Harness Engineering:用控制论看 Agent 时代的软件工程
从 Kubernetes 的声明式协调,到 AI Agent 的自主编程,工程系统越来越像一个需要被设计、观测和校正的闭环。这篇文章想讨论的是:为什么控制论提供了一个理解 Harness Engineering 的好视角,并以此得到实践上的启发。
一、引言:什么是 Harness Engineering?
2025 年下半年以来,Claude Code、Codex 等 Coding Agent 迅速走红。越来越多工程师发现,自己花在“亲手写代码”上的时间在减少,花在“搭建一个让 Agent 稳定产出好代码的环境”上的时间在增加。
OpenAI 在 2026 年初的一篇文章里,用 Harness Engineering 来概括这种新的工程实践。
Harness 这个词很有意思。它的本义是“挽具”,也就是套在马身上的绳索和皮带系统。挽具不替马奔跑,但它负责控制方向、传递力量、施加约束。没有挽具,再强壮的马也可能只是在旷野里乱跑;有了挽具,力量才会被引导到有用的方向上。
Harness Engineering 想表达的,正是这层含义:我们不是替模型完成任务,而是为模型设计一套“挽具”,让它在真实环境中更稳定地达成目标。
这套“挽具”包括什么?架构文档、AGENTS.md 指令文件、自动化测试、自定义 Linter、CI/CD 管道,等等。它们共同构成了一个运行环境,一个让 Agent 能够可靠产出正确代码的系统。
但如果我们只把 Harness Engineering 理解成一组“工具链”,就会错过它更深的一层含义。
二、从 Prompt 到 Context 到 Harness:人类角色的上移
Prompt Engineering 阶段:我该怎么告诉模型去做
2023 年前后,我们在学习如何与 LLM 对话。写好一个 Prompt,就能得到一段还不错的代码。这个阶段的核心技能是“措辞”:用对词、给对例子、选对格式。那时我们常常在对话框里写:“你是一个资深的软件工程师,现在有一个问题……”
Prompt Engineering 要解决的核心问题,是如何写出一轮效果更好的提示词。大家关注的是各种提示技巧:角色设定、few-shot、思维链、格式约束,等等,希望借此让模型这一轮的输出更好。
这些技巧当然有价值,但它们本质上是人类为了适应 AI 总结出的阶段性经验。随着模型能力不断增强,AI 适应人类的速度,往往比人类适应 AI 的速度更快。有些技巧在更强的模型上已经不再重要,甚至会约束模型本可展现的能力——比如过度详细的 step-by-step 指令,在强模型上反而会降低输出质量。
更上层的概念 —— Context Engineering 开始进入人们的视野。
Context Engineering 阶段:我应该如何组织模型的上下文
随着模型能力提升、上下文窗口扩大,模型开始真正进入软件开发场景。以 2024 年爆火的 Cursor 为例,它把人类、模型与 IDE 能力更紧密地组织在一起:人类通过 @、cmd + k、cmd + l 等交互方式主动补充上下文,模型也能借助 IDE 暴露的能力,比如代码检索、文件读取等,按需获取解决问题所需要的信息。
Context Engineering 要解决的核心问题不再是”怎么把更多信息塞进窗口”,而是”在某个任务、某个时刻,模型到底需要看到什么”。这件事之所以难,是因为上下文的两种失败模式都很致命:太少,模型会凭空猜测,写出签名完全不兼容的代码;太多,模型又会淹没在噪音里,输出质量反而下降。围绕这个问题,行业陆续发展出 offload、retrieve、isolate、cache 等一系列最佳实践,限于篇幅不展开。
但 Context Engineering 解决的仍然是”单次交互中模型该看到什么”的问题。它还没有回答一个更根本的问题:当 Agent 可以自主执行多步操作时,如何确保整个过程持续收敛,而不是越跑越偏?
Harness Engineering 阶段:我应该如何设计反馈回路
到了 Coding Agent 时代,事情又继续向前推进。Prompt 没有消失,Context 也没有消失,但它们都开始被放进一个更大的系统里。Agent 不再只是“请求-响应”式的工具,它可以自主规划、执行多步操作、运行测试、读取错误信息、修复问题,从而形成一个自主循环。
几乎所有长期使用 Claude Code 或 Codex 的人,都会提到一个经验:给 Agent 一个清晰、可验证的目标非常重要,甚至可能是最重要的技巧,没有之一。这也是 Harness Engineering 的核心问题:如何把 Agent 放进一个可控、可验证、可恢复、可持续改进的运行系统里。
OpenAI 在同一篇文章里总结过一些内部实践,比如:
- 为 Agent 建设可观测性工具栈,让模型可以读取日志、链路追踪和指标,并根据这些信号判断任务是否完成
- 为模型构建足够的产品上下文,让 Agent 能像新加入团队的工程师一样从不同系统中获取知识
- 将架构约束和工程品味编码进系统,通过自定义 lint、结构测试等方式机械地约束 Agent 生成的代码
如果把这几件事放进同一个框架里看,会发现它们都指向同一个问题:不是“如何让模型一次回答得更漂亮”,而是“如何让系统在多轮运行中持续收敛”。
这里的关系不是替代,而是递进。Prompt 仍然是 Agent 接收任务和约束的入口,Context 仍然决定 Agent 能否看见完成任务所需的信息;Harness 则把 Prompt 和 Context 一起放进一个可观测、可验证、可纠偏的运行系统里。人类工程师发挥价值的层次,也因此逐级上移:先把话说清楚,再把信息组织清楚,最后把反馈回路设计清楚。
串起这三个阶段,会看到一条很清晰的上移路径:人类工程师的角色并不是被替换,而是在不断上移。从 Prompt Engineering 阶段的指令发出者,到 Context Engineering 阶段的信息组织者,再到 Harness Engineering 阶段的系统设计者,人类关注的对象越来越从”眼前的一次输出”转向”支撑持续收敛的整个系统”。这个方向最终会导向一个非常鲜明的结论:人类正在从”亲自做事的人”,上移到”设计让事情被正确完成的系统的人”这个位置。
为什么是控制论?
一旦工程师的工作从”亲自执行”转向”定义目标、组织观测、设计纠偏机制”,问题的本质就从”求解”变成了”控制”。我们不再是一次性把答案写出来,而是让一个系统在不断变化的环境中持续逼近期望状态。
而研究”如何通过反馈让系统收敛”的学问,正是控制论。控制论关心的不是某个组件有多聪明,而是目标、观测、比较、行动和反馈如何连接成闭环。理解了这一点,我们就能明白:Harness Engineering 不是一组零散工具,而是一种反馈控制系统的设计实践。
三、一个熟悉的模式:反馈控制系统
从最基本的意义上说,一个反馈控制系统通常包含几个元素:目标状态、对现实的观测、对偏差的计算、纠偏动作,以及把结果重新送回系统的反馈回路。只要一个系统依赖这种循环来维持稳定,它就是控制论意义上的系统。
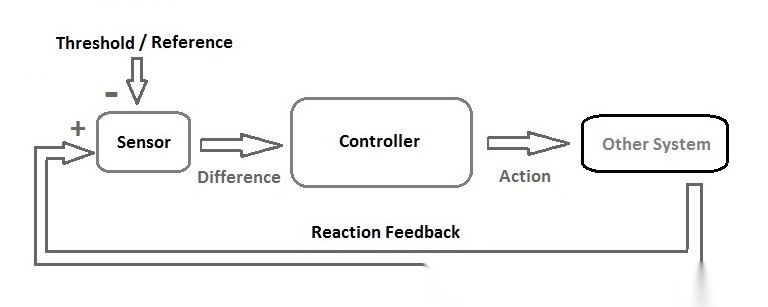
这个抽象听起来有点理论,但在现代工程里其实非常常见。Kubernetes 就是最典型的例子之一。
Kubernetes 的关键价值,不只是自动化,而是它把基础设施管理改写成了一个闭环:先定义目标,再观察现实,再计算偏差,再执行纠偏。只要这个循环不停,系统就能在节点故障、流量波动、资源漂移等扰动下,持续逼近期望状态。
for {
desired := getDesiredState() // 读取 YAML 声明的期望状态
actual := getActualState() // 观察集群当前实际状态
diff := compare(desired, actual)
if diff != empty {
reconcile(diff) // 执行动作:创建/删除/更新资源
}
wait(syncPeriod) // 等待,然后再来一轮
}
在 Kubernetes 出现之前,工程师管理基础设施的方式更多是命令式的:SSH 登录机器、重启进程、扩容实例、处理告警、执行脚本。系统一旦偏离预期,人就必须亲自介入,把它拉回正确状态。Kubernetes 改变了这件事。工程师不再需要持续地下达具体命令,而是转向定义“什么是正确的状态”,再由控制器通过调谐循环持续纠偏。
用控制论的语言看,这个循环非常标准:desired state 是设定点,actual state 是被观测对象的状态,compare 用来计算偏差,reconcile 是控制动作,而 sync period 决定了系统感知和纠偏的频率。Kubernetes 之所以重要,不只是因为它“自动化了运维”,更是因为它把运维问题改写成了一个可持续收敛的反馈控制问题。
工程师的职责也随之上移:从编写运维脚本、执行具体操作,逐步上移到定义目标状态、设计控制器、把领域知识编码进 Kubernetes 的 Operator。
如果说 Kubernetes 控制的是容器、服务和集群资源,那么 Harness Engineering 控制的,就是 Agent 与任务环境之间的交互过程。人类同样不再负责每一个具体动作,而是定义任务目标、验收标准和约束条件;真正持续执行“观察、比较、纠偏”循环的,则是由提示词、架构文档、测试、日志、CI 和审批机制共同组成的 harness。
OpenAI 曾提到,有内部团队借助 Codex Agent,在很少的人力投入下构建出大规模代码库。工程师并不手动编写每一行代码,他们更多在做的是:设计架构文档、编写 AGENTS.md、构建自动化测试、配置 CI 管道、校准 Linter 规则。换句话说,他们主要在设计这个闭环本身。
于是,控制论就不只是一个修辞上的类比,而是一个很有解释力的观察框架:它能帮助我们理解 Harness Engineering 关心的核心问题,正是如何让系统在扰动中持续逼近期望状态。
四、用控制论理解 Harness Engineering
有了对控制论的直觉,我们就可以更具体地回到 Harness Engineering 本身。控制论由诺伯特·维纳在 1948 年系统化提出;今天再看 Agent 时代的软件工程,它依然提供了一套很有解释力的语言。
当然,这里说的不是数学意义上的同构,也不是逐项一一对应。更准确地说,控制论提供了一组观察坐标,让我们更清楚地描述 Harness Engineering 里的目标、观测、决策、执行与反馈。下面不妨沿着这些坐标逐一展开。
设定点(Set Point):什么是“正确”
在控制论中,设定点是系统的目标状态,比如恒温器的目标温度、自动巡航的目标时速。
在 Harness Engineering 中,设定点可以理解为你对代码库的期望:架构分层规则、命名约定、依赖方向、性能基准。这些期望被编码在 AGENTS.md、架构文档、黄金规则之中。
OpenAI 团队有一个很关键的洞察:如果你不把“好”的定义外化为机器可读的形式,Agent 在第一百次运行时,仍然会犯第一次那样的错误。 Agent 不会通过耳濡目染来学习。你脑海里的“品味”和“直觉”,团队熟悉的最佳实践,必须变成写下来的规则。
这就是设定点的作用:把模糊的“应该如何”,转化为明确、可度量、可检查的标准。
传感器(Sensor):感知偏差
传感器的作用是感知系统的实际状态,并将它与设定点进行比较。
在传统软件工程中,我们其实已经有不少接近“传感器”的机制:
| 传感器 | 感知的属性 |
|---|---|
| 编译器 | 语法正确性 |
| 测试套件 | 行为正确性 |
| Linter | 风格一致性 |
但这些传感器只能感知可以机械检查的属性。更高层的问题,比如“这个改动是否符合系统架构”“这个抽象在代码库扩展时会不会出问题”,传统上往往没有传感器,只有人类判断。
从控制论视角看,Harness Engineering 在两个方向上扩展了传感器的覆盖范围。
第一个方向,是用传统工具覆盖更多可机械检查的属性。自定义 Linter 可以检查架构分层是否被违反,比如 UI 层不得直接导入 Service 层;结构性测试可以验证模块边界是否完整;依赖方向检查可以防止循环引用。这些事情本身不需要 LLM,但过去常常因为“人记着就行”而没有被编码为自动化检查。Agent 的到来,反而倒逼工程师把这些隐性规则外显成机器可执行的传感器。
第二个方向,才是 LLM 带来的真正新能力:在语义层面构建传感器。比如,让 Agent 评估一个改动是否符合文档中定义的设计原则,扫描代码中是否存在“AI 糟粕”(机械、低质量的生成模式),或者判断一段新代码是否与代码库既有风格一致。这些判断涉及自然语言理解和上下文推理,传统工具难以胜任。
OpenAI 团队的做法,就是在这两个方向上同时推进:从编译和测试,到架构合规性的自动化检查,再到语义层面的 AI 辅助审查。每增加一个传感器,Agent 写出的代码就更有可能收敛到预期状态。
控制器(Controller):决定如何纠偏
控制器根据传感器给出的状态,以及它与设定点之间的偏差,决定系统下一步应该采取什么动作。
在 Harness Engineering 中,控制器的角色通常由两部分共同承担。
一部分是确定性的编排规则:CI pipeline 的条件分支,比如测试失败就阻断合并;重试策略,比如失败后最多重跑三次;审批门控,比如高风险操作必须由人确认;工具权限边界,比如 Agent 可以读文件,但不能随意编辑。这些规则不负责语义判断,但它们框定了系统的决策空间。
另一部分是LLM 的语义推理。当 Agent 读到一条测试失败信息,它需要理解错误的含义、定位问题根因、决定该改哪段代码。这类判断很难用固定的 if/else 写死,需要模型的推理能力。
两者的分工是:编排规则回答“什么时候该行动、能在什么边界内行动”,LLM 回答“具体该怎么行动”。好的 harness 设计,不是让模型承担全部决策,而是先用确定性规则尽量收窄决策空间,再把真正需要语义判断的部分交给模型。
执行器(Actuator):把控制信号施加到真实世界
执行器的作用,是把控制器的决策真正施加到系统上。在恒温器里,执行器是加热器;在 Kubernetes 里,执行器是负责创建、删除、更新资源的那套机制。
在 Harness Engineering 中,执行器可以理解为 Agent 可以驱动的那组操作接口:文件编辑器、Shell、浏览器、测试命令、Git、CI/CD API,甚至日志和监控系统的查询入口。它们把“下一步该做什么”的判断落实成真实动作:修改代码、运行测试、读取报错、提交 PR。
这样看,LLM 更像是决策环节的一部分,而不是执行器本身。真正的突破在于:模型第一次可以基于高层语义,选择合适的工具、组织合适的动作,再把这些执行器组合起来作用于代码库。过去,编译器能发现错误,却不能修复设计问题;脚本能自动执行,却缺乏语义判断。今天,Agent 第一次把“理解问题”和“执行修改”连接在了一起,代码库也因此第一次成为一个可以被持续闭环控制的对象。
反馈回路(Feedback Loop):让系统自我纠正
控制论的核心不是任何单个组件,而是这些组件形成的闭合回路:传感器感知,控制器比较,执行器行动,行动结果再被传感器重新感知。只要这个循环持续运转,系统就能在扰动中保持稳定。
Harness Engineering 中最典型的反馈回路是:
ounter(line
Agent 生成代码 -> 运行测试 -> 发现失败 -> Agent 读取错误信息 -> Agent 修复代码 -> 再次运行测试 -> ...
但更有价值的,是更大尺度上的反馈回路:
ounter(lineounter(lineounter(lineounter(lineounter(line
Agent 提交 PR -> 发现架构违规 -> Agent 修复 -> 通过
↓
类似违规反复出现
↓
工程师更新 AGENTS.md 和 Linter 规则 -> Agent 从源头避免违规
这种双层反馈结构,也就是 Agent 层面的短回路和人类层面的长回路,正是 Harness Engineering 的精髓。短回路处理日常偏差,长回路优化系统本身。
一个完整的闭环
把上面几个组件串起来,看一个具体的例子。假设你要让 Agent 给订单服务新增"取消订单"接口。
设定点是你在任务描述里写下的验收条件:接口路径、允许取消的状态、错误码约定、审计日志要求、测试覆盖范围。传感器是编译器、单元测试、集成测试、自定义架构 lint(比如"Handler 层不得直接依赖 Repository")。Agent 生成代码后,这些传感器立刻给出信号。
如果架构 lint 报错"Handler 直接导入了 repository 包",这个误差信号会被送回 Agent。控制器——也就是 CI 编排规则加上 Agent 自身的推理——决定下一步动作:Agent 理解报错含义,把数据访问逻辑移到 service 层。然后执行器(文件编辑器、Shell)把修改落地,测试重新运行。这就是一轮短回路。
如果类似的架构违规在多个 PR 里反复出现,工程师会介入长回路:更新 AGENTS.md,在任务模板里预置分层约束,甚至加一条新的 lint 规则。从此,Agent 在生成代码时就已经知道这条边界,违规从源头被消除。
整个过程里,没有一个组件是孤立的:设定点给出方向,传感器感知偏差,控制器决定纠偏策略,执行器落地修改,反馈回路把结果送回起点。这就是控制论视角下的 Harness Engineering。
五、从认识到实践
如果前面几节是在建立一个理解框架,那么接下来的问题就是:把这些认识落到工程实践里,怎样的 harness,才能让系统更稳定、更可靠、更少发散?
从控制论的角度看,答案并不神秘。我们要做的,无非是把目标定义得更清楚,把观测做得更充分,把误差信号设计得更可操作,把动作边界控制得更稳,再让整个系统拥有记忆、层次和自我清理能力。
1. 明确目标值:让 Agent 知道什么叫“完成”
控制系统没有设定点,就不可能收敛。Agent 也一样。很多失败并不是模型不会做,而是任务本身没有被定义成一个可以验证的目标。
不要只说“加一个取消订单接口”或“把订单状态改对”。更好的写法,是把目标拆成接口行为、业务规则、兼容边界、验收条件和失败条件。比如,假设你要在订单服务里新增“取消订单”能力,可以这样定义:
- 新增
POST /api/orders/{id}/cancel接口,只允许取消PENDING_PAYMENT和PAID_PENDING_REVIEW状态的订单 - 订单不存在时返回
404,状态不允许取消时返回409,未登录或无权限时返回401/403 - 取消成功后必须写入
order_events审计记录,并保存cancel_reason、cancelled_by、cancelled_at - 不得修改现有下单、支付、查询接口的响应结构
- 必须补齐单元测试和集成测试,至少覆盖成功取消、重复取消、越权取消、并发重复请求四类场景
- 如果需要数据库迁移,必须提供迁移脚本、回滚方案,并说明对历史数据和索引的影响
- 任一测试失败、出现状态机漏洞或审计日志缺失,都不能算完成
人类工程师过去可以在模糊目标里边做边想,但 Agent 更依赖外显的完成条件。你定义得越具体,系统的收敛方向就越稳定。
2. 增强传感器:让 Agent 真正看见系统状态
没有传感器,就没有反馈回路。Agent 之所以经常“自信地做错”,很大程度上不是因为它不会推理,而是因为它看不见足够多的现实信号。
一个实用的 harness,至少应该逐步把下面这些状态暴露给 Agent:
- 测试结果:单元测试、集成测试、端到端测试
- 运行时信号:日志、指标、链路追踪
- 界面状态:DOM、截图、浏览器行为
- 环境状态:文件系统、配置、依赖、进程状态
OpenAI 在文章里提到,他们把日志、指标、链路追踪和浏览器能力直接暴露给 Codex。这样,“把启动时间降到 800ms 以下”就不再是一句模糊要求,而变成了 Agent 可以自行观测、自行修正的闭环任务。
3. 设计更好的误差信号:让反馈能直接指导下一步动作
反馈不是越多越好,而是越可操作越好。一个控制系统最怕的不是没有误差,而是误差信号太噪、太模糊,或者根本无法指导纠偏。
一个坏反馈是:
architecture violation
一个好反馈是:
HTTP Handler 层禁止直接依赖 repository 包。请将数据访问逻辑移动到 service/usecase 层,参考 docs/architecture/layers.md,并运行 golangci-lint run 与 go test ./... 重新验证。
OpenAI 提到,他们会在自定义 lint 的报错里直接写入修复指引。这个细节非常关键,因为它等于把“发现偏差”和“提示修正路径”合并进了同一个信号里。对 Agent 来说,最有价值的错误信息不是“你错了”,而是“你错在哪里,下一步该怎么改”。
4. 限制执行器:让 Agent 在边界内行动
“限制执行器”听起来像一个抽象概念,但在今天的 Agent 工具里,它最直观的体现,其实就是权限管理。
以 Claude Code 和 Codex 为例,它们都把“Agent 能做什么、做到哪一步需要人类确认”设计成了一等公民。Claude Code 会把工具调用放进显式的权限模式和规则系统里:可以选择默认模式,也可以切到只规划不执行的 plan mode,并通过 allow / ask / deny 规则把权限细化到具体命令。Codex 则把执行边界直接暴露为 sandbox 和 approval policy:比如 read-only、workspace-write、danger-full-access,以及按需审批、对不受信任命令单独审批等策略。它们的共同点不是界面设计,而是都在回答同一个问题:Agent 现在到底能读什么、改什么、运行什么、联网到哪里、越界时谁来拍板。
这件事之所以重要,是因为 Agent 的风险从来不只来自“回答错了”,更来自“做错了,而且做得太快”。如果一个模型只能读代码,它顶多分析失误;如果它还能改文件、跑命令、访问外部系统,那么同样一次误判,后果就可能从“建议不靠谱”升级成“工作区被污染”“测试数据被删除”“生产资源被误操作”。
所以,好的 harness 不是把 Agent 一股脑放进最高权限里,而是把执行能力拆成分层、分区、分审批的边界。
实践上,这通常意味着三件事:
- 低风险动作默认放行:读文件、全文检索、查看日志、运行只读命令
- 中风险动作放进受限环境:允许在工作区内改代码、跑测试、启动本地服务,但受沙箱、目录范围和网络策略约束
- 高风险动作必须显式审批或直接禁止:访问生产数据库、调用外部生产 API、批量删除、推送主分支、改密钥和凭证
从控制论看,这相当于不是让控制器”没有力量”,而是避免它把过强的控制信号直接施加到高风险环境里。权限系统的作用,不只是安全防线,也是稳定性设计。很多时候,好的 Harness 不是”让 Agent 什么都能做”,而是”让 Agent 在安全边界内自动完成尽可能多的动作,并在真正越界时把控制权交还给人类”。
以上四点——目标、传感器、误差信号、执行器——关注的是单次循环内如何让闭环跑通。但真实的软件工程不会只跑一次循环。接下来三点,关注的是跨循环的系统演化:如何让 harness 本身越来越好。
5. 代码库即记忆系统
记忆系统本质上是设定点和传感器的基础设施:如果系统的目标和约束没有被持久化,反馈回路就没有参照物。所以记忆系统的意义,不是给模型塞更多上下文,而是把那些存在于代码之外、却持续影响决策的知识写进仓库。很多关键背景本来就在代码外:业务规则为什么这样定、某个兼容分支是在迁移历史数据还是在满足合规要求、哪些客户承诺绝不能破坏。人类可以靠会议和经验补全这些信息,Agent 不行;对 Agent 来说,看不见就等于不存在。
这也是为什么,代码库不能只保存“现在是什么”,还要保存“为什么会变成这样”。业务发展会推动架构不断调整,如果没有决策历史,Agent 很容易把阶段性妥协当成长期原则。ADR 在这里尤其重要,因为它记录的不是代码长相,而是当时的选择、权衡和适用条件,让后续的人和 Agent 都能理解架构演化的原因。
实践上,记忆系统可以分层实现:
- 用精简的
AGENTS.md做导航,告诉 Agent 去哪里找规则(渐进式披露) - 用
docs/、产品文档、领域说明保存业务背景和长期知识 - 用任务计划文档和 ADR 记录任务状态、关键决策和架构变更
但记忆系统的关键不只是“写下来”,更是“持续更新”。文档和代码的一致性一直很难靠自觉维持,传统团队里文档之所以容易过时,就是因为改代码有即时反馈,改文档没有。到了 Agent 时代,代码变化更快,这个问题只会更明显。
所以,记忆系统必须由人和 Agent 共同维护:人类负责判断什么值得记录、哪些共识已经变化,Agent 负责扫描失效文档、检查交叉引用、补齐结构化更新。OpenAI 也提到过专门的文档 Agent,用来周期性发现文档与真实代码行为不一致的问题,并提交修复 PR。换句话说,“代码库即记录系统”并不是把所有知识都塞进代码,而是把会反复影响系统行为的知识版本化、可检索化,并纳入持续维护的反馈回路。
6. 引入多层反馈回路:让系统既快又稳
单一反馈回路,很难支撑真实的软件工程。
如果只有一层很快的反馈,比如 lint、类型检查和单元测试,Agent 的确能迅速修正局部错误,但它也很容易学会另一件事:不是把系统做对,而是把眼前的检查做过。代码可以通过静态约束,却仍然违背架构原则;测试可以全部通过,真实交互却依然出错。
反过来,如果只有一层很慢的反馈,比如集成测试、人工评审,甚至线上告警,系统又会变得迟钝。错误总要等到传播得更远、代价变得更高之后才被发现。
这就是为什么 Harness Engineering 必须引入多层反馈回路,让不同时间尺度、不同抽象层级上的偏差,都能在合适的位置被看见、被纠正:
- 短回路(秒级到分钟级):lint、格式化、类型检查、单元测试。负责尽快阻止低级错误扩散,像控制系统的内环,让 Agent 每一步都能立刻知道自己有没有偏出基本约束。
- 中回路(分钟级到小时级):集成测试、端到端验证、浏览器自动化、架构检查、PR review。负责验证多个模块是否真的协同工作,防止系统只对最容易测量的信号过拟合。很多 Agent 的失败,恰恰不发生在语法层,而发生在接口层、边界层和语义层。
- 长回路(天级到周级):线上指标、用户反馈、事故复盘、架构治理、规则更新。负责回答“我们的系统是不是正在慢慢偏离目标”。
从控制论的角度看,多层回路的价值在于分工:快回路负责即时纠偏,慢回路负责整体校准;内环处理局部稳定,外环处理方向修正。好的 harness,不只是让 Agent 在当前任务里通过测试,而是让每一次偏差都能在合适的层级被吸收,把问题逐层向内压缩,直到它们不再反复出现。
7. 抵抗熵增:Agent 时代的“垃圾回收”
在 Agent 时代,长回路还有一个特别重要的职责:做“垃圾回收”。
Agent 会以极高的速度复制代码库里已经存在的模式。好的模式会被学习,坏的模式也会扩散。一次错误的抽象、一个脆弱的边界、一种临时性的修复方式,如果不被及时发现,就会在短时间内变成整个系统的新常态。人类工程师写代码时,这种扩散是缓慢的;但是 Agent 写代码时,一个坏模式可能在几小时内被复制到几十个文件里。
所以 harness 不能只关注“这次改动对不对”,还必须持续清理系统:扫描架构漂移,回收过期规则,把反复出现的问题沉淀为新的测试和约束,用小而稳定的治理性修改抵抗代码库熵增。这不是一次性的修补,而是对系统稳定性的长期维护。
抵抗熵增不能只靠事后清理,还要把治理前移到项目初始化阶段。因为一旦一个项目从第一天起就目录混乱、边界模糊、技术选型漂移,Agent 只会更快地放大这种混乱。一个能长期维护的项目,至少要在一开始就把几件事固定下来:功能要尽量内聚,模块之间要尽量解耦,目录划分要足够清晰;多人协作时,每个人和每个 Agent 都应该在明确的职责边界内工作,而不是不断跨边界修改彼此的区域;技术选型也不应该在执行任务时被临时发明出来,而应该尽量收敛到团队已经验证过的技术栈上。
这也是为什么,团队内部的脚手架在 Agent 时代会变得格外重要。它不只是一个提高启动效率的小工具,而是一种把秩序提前写进系统的方式。一行命令初始化出来的,不应该只是几个空目录,而应该是一个已经带着团队约束的项目骨架:比如预置符合团队习惯的 DDD 目录结构,默认采用团队熟悉的技术栈,自动引入内部基础包,再通过 AGENTS.md 把架构原则、模块导航和协作边界写清楚。这样,AGENTS.md 既是在说明架构,也是在为 Agent 提供记忆入口;更细的知识则可以在后续执行中按需渐进式加载。换句话说,脚手架不是开发流程之外的辅助物,而是团队用来对抗代码库熵增的一部分基础设施。
这个类比的边界
控制论提供了一个有力的思维框架,但任何类比都有局限,值得诚实地标注出来。
首先,不是所有软件工程任务都适合这个范式。控制论假设存在一个可定义的目标状态和可观测的偏差信号,但探索性研究、创造性设计、早期原型验证,这些任务的目标本身就是模糊的、流动的。试图为一个尚未明确的目标设计精密的反馈回路,反而可能过早锁定方向。Harness Engineering 更适合目标相对清晰、可验证的工程任务,而非所有软件开发活动。
其次,过度 harness 化本身也是一种风险。规则越多,Agent 越可能退化为“面向检查编程”:代码能通过所有 lint 和测试,却只是在机械地满足约束,而不是真正解决问题。当传感器覆盖过多维度时,Agent 也可能把大量循环耗在满足相互冲突的规则上,而不是推进任务本身。好的 harness 需要克制,知道什么时候不检查,和知道什么时候检查同样重要。
最后,LLM 不是经典控制论中的线性系统。恒温器的行为是可预测、连续的;LLM 的输出却可能因为上下文的一点细微变化而出现显著差异。这意味着控制论中许多关于稳定性和收敛性的数学保证,在 Agent 系统中并不能被严格照搬。我们借用的,是控制论的结构直觉,而不是它的数学确定性。
也正因为如此,Harness Engineering 的重点,不是把软件工程生硬地套进一个理论模型,而是借用控制论的视角,设计一个更容易收敛的工程系统。
六、总结:成为系统的舵手
如果说前一节讨论的是如何把一个 Agent 系统设计得更稳,那么最后可以回到本文最初的问题:Harness Engineering 到底改变了什么?
控制论(Cybernetics)来自希腊语 κυβερνήτης,意思是“舵手”。Kubernetes 的名字来自同一个词根。Harness(挽具)则是另一个方向的隐喻:它不是掌舵,而是驾驭。但这两个意象恰好可以拼成一幅完整的画面。挽具是从执行侧看的,强调如何约束和引导力量;舵手是从系统侧看的,强调如何把握方向、感知偏差、持续修正。一个好的 Harness Engineer,既是设计挽具的人,也是掌舵的人。
这正是软件工程正在发生的变化。从写代码,到写 Prompt,到组织 Context,再到设计 Harness,这些能力不是彼此替代,而是在不断叠加;只是人类工程师的价值重心,确实在向更高杠杆的位置移动。过去,优秀工程师的标志是能亲自写出正确的代码;今天,越来越重要的能力,是设计一个让 Agent 可靠产出正确代码的环境。
这也是为什么,用控制论来理解 Harness Engineering 会特别有帮助。它要求我们的思维从命令式的“我要做什么”,转向声明式的“系统应该是什么样”,再进一步转向控制论式的“系统如何在扰动中自我稳定”。你关注的不再只是一次输出,而是整个系统的动态行为:目标是否明确,反馈是否充分,约束是否清晰,偏差是否能够被吸收。
Kubernetes 的使用者没有回到手动重启服务的日子。今天的工程师也不会长期停留在逐行驱动 Agent 的状态。不是因为我们做不到,而是因为这样做已经不再有意义。当 Agent 能以机器的速度生成和修改代码时,工程的重心就会不可逆转地从执行转向设计。
而这些设计所要求的东西,如文档编写、自动化测试、规范化架构决策、快速反馈循环,本来就是好的工程实践。Agent 只是把它们的重要性从“长期正确”放大成了“立即生效”:你是否定义了正确,是否暴露了足够的信号,是否把经验沉淀进系统,现在都会立刻体现在 Agent 的表现里。
所以,Harness Engineering 并不是一个关于“如何更好地使用模型”的小技巧集合。它更像是一种提醒:在一个高自治的软件系统里,人类最重要的价值,不是比机器执行得更快,而是比机器更清楚什么叫正确,并把这种判断力变成系统的一部分。
这正是舵手的工作。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)