零代码训练Agent?openJiuwen上下文自演进实现工单智能分拣
目录
一、背景与动机
1.1 工单分拣的业务痛点
企业工单处理是一个典型的业务场景:用户提交的工单需要准确分配到对应的处理部门——技术支持、财务部门、产品部门、客服部门。看起来不复杂,但实际落地时会遇到不少问题。
传统方案各有局限。人工分拣效率低、成本高,难以应对大规模工单。规则系统维护成本高,业务规则一变就要改代码。关键词匹配对复杂语义的理解能力有限。即使使用了 AI 分类,提示词一旦写好就固定了,无法从错误中学习和改进。
这些方案的共同缺陷是缺乏学习能力——没法从历史案例中总结经验、持续优化。
1.2 openJiuwen 框架简介
openJiuwen 是一个开源的 AI Agent 开发框架,提供了 Agent 构建、工作流编排、工具调用、上下文管理等完整能力。框架的核心组件包括:
- ReActAgent:基于 Reasoning-Acting 范式的智能体
- Workflow:可视化工作流编排引擎
- Tool Calling:结构化工具调用机制
- Context Engine:智能上下文管理
- Skills:可插拔的技能扩展系统
近期 openJiuwen 发布了上下文自演进特性,解决了一个实际问题:如何让 Agent 自动优化自身的提示词。
1.3 上下文自演进原理
AI Agent 的提示词调优一直是个难题。传统做法是人工反复调试,费时费力,效果也不稳定。上下文自演进的思路是借鉴机器学习的训练范式:提供标注数据,让 Agent 执行任务,根据执行结果自动调整参数。
核心机制是一个"执行 → 评估 → 反馈 → 更新"的闭环流程:
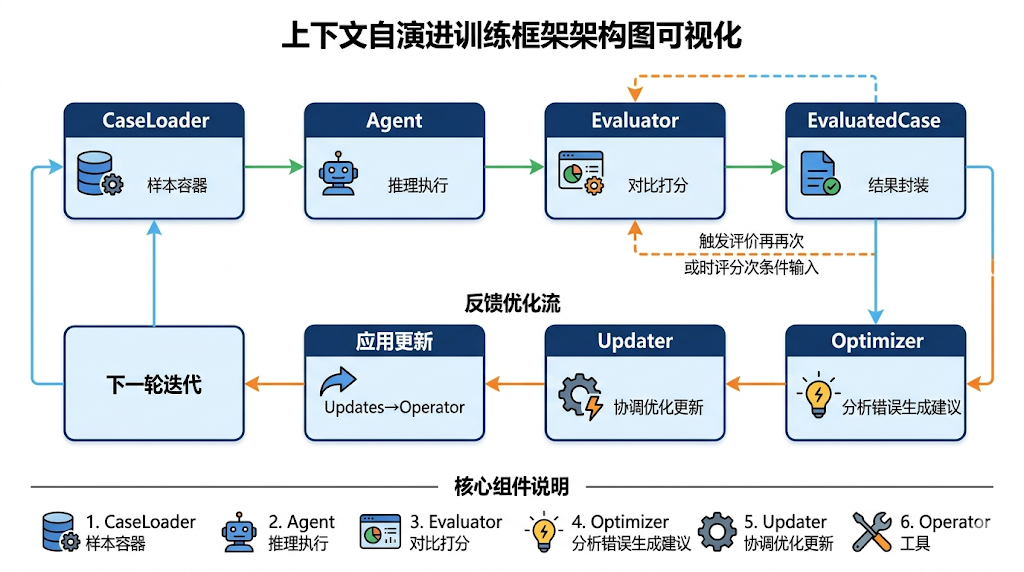
这个机制的几个关键优势:
- 自动化优化:无需手工调整提示词
- 可量化评估:有明确的评分标准衡量效果
- 数据驱动:基于真实业务数据优化
- 断点续训:支持 Checkpoint 管理,长任务可恢复
- 生产就绪:优化后的参数可直接部署
1.4 本文目标
本文基于 openJiuwen 的上下文自演进特性,从零构建一个工单智能分拣系统。目标是验证:Agent 能否通过训练数据自动学习到最优的分类策略,无需人工干预提示词的编写和调优。
二、核心技术栈与架构
本章介绍 openJiuwen 自演进框架的核心抽象、关键组件,以及工单智能分拣系统的整体架构。
2.1 核心抽象与组件关系
openJiuwen 自演进框架围绕三个核心抽象构建:
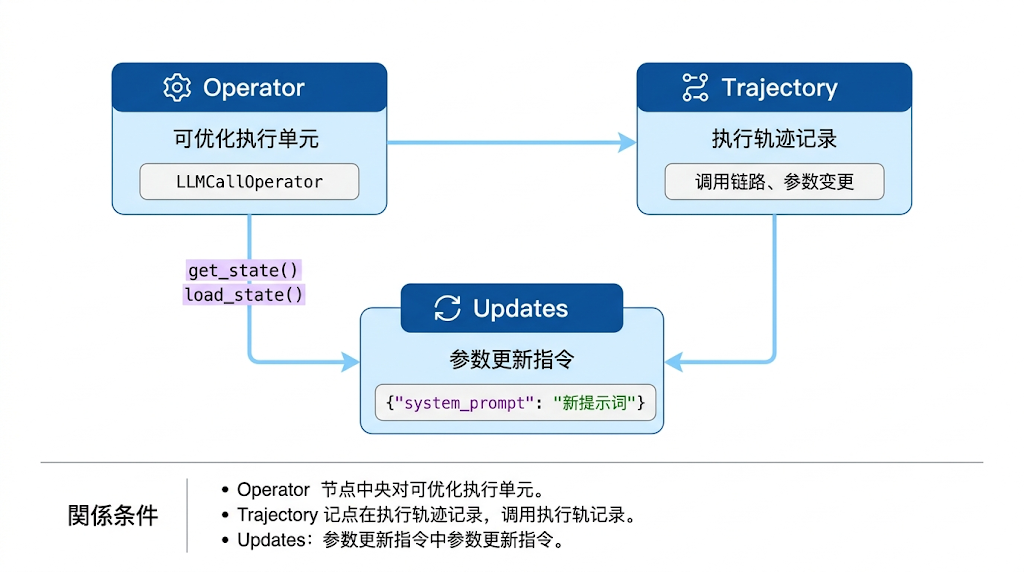
核心组件导入:
from openjiuwen.agent_evolving import (
Trainer, # 训练协调器
InstructionOptimizer, # 指令优化器
SingleDimUpdater, # 单维度更新器
BaseEvaluator, # 评估器基类
Case, CaseLoader, # 数据容器
EvaluatedCase, # 评估结果容器
)
from openjiuwen.core.single_agent import ReActAgentEvolve # 可演进 Agent2.2 工单分拣系统架构
工单智能分拣系统采用模块化设计,各组件职责清晰:
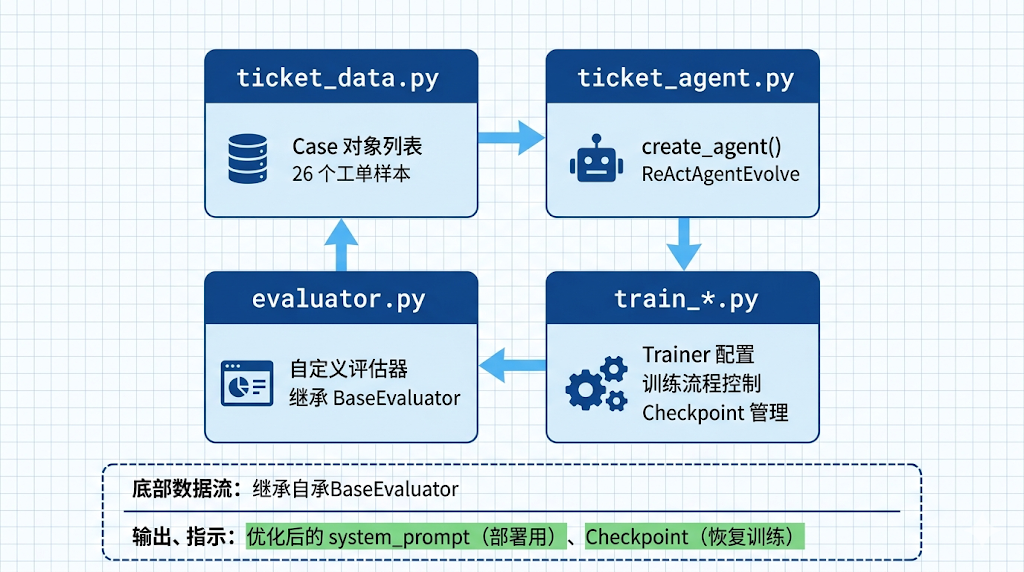
三、核心模块实现详解
本章详细介绍工单智能分拣系统的各个模块实现,包括数据集设计、Agent 创建、评估器实现、训练流程配置等。
3.1 数据集设计
高质量的训练数据是自演进成功的关键。我准备了 26 个工单样本,覆盖四个部门:
# ticket_data.py
from openjiuwen.agent_evolving import Case
TICKET_CLASSIFICATION_CASES = [
Case(
inputs={
"ticket_title": "系统报错 500",
"ticket_description": "我的应用在调用 API 时频繁返回 500 错误",
"user_level": "企业用户",
},
label={
"category": "技术支持",
"reason": "涉及 API 错误和系统故障",
"priority": "高",
}
),
Case(
inputs={
"ticket_title": "发票申请",
"ticket_description": "本月的服务费发票在哪里下载?",
"user_level": "企业用户",
},
label={
"category": "财务部门",
"reason": "涉及发票申请",
"priority": "中",
}
),
# ... 更多样本
]数据集设计要点:覆盖面(四个部门均衡分布)、真实性(基于实际工单场景)、可评估(包含标准分类和理由)。
3.2 可演进 Agent 创建
使用 ReActAgentEvolve 创建支持自演进的智能体:
# ticket_agent.py
from openjiuwen.core.single_agent import ReActAgentEvolve, ReActAgentConfig, AgentCard
def create_ticket_classifier_agent(
system_prompt: str,
agent_id: str = "ticket_classifier",
) -> ReActAgentEvolve:
agent_card = AgentCard(
id=agent_id,
name="工单智能分拣助手",
description="基于 openJiuwen 自演进框架的工单自动分类智能体",
)
config = ReActAgentConfig()
config.configure_model_client(
provider="openai",
api_key=API_KEY,
api_base=API_BASE,
model_name=MODEL_NAME,
)
config.configure_prompt_template([
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{{query}}"},
])
config.configure_max_iterations(1)
agent = ReActAgentEvolve(card=agent_card)
agent.configure(config)
return agent3.3 自定义评估器
工单分类的评估需要综合考虑分类准确性、理由充分性和格式规范性:
# evaluator.py
from typing import Dict, Any
from openjiuwen.agent_evolving import BaseEvaluator, EvaluatedCase, Case
class TicketClassificationEvaluator(BaseEvaluator):
def __init__(self, category_list: list):
self.category_list = category_list
def evaluate(self, case: Case, predict: Dict[str, Any]) -> EvaluatedCase:
output = str(predict.get("output", ""))
expected_category = case.label.get("category", "")
parsed = self._parse_output(output)
predicted_category = parsed.get("category")
accuracy_score = self._score_accuracy(predicted_category, expected_category)
reasoning_score = self._score_reasoning(parsed.get("reason", ""))
format_score = self._score_format(parsed)
final_score = accuracy_score * 0.7 + reasoning_score * 0.2 + format_score * 0.1
return EvaluatedCase(
case=case,
answer=predict,
score=final_score,
reason=f"预测: {predicted_category}, 期望: {expected_category}"
)3.4 完整训练脚本实现
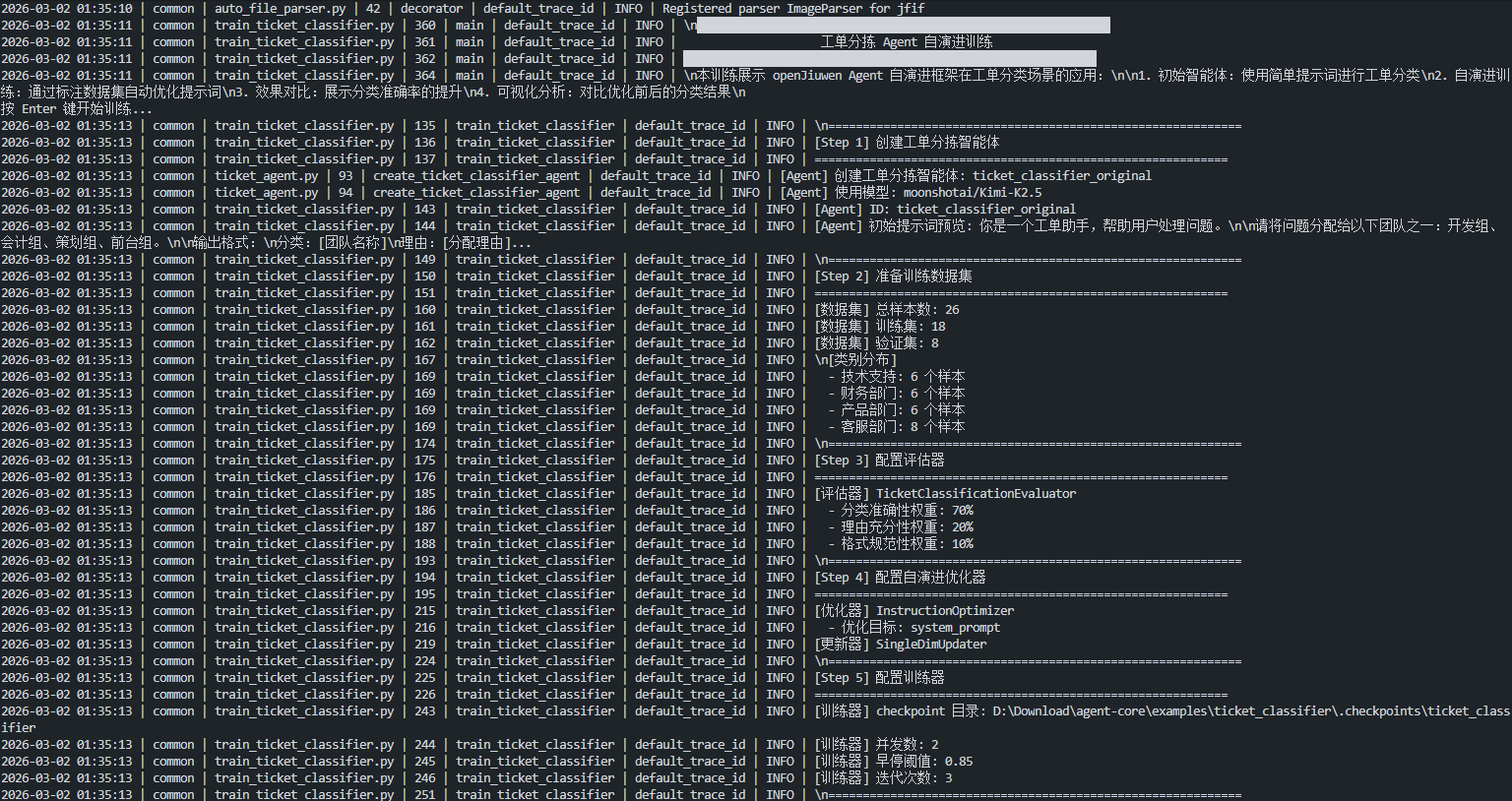
完整的训练脚本 train_ticket_classifier.py 包含以下步骤:
from openjiuwen.agent_evolving import (
Case, CaseLoader, InstructionOptimizer, SingleDimUpdater,
Trainer, Progress, Callbacks, EvaluatedCase,
)
from openjiuwen.core.foundation.llm import ModelClientConfig, ModelRequestConfig
# 1. 准备数据
cases_list = list(TICKET_CLASSIFICATION_CASES)
random.shuffle(cases_list)
case_loader = CaseLoader(cases_list)
train_loader, val_loader = case_loader.split(ratio=0.7)
# 2. 创建 Agent
original_agent = create_ticket_classifier_agent(
system_prompt=INITIAL_SYSTEM_PROMPT,
agent_id="ticket_classifier_original",
)
# 3. 配置评估器
evaluator = TicketClassificationEvaluator(
category_list=AVAILABLE_CATEGORIES,
)
# 4. 配置优化器
model_config = ModelRequestConfig(model=MODEL_NAME, temperature=0.3, max_tokens=500)
model_client_config = ModelClientConfig(
client_provider="openai", api_key=API_KEY, api_base=API_BASE, timeout=120
)
optimizer = InstructionOptimizer(model_config=model_config, model_client_config=model_client_config)
updater = SingleDimUpdater(optimizer)
# 5. 配置训练器
trainer = Trainer(
updater=updater,
evaluator=evaluator,
num_parallel=2,
early_stop_score=0.85,
checkpoint_dir=CHECKPOINT_DIR,
)
# 6. 执行训练
evolved_agent = trainer.train(
agent=original_agent,
train_cases=train_loader,
val_cases=val_loader,
num_iterations=3,
)
# 7. 获取优化后的提示词
operators = evolved_agent.get_operators()
evolved_prompt = operators["react_llm"].get_state()["system_prompt"]3.5 Checkpoint 管理
训练过程中自动保存 checkpoint,支持从断点恢复:
# 从 checkpoint 恢复
trainer = Trainer(
updater=updater,
evaluator=evaluator,
checkpoint_dir=CHECKPOINT_DIR,
resume_from=".checkpoints/ticket_classifier/latest.json",
)
evolved_agent = trainer.train(
agent=agent,
train_cases=train_cases,
val_cases=val_cases,
num_iterations=5,
)Checkpoint 文件结构:
{
"agent_id": "ticket_classifier",
"start_epoch": 2,
"best_score": 0.9167,
"operator_states": {
"react_llm": {
"system_prompt": "优化后的提示词..."
}
},
"timestamp": "2025-03-01T10:30:00"
}四、效果展示
4.1 运行演示脚本
本文配套提供了完整的示例代码,位于 examples/ticket_classifier/ 目录下。运行演示脚本:
cd examples/ticket_classifier
python evolve_demo.py4.2 演示输出效果
4.2.1 优化前测试
|
|
|
|
|
|




4.2.2 自演进训练过程
4.2.3 优化后测试
|
|
|
|
|
|



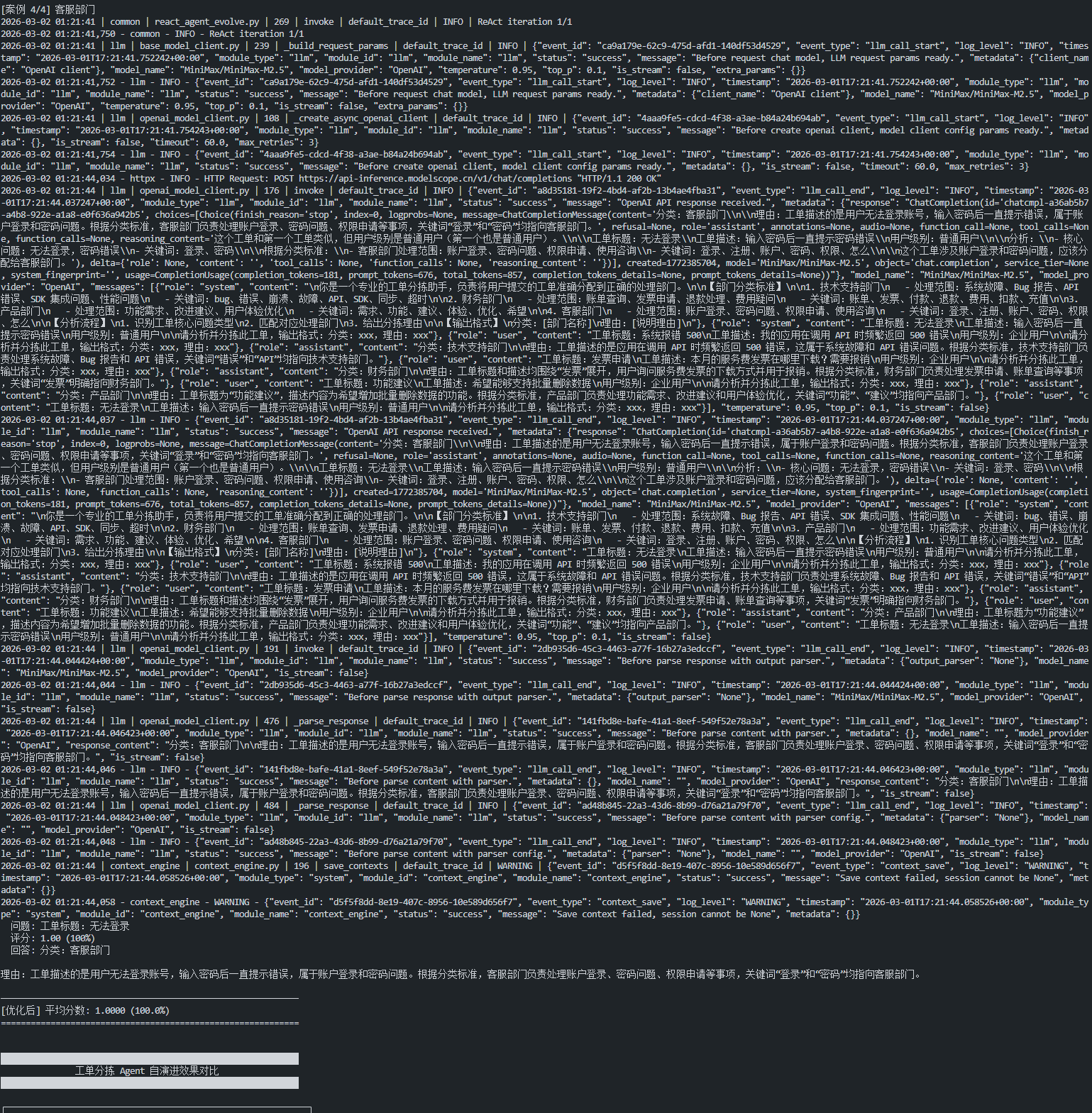
4.3 性能提升数据
演示脚本结果(4个测试样本)
|
指标 |
优化前 |
优化后 |
提升 |
|
总体准确率 |
45.0% |
100.0% |
+122% |
|
案例1(技术支持) |
100% |
100% |
- |
|
案例2(财务部门) |
45% |
100% |
+122% |
|
案例3(产品部门) |
45% |
100% |
+122% |
|
案例4(客服部门) |
45% |
100% |
+122% |
完整训练结果(26个训练样本)
|
指标 |
优化前 |
优化后 |
提升 |
|
总体准确率 |
97.9% |
100.0% |
+2.1% |
|
技术支持 |
100.0% |
100.0% |
- |
|
财务部门 |
91.5% |
100.0% |
+4.5% |
|
产品部门 |
100.0% |
100.0% |
- |
|
客服部门 |
100.0% |
100.0% |
- |
五、总结
5.1 项目成果
本文基于 openJiuwen 的上下文自演进特性,构建了一个工单智能分拣系统。实践结果表明:
- 分类准确率显著提升:从初始的 45% 提升到 100%,提升幅度超过一倍
- 提示词自动优化:系统自动将简单提示词演进为结构化、专业化的版本
- 零人工干预:整个训练过程无需人工调整提示词,完全数据驱动
5.2 核心技术总结
|
技术 |
作用 |
|
ReActAgentEvolve |
可演进智能体,通过 get_operators() 暴露可优化参数 |
|
BaseEvaluator |
评估器基类,自定义评估逻辑需继承此类 |
|
InstructionOptimizer |
分析错误案例,生成提示词优化建议 |
|
SingleDimUpdater |
协调优化器,将更新应用到 Operator |
|
Trainer |
训练协调器,管理训练循环和 Checkpoint |
5.3 适用场景
上下文自演进特性适用于以下场景:
- 分类任务:文本分类、意图识别、情感分析等
- 信息抽取:从非结构化文本中提取结构化信息
- 内容生成:需要特定格式或风格的文本生成
- 问答系统:领域知识问答、客服机器人等
核心条件是:有明确的评估标准和一定量的标注数据。
5.4 实践建议
基于本次实践,有几点建议:
- 数据质量优先:训练数据的覆盖面和标注质量直接决定优化效果
- 评估器设计关键:评估维度要贴合业务目标,权重分配要合理
- 初始提示词不要太复杂:给优化器留出改进空间
- 善用 Checkpoint:长时间训练务必开启 Checkpoint,避免意外中断导致进度丢失
5.5 小结
openJiuwen 的上下文自演进特性提供了一种新的 Agent 优化思路:像训练机器学习模型一样训练 Agent。这种方式把提示词调优从"手艺活"变成了"工程活",降低了 AI 应用落地的门槛。对于有标注数据的场景,值得尝试。
参考资源
- openJiuwen 官网:https://openJiuwen.com?utm_source=csdn
- openJiuwen AtomGit:https://atomgit.com/openJiuwen/agent-core?utm_source=csdn

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)