扩散模型(Diffusion Models)
扩散模型(Diffusion Models)是近年来在深度生成模型领域取得显著成功的一类模型,尤其在图像生成方面表现突出。扩散模型是一类生成模型,通过逐步添加噪声(正向过程)和逐步去噪(反向过程)生成数据。其核心思想源于非平衡统计物理中的扩散过程:想象一滴墨水滴入水中,墨水分子会逐渐扩散开来,直至均匀分布在整个水体中。扩散模型模拟了这个过程的逆向——从随机噪声中逐步“去噪”,生成出具有清晰结构的样本,即模拟数据从有序到无序的扩散过程,再通过学习逆向过程实现数据生成。
一.核心原理
扩散模型通常包含两个关键过程:1.正向扩散过程(加噪声):这是一个逐步加噪的过程。即,清晰图片——一点点加高斯噪声——纯噪声。2.反向去噪过程(生成过程):这是一个逐步去噪的过程,也是模型学习的目标。即,训练一个网络——输入噪声图片,预测噪声——把噪声去掉。然后反复去噪。从纯噪声开始,一步步去噪声,最终生成清晰图片。
Diffusion Model的过程如下:开始输入一张纯噪声的图片,并一步一步将噪声过滤掉一点,最终得到一张清晰的图片。这其中的Denoise模型是反复使用的,去噪过程的总步数是预先定义好的(比如常见的 1000 步),每一个step会对应一个 “步数编号”。由于过程中每一次输入的图片噪声情况不同,所以反复使用同一个模型的结果未必很好,因此每次输入时除了图片还要有一个time embedding(时序嵌入),这里的time embedding与噪声权重有关,值越大代表噪声权重越大(噪声越严重)。
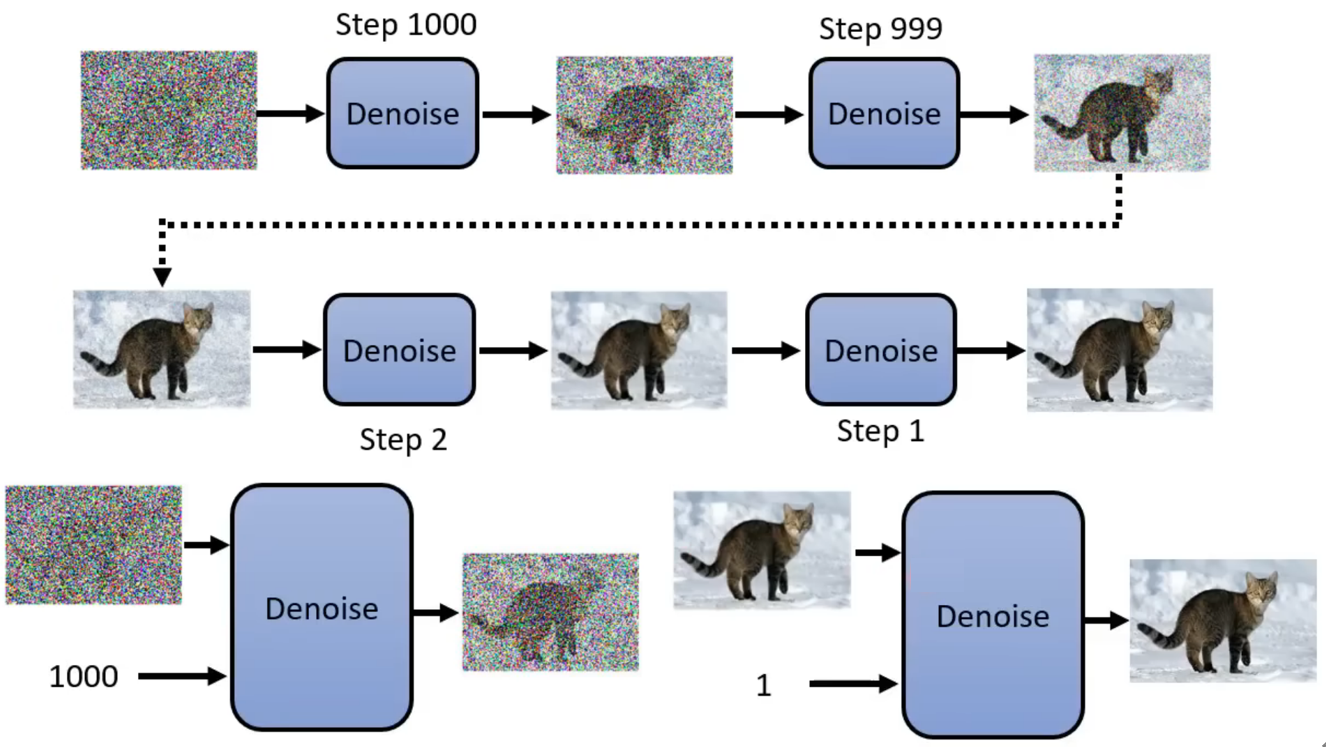
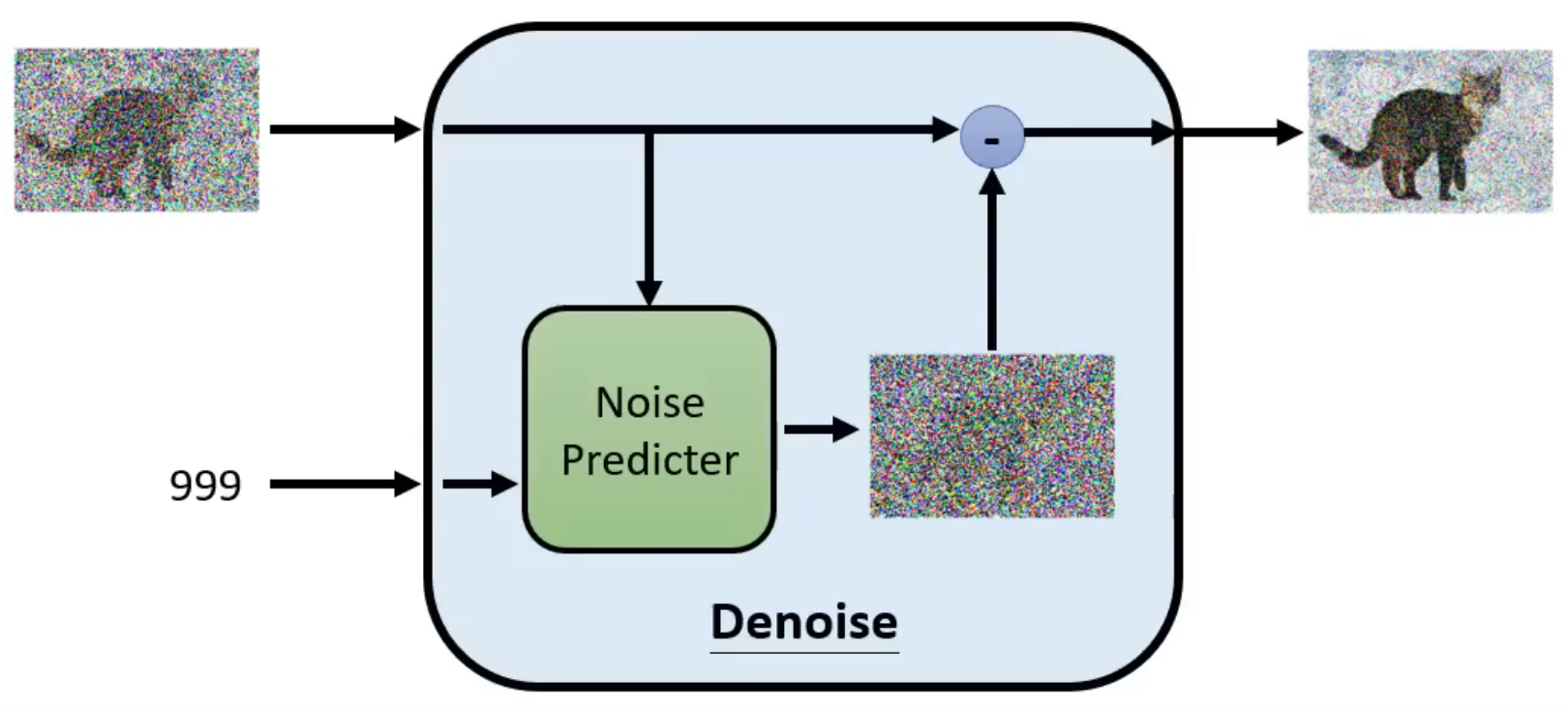
Denoise模型内部的实现如下:Denoise内部有一个Noise Predicter,接收输入图片和time embedding,并预测输出这张输入图片的噪声情况,再使用输入图片减去预测的噪声,最终得到输出结果。
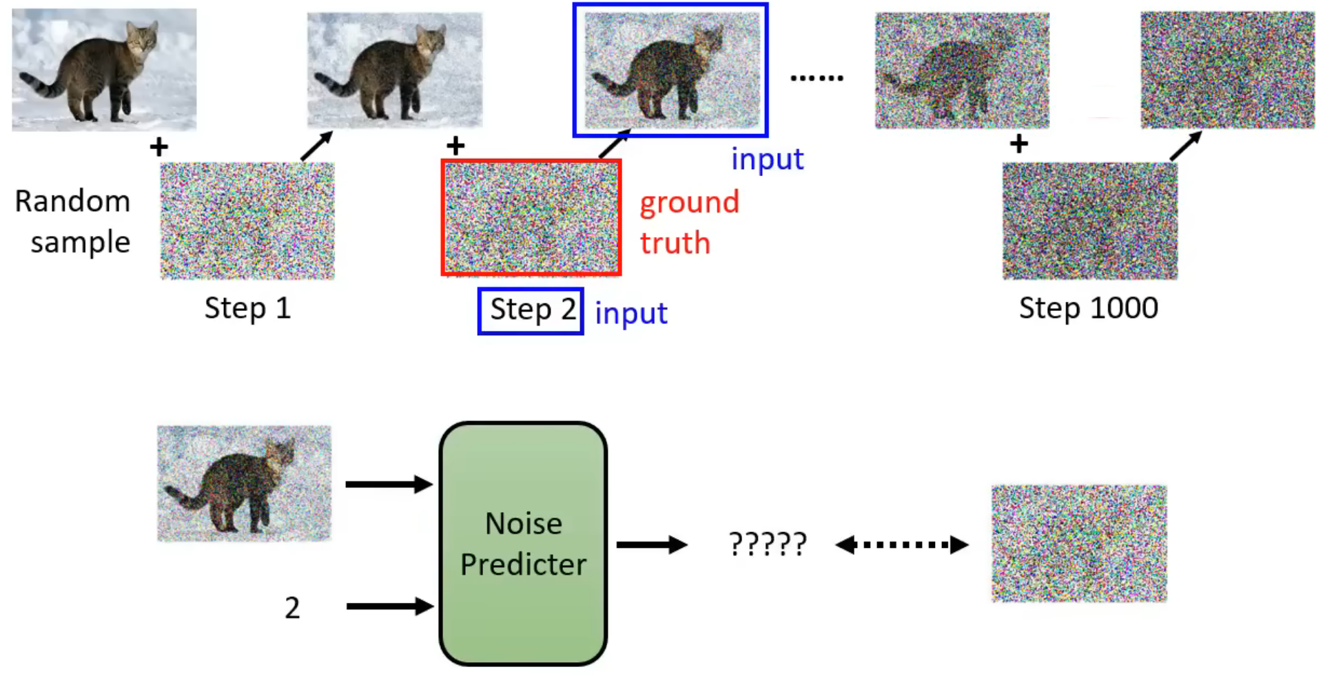
那么如何训练Noise Predicter?从database中取出一张图像,加入噪声后产生带有噪声的输出图像,不断重复这个过程,最终得到一个纯噪声图像。这也就是正向扩散的过程。而对于Noise Predicter需要学会的就是,认识到这张加完噪声的图片与当前的step是Denoise模型输入,而其中加入的噪声信息就是这个网络应该预测的噪声输出。因此,在进行正向扩散的步骤之后,Noise Predicter就已经学会如何预测噪声。
二.数学表示
这是DDPM(Denoising Diffusion Probabilistic Models)模型的过程,其核心是两个互逆的马尔可夫链:
-
前向扩散(Forward Diffusion):从原始图像
出发,逐步添加高斯噪声,经过 T 步后得到纯噪声
(T 通常取 1000);
-
反向扩散(Reverse Diffusion):从纯噪声

下面先明确核心符号定义:
| 符号 | 数学意义 |
|---|---|
| T | 扩散总步数 |
| 第 t 步的噪声强度(前向扩散参数) | |
| 第 t 步的权重系数 | |
| 前 t 步的累积权重系数 | |
| ε | 标准高斯噪声(ε∼N(0,I)) |
| 第 t 步的带噪图像 | |
| 模型预测的噪声 |
1.Training 正向扩散(加噪声):

其中 表示从真实样本中抽取的干净图片,t 为添加噪声的次数,
为噪声,
为权重,根据第5步的公式可以看出,t 越大
值越小,等价于
越小
越大。因此对应前面提到的t 越大噪声越严重(权重越大)。随着t 增大,最终的输出
越接近纯噪声。
因此,DDMP并不是简单的一步一步加入噪声进行训练,而是进行加权。

1.1前向扩散的核心数学公式
(1)单步加噪公式

(2)闭式解(从 直接得到
)

(3)前向过程的概率分布

2.Sampling 逆向扩散(去噪声):

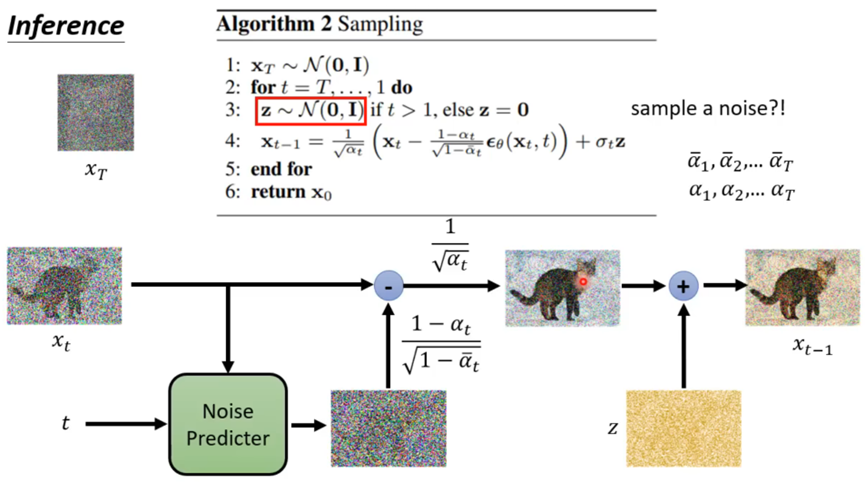
其中,为纯噪声,
为上一步骤产生的图。
(
,t)为Noise Predicter输出的预测噪声,进行加权后,用于从
中减去噪声,得到更清晰的
。
2.1逆向扩散的核心数学公式


3.损失函数的数学原理
扩散模型的训练目标是最小化反向过程与前向过程的 KL 散度,但通过数学推导可简化为预测噪声与真实噪声的均方误差(MSE),这是 DDPM 的核心简化技巧,让训练变得高效。
3.1损失函数的数学推导

4.核心公式作用

三.与GAN、VAE的对比
| 维度 | DDPM (扩散模型) | GAN (生成对抗网络) | VAE (变分自编码器) |
|---|---|---|---|
| 核心思想 | 先逐步加噪破坏数据,再学习逆向去噪重建 | 对抗训练:生成器 vs 判别器,互相博弈 | 编码器压缩数据到隐空间,解码器从隐空间重建 |
| 训练目标 | 最小化预测噪声与真实噪声的 MSE | 最小化生成器损失,最大化判别器损失(对抗) | 最大化证据下界(ELBO),平衡重构与 KL 散度 |
| 训练稳定性 | ✅ 极稳定,几乎不模式崩溃 | ❌ 不稳定,易模式崩溃、梯度消失 / 爆炸 | ✅ 稳定,训练过程平滑 |
| 生成质量 | ✅ 极高,细节丰富、真实感强 | ⚠️ 早期质量高,但易模式崩溃;现代 GAN 仍很强 | ❌ 通常偏模糊,细节不足 |
| 生成速度 | ❌ 慢(原生需 1000 步采样),但可通过 DDIM/LCM 加速 | ✅ 一步生成,速度快 | ✅ 一步生成,速度快 |
| 可控性 | ✅ 强(条件扩散、CFG、ControlNet 等) | ⚠️ 中等,条件 GAN 可控制但不如扩散灵活 | ⚠️ 弱,隐空间插值可控性有限 |
| 数学框架 | 概率扩散、马尔可夫链 | 博弈论、极小极大优化 | 变分推断、概率图模型 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)