具身智能发展——通往通用人工智能的必由之路
学习资料:https://www.techrxiv.org/doi/full/10.36227/techrxiv.176948355.54623875
在人工智能(AI)的发展史上,“具身智能”(Embodied AI)正成为最引人注目的前沿范式。它不再是单纯的“数字大脑”,而是将智能赋予一个拥有“身体”的实体——机器人、无人机或人形机械臂——使其能够在物理世界中感知、理解、规划并执行任务。不同于传统AI仅在虚拟环境中处理数据,具身智能强调感知-决策-行动的闭环:通过与真实环境的交互,智能体不断学习、适应,并最终实现开放世界的通用能力。
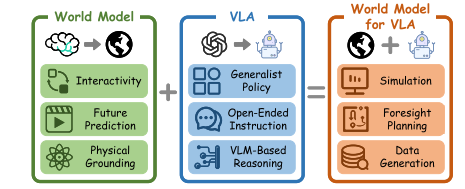
为什么具身智能如此重要?因为它是实现通用人工智能(AGI)的关键桥梁。大型语言模型(LLM)和多模态模型(如GPT系列)已在文本和图像领域展现惊人能力,但它们“离身”——无法真正“触摸”世界、验证物理规律,也难以处理长时序因果关系。具身智能则通过物理交互,让AI从“知道”走向“会做”,从抽象符号走向现实世界。模型是当前具身智能的关键里程碑,而世界模型(World Models)的引入,正在解决VLA的物理幻觉、计划不可执行性和数据稀缺三大瓶颈,推动具身AI迈向真正通用时代。
本文将系统梳理具身智能的发展脉络,从早期哲学与行为主义基础,到VLA模型的爆发,再到世界模型的创新范式,最后展望未来挑战与方向,为读者呈现一幅完整的技术演进图景。
一、早期萌芽阶段(1950s-1990s)
具身智能的思想根源可追溯至20世纪中叶的认知科学与哲学辩论。1950年,图灵在《计算机器与智能》中已暗示智能与物理体验的关联。1980年代,“莫拉维克悖论”(Moravec's Paradox)揭示了传统AI的致命短板:对人类而言“困难”的逻辑任务(如下棋),机器很容易;但“简单”的感知与运动(如婴儿抓物),机器却极难实现。这直接催生了行为主义AI的兴起。
1991年,罗德尼·布鲁克斯(Rodney Brooks)发表开创性论文《Intelligence without representation》,提出“无表征的智能”理念。他认为,智能无需复杂内部符号模型,而可直接从身体与环境的简单物理交互中涌现。布鲁克斯在MIT开发了“Genghis”等移动机器人,采用“ subsumption architecture”(包容架构):底层是反应式传感器-执行器回路,上层逐步叠加复杂行为,无需中央规划器。这一范式彻底颠覆了符号主义AI的“先思考后行动”逻辑,开启了“具身认知”(Embodied Cognition)时代。
1999年,罗尔夫·普费弗(Rolf Pfeifer)和克里斯蒂安·谢尔(Christian Scheier)在《Understanding Intelligence》一书中进一步系统化“身体化智能”理论:智能是整个身体结构与功能的综合体现,而非孤立大脑计算。2005年,琳达·史密斯(Linda Smith)提出“具身假说”(Embodiment Hypothesis),强调认知过程根植于身体-环境交互。
二、技术积累阶段(1990s-2022)
进入1990s-2020s,具身智能进入“技术深耕”期。强化学习(RL)成为主流:通过试错与奖励信号,机器人学会复杂控制,如DeepMind的AlphaGo虽非具身,但其RL思想迅速迁移到机器人领域。Sim-to-Real(仿真到真实)技术兴起,RLBench、Meta-World等模拟器让数据采集安全高效,避免真实世界风险。
这一时期的研究聚焦专用任务策略:视觉政策(Visual Policies)主导桌面操作、导航等场景。但局限明显——模型高度任务特定,泛化能力弱,无法处理开放世界指令。代表性工作包括波士顿动力Atlas的动态平衡控制、本田ASIMO的人形行走,以及谷歌RT-1(2022)初步将Transformer用于机器人动作生成。这些积累为后续大模型时代铺路:硬件(如Franka Panda机械臂)成熟,传感器(RGB-D相机、触觉)进步,数据集(BridgeData、RT-1)初具规模。
然而,传统方法仍依赖手工特征或有限示范,难以实现“零样本”泛化。VLA世界模型综述指出,这一阶段的具身AI“局限于孤立技能”,亟需互联网-scale知识注入。
三、VLA时代的突破(2022至今)
2022年以后,具身智能真正迎来了“爆发式”转折——VLA(Vision-Language-Action,视觉-语言-动作)模型的诞生,标志着具身AI从“专用任务策略”迈向“通用具身代理”的历史性跨越。
在此之前,机器人策略大多是任务特定(task-specific)的视觉策略,只能完成固定场景下的单一操作(如抓取特定物体或导航固定路线)。它们依赖手工设计的特征或有限示范数据,泛化能力极弱,一旦环境稍有变化(如光照改变、物体新位置)就会失效。2022年谷歌发布的RT-1虽然已开始尝试将Transformer用于动作生成,但仍属于“专用”范畴,无法处理开放世界的自然语言指令。
真正的转折点出现在2023年。谷歌DeepMind推出的RT-2(Robotics Transformer 2)被公认为VLA概念的开山之作。它首次将大型视觉-语言模型(VLM)作为骨干网络,把互联网规模的知识直接迁移到机器人控制中。RT-2不再把“视觉”“语言”“动作”割裂开来,而是把三者统一建模:机器人看到一张图像、听到一句指令,就能直接输出连续动作序列。例如,用户说“把苹果递给我”,RT-2就能理解语义、定位物体,并生成合理的抓取-传递轨迹。这就是VLA的核心优势——语义接地(semantic grounding):利用LLM/VLM海量常识,实现“零样本”或“少样本”泛化。
VLA时代的后续爆发可以用“井喷”来形容:
- 2023-2024:PaLM-E(谷歌)将3D感知注入LLM,支持更复杂的导航与多物体操作;Mobile ALOHA(斯坦福)用低成本双臂远程操作平台,实现了炒菜、整理物品等高难度长时序任务。
- 2024-2025:Octo、π0等模型进一步提升动作频率,从早期的1-5Hz提高到50-200Hz,实现端到端实时控制;GR-1、UniVLA等模型开始大规模视频预训练,让机器人能从互联网视频中“偷师”物理常识。
根据2026年1月发布的《Towards Generalist Embodied AI: A Survey on World Models for VLA Agents》(VLA世界模型综述),VLA模型已成为当前具身智能的关键里程碑。它首次将大型语言模型(LLM)和多模态模型的互联网-scale知识与低级控制策略对齐,使机器人能够跟随开放式指令,并在开放世界环境中泛化。
然而,VLA虽然在语义理解上取得了巨大进步,却暴露出三大致命短板,这正是世界模型诞生的直接驱动力:
- 物理幻觉(physical hallucination):VLA生成的动作往往“看起来合理”,但在物理上不可行(如物体穿模、力学不平衡、抓取失败)。
- 计划不可执行:LLM擅长高层次文本规划,却无法验证抽象策略在真实物理环境中的可行性,尤其在长时序任务中容易出现累积误差。
- 数据稀缺与安全风险:高质量机器人示范数据极少(真实世界采集成本高、危险),强化学习(RL)在真实机器人上直接训练可能损坏硬件或造成安全事故。
这些问题让VLA难以真正落地。VLA世界模型综述明确指出:“VLA模型在任务泛化上表现出色,但在真实世界部署中面临显著差距。” 正是为了填补这些差距,世界模型(World Models)应运而生。它不再是单纯的“预测器”,而是VLA的“物理大脑”——通过模拟未来状态、注入物理先验,帮助VLA生成真正物理接地(physically grounded)的动作。
四、世界模型的兴起
世界模型的核心思想是:把环境动态建模成一个未来预测器(future predictor),它能根据当前观测预测下一时刻的视觉、动作甚至整个场景演化,从而为VLA提供可验证的物理约束。这与传统LLM的“离散文本世界模型”形成鲜明对比——世界模型处理的是连续物理动态,真正实现了“所想即所得”的具身闭环。
2026年的VLA世界模型综述首次提出统一的四范式分类法,并为每个范式给出形式化定义、二级子分类、演化轨迹和代表性工作。这套分类是目前最权威、最系统的框架:
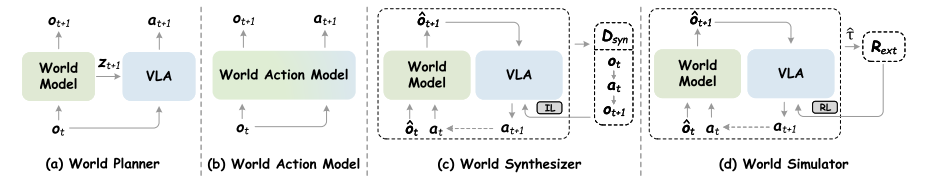
- ①World Planner(世界规划器)定义:世界模型
作为前向动力学模型,合成未来观测
或隐特征,作为策略
的语义条件。
- 演 化:早期(如UniPi 2023、SuSIE 2023)把规划当作高保真视频生成任务,用扩散模型预测像素级未来图像,再通过逆动力学求动作;中期转向隐式规划(如V-JEPA 2、PIVOT-R),避免无关视觉细节干扰;2025年后主流是视频扩散模型+潜在特征指导(如VPP、MinD、TriVLA、Genie Envisioner),GO-1引入离散潜在表示,MoWM则实现混合架构。 作用:让规划不再是“纸上谈兵”,而是基于预测物理动态的可执行规划。
- ②World Action Model(世界动作模型)定义:生成式建模未来观测与动作的联合分布:
- 演化:自回归范式(AR)最早流行(如GR-1/2、WorldVLA、RynnVLA-002),把观测和动作统一为token序列;扩散范式(Diff)后来居上(如UD-VLA、dVLA离散扩散;DUST、FLARE实值扩散),有效缓解量化损失和多步误差。 代表作:Seer、F1、FlowVLA、CoT-VLA、DreamVLA等引入多模态思维链,进一步强化物理推理。 作用:直接端到端生成语义对齐且物理一致的动作序列,是VLA最核心的“动作大脑”。
- ③World Synthesizer(世界合成器)定义:构建可扩展数据引擎,合成交错的观测-动作轨迹
,用于模仿学习。
-
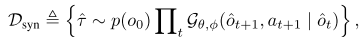
- 演化:WristWorld专注腕部视角增强;Genie Envisioner、Ctrl-World采用动作条件生成;DreamGen、GigaWorld-0则先合成视觉轨迹再用逆动力学推断动作。 作用:彻底解决“数据稀缺”问题,把世界模型变成“无限数据工厂”。
- ④World Simulator(世界模拟器)定义:将动作条件世界模型作为虚拟环境,支持RL策略优化
-
演化:WorldGym、Genie Envisioner用于任务评估;World4RL、WMPO、SRPO、VLA-RFT、NORA-1.5等提供稀疏/稠密奖励,实现闭环优化;VLA-Reasoner、AdaPower支持测试时自适应。 作用:让RL训练在“安全沙盒”中进行,极大降低真实世界风险。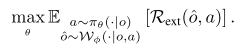
演化时间线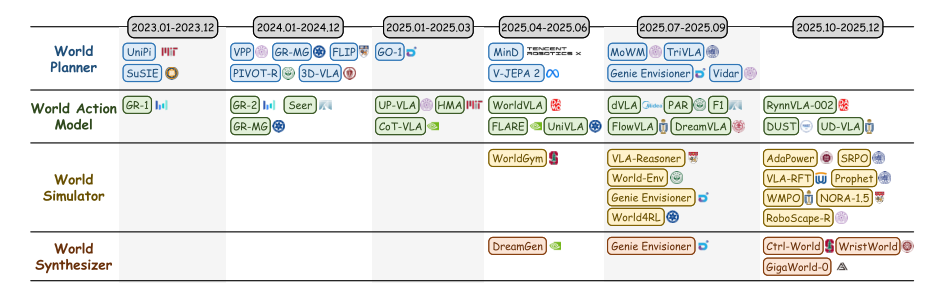 2023-2024年以Planner和Action Model为主,聚焦推理与控制;2025年视频生成模型爆发后,Synthesizer和Simulator迅猛增长,成为主流。
2023-2024年以Planner和Action Model为主,聚焦推理与控制;2025年视频生成模型爆发后,Synthesizer和Simulator迅猛增长,成为主流。
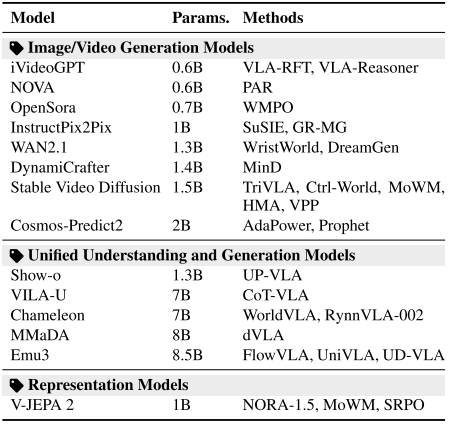
世界模型的底层依赖三大基础模型:图像/视频生成模型(Stable Video Diffusion、WAN2.1)、统一理解-生成模型(Emu3、Chameleon)、表征模型(V-JEPA 2)。它们共同构成了VLA的“物理引擎”。
通过这四大范式,世界模型成功弥合了VLA的三大痛点:物理幻觉被预测动态压制、计划可执行性得到验证、数据与安全问题被合成与模拟解决。VLA世界模型综述在LIBERO和CALVIN基准上的性能报告(Table 6-7)显示:SRPO Online、RynnVLA-002、DreamVLA等已将成功率推至99.2%,平均任务长度达4.44,接近仿真饱和。这也说明,未来必须转向更具挑战性的真实世界验证。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)