告别人工 Code Review?用 JiuwenClaw 构建自动化审查流水线
告别人工 Code Review?用 JiuwenClaw 构建自动化审查流水线
第一章|项目背景与框架介绍
1.1 项目背景与痛点
代码审查(Code Review)是保障代码质量的基本手段。但实际工作中,Reviewer 花在语法错误、风格问题、安全隐患上的时间远多于有价值的逻辑讨论。
主要有三个问题:
- 重复劳动:语法错误、格式问题、基础安全问题,每次都要人工检查
- 工具分散:Lint 工具、安全扫描、复杂度分析各跑各的,结果难以整合
- 缺乏标准:代码质量没有统一评分,问题严重程度全凭感觉
本文介绍一个基于 JiuwenClaw 构建的代码审查助手,整合 Ruff、Radon、Bandit 三个工具,自动生成质量评分和改进建议,支持飞书推送和本地报告。
主要内容:多层次代码分析架构、综合评分引擎、报告生成器、多代码来源支持、完整实现流程
1.2 JiuwenClaw 框架介绍
openJiuwen 是一个开源的 AI Agent 开发组织,JiuwenClaw 是其核心开发框架。本文的代码审查助手基于 JiuwenClaw 的技能系统构建。
JiuwenClaw 技能系统的特点:
| 能力 | 说明 |
|---|---|
| 模块化技能 | 每个 Skill 可包含多个 Python 模块,便于分层设计 |
| 工具集成 | 声明 allowed_tools 获取系统工具权限,执行外部命令 |
| 文件操作 | 支持读写文件,便于扫描代码和生成报告 |
| 多渠道推送 | 支持飞书等渠道推送审查报告 |
代码审查助手采用分层设计:代码采集层(LocalCollector、AtomGitClient)、分析引擎层(Ruff、Radon、Bandit、ScoreCalculator)、报告生成层(ReportGenerator、FeishuPublisher)。各层职责清晰,易于扩展和维护。
1.3 项目环境配置
实际运行环境
| 项目 | 配置值 |
|---|---|
| 项目路径 | D:\Download\jiuwenclaw |
| 操作系统 | Windows 10 |
| Python | 3.11+ |
| 模型服务 | 智谱AI (GLM-4.7) |
代码分析工具
| 工具 | 版本 | 功能 | 语言 |
|---|---|---|---|
| Ruff | 0.4.0+ | Python Linting(替代 Pylint/Flake8) | Python |
| Radon | 6.0.0+ | 圈复杂度分析 | Python |
| Bandit | 1.7.0+ | 安全漏洞扫描 | Python |
| ESLint | 9.0+ | 代码质量检查 | JavaScript/TypeScript |
| Checkstyle | 10.12+ | 代码风格检查 | Java |
| golangci-lint | latest | 综合代码检查 | Go |
| Clippy | latest | Lint 检查 | Rust |
核心文件位置
D:\Download\jiuwenclaw\
├── .env # 环境变量配置
├── workspace/
│ └── agent/
│ ├── reports/code-review/ # 审查报告输出目录
│ └── skills/code-review/ # 技能模块
│ ├── SKILL.md # 技能定义 v1.1.0
│ ├── config.py # 配置管理
│ ├── run_review.py # 入口脚本
│ ├── models/ # 数据模型层
│ ├── collectors/ # 代码采集层
│ ├── analyzers/ # 分析引擎层
│ └── generators/ # 报告生成层
第二章|技术方案
2.1 分层架构设计
代码审查助手采用三层架构:代码采集层、分析引擎层、报告生成层。
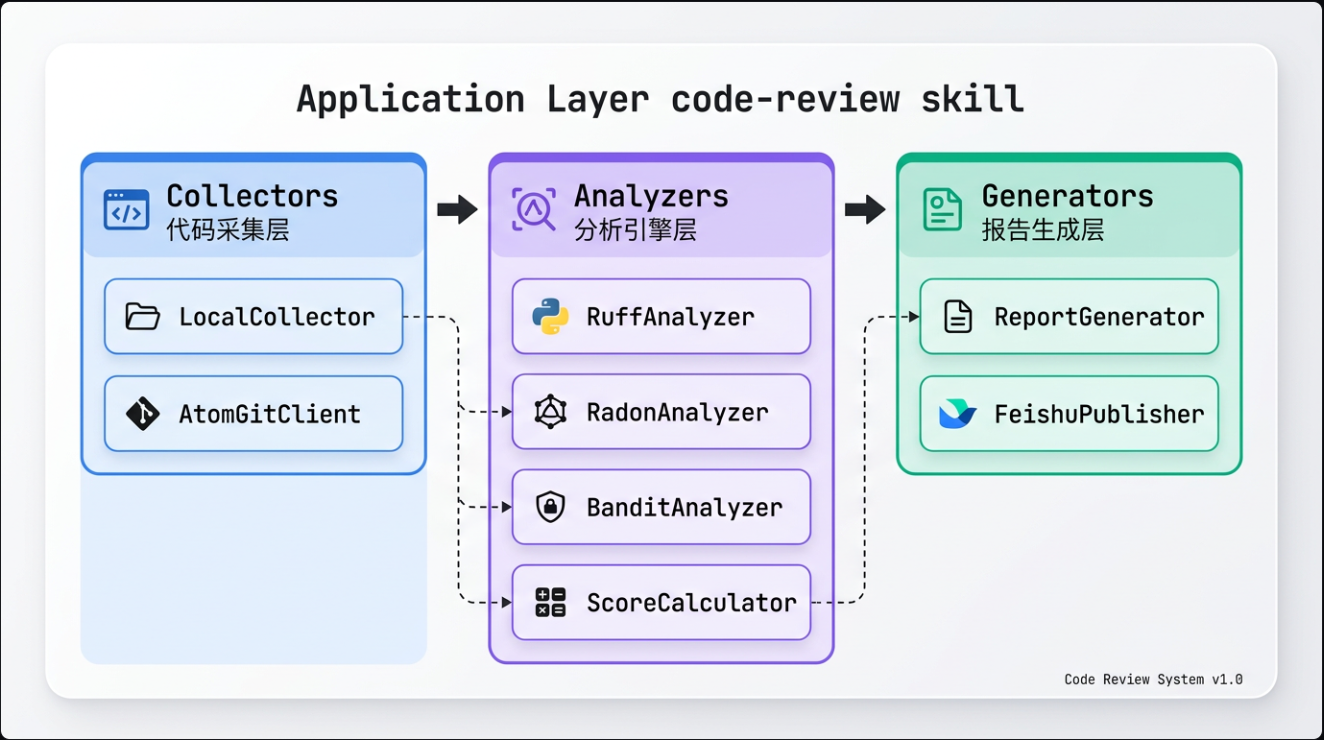
2.2 数据处理流程
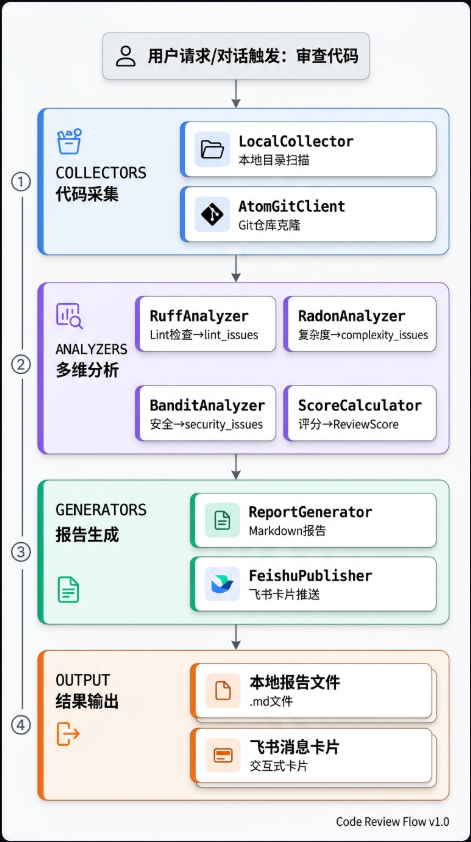
2.3 核心组件概览
| 组件 | 类型 | 职责 | 所在模块 |
|---|---|---|---|
| LocalCollector | Collector | 本地代码文件采集 | collectors/local_collector.py |
| AtomGitClient | Collector | Git 仓库克隆与文件获取 | collectors/atomgit_client.py |
| RuffAnalyzer | Analyzer | Lint 语法检查 | analyzers/ruff_analyzer.py |
| RadonAnalyzer | Analyzer | 复杂度分析 | analyzers/radon_analyzer.py |
| BanditAnalyzer | Analyzer | 安全漏洞扫描 | analyzers/bandit_analyzer.py |
| ScoreCalculator | Analyzer | 综合评分计算 | analyzers/score_calculator.py |
| ReportGenerator | Generator | Markdown 报告生成 | generators/report_generator.py |
| FeishuPublisher | Generator | 飞书消息推送 | generators/feishu_publisher.py |
2.4 评分体系设计
多维度加权评分:
| 维度 | 权重 | 计算依据 |
|---|---|---|
| 代码质量 | 35% | Lint 问题数量与严重程度 |
| 安全性 | 30% | 安全漏洞数量与严重程度 |
| 复杂度 | 20% | 圈复杂度与高复杂度函数数量 |
| 风格 | 15% | 代码风格问题 |
综合评分等级:
| 等级 | 分数范围 | 状态 |
|---|---|---|
| A | 90-100 | 优秀 |
| B | 80-89 | 良好 |
| C | 70-79 | 合格 |
| D | 60-69 | 需改进 |
| F | <60 | 不通过 |
第三章|核心实现
3.1 目录结构
workspace/agent/skills/code-review/
├── SKILL.md # 技能定义
├── config.py # 配置管理
├── run_review.py # 入口脚本
│
├── models/ # 数据模型层
│ ├── code_issue.py # 代码问题模型
│ ├── code_metrics.py # 代码指标模型
│ ├── review_result.py # 审查结果模型
│ └── review_score.py # 评分模型
│
├── collectors/ # 代码采集层
│ ├── local_collector.py # 本地文件采集
│ └── atomgit_client.py # Git 仓库客户端
│
├── analyzers/ # 分析引擎层
│ ├── ruff_analyzer.py # Ruff Lint 分析
│ ├── radon_analyzer.py # Radon 复杂度分析
│ ├── bandit_analyzer.py # Bandit 安全分析
│ └── score_calculator.py # 综合评分计算
│
└── generators/ # 报告生成层
├── report_generator.py # Markdown 报告生成
└── feishu_publisher.py # 飞书推送
3.2 SKILL.md 定义
---
name: code-review
version: 2.0.1
description: 多语言代码审查助手,支持 Python/JavaScript/Java/Go/Rust
allowed_tools: [mcp_exec_command, read_file, write_file]
---
# 多语言代码审查助手
审查 Git 仓库代码,检测安全漏洞、代码质量问题、复杂度问题。
3.3 使用方式
审查远程仓库:
python run_review.py clone --url <仓库地址>
审查本地代码:
python run_review.py local --path <路径>
3.4 评分等级
| A | B | C | D | F |
|---|---|---|---|---|
| 90-100 | 80-89 | 70-79 | 60-69 | <60 |
| 优秀 | 良好 | 合格 | 需改进 | 不通过 |
3.5 核心代码实现
3.5.1 数据模型层
代码问题模型 (CodeIssue) - 表示单个代码问题,包含位置、严重程度、分类等信息:
# models/code_issue.py
from dataclasses import dataclass
@dataclass
class CodeIssue:
file: str # 文件路径
line: int # 行号
severity: str # 严重级别: error/warning/info
category: str # 类别: lint/complexity/security/style
message: str # 问题描述
rule: str # 规则ID (如 E501, B101)
source: str # 来源工具 (ruff/bandit/radon)
column: int = 0 # 列号
suggestion: str = "" # 修复建议
def to_dict(self) -> dict:
return {
"file": self.file,
"line": self.line,
"severity": self.severity,
"category": self.category,
"message": self.message,
"rule": self.rule,
"source": self.source,
"suggestion": self.suggestion,
}
代码指标模型 (CodeMetrics) - 统计代码行数、函数数量、复杂度等指标:
# models/code_metrics.py
from dataclasses import dataclass
@dataclass
class CodeMetrics:
total_lines: int = 0
code_lines: int = 0
comment_lines: int = 0
blank_lines: int = 0
avg_complexity: float = 0.0
max_complexity: int = 0
complexity_rank: str = "A"
high_complexity_count: int = 0
maintainability_index: float = 0.0
function_count: int = 0
class_count: int = 0
file_count: int = 0
评分模型 (ReviewScore) - 多维度评分与等级计算:
# models/review_score.py
from dataclasses import dataclass
@dataclass
class ReviewScore:
overall: float = 0.0 # 综合评分 (0-100)
quality_score: float = 0.0 # 代码质量分
security_score: float = 0.0 # 安全评分
complexity_score: float = 0.0 # 复杂度评分
style_score: float = 0.0 # 风格评分
grade: str = "C" # 等级: A/B/C/D/F
passed: bool = False # 是否通过审查
@staticmethod
def score_to_grade(score: float) -> str:
if score >= 90: return "A"
elif score >= 80: return "B"
elif score >= 70: return "C"
elif score >= 60: return "D"
else: return "F"
3.5.2 分析引擎层
评分计算器 (ScoreCalculator) - 根据各类问题计算综合评分,采用多维度加权评分体系:
# analyzers/score_calculator.py
from dataclasses import dataclass
@dataclass
class ScoringWeights:
quality: float = 0.35 # 代码质量权重
security: float = 0.30 # 安全性权重
complexity: float = 0.20 # 复杂度权重
style: float = 0.15 # 风格权重
class ScoreCalculator:
SEVERITY_PENALTY = {"error": 5.0, "warning": 2.0, "info": 0.5}
def calculate(self, result: ReviewResult) -> ReviewScore:
score = ReviewScore()
score.quality_score = self._calc_quality_score(result.lint_issues)
score.security_score = self._calc_security_score(result.security_issues)
score.complexity_score = self._calc_complexity_score(result.metrics)
score.style_score = self._calc_style_score(result.style_issues)
# 加权计算总分
score.overall = (
score.quality_score * 0.35 +
score.security_score * 0.30 +
score.complexity_score * 0.20 +
score.style_score * 0.15
)
score.grade = ReviewScore.score_to_grade(score.overall)
score.passed = score.overall >= 60.0
return score
3.5.3 代码采集层
本地采集器 (LocalCollector) - 扫描本地目录,收集代码文件:
# collectors/local_collector.py
from pathlib import Path
from typing import List
class LocalCollector:
DEFAULT_EXCLUDES = [
"**/test_*.py", "**/*_test.py", "**/tests/**",
"**/venv/**", "**/.venv/**", "**/__pycache__/**",
"**/node_modules/**", "**/.git/**",
]
def __init__(self, path: str, max_file_size: int = 1024 * 1024):
self.path = Path(path).resolve()
self.max_file_size = max_file_size
def collect(self) -> ScanResult:
result = ScanResult()
for py_file in self.path.rglob("*.py"):
if self._should_exclude(py_file):
continue
size = py_file.stat().st_size
if size <= self.max_file_size:
result.files.append(FileInfo(str(py_file), ...))
return result
3.5.4 报告生成层
报告生成器 (ReportGenerator) - 生成富文本格式的代码审查报告:
# generators/report_generator.py
from pathlib import Path
class ReportGenerator:
def __init__(self, output_dir: str = "workspace/agent/reports/code-review"):
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
def generate(self, result: "ReviewResult") -> str:
lines = []
icon = ":white_check_mark:" if result.score.passed else ":x:"
lines.append(f"# {icon} 代码审查报告")
# 基本信息、评分、问题统计、问题详情、改进建议...
lines.append(f"| 综合评分 | **{result.score.overall:.1f}** ({result.score.grade}) |")
return "
".join(lines)
def save_report(self, content: str, result: "ReviewResult") -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"review_{result.review_type}_{timestamp}.md"
filepath = self.output_dir / filename
filepath.write_text(content, encoding="utf-8")
return str(filepath)
第四章|配置与部署
4.1 环境变量配置
在项目根目录的 .env 文件中配置:
# 模型配置(智谱AI GLM-4.7)
MODEL_PROVIDER="OpenAI"
MODEL_NAME="glm-4.7"
API_BASE="https://open.bigmodel.cn/api/paas/v4"
API_KEY="your-api-key"
# 飞书推送
FEISHU_APP_ID=cli_xxx
FEISHU_APP_SECRET=xxx
FEISHU_REVIEW_CHAT_ID=oc_xxx
4.2 飞书配置详细说明
飞书推送需要以下配置,按步骤获取:
- 创建飞书应用
-
- 登录 飞书开放平台
- 创建企业自建应用,获取
App ID和App Secret
- 申请权限
-
- 在权限管理中申请以下权限:
- 在权限管理中申请以下权限:
-
-
im:message(发送消息)im:message:send_as_bot(以机器人身份发送)im:chat(获取群信息)
-
- 获取 Chat ID
-
- 打开飞书,进入需要推送的群聊
- 点击群设置 → 群信息 → 复制群 ID(格式如
oc_xxx) - 或者通过群机器人 Webhook 获取
- 启用应用
-
- 在应用管理中启用应用
- 将应用添加到目标群聊
- 测试推送
-
- 配置完成后,发送审查请求测试推送是否正常
配置完成后,代码审查报告将自动推送到指定群聊。
第五章|测试验证
| 测试方式 | 说明 |
|---|---|
| 飞书对话 | 通过飞书私聊机器人发送审查请求 |
| Web 对话 | 通过 JiuwenClaw Web 界面发送审查请求 |
5.1 飞书对话测试
JiuwenClaw 作为远程智能管家,支持通过飞书与机器人对话进行代码审查。
前提条件:
- 启动 JiuwenClaw 服务
- 配置飞书机器人并建立 WebSocket 长连接
- code-review 技能已部署到项目目录
在飞书中私聊机器人发送消息:
测试消息:
审查这个项目:https://github.com/openclaw/openclaw
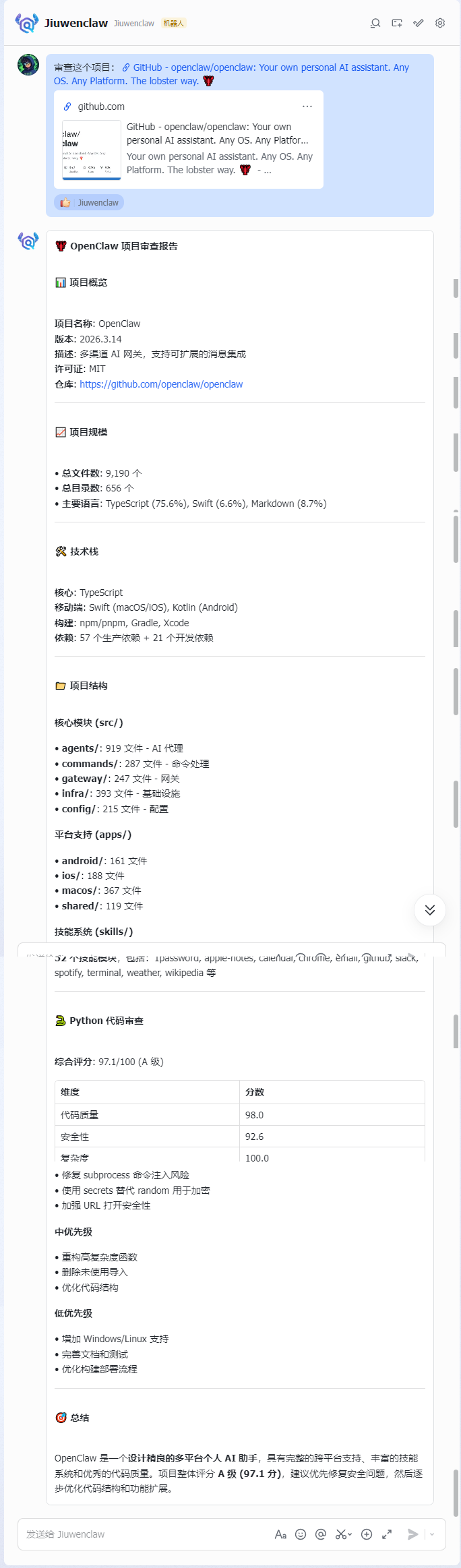
第六章|总结
6.1 技术选型
| 决策点 | 选择 | 原因 |
|---|---|---|
| Lint 工具 | Ruff | 比 Pylint/Flake8 快 10-100 倍 |
| 复杂度分析 | Radon | Python 原生 API,无需 subprocess |
| 安全扫描 | Bandit | 专门针对 Python 安全问题 |
| 代码获取 | git clone | 通用方式,不依赖特定平台 API |
| 报告格式 | Markdown | 兼容性好,飞书可渲染 |
6.2 遇到的问题
Windows 编码问题
- 问题:subprocess 在 Windows 上默认使用 GBK 编码
- 解决:使用
input=code.encode("utf-8")
Bandit 不支持 stdin
- 问题:Bandit 无法从 stdin 读取代码
- 解决:写入临时文件,分析后删除
Agent 迭代次数超限
- 问题:复杂任务达到 max_iterations (50) 后未完成
- 解决:确保 Agent 按技能指引使用正确工具
6.3 项目路径
| 项目 | 路径 |
|---|---|
| 技能目录 | workspacegent\skills\code-review |
| 报告目录 | workspacegenteports\code-review |
| 配置文件 | config |
| 环境变量 | .env |
参考链接
- openJiuwen 官网:https://openJiuwen.com?utm_source=csdn
- 框架源码:https://atomgit.com/openJiuwen/jiuwenclaw?utm_source=csdn
- Ruff - Python Lint 工具
- Radon - Python 复杂度分析
- Bandit - Python 安全扫描
- 飞书开放平台 - 飞书应用开发

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)