
Langchain从入门到精通(七)---从零搭建本地 RAG 知识库问答系统

在大模型应用落地过程中,“本地知识库问答” 是最核心、最常见的场景之一 —— 通过将私有文档(PDF/TXT/Excel)转化为结构化向量,结合大模型实现 “基于私有数据的精准问答”,既解决了大模型 “知识过时” 的问题,又保障了数据隐私(无需将敏感数据上传到公有云)。
本文将从背景、核心原理、技术路线、完整实现四个维度,手把手教你搭建一套支持 PDF / 多文件 / 长文本的本地 RAG(检索增强生成)问答系统,所有核心流程和代码均可直接复用。
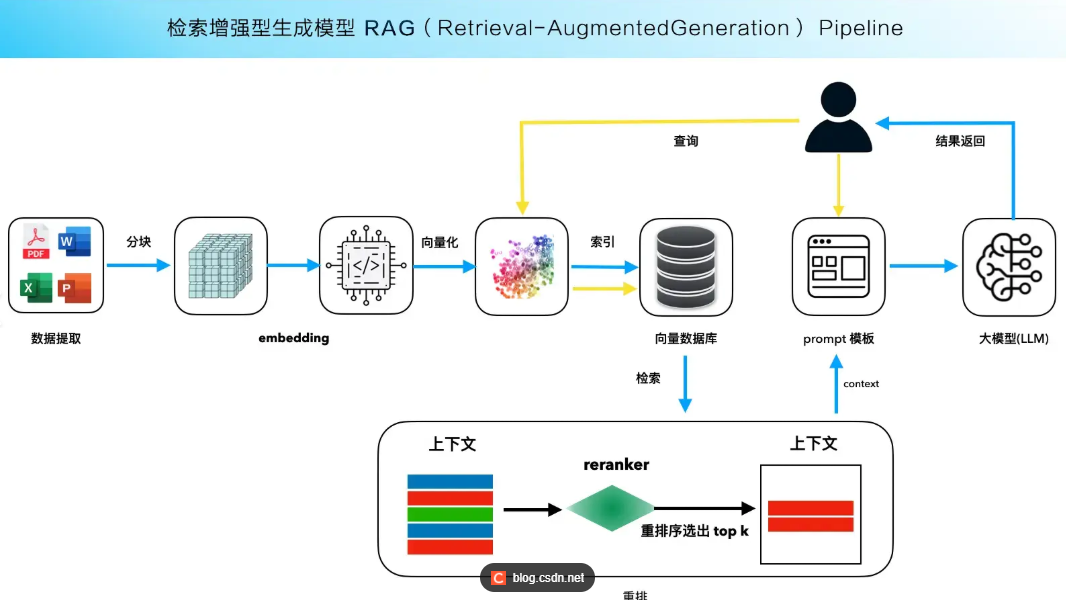
一、RAG 核心背景:为什么需要检索增强生成?
1. 纯大模型问答的痛点
- 知识时效性差
大模型的训练数据有时间截止(比如 GPT-3.5 截止 2021 年 9 月),无法回答最新的私有文档内容;
- 幻觉问题
纯大模型易生成 “看似合理但错误” 的内容,尤其对专业领域知识;
- 数据隐私风险
将企业 / 个人敏感文档上传到公有大模型 API,存在数据泄露风险;
- 长文本处理能力弱
大模型有上下文窗口限制(比如 8k/16k),无法直接处理万字级的长文档。
2. RAG 的核心价值
RAG(Retrieval-Augmented Generation,检索增强生成)通过 “先检索、后生成” 的模式,完美解决上述问题:
- 知识私有化:基于本地文档构建知识库,所有数据不上云;
- 回答精准化:从私有文档中检索相似内容,作为大模型回答的依据,大幅降低幻觉;
- 长文本适配:通过 “分块 + 检索”,突破大模型上下文窗口限制;
- 低成本落地:无需重新训练大模型,仅需适配本地文档即可快速落地。
二、RAG 核心原理:5 步全流程(必须掌握)
RAG 的核心逻辑是 “将非结构化文档转化为可检索的向量,结合检索结果辅助大模型回答”,完整流程可拆解为 5 个核心步骤:
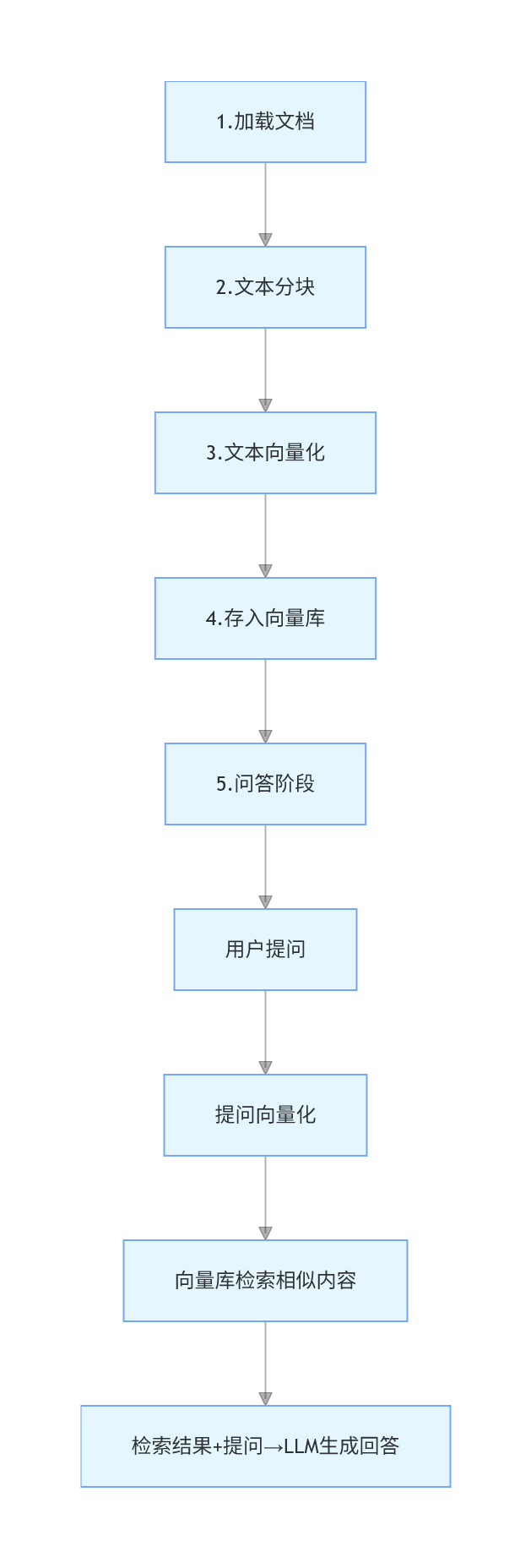
核心步骤解析
- 加载文档
将 PDF/TXT/MD 等非结构化文件转化为程序可处理的文本格式;
- 文本分块
将长文本拆分为大小适中的 “文本块”(Chunk),适配大模型上下文窗口,同时保证语义完整;
- 文本向量化
通过 Embedding 模型将每个文本块转化为数值型向量(Embedding),向量的相似度代表文本语义的相似度;
- 存入向量库
将向量和对应的文本块存入向量数据库(如 FAISS/Chroma),支持快速的相似度检索;
- 问答阶段
用户提问→提问向量化→向量库检索 Top-N 相似文本块→将 “提问 + 检索结果” 传给大模型→生成精准回答。
三、RAG 技术路线:核心组件选型(本地优先)
搭建本地 RAG 系统的核心是 “组件选型适配本地环境”,以下是经过验证的最优技术路线(新手直接抄)
|
环节 |
核心组件 |
选型理由 |
|
文档加载 |
PyPDFLoader/TextLoader |
LangChain 原生支持,适配 PDF/TXT,轻量无依赖 |
|
文本分块 |
RecursiveCharacterTextSplitter |
对中文友好,支持按语义分隔(换行 / 句号 / 逗号),长文本分块最优选择 |
|
嵌入模型 |
Ollama 兼容的 OpenAIEmbeddings |
基于本地 Ollama 部署的大模型,无需调用公有 API,数据本地化 |
|
向量库 |
FAISS |
Facebook 开源,本地轻量,检索速度快,支持百万级向量 |
|
检索器 |
VectorStoreRetriever |
LangChain 原生适配,支持自定义检索数量(k 值),可直接对接向量库 |
|
LLM 模型 |
Ollama(qwen3:8b/llama3:8b) |
本地部署的大模型,无需联网,支持中文,8B 参数级模型性能足够满足日常需求 |
|
问答链 |
RetrievalQA |
LangChain 封装的 RAG 核心链,支持 stuff/map_reduce 等多种生成模式 |
四、完整实现:本地 RAG 知识库问答系统
4.1 环境准备
1. 基础依赖安装
# 核心依赖pip install langchain langchain-community faiss-cpu pypdf python-dotenv ollama# 注意:faiss-cpu为CPU版本,GPU版本安装faiss-gpu(需适配CUDA)
2. 本地大模型部署
-
安装 Ollama:访问Ollama 官网下载对应系统的安装包,一键安装;
-
拉取本地模型:终端执行
ollama pull qwen3:8b(通义千问 3,8B 参数,中文友好); -
启动 Ollama 服务:安装完成后自动启动,默认地址
http://127.0.0.1:11434(可通过ollama serve手动启动)。
3. 目录准备
创建如下目录结构:
├── knowledge_base/ # 存放私有文档(PDF/TXT)│ ├── 产品手册.pdf│ ├── 技术文档.txt├── faiss_local_kb/ # 自动生成:存储向量库(首次运行后生成)└── rag_demo.py # 核心代码文件
4.2 完整代码实现(带详细注释)
import osfrom dotenv import load_dotenvimport sys# 兼容LangChain 0.3版本的内存模块(可选,解决版本兼容问题)sys.modules['langchain_core.memory'] = __import__('langchain.memory.base')# ========== 1. 核心组件导入(适配LangChain 0.3+) ==========# 本地大模型适配器(Ollama)from langchain.llms import Ollama# 文档加载器:支持TXT/PDF(可扩展Excel/MD等)from langchain_community.document_loaders import TextLoader, PyPDFLoader# 文本分块器:RecursiveCharacterTextSplitter(中文长文本最优)from langchain.text_splitter import RecursiveCharacterTextSplitter# 嵌入模型:适配Ollama的OpenAI兼容接口from langchain_community.embeddings import OpenAIEmbeddings# 向量库:FAISS(本地轻量级)from langchain_community.vectorstores import FAISS# RAG核心链:检索问答链from langchain.chains import RetrievalQA# 加载环境变量(可选,也可直接在代码中配置)load_dotenv()# ========== 2. 初始化核心组件 ==========# 2.1 初始化本地LLM(Ollama部署的大模型)llm = Ollama(model="qwen3:8b", # 替换为你的Ollama模型(llama3:8b/qwen2:7b等)base_url="http://192.168.2.205:11434", # Ollama服务地址(本地默认127.0.0.1:11434)temperature=0.1, # 低温度(0.1)保证回答精准,减少幻觉timeout=60 # 超时时间,避免长文本处理卡顿)# 2.2 初始化嵌入模型(适配Ollama的OpenAI兼容接口)embeddings = OpenAIEmbeddings(openai_api_base="http://192.168.2.205:11434/v1", # Ollama嵌入接口(固定/v1后缀)openai_api_key="ollama", # 固定占位符,无需真实API Keymodel="qwen3:8b" # 与LLM模型保持一致,保证嵌入和生成的一致性)# ========== 3. RAG核心流程实现 ==========def build_local_rag_kb(folder_path="knowledge_base"):"""构建本地RAG知识库:加载文档→分块→向量化→存入FAISS:param folder_path: 文档存放目录:return: 构建好的FAISS向量库对象"""# 步骤1:加载多类型文档(TXT/PDF)documents = [] # 存储所有加载的文档内容# 遍历目录下的所有文件for file_name in os.listdir(folder_path):file_path = os.path.join(folder_path, file_name)# 处理TXT文件(指定UTF-8编码,避免中文乱码)if file_name.endswith(".txt"):loader = TextLoader(file_path, encoding="utf-8")documents.extend(loader.load()) # 加载并追加到文档列表# 处理PDF文件(PyPDFLoader自动解析PDF每页内容)elif file_name.endswith(".pdf"):loader = PyPDFLoader(file_path)documents.extend(loader.load())# 步骤2:长文本分块(核心:保证语义完整+适配上下文窗口)text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, # 每个文本块500字符(可根据模型调整,如8k模型可设1000)chunk_overlap=50, # 块重叠50字符,避免语义割裂(比如一句话被拆成两个块)# 中文优先分隔符:按“空行→换行→句号→感叹号→问号→逗号→分号→空格”依次分割separators=["\n\n", "\n", "。", "!", "?", ",", ";", " "])split_docs = text_splitter.split_documents(documents)print(f"文档分块完成,共生成 {len(split_docs)} 个文本块")# 步骤3:向量化 + 存入FAISS向量库vector_db = FAISS.from_documents(split_docs, embeddings)# 保存向量库到本地(下次可直接加载,无需重复处理文档)vector_db.save_local("faiss_local_kb")print("本地向量库构建完成,已保存到 faiss_local_kb 文件夹")return vector_dbdef rag_qa(query, vector_db):"""RAG问答核心逻辑:用户提问→检索相似内容→LLM生成回答:param query: 用户提问:param vector_db: FAISS向量库对象"""# 步骤4:创建检索器(k=3:返回最相似的3个文本块,可根据需求调整)retriever = vector_db.as_retriever(search_kwargs={"k": 3})# 步骤5:创建RetrievalQA链(RAG核心)qa_chain = RetrievalQA.from_chain_type(llm=llm, # 本地大模型chain_type="stuff", # 适合短文本:直接将所有检索结果拼接传给LLM# chain_type="map_reduce" # 适合长文本:先分块生成,再汇总结果(可选)retriever=retriever, # 检索器return_source_documents=True # 返回检索到的源文档,便于溯源和验证)# 步骤6:执行问答并输出结果result = qa_chain({"query": query})# 格式化输出回答print("\n===== RAG 问答结果 =====")print(f"问题:{query}")print(f"回答:{result['result']}")# 输出检索到的源文档(便于验证回答的依据)print("\n===== 参考文档 =====")for i, doc in enumerate(result["source_documents"]):print(f"【参考{i + 1}】来源:{doc.metadata['source']}")# 只显示前200字符,避免输出过长print(f"内容:{doc.page_content[:200]}...")# ========== 4. 主流程执行 ==========if __name__ == "__main__":# 首次运行:构建知识库(加载→分块→向量化→入库)# 后续运行:注释该行,直接加载本地向量库(提升速度)vector_db = build_local_rag_kb(folder_path="knowledge_base")# 后续运行:直接加载本地已保存的向量库(无需重复处理文档)# vector_db = FAISS.load_local("faiss_local_kb", embeddings, allow_dangerous_deserialization=True)# 交互式问答:输入q退出while True:query = input("\n请输入你的问题(输入q退出):")if query.lower() == "q":breakrag_qa(query, vector_db)
4.3 关键代码解析
1. 文档加载模块
for file_name in os.listdir(folder_path):file_path = os.path.join(folder_path, file_name)if file_name.endswith(".txt"):loader = TextLoader(file_path, encoding="utf-8")documents.extend(loader.load())elif file_name.endswith(".pdf"):loader = PyPDFLoader(file_path)documents.extend(loader.load())
-
核心:遍历指定目录,根据文件后缀选择对应的 Loader;
-
关键:TXT 文件指定
encoding="utf-8",避免中文解码错误; -
扩展:可新增
CSVLoader/UnstructuredExcelLoader支持 Excel/CSV 文件。
2. 文本分块模块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50,separators=["\n\n", "\n", "。", "!", "?", ",", ";", " "])split_docs = text_splitter.split_documents(documents)
chunk_size=500:每个块 500 字符(适配 8B 模型的上下文窗口);chunk_overlap=50:块之间重叠 50 字符,保证语义连贯(比如 “人工智能” 不会被拆成 “人工” 和 “智能”);separators:中文优先分隔符,按 “语义从大到小” 排序,保证分块符合中文阅读习惯。
3. 向量库构建与保存
vector_db = FAISS.from_documents(split_docs, embeddings)vector_db.save_local("faiss_local_kb")
FAISS.from_documents:自动将分块后的文档向量化并存入 FAISS;save_local:将向量库保存到本地,避免每次运行都重新处理文档(首次运行耗时,后续秒级加载)
4. 检索与问答模块
retriever = vector_db.as_retriever(search_kwargs={"k": 3})qa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=retriever,return_source_documents=True)
search_kwargs={"k": 3}:检索最相似的 3 个文本块(k 值越大,参考信息越多,但可能增加上下文长度);chain_type="stuff":将所有检索结果直接拼接传给 LLM(适合短文本,速度快);return_source_documents=True:返回检索到的源文档,便于验证回答的准确性(溯源)。
4.4 运行与测试
-
将 PDF/TXT 文档放入
knowledge_base目录; -
执行
python rag_demo.py,程序会自动:-
加载文档→分块→向量化;
-
生成
faiss_local_kb向量库目录; -
进入交互式问答界面。
-
请输你的问题(输入q退出):产品手册中提到的核心功能有哪些?===== RAG 问答结果 =====问题:产品手册中提到的核心功能有哪些?回答:产品手册中明确的核心功能包括:1. 多端数据同步,支持PC/移动端实时同步;2. 智能检索,可按关键词/语义检索文档内容;3. 权限管理,支持多角色分级权限控制;4. 离线访问,下载文档后无需联网即可查看。===== 参考文档 =====【参考1】来源:knowledge_base/产品手册.pdf内容:产品核心功能:1. 多端数据同步:支持Windows/Mac/Android/iOS多端实时同步,数据更新延迟≤1秒;2. 智能检索:基于语义的全文检索,支持关键词高亮、模糊匹配;...
3. 后续运行优化
首次运行后,注释vector_db = build_local_rag_kb(...),取消注释vector_db = FAISS.load_local(...),直接加载本地向量库,大幅提升启动速度。
最后
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取