knowledge Neurons in Pretrained Transformers

摘要
大规模预训练语言模型在**回忆训练语料中包含的事实性知识**方面表现出惊人的能力(Petroni et al., 2019; Jiang et al., 2020b)。本文通过引入**知识神经元**这一概念,对事实性知识如何存储在预训练 Transformer 中展开初步研究。具体而言,我们以 BERT 模型为对象,在填空式完形任务上进行分析。针对一条关系型事实,我们提出一种知识归因方法,以定位出表达该事实的神经元。实验发现,这类知识神经元的激活程度与其对应事实的表达呈**正相关**。在案例研究中,我们尝试利用知识神经元,**在不进行微调的前提下编辑(如更新、删除)特定事实知识**。本文研究结果有助于理解预训练 Transformer 内部的知识存储机制。代码开源地址:https://github.com/Hunter-DDM/knowledge-neurons。
1 引言
大规模预训练 Transformer 模型(Devlin 等,2019;Liu 等,2019;Dong 等,2019;Clark 等,2020;Bao 等,2020)通常在维基百科等包含海量事实性知识的大规模语料上,以语言建模为目标进行学习。预训练语言模型通过文本预测,天然地充当了一个自由文本形式的知识库(Bosselut 等,2019)。Petroni 等(2019)与 Jiang 等(2020b)采用填空式查询任务,探测了预训练语言模型中存储的事实性知识。评估结果表明,预训练 Transformer 在无需任何微调的情况下,就具备很强的事实知识回忆能力。Roberts 等(2020)通过闭卷问答任务证明,模型规模越大,所能存储的知识就越多。然而,以往大多数工作仅聚焦于评估文本形式知识预测的整体准确率。本文尝试更深入地探究预训练 Transformer,研究其内部事实性知识的存储机制。
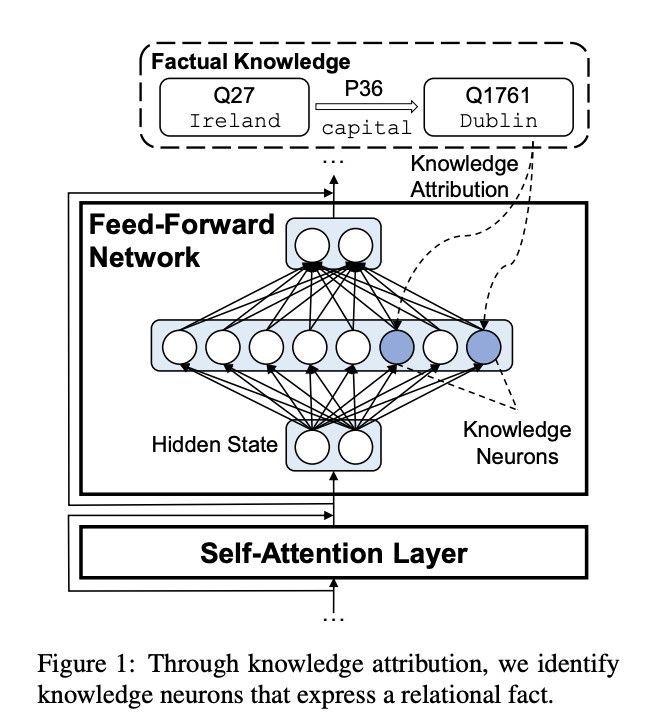
如图 1 所示,我们提出一种**知识归因方法**,用于定位表达关系型事实的神经元,并将这类神经元命名为**知识神经元**。具体而言,我们将 Transformer 中的前馈网络模块(即双层感知机)视作键值记忆结构(Geva 等,2020)。以图 1 中的示例为例,隐状态输入第一层线性层后会激活知识神经元;随后,第二层线性层对对应的记忆向量进行整合。键值记忆的特性(Geva 等,2020)启发我们提出该知识归因方法,通过计算每个神经元对知识预测的贡献度,在前馈网络中定位知识神经元。 大量分析结果表明,所定位的知识神经元的激活程度与知识表达呈**正相关**,验证了所提知识归因方法的有效性。
第一,抑制或增强知识神经元的激活,会显著影响对应事实知识的表达。
第二,我们发现某一事实对应的知识神经元,更容易被表达该事实的提示文本激活。
第三,针对某一事实的知识神经元,从开放域文本中检索得到的高激活度提示文本通常会表达该事实,而低激活度提示文本则不会表达正确的关系。
在案例研究中,我们尝试利用知识神经元,**在不进行任何微调的前提下**,对预训练 Transformer 中的事实性知识进行显式编辑。本文开展了两项初步研究:事实更新与关系擦除。在定位知识神经元后,我们通过直接修改前馈网络中的对应参数,对预训练 Transformer 执行**知识手术**。该编辑方式取得了良好效果,且对其他知识仅产生适度影响。 本文贡献总结如下:
- 提出**知识神经元**概念,并设计一种知识归因方法,在填空任务中定位表达特定事实知识的知识神经元。
- 从定性与定量两方面展开分析,证明知识神经元的激活与知识表达呈正相关。
- 开展初步探索,验证可借助知识神经元在**无需微调**的情况下编辑 Transformer 中的事实知识。
2 背景:
Transformer Transformer(Vaswani et al., 2017)是目前最流行、最有效的自然语言处理架构之一。Transformer 编码器由 **L 个相同的模块堆叠**而成。每个 Transformer 模块主要包含两个组件:**自注意力模块**和**前馈网络模块**(简称 FFN)。 设输入矩阵为 $X \in \mathbb{R}^{n \times d}$,两个组件可形式化表示如下:
(2)
(3) 其中:
为参数矩阵;
表示单个注意力头的计算; 隐状态
由所有注意力头拼接后投影得到;
为 GELU 激活函数(Hendrycks and Gimpel, 2016)。 为简化表达,我们省略了自注意力中的缩放因子和偏置项。
自注意力与 FFN 的联系 对比式 (2) 与式 (3) 可以发现,FFN 的形式与自注意力十分相似,区别仅在于 FFN 使用 GELU 激活,而自注意力使用 Softmax。 因此,类比自注意力中的**查询‑键‑值(QKV)机制**,可以合理地将: - FFN 的输入看作**查询向量** - FFN 的两层线性层分别看作**键**和**值** 类似的观点在 Geva et al. (2020) 中也有论述。
3 知识神经元的识别
与 Geva 等人(2020)的工作类似,我们将 Transformer 中的前馈网络(FFN)视作**键值记忆结构**,如图 2 所示。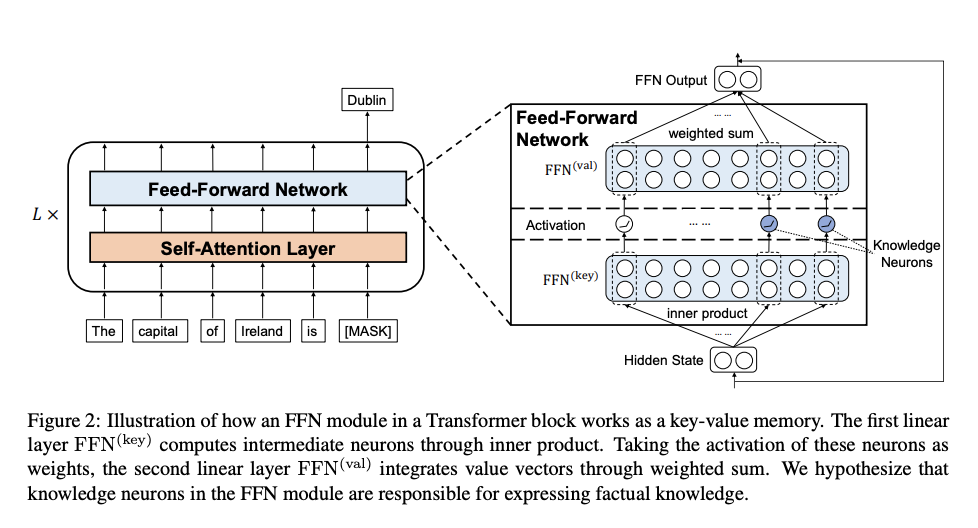 我们假设:事实性知识存储在前馈网络的记忆中,并由**知识神经元**进行表达。在本节中,我们提出一种**知识归因方法**与一套**提纯策略**,用于定位这些知识神经元。
我们假设:事实性知识存储在前馈网络的记忆中,并由**知识神经元**进行表达。在本节中,我们提出一种**知识归因方法**与一套**提纯策略**,用于定位这些知识神经元。
3.1 知识评估任务
我们采用**填空完形任务**来评估预训练模型是否掌握某条事实。遵循 Petroni 等人(2019)的设定,每条关系型事实表示为三元组 ,其中 h 为头实体,t 为尾实体,r 为二者之间的关系。 给定一条事实,预训练模型根据表达该事实、但将尾实体留空的完形查询 x 进行作答。
例如,对事实 $\langle\text{爱尔兰}, \text{首都}, \text{都柏林}\rangle$,对应的查询可以是:“爱尔兰的首是____。”我们也将这类查询称为**知识表达提示**。 Petroni 等人(2019)认为,如果模型能预测出正确答案,就说明它掌握了该事实。在本文中,我们不只检验模型输出,还进一步定位**表达该事实知识的特定知识神经元**。
3.2 知识归因
受 Hao 等人(2021)启发,我们基于**积分梯度**(Sundararajan et al., 2017)提出一种知识归因方法,用于评估每个神经元对知识预测的贡献。本文重点分析**掩码位置**(即答案预测位置)对应的前馈网络中间神经元。 给定输入提示 x,我们首先将模型输出 定义为预训练模型预测正确答案的概率:
(4)
其中 表示正确答案;
表示第 l 层前馈网络中的第 i 个中间神经元;
是为该神经元指定的常量取值。 为计算神经元的归因分数
,我们将
的值从 0 逐步变化到由预训练模型计算得到的原始值,并对梯度进行积分:
(5)
其中 表示模型输出关于神经元
的梯度。直观上,随着
从 0 变到 1,通过积分梯度,
累计了由神经元取值变化带来的输出概率变化。如果某个神经元对事实表达有重要影响,其梯度会较为显著,进而得到较大的积分值。因此,归因分数可以衡量神经元
对事实表达的贡献程度。 直接计算连续积分难以实现,我们改用黎曼近似:
其中近似步数 $m=20$。 借助该归因算法,我们可以选取归因分数大于阈值 t 的神经元,得到一个**粗选知识神经元集合**。
3.3 知识神经元提纯
为更精准地定位知识神经元,我们进一步提出**提纯策略**。粗选集合中除了表达事实知识的“真阳性”知识神经元外,还可能包含表达句法、词汇等其他信息的“假阳性”神经元。提纯策略的目标就是滤除这类假阳性神经元。 我们假设:对应同一条事实的不同提示,会共享同一套**真阳性知识神经元**,因为它们表达相同的事实;而只要提示足够多样化,它们就不会共享假阳性神经元。因此,给定多条多样化提示,我们可以只保留在这些提示中广泛共有的神经元,从而提纯知识神经元集合。 具体而言,给定一条关系型事实,识别其知识神经元的完整流程如下:
1. 生成 n 条多样化提示;
2. 对每条提示,计算神经元的知识归因分数;
3. 对每条提示,保留归因分数大于阈值 $t$ 的神经元,得到粗选知识神经元集合;
4. 综合所有粗选集合,只保留在超过 $p\%$ 的提示中共同出现的知识神经元。
4 实验
4.1 实验设置
我们在**BERT-base-cased**(Devlin et al., 2019)上开展实验,这是应用最广泛的预训练模型之一。该模型包含 12 层 Transformer 模块,隐层维度为 768,前馈网络(FFN)内部隐层维度为 3072。值得注意的是,本文方法并不局限于 BERT,可轻松扩展到其他预训练模型。 对每条提示文本,我们将归因阈值 \(t\) 设为最大归因分数的 0.2 倍。针对每种关系,我们先将提纯阈值 \(p\%\)(3.3 节)初始化为 0.7,之后以 0.05 为步长上调或下调,直到知识神经元的平均数量落在区间 [2, 5] 内。 实验在 **NVIDIA Tesla V100** GPU 上运行。平均而言,对一条包含 9 条提示的关系型事实,识别其知识神经元耗时 13.3 秒。
4.2 数据集
我们基于 **PARAREL** 数据集(Elazar et al., 2021),通过填空完形任务探究知识神经元。PARAREL 由专家标注构建,包含来自 T-REx 数据集(ElSahar et al., 2018)的 38 种关系对应的多种提示模板。表 1 展示了部分模板示例。 对每条关系型事实,我们在提示模板中填入头实体,并将尾实体留空以待模型预测。为保证模板多样性,我们剔除提示模板少于 4 个的关系,最终保留 34 种关系,每种关系平均对应 8.63 个不同提示模板。这些模板共为 27738 条关系型事实生成了 253448 条知识表达提示。
4.3 归因基准方法
本文选用的基准方法以**神经元激活值**作为归因分数,即:该方法用于衡量神经元对输入的敏感程度。计算完归因分数后,我们采用与本文方法相同的流程得到提纯后的知识神经元。为保证公平对比,我们使用相同方式为基准方法选取超参数 \(t\) 和 \(p\%\),确保每种关系对应的知识神经元平均数量落在 [2, 5] 区间内。 基于神经元激活的方法是合理的基准,其动机源于前馈网络与自注意力机制的类比(见第 2 节),因为自注意力分数通常被用作强有力的归因基准(Kovaleva et al., 2019; Voita et al., 2019; Hao et al., 2021)。
4.4 知识神经元统计分析
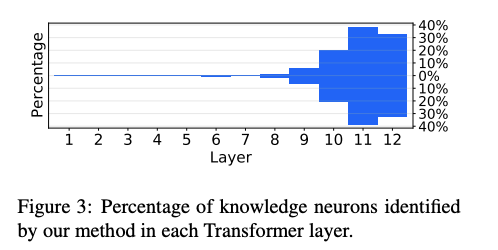
图 3 展示了本文知识归因方法所识别出的知识神经元的层分布情况。我们发现,大多数与事实相关的神经元分布在预训练 Transformer 的**最顶层**,这一结论与 Tenney et al. (2019) 和 Geva et al. (2020) 的发现一致。 表 2 给出了知识神经元的统计结果。
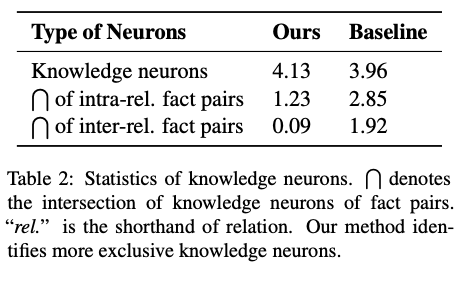
平均而言,本文方法为每条关系型事实识别出 4.13 个知识神经元,基准方法为 3.96 个。二者数量级相近,保证了本文后续对比实验的公平性。 我们还计算了不同关系型事实之间知识神经元的交集数量。表 2 展示了事实对之间知识神经元交集的平均数量。对于本文方法:
1. 具有相同关系的事实对(关系内事实对)平均共享 1.23 个知识神经元;
2. 具有不同关系的事实对(关系间事实对)几乎不共享知识神经元。 与之相对,基准方法:
3. 大多数识别出的神经元会被关系内事实对共享;
4. 甚至有相当一部分神经元为关系间事实对所共有。
知识神经元交集上的差异表明,本文方法能够识别出**更具专属特性**的知识神经元。
4.5 知识神经元对知识表达的影响
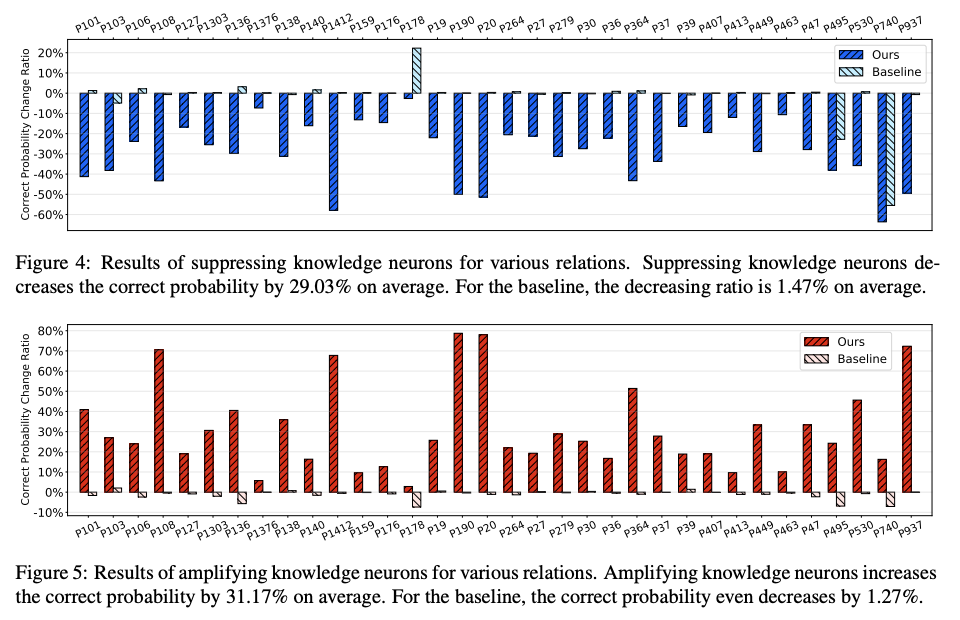
在图 4 和图 5 中,我们研究了知识神经元对知识表达的影响程度。给定一条关系型事实,我们以两种方式操纵其知识神经元: 1. **抑制**知识神经元:将其激活值置为 0; 2. **增强**知识神经元:将其激活值翻倍。 随后,针对每种关系,我们绘制正确答案预测概率在操纵后的平均变化率。作为对比,我们同时绘制操纵基准方法识别出的知识神经元所得到的结果。
图 4 显示,抑制本文方法识别出的知识神经元会使正确概率**持续下降**(平均下降 29.03%)。相比之下,抑制基准方法识别的神经元对正确概率几乎没有影响(平均仅下降 1.47%)。值得注意的是,在 P178(开发者)关系上,操纵基准神经元反而使正确概率反常上升。 如图 5 所示,增强本文方法识别的知识神经元时可观察到类似规律:正确概率**持续上升**(平均提升 31.17%);而基准方法甚至使平均正确概率下降 1.27%。 综上,本文知识归因方法识别出的知识神经元能够**显著影响知识表达**。需要说明的是,上述评估结果会受知识神经元分布的影响。例如,如果某一关系对应的知识神经元分布更分散,则需要操纵更多的 Top-k 神经元以实现更好的控制效果。本文实验仅作为概念验证,更精确的控制将留待未来工作研究。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)