LLM之Agent(四十六)|OpenClaw-RL:AI Agent正在丢弃最宝贵的训练数据
一个可能改变 Agent 训练方式的关键发现:
我们一直在浪费最重要的数据。
一、TL;DR(先看结论)
- 每一次 Agent 交互,都会产生“下一状态信号”
- 但现有系统几乎全部 **浪费了这些信号**
- OpenClaw-RL 把这些信号变成实时训练数据
- 完全异步架构:边服务边学习
- 两大方法:
-
On-Policy Distillation
-
Binary RL
-
- 效果:个性化 0.17 → 0.81
二、我们一直在浪费的数据(金矿)
现实情况是:
每一个 AI Agent 在运行过程中,都在不断产生高质量数据:
- 用户反馈(“不是这个文件”)
- 工具调用结果
- 终端输出
- GUI 状态变化
- 测试结果
这些数据的特点是:
👉 免费
👉 实时
👉 高价值
👉 强结构化
但问题是:
几乎所有系统,都把这些数据当“上下文”,而不是“训练数据”。
三、什么是“下一状态信号”
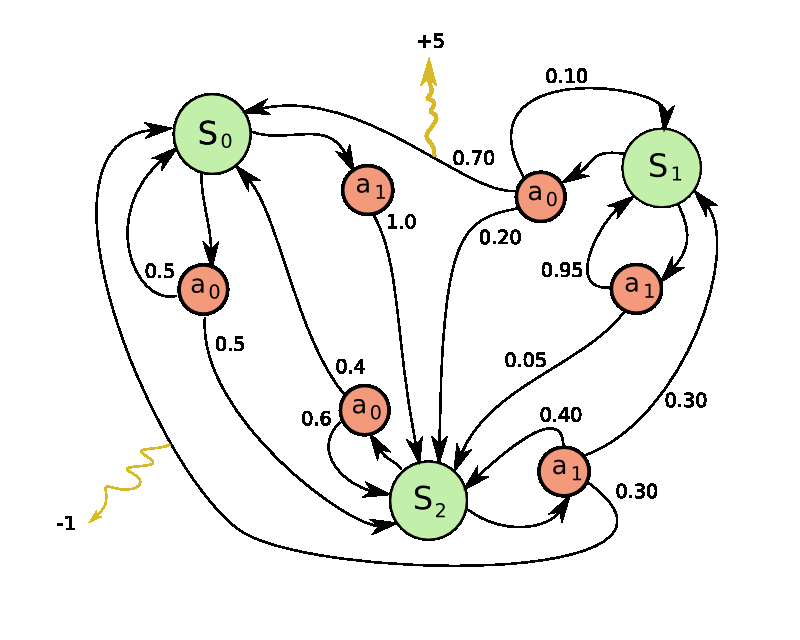
在强化学习中:
- Agent 执行动作:aₜ
- 环境反馈变化:sₜ₊₁
这个 sₜ₊₁,就是:
👉 **Next-State Signal(下一状态信号)**
关键问题
在传统 LLM 系统中:
- 要么忽略这个信号
- 要么只在最后给 reward
👉 导致:
- 中间过程无法学习
- 长链任务难优化
- 学习效率极低
四、下一状态信号的两种信息
1️⃣ 评估信号(Evaluative)
- 用户重复提问 → 不满意
- 测试通过 → 成功
- 报错 → 失败
👉 可转为 reward(+1 / 0 / -1)
2️⃣ 指令信号(Directive)
例如:
“你应该先检查文件再修改”
这不是简单的负反馈,而是:
👉 明确告诉模型:
- 哪里错
- 怎么改
⚠️ 这是传统 RL 完全无法捕捉的
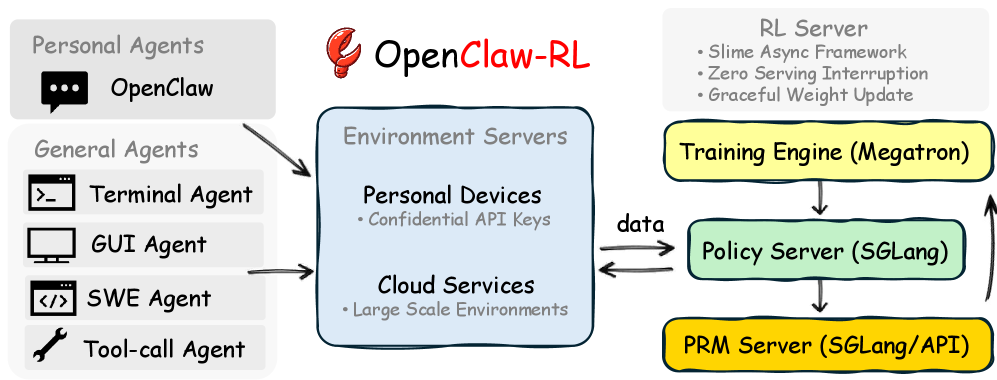
五、OpenClaw-RL 的核心架构

OpenClaw 的关键创新不是单一算法,而是:
一个完全异步的学习系统
四个并行循环
系统同时运行:
-
Agent 推理
-
PRM 评分
-
Trainer 更新
-
数据处理
核心特点
- 无阻塞(Zero Blocking)
- 持续学习
- 用户无感知
一句话理解
你在用它,它就在变强。
六、方法一:Binary RL(基础但必要)
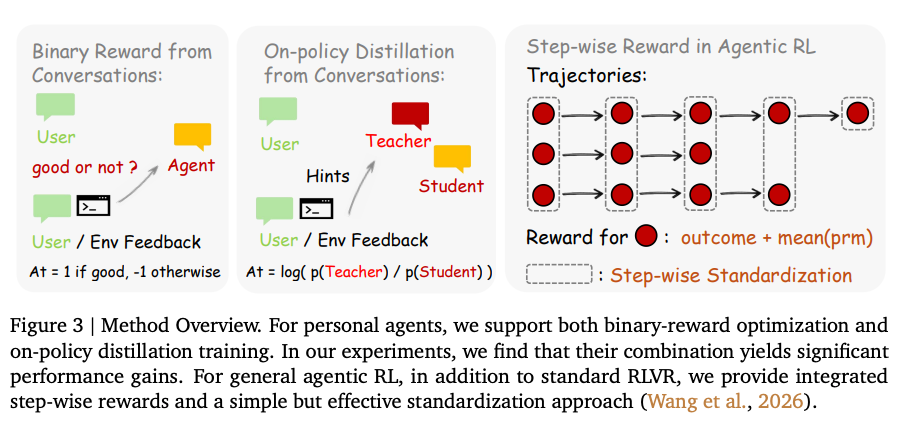
PRM 对每一步打分:
- +1(好)
- 0(中)
- -1(差)
并通过 PPO 优化模型。
优点
- 简单稳定
- 覆盖全面
- 所有数据都能用
缺点
信息太粗糙
例如:
用户说:
你应该先检查文件
模型只得到:
👉 -1
但不知道:
👉 应该怎么改
七、方法二:On-Policy Distillation(真正核心)
这是 OpenClaw 最关键的创新。
四步流程
Step 1:提取 Hint
从反馈中提炼:
👉 1–3句改进建议
Step 2:质量筛选
只保留:
👉 有明确方向的数据
Step 3:构造 Teacher 输入
把 Hint 加入 prompt:
👉 得到“理想输入”
Step 4:自蒸馏训练
比较:
- Teacher(优化后)
- Student(原始)
👉 得到 token-level 优化信号
本质
模型用“事后反馈”,训练“更好的自己”
八、组合方法:效果爆炸
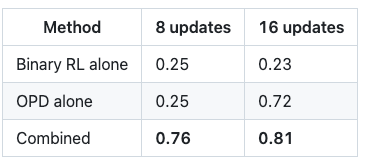
单独使用:
- Binary RL → 后期退化
- OPD → 收敛慢
组合后
- 8步:0.17 → 0.76
- 16步:0.81
实际案例
学生 Agent
- 36次交互后:
-
更自然表达
-
不再“AI味”
-
教师 Agent
- 24次交互后:
-
更具体反馈
-
更友好
-
九、扩展到通用 Agent

OpenClaw 可扩展到:
- Terminal Agent
- GUI Agent
- SWE Agent
- Tool Agent
实验结果
- 仅 outcome reward:0.17
- 加 process reward:0.30
👉 提升 76%
十、为什么这件事非常重要
现在的 Agent:
- 用 memory
- 用 prompt
- 用工具链
👉 但:
模型本身没有进化
OpenClaw 的改变
👉 **模型权重实时更新**
而且:
- 在线
- 无中断
- 本地运行
十一、真正的认知升级
❗你已经拥有训练数据
问题不是没有数据,而是:
你没有用它
❗最有价值的数据
不是:
- 标注数据
- benchmark
而是:
👉 真实用户交互
❗未来趋势
Agent = 使用越多 → 越聪明
十二、总结
OpenClaw-RL 做的事情不是创造数据,而是:
把你每天丢掉的数据,变成最强训练信号。
如果你在做 AI Agent,可以问自己一个问题:
👉 你有没有在用 next-state signal 训练模型?
如果没有:
👉 你正在浪费整个系统中最有价值的资产。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)