AI学习笔记一
一,分类和回归
1,分类(classification)
预测 “类别”,结果是离散的、有限的、有标签的。
2,回归(regression)
预测 “数值”,结果是连续的、无限的。
3,总结
分类和回归是ai研究的基本两个方向。
二,KNN算法
1,KNN算法本质
我认为knn算法的本质是基于概率学的统计,在有足够标本量的情况下,选择与目标feature最相近的几个标本量feature进行概率学统计,用已知的label推算,其算法依赖于样本量的选择,样本数据的质量,是一种简单的仿AI算法模型。
2,KNN算法python实现
import numpy as np
import collections as cl
data=np.array([
[253,2],
[198,1],
[278,4],
[124,2],
[234,3]
])
feature=data[:,0]
label=data[:,-1]
P_point=241
distance=list(map(lambda x:abs(P_point-x),feature))
sortindex=np.argsort(distance)
sortedlabl=label[sortindex]
k=3
P_result=cl.Counter(sortedlabl[0:k]).most_common(1)[0][0]
print(P_result)在这里涉及到数据分析,所以选择使用array数组,基本逻辑为将与P_point最近的几个已知feature按照从小到大的方式排列,选择前3个feature进行概率学分析,选择最常出现的label作为预测的结果。
import numpy as np
import collections as cl
data=np.loadtxt('data.csv',delimiter=',',skiprows=1)
def knn(k,P_point,feature,label):
distance=list(map(lambda x:abs(P_point-x),feature))
sortindex = np.argsort(distance)
sortedlabl = label[sortindex]
return(cl.Counter(sortedlabl[0:k]).most_common(1)[0][0])
if __name__=='__main__':
data = np.loadtxt('data.csv', delimiter=',', skiprows=1)
feature = data[:, 0]
label = data[:, -1]
P_point =300
k=3
print(knn(k,P_point,feature,label))将其抽象为函数,便于适配不同的数据集。
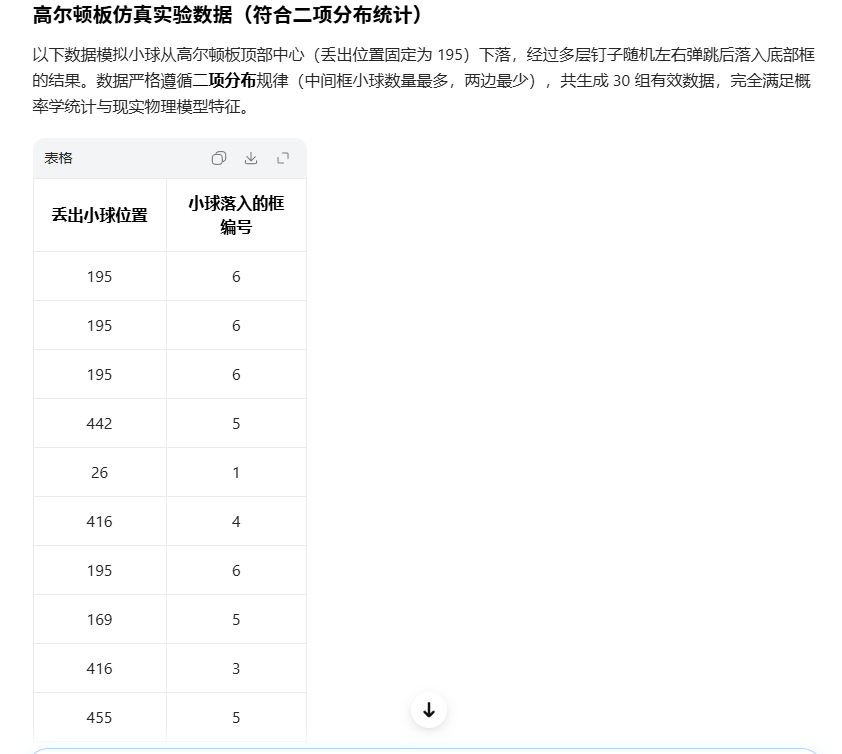
这里我让豆包生成了符合统计学规律的数据集,以300为目标feature进行预测得到了4
这与ai模拟的符合概率学的现实情况吻合,这说明模型具有一定的参考价值。
3,评估KNN模型好坏
for k in range(1,100):
print("k={},P_point={}".format(k,knn(k,P_point,feature,label)))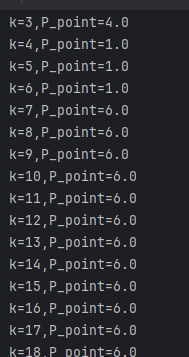
改动后发现随着k的变化,预测的位置也开始变化,可以看出,k的选取是影响knn模型好坏的关键要素。那么如何找出最适合的k呢,在这里采用testData和trainData比对的方式(前提是两个数据集合中的数据具有现实参考价值)
(np.random.shuffle(data))
testdata=data[:100]
traindata=data[100:-1]
np.savetxt('traindata.csv',traindata,delimiter=',',fmt='%d')
np.savetxt('testdata.csv',testdata,delimiter=',',fmt='%d')使用shuffle方法将收集到的数据集合打散,其中testData与trainData的数量比大概为1:10
之后将基于trainData数据集的训练预测结果与testData实际情况相比较,计算准确率,同时改动k的值,观察准确率变化,得到最适合的k值。
for k in range(1,100):
count=0
for itme in teatdata:
prediction=knn(k,itme[0],feature,label)
real=itme[1]
if prediction==real:
count+=1
print("k={},准确率:{}%".format(k,count*100.0/len(teatdata)))
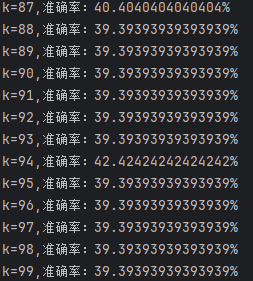
根据多次实验总结,选择训练数据集的开平方为k值可以得到较高的准确率。
4,增加数据维度,提高准确率
在实际情况下,影响label的结果可能很多,比如在本模型下的feature为小球下落的位置,label为小球落入的框,在实际情况下,小球的直径,颜色,弹性等等要素都会影响小球的落点,实际操作中可以增加数据的维度让预测的结果更准确。
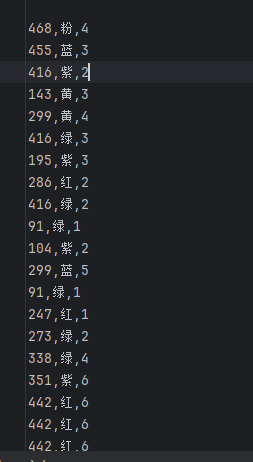
在这里我选择颜色不同增加数据维度,(默认为utf-8编码,要将其改为gbk编码),因为颜色不能单独作为一个可以分析的数据变量,所以将其颜色对应为不同的弹性程度,便于量化分析。
import numpy as np
def color2num(color):
dict={"红":0.50,"黄":0.51,"蓝":0.52,"绿":0.53,"紫":0.54,"粉":0.55}
return dict[color]
data = np.loadtxt('data1.csv', delimiter=',',converters={1:color2num},encoding='gbk')
print(data)
此时因为增加了更多的数据维度,所以应该计算预测点与已知feature的欧式距离。

def knn2(k,P_point,ballcolor,feature,label):
distance=map(lambda item:((item[0]-P_point)**2+(item[1]-ballcolor)**2)**0.5,feature)
sortindex = np.argsort(distance)
sortedlabl = label[sortindex]
return(cl.Counter(sortedlabl[0:k]).most_common(1)[0][0])5,数据归一化,提升精度
对比knn与knn2函数后发现预测准确度上升不明显,因为两个数据维度的差异很大,那么对预测的权重占比不同,与实际情况差异很大,这时对数据进行归一化(nornalization),保持权重相近。
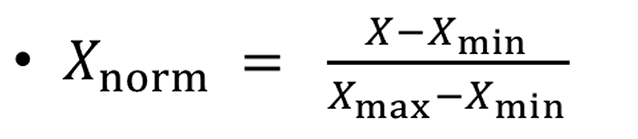
在这里可以对位置变量进行数据归一化,使其于颜色变量在同一数据维度。
6,KNN特征选择
knn的feature应该显著影响模型,比如增加影响不大的数据维度,会造成数据处理困难,甚至会影响模型精确度。
7,KNN预测房价
import numpy as np
feature=np.array([
[-121,47],
[-121.2,46.5],
[-121.3,46.6],
[-121.4,46.7],
[-121.5,46.8]
]
)
label=np.array([200,215,220,225,229])
predictPoint=np.array([-121,46])
matrixtemp=(feature-predictPoint)
matrixtemp2=np.square(matrixtemp)
np.sqrt(np.sum(matrixtemp2,axis=1))
sortindex=np.argsort(np.sqrt(np.sum(matrixtemp2,axis=1)))
sortlabel=label[sortindex]
k=3
predictPoint=np.sum(sortlabel[0:k]/k)
print("预测的房价是{}万".format(predictPoint))相当于是knn模型的回归应用。
8,数据标准化
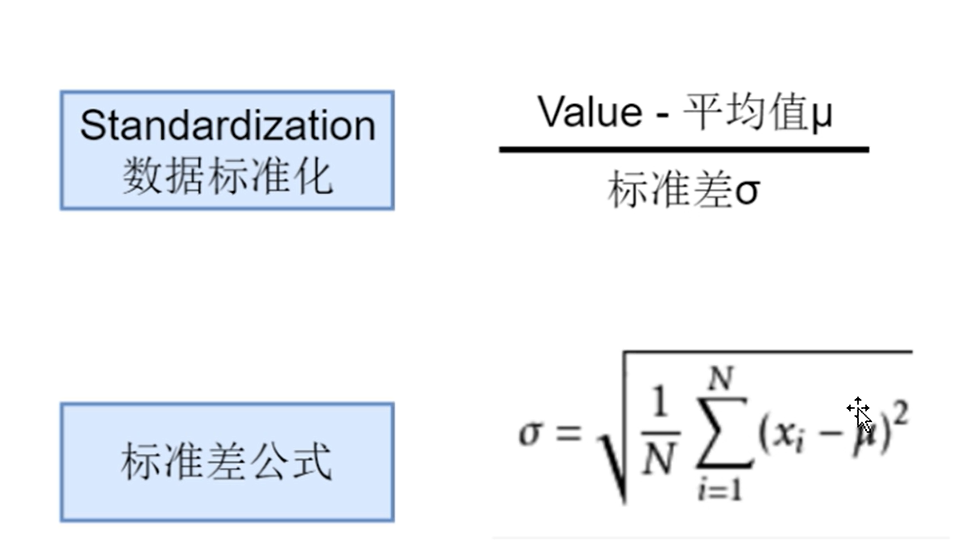
特征单位不一样、大小差距很大要对数据标准化。
三,线性回归
1,作用
线性回归是总结模型,不依托于原始数据,总结规律后可以丢弃数据集。
2,内涵
线性回归就是求线性函数的参数的值的过程,涉及到自变量(independent variable)与因变量(dependent variable).
3,excel与线性回归
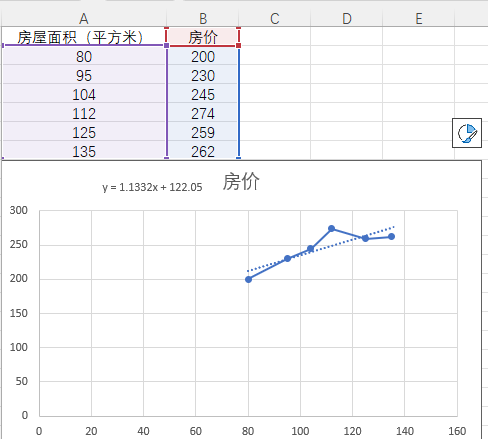
如图,我使用excel表格对线性回归进行了简单模拟,实际上就是找出一个函数使各个点与函数的相差最小。
4,评估模型好坏
评估一个模型的好坏,要计算损失函数(lost function)。

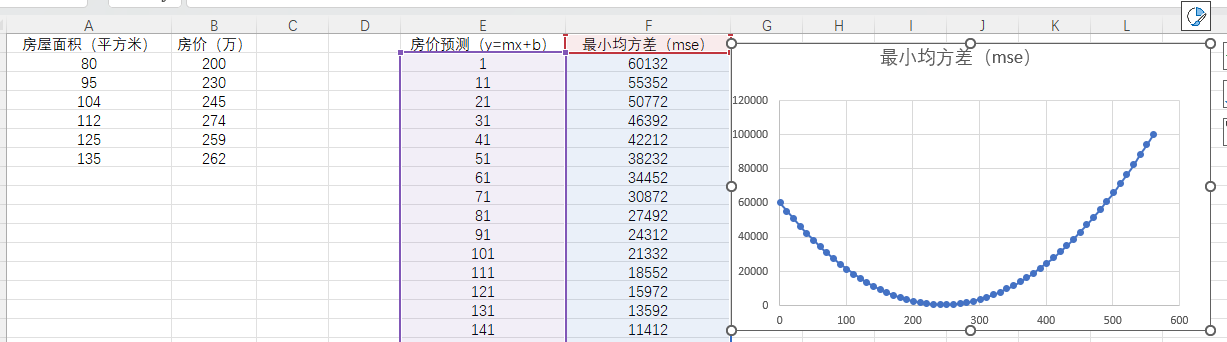
这里用excel对预测结果进行最小均方差计算,可以清晰的看出mse走向。
这时可以指定学习速率(learning rate)以上方模型为例,假设m为0,对已知的mse函数关于b求导,房价预测的价格为1*f(mse)’*rate。学习速率对模型的训练速度有重要影响。下面对其进行python实现。
import numpy as np
data = np.array([
[80, 200],
[95, 230],
[104, 245],
[112, 274],
[125, 259],
[135, 262]
])
m = 1
b = 1
xarray = data[:, 0]
yreal = data[:, -1]
learningrate=0.00001
def grandentdecent():
bslop = 0
for index, x in enumerate(xarray):
bslop = bslop + m*x + b - yreal[index]
bslop = bslop*2/len(xarray)
print("mse对b求导={}".format(bslop))
mslop = 0
for index, x in enumerate(xarray):
mslop = mslop + (m * x + b - yreal[index])*x
mslop = mslop * 2 / len(xarray)
print("mse对m求导={}".format(mslop))
return (bslop, mslop)
def train():
for i in range(1, 1000000):
bslop, mslop = grandentdecent()
global m
m = m - mslop*learningrate
global b
b = b - bslop*learningrate
if (abs(mslop)<0.5 and abs(bslop)<0.5):
break
print("m={}, b={}".format(m, b))
if __name__ == '__main__':
train()![]()
最后可以得到合适的函数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)