【kaggel房价预测】Housing Prices Competition for Kaggle Learn Users
1. 数据加载及预处理
1.1 数据导入
导入库,传入input中的data文件路径,获取data集的形状
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.utils.data import TensorDataset, DataLoader
BASE_PATH = "/kaggle/input/competitions/home-data-for-ml-course"
train_data=pd.read_csv(f"{BASE_PATH}/train.csv")
test_data=pd.read_csv(f"{BASE_PATH}/test.csv")
print(train_data.shape)
print(test_data.shape)然后打印前4行的前4后3列看看
print(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])去掉第一列id,合并数据集
all_features=pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))1.2 Z-score 标准化处理数值型data
对于数值型data,将所有缺失值替换为相应特征的平均值,通过将特征重新缩放到零均值和单位方差来标准化数据, 对于数值型的特征,apply一个标准化的x等于x减去每一列均值除以方差,注意这里是训练和测试一起算均值方差, 未采样的特征数据填充为均值0
numeric_features=all_features.dtypes[all_features.dtypes!='object'].index
all_features[numeric_features]=all_features[numeric_features].apply(lambda x:(x-x.mean())/(x.std()))
all_features[numeric_features]=all_features[numeric_features].fillna(0)1.3 独热编码处理非数值型data
对于字符串data,处理离散值,用一次独热编码替换他们,dummy是not a number,即NA的话,也加入到一个特别的类中
all_features=pd.get_dummies(all_features,dummy_na=True)
all_features.shape
all_features = all_features.astype(float)1.4 数据转换为张量
把 pandas 数据 变成 PyTorch 张量(Tensor),给模型训练用
pandas(表格工具)
-
存的是 DataFrame / 表格
-
用来处理数据、清洗、归一化、拼接
-
不能用来训练神经网络
Tensor(PyTorch 张量)
-
是 神经网络能看懂的格式
-
本质 = 数字数组
-
模型训练、预测 必须用张量
从pandas格式中提取numpy格式,并将其转换为张量表示,shape(0)表示行数,n_train记录训练集行数,以便于切分,.reshape(-1, 1)把房价这一预测标签从一维数据转换为二维数据,-1表示自动计算行数,1表示1列,也就是读取成横着的再转成竖着的
n_train=train_data.shape[0]
train_features =torch.tensor(all_features[:n_train].values,dtype=torch.float32)
test_features =torch.tensor(all_features[n_train:].values,dtype=torch.float32)
train_labels =torch.tensor(train_data.SalePrice.values.reshape(-1,1),dtype=torch.float32)
print(train_features.shape)
print(test_features.shape) 2. 定义损失函数和训练模型
2.1 定义损失函数和输入特征值数量
loss=nn.MSELoss()#定义损失函数为均方误差函数
in_features=train_features.shape[1]#输入特征的量有多少列就有多少个输入2.2 定义训练模型
以下两种模型只需要选择一种,首先是最简单的是单层线性回归模型
def get_net():#一个最简单的线性网络
net=nn.Sequential(nn.Linear(in_features,1))
return net 其次,为了降低loss还可以选择深度神经网络MLP模型
def get_net():
in_features = train_features.shape[1]
net = nn.Sequential(
nn.Linear(in_features, 512),
nn.ReLU(),
nn.Dropout(0.3), # 防止过拟合
nn.Linear(512, 128),
nn.ReLU(),
nn.Linear(128, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
return net2.3 定义RMSE损失
对于房价来讲,更关心相对误差(真实值减去预测值除以真实值),普通的真实值减去预测值的误差不能用,以免房价高的房子误差占比高,解决这一问题的一种方法是用价格预测的对数来衡量误差
def log_rmse(net,features,labels):
clipped_preds=torch.clamp(net(features),1,float('inf'))
rmse=torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse.item()3. 添加Adam优化器
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
# 初始化训练/测试损失列表(存储log-RMSE)
train_ls, test_ls = [], []
# 加载训练数据迭代器(按batch_size分批次)
train_dataset = TensorDataset(train_features, train_labels)
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 定义Adam优化器,带权重衰减(L2正则化)
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate,
weight_decay=weight_decay)
for epoch in range(num_epochs):
# 遍历每个batch
for X, y in train_iter:
optimizer.zero_grad() # 梯度清零
l = loss(net(X), y) # 前向传播计算损失
l.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
# 记录当前epoch在训练集上的log-RMSE
train_ls.append(log_rmse(net, train_features, train_labels))
# 如果提供了测试集,记录测试集上的log-RMSE
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
# 返回训练/测试过程的损失曲线
return train_ls, test_ls4. 添加K折交叉验证
def get_k_fold_data(k, i, X, y):
# 断言k必须大于1,否则无法进行交叉验证
assert k > 1
# 计算每一折的样本数量(向下取整)
fold_size = X.shape[0] // k
# 初始化训练集
X_train, y_train = None, None
# 遍历k个折
for j in range(k):
# 计算当前折的切片索引
idx = slice(j * fold_size, (j + 1) * fold_size)
# 取出当前折的特征和标签
X_part, y_part = X[idx, :], y[idx]
# 如果是第i折,则作为验证集
if j == i:
X_valid, y_valid = X_part, y_part
# 如果训练集还为空,则当前折作为训练集的起始部分
elif X_train is None:
X_train, y_train = X_part, y_part
# 否则将当前折拼接到训练集中
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
# 返回划分好的训练集和验证集
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):
# 初始化训练/验证误差累加和
train_l_sum, valid_l_sum = 0, 0
# 遍历k个折
for i in range(k):
# 获取第i折的训练/验证数据
data = get_k_fold_data(k, i, X_train, y_train)
# 初始化模型
net = get_net()
# 训练模型,返回每轮epoch的训练/验证log-RMSE
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
# 累加最后一轮epoch的训练误差
train_l_sum += train_ls[-1]
# 累加最后一轮epoch的验证误差
valid_l_sum += valid_ls[-1]
# 仅在第0折时绘制学习曲线(避免重复绘图)
if i == 0:
plt.figure(figsize=(7, 4))
plt.plot(range(1, num_epochs+1), train_ls, label='train')
plt.plot(range(1, num_epochs+1), valid_ls, label='valid')
plt.xlabel('epoch')
plt.ylabel('rmse')
plt.xlim(1, num_epochs)
plt.yscale('log')
plt.legend()
plt.show()
# 打印当前折的训练/验证误差
print(f'fold {i + 1}, train log rmse {float(train_ls[-1]):f}, '
f'valid log rmse {float(valid_ls[-1]):f}')
# 返回k折的平均训练/验证误差
return train_l_sum / k, valid_l_sum / k5. 模型训练
# 超参数设置
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.005, 0.0005, 64
# 执行5折交叉验证
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
# 打印平均结果
print(f'{k}-折验证:平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')6. 结果预测及提交
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
# 初始化模型
net = get_net()
# 在完整训练集上训练模型(无验证集)
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
# 绘制训练过程的log-RMSE曲线
plt.figure(figsize=(7,4))
plt.plot(np.arange(1, num_epochs+1), train_ls)
plt.xlabel('epoch')
plt.ylabel('log rmse')
plt.xlim(1, num_epochs)
plt.yscale('log')
plt.show()
# 打印最终训练误差
print(f'train log rmse {float(train_ls[-1]):f}')
# 对测试集进行预测,并将张量转为numpy数组
preds = net(test_features).detach().numpy()
# 将预测结果填入测试集的SalePrice列
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
# 拼接Id与预测结果,生成提交格式
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
# 保存为CSV文件,用于Kaggle提交
submission.to_csv('submission.csv', index=False)
# 调用函数执行训练与预测
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)7.调参及最终成果展示
使用单层模型rmse降低到0.16左右,提交分数为21358(越低越好)
单层模型的学习率可以设的稍微大点,收敛的更快
继续调整参数降低rmse到0.14左右,继续提交分数为19000
改用深度神经网络继续调节参数后,rmse进一步降低到了0.10左右
7.1最近一次训练结果
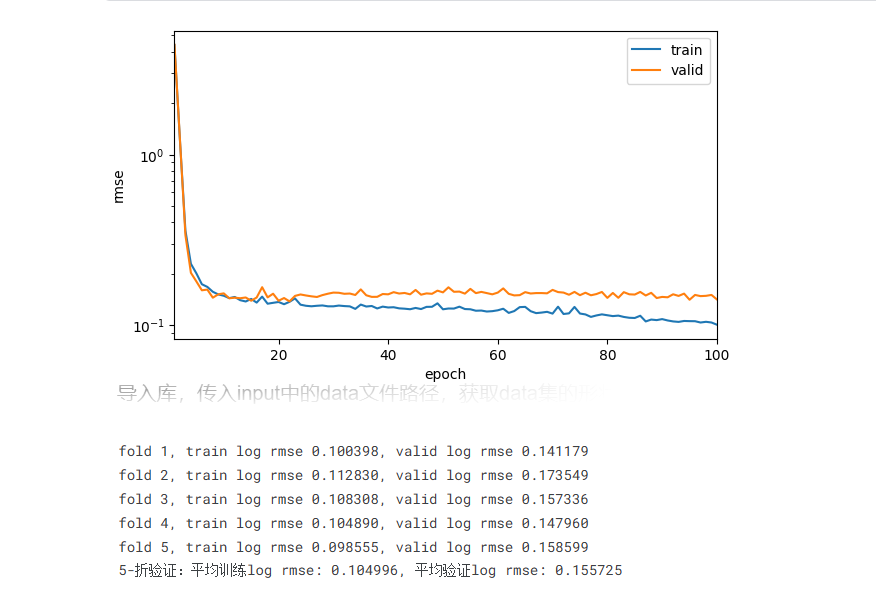
7.2最近一次RMSE预测误差
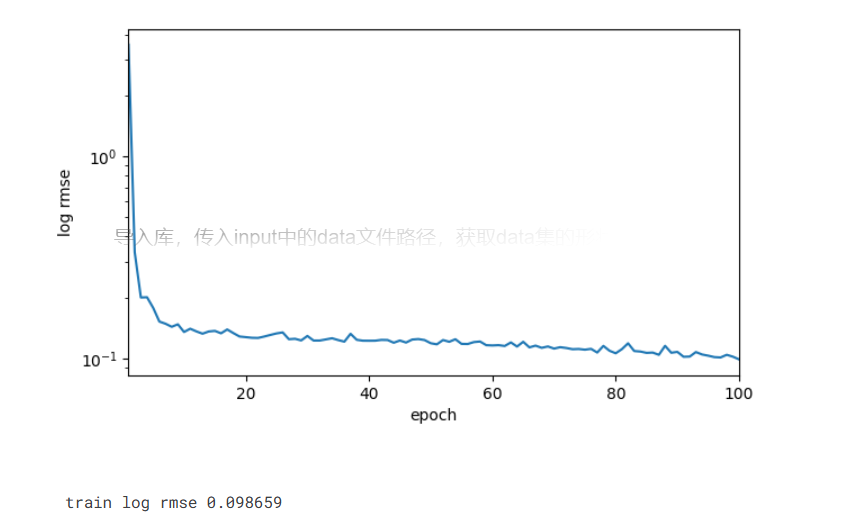
7.3最近一次提交分数
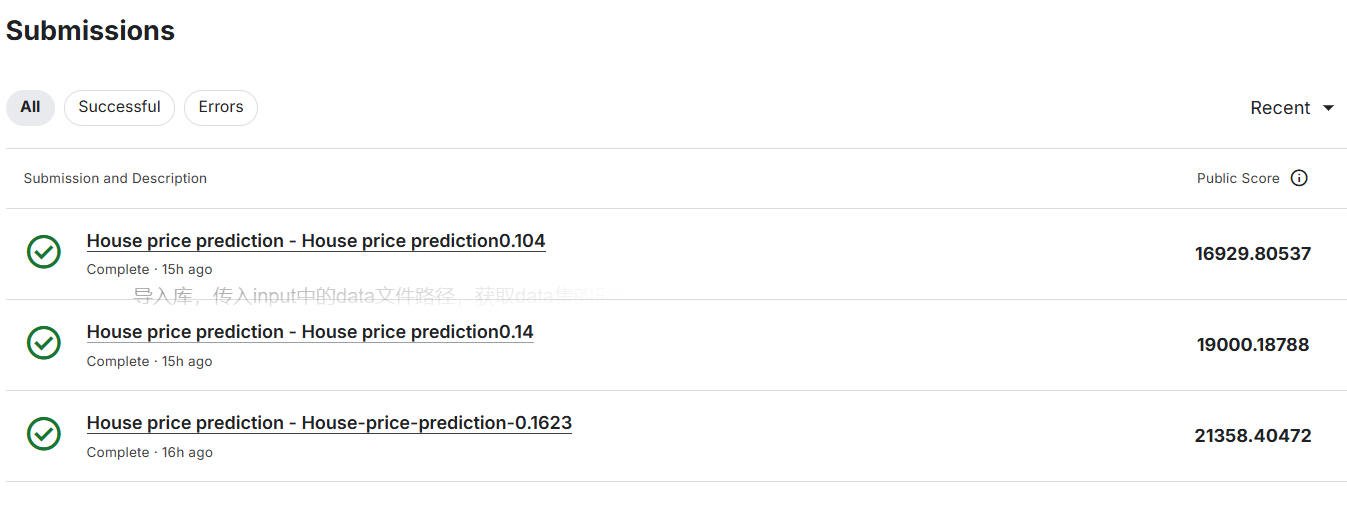
排名提升至2045左右
 后续还可以继续调节超参数进行优化
后续还可以继续调节超参数进行优化
8.一些细节方面的学习总结
8.1训练具体的执行过程
1. 先设置超参数
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 8, 0.01, 64
2. 然后调用 k_fold → 这里开始触发训练
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
3. k_fold 内部调用 train()
train_ls, valid_ls = train(net, *data, ...)
4. 真正开始训练(epoch 循环 + 反向传播)
进入 train() 函数里的这一段:
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step() 
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)